RNN��������IJ�ͬ�ǣ�����cell������Ϊ��һ��cell�����룬�������RNN����һ��**��������**�ģ���Ϊ�ҵ������Ϊ���ҵ����룬����ѵ���������м����Եģ���������������������Ӿ���ģ�⣬��ѭ������������������źŵ�ģ�⣬��ͨ������ʱ�������ϵ�����Բ�����һ���̶ȵļ��䣬���ּ���������壬�����Ϣ��
����Ӧ��
1.Ԥ��һ��ʱ���źŵ�δ�����ݣ����緿�ۣ��ɼۣ���˾Ч���Ԥ�⡣
2.��Ȼ���Դ���
���ڿ�һƪ���µ�ʱ��Ҫ����������⣬������Ҫ����ȫ���Ķ������ӣ�������ֻ����ij���֣�Ȼ��ſ��Դ�ȫ�����������µ����ݣ��������Dz�����������ֶ������������Ե�����������������һ�ֳ����������������CV��ͼ����������ֱ�ۣ�������һ������Ҹ����ǻ��Ե�������
��������

1�Զ����ӣ����£�ժҪ�����ɣ��Ҹ���ǰһ���ֻ��Ǵʣ����ͻ����ɺ����һ�������
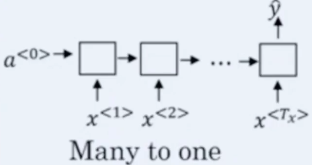
���һ���ӣ���Ʊ����Ԥ�⣬�Զ���ʻ�켣Ԥ��
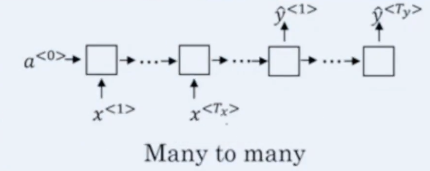
��Զ����ӣ�������������
��ͨRNNȱ��
�Գ��ڼ��䶪ʧ���ر��������һֱ��ͬһ����Ԫѵ�����ݶȲ�ͣ�������ۼӣ�Ϊ�˷�ֹ�ݶȱ�ը���ݶ���ʧ�����������ͨ��ѡsigmoid����ȥ���������relu����͵���һ�����⣺�����źŵĽ�β���бȽϴ���ݶ��źţ���������һֱ���ݵ��ź�����Ŀ�ͷ���֣��ݶȾͺ�С�ˣ��Ͳ�̫��ı�ѵ�������ˡ�
ֱ���Ͻ���������仰����IJ��ֺ�������һ�����ͱ��磬�ҿ���һ�仰�����Ѿ�������仰��������ʲô�ˡ���͵����Ҽ���������������仰��
���ȱ�㣬������LSTM
LSTM
����4��ȫ���Ӳ���ɣ�
 �����������ˣ�����ʵ���ϲ��ѣ�I,F,G,O����ȫ���Ӳ�ѵ������������
�����������ˣ�����ʵ���ϲ��ѣ�I,F,G,O����ȫ���Ӳ�ѵ������������
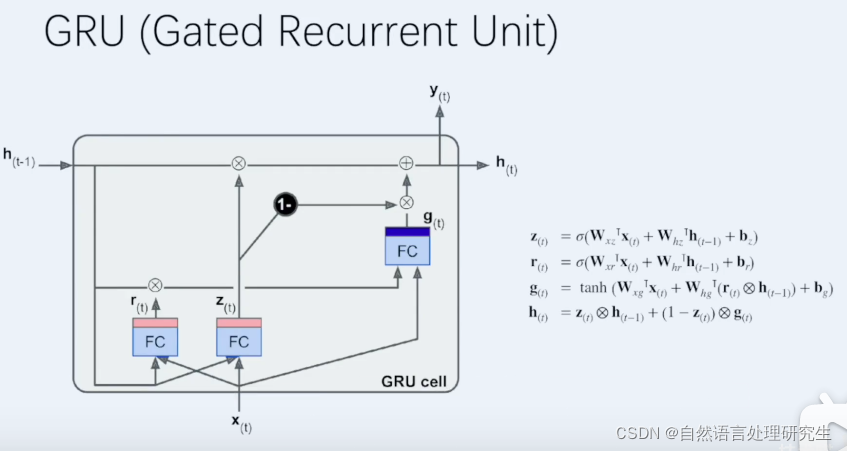
G�Ƕ��ڼ�����Ϣ��������ͨRNN���㹫ʽ��Ҳ���ֹ�
���ڼ���G��ͨ��һ��input gate�ţ��������I������i��ֵ��[0,1]֮�䣬IԽ��G��������������ϢԽ�ࡣ
C�dz��ڼ�����Ϣ����ΪCt�ļ��㹫ʽ�а�����Ct-1��
���ڼ���C��ͨ��һ��forget gate�ţ��������F������F��ֵҲ��[0,1]֮�䣬FԽ���ڼ��䱻����������Խ�ࡣ
������ڵ�ǰ״̬�����ڼ���ȳ��ڸ���Ҫ����ô�ͻ��Fϵ�����ͣ�������һ����
Ȼ��O��������ţ��ۺ���Ϣ������Եõ����ս��yt��ht
����LSTMѵ����4��ȫ���Ӳ㣬�������IJ�����ܸ��ӣ������Ƴ��˼�GRU
GRU
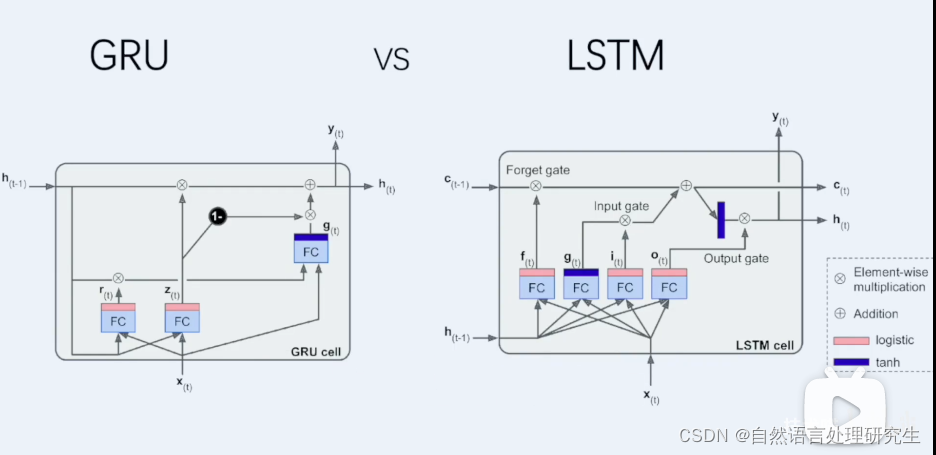
 GRU��LSTM��������
GRU��LSTM��������
1.������������ϢCt��
2.��ΪRt�Ǿ���ȫ���Ӳ�����Ϣ��������������ṹ��
3.��Ϊ��������һ��ȫ���Ӳ����Բ����٣��ٶȱ�lstm��
˫��ѭ��������
�����е�ʱ������������ǰ��ľ�����˼����Ҫ֪������ľ�����ʲô�����Ծ�����˫��ѭ�������磬���Դ�ǰ���Ӻ���ǰ�������Ƕ�ȥ�����������
RNN��������Ϣ
RNN������reluȥ�����������Ϊ��������ͬ���IJ������˺ܶ����������ÿһ�㲻ͬ�IJ���������Ǻ��ߣ�����ܻᵣ���ݶȻ���ɢ���ݶ���ʧ��ѵ��ֹͣ������ʵ�����ǰ�ߣ�����RNN���ԣ��ݶȱ�ը�Ǹ���Ҫ�����⣬�Լ��ݶȲ��ȶ����⣬��ǰһ�����뵼������������һ�����뵼�����½���������ȶ������ⷽ���кࣺܶdropout��BN�ȡ�
����BN������ij������㣬ȥ�Ѹ��������ľ�ֵ�ͷ���̶���һ��С�ķ�Χ�����������һ�㣬��ᵼ�²������ȱ仯����ȶ������������ȶ��ԡ�
BN������ʽ���ҵ�batch��1000�����ӣ��Ҷ����о����еĵ�һ���ʽ��б������������������ı���
���Ӧ��LN�Ĺ�����ʽ�����������ı�������Ӧ��ÿ�����������ӵ�һ���ʵ����һ���ʵı�����