MARL学习篇----MADDPG
前言
MADDPG是DDPG在多智能体任务中的一种扩展,其基础思想为:集中式学习,分散式执行(CTDE)。
简单来说,在训练的时候,引入可以观察全局的critic来指导actor训练,而测试的时候只使用有局部观测的actor采取行动。。你可以这么理解:每一个agent都有一个全知全能的老师指导,而在做决策的时候,agent只需要根据自己对环境的观察做出正确的动作。
这种思想简单粗暴但方法却行之有效,可见这其中的trick应该不少。
算法简介
传统强化学习方法很难用在multi-agent环境上,一个主要的原因是每个agent的策略在训练的过程中都是不断变化的,这导致对每个agent个体来说,环境都是不稳定的,而在这种不稳定的环境中学习到的策略是毫无意义的。因此,对于Q-learning这类方法,经验回放的方法(experience replay)是完全失效的。而对于policy gradient方法来说,随着agent数量增加,环境复杂度也增加,这就导致通过采样来估计梯度的优化方式,方差急剧增加。给一张图你就明白了
而在MADDPG中,一个重要的前提是:当我们知道所有agent的动作时,无论策略如何变化,我们的环境都是稳定的。这也为我们之后方法的设计提供了保障。

MADDPG算法具有以下三点特征: 1. 通过学习得到的最优策略,在应用时只利用局部信息就能给出最优动作。 2. 不需要知道环境的动力学模型以及特殊的通信需求。 3. 该算法不仅能用于合作环境,也能用于竞争环境。
其算法有以下三个技巧
- 集中式训练,分布式执行(CTDE):训练时采用集中式学习训练critic与actor,使用时actor只用知道局部信息就能运行。critic需要其他智能体的策略信息.
- 改进了经验回放记录的数据。
- 利用策略集合效果优化(policy ensemble):对每个智能体学习多个策略,改进时利用所有策略的整体效果进行优化。以提高算法的稳定性以及鲁棒性。
算法实现
网络整体结构如下

这里π\piπ为智能体策略,我们设定其参数为θ\thetaθ,J(θ)J(\theta)J(θ)为第i个智能体的累计期望奖励E[Ri]E[R_i]E[Ri?],由此第i个agent的梯度可以表示为
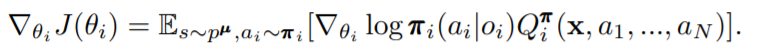
其中
oio_ioi?表示第i个智能体的观测,x=[o0,…,oi]x = [o_0, \dots,o_i]x=[o0?,…,oi?]即状态。 QiπQ_i^{\pi}Qiπ?为critic_network。由于每个智能体独立的学习自己的QiπQ_i^{\pi}Qiπ?,因此,MADDPG也可应用于合作或竞争任务。
对于确定性策略而言,其梯度可表示为
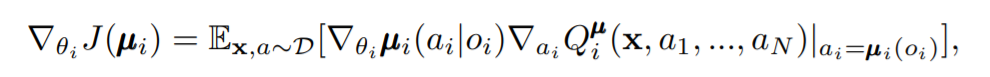
由此我们利用该梯度更新actor网络,而对于critic网络,我们需要计算其与目标网络的均方差作为loss来更新参数。
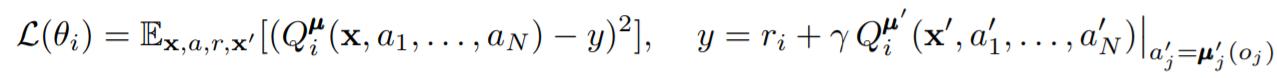
其中 Qiπ′Q_i^{\pi'}Qiπ′?为target_critic_network
最后,利用软更新的操作更新我们target_network的相关参数
算法整体伪代码如下

其它
MADDPG算法整体和DDPG基本类似,思路也很清晰,之后会更新对应的代码及调试经历可参见我的GitHub。
而对于MARL这个系列打算只更新两版,MADDPG和MAPPO,不过MAPPO刚发布没多久,可参考的资料较少,期间可能会断断续续更新一些学习笔记之类的。