1.原理
在之前的交叉熵损失函数中,我们让模型学习到的标签类别的概率为1,其他的类别让模型学习出的概率为0,这样很容易让模型过拟合,并且使得损失函数不平滑,为了解决这个问题,我们使用标签平滑的方法。
平滑前的理想概率分布:
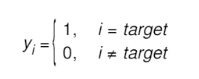
平滑后的理想概率分布:
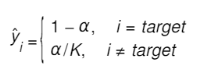
经过标签平滑的方法,然后送入到交叉熵损失函数下,具体公式如下图(小黑找了半天才找到的图):
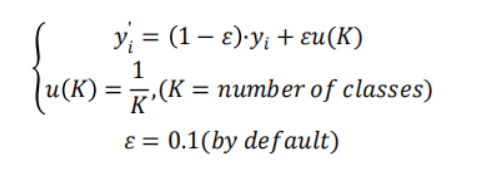
损失函数核心代码:
loss * self.eps / c + (1 - self.eps) * F.nll_loss(log_preds,target,reduction = self.reduction,ignore_index = self.ignore_index)
核心代码对应公式:

小黑突然上面两张图与本文的第二张图在概率分布上的表示出现了不一致的现象,好多博客上的写法也不太一样,为此小黑纠结了一下午,不纠结了,明白啥意思就行了,学!跑!练!干!小黑冲!!!!!!

2.整体代码demo:
import torch.nn as nn
import torch.nn.functional as F
import torch
class LabelSmoothingCrossEntropy(nn.Module):def __init__(self,eps = 0.1,reduction = 'mean',ignore_index = -100):super(LabelSmoothingCrossEntropy,self).__init__()self.eps = epsself.reduction = reductionself.ignore_index = ignore_indexdef forward(self,output,target):# output:[num,num_tags]# target:[num]c = output.size()[-1]# log_preds:[num,num_tags]log_preds = F.log_softmax(output,dim = -1)if self.reduction == 'sum':loss = -log_preds.sum()else:loss = -log_preds.sum()if self.reduction == 'mean':loss = loss.mean()return loss * self.eps / c + (1 - self.eps) * F.nll_loss(log_preds,target,reduction = self.reduction,ignore_index = self.ignore_index)reduction = 'sum'
loss = LabelSmoothingCrossEntropy(reduction = reduction)
pred = torch.randn([4,10])
target = torch.ones([4]).long()
print('smooth loss:',loss(pred,target))
输出:
smooth loss: tensor(10.6777)