һ�����Իع�
���Ƿ��۵����ӡ�
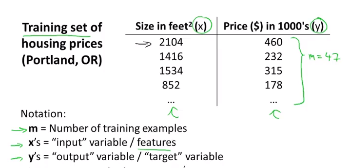
�ع��������Ԥ��һ���������ֵ�����Ҳ���Ǽ۸�
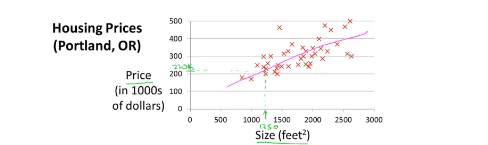
���Իع������һ��һ�κ��������ѵ�����ݼ�����ͼ��
����Ԥ��y�ǹ���x�����Ժ�����
��

���ǿ��Կ������������ǵ�ѵ������Training Set�������ǰ����ṩ���ǵ�ѧϰ�㷨��Learning Algorithm������ѵ����Ȼ���㷨ͨ��ѵ�����һ������h����hypothesis(����)������ h��ʾһ����������������x�Ƿ��ݳߴ��С��h ��������� x ֵ���ó�yֵ��yֵ����Ԥ��Ķ�Ӧ���Ӽ۸���� h��һ����x��y�ĺ���ӳ�䡣
�������ۺ���
���ۺ������������ҵ����Ž���Ŀ�ĺ�������Ҳ�Ǵ��ۺ��������á�
��Ȼ���ҳ�һ��ֱ�� �����ѵ�����ݣ���ô������εó�
��
��ֵ����ʹ���ܺõ���������أ���һ���뷨������Ҫѡ��һ��h(x)����ʹ����xʱ������Ԥ���ֵ��ӽ���������Ӧ��yֵ����ʱ��
��
��������Ҫ�ҵġ�����������Ҫһ��������ѵ���������������
��
��ֵ����������Ҫ����ѡ����ʵIJ���ֵ��ʹ�ø���ѵ�����е�xֵ�������ܺ���ȷ��Ԥ��y��ֵ��
���ڻع����⣬������Ҫ������ۺ�����������Ž⣬���õ���ƽ�������ۺ�����
�������磬��������ļ��躯��:
���������� ��
���������������ĸı佫�ᵼ�¼��躯���ı仯�����磺
�������Ķ��壺�����Իع��У�����Ҫ�������һ����С�����⣬����Ҫд��������
����С��������ϣ�����ʽ�Ӽ���С����h(x)��y֮��IJ���ҪС������Ҫ����������Ǿ�����������������������ʵ�۸�֮��IJ��ƽ����
����
ƽ�������ۺ�������Ҫ˼�룺��ʵ�����ݸ�����ֵ��������ϳ����ߵĶ�Ӧֵ�����ƽ�������������ϳ���ֱ����ʵ�ʵIJ�ࡣ
������m��������������Ҫ�����е�ѵ����������һ����ͣ�
ps���ϱ� i ��ʾ�� i ��ѵ���������õ� i ��ѵ������������ֵ��Ԥ��ı�ǩh��ȥ �� i ��ѵ������������ȷ�����
����2 ����Ϊ���㡣
����������Ҫ�Ĵ��ۺ�����Ҳ������Ҫ�Ż���Ŀ�꺯����