ФЪұҫІ©ҝНЦРЈ¬ОТҪ«¶Ф№ЗјЬ¶ҜЧчК¶ұрИООсЦРУҰУГНјҫн»эөДҝӘЙҪЦ®ЧчST-GCNҪшРРЦШКцЈ¬ЖдЦР»бІОФУёцИЛөДАнҪвЎЈұҫЖӘІ©ҝНДЪИЭОӘұҫИЛСРҫҝЙъҪЧ¶ОҪбҝОЧчТөУлВЫОДІҝ·ЦДЪИЭЈ¬ТтҙЛёДҪшІҝ·ЦФЭКұОҙЙПҙ«Ј»ұҫЖӘІ©ҝНЦјФЪУЪ№гҙуН¬С§Т»Жр·ЦПнМЦВЫУЪҪшІҪЈ¬ЗлОрЛҪЧФЧӘФШЎЈ
ФЪОДД©Ҫ«»б¶ФST-GCNЦРөДНјҫн»эҙъВлҪшРРНј»ӯІыКцЎЈәуРшҝЙДЬ»бёьРВҙъВлҪІҪвЎЈ
Т»ЎўХӘТӘ
ФЪ»щУЪ№ЗјЬөД¶ҜЧчК¶ұрИООсЦРЈ¬¶ҜМ¬өДИЛМе№ЗјЬҫЯУРёГИООсЛщРиөДЦШТӘРЕПўЈ¬И»¶шТФНщҙ«НіөД·Ҫ·ЁНЁіЈК№УГКЦ№ӨМШХч»тұйАъ№жФт¶Ф№ЗјЬҪшРРҪЁДЈЈ¬І»ҪцПЮЦЖБЛДЈРНұнҙпДЬБҰ»№К№өГДЈРН·ә»ҜА§ДСЈ»ТтҙЛЧчХЯМбіцБЛТ»ёцРВУұөД¶ҜМ¬№ЗјЬДЈРНST-GCNЈ¬ЛьҝЙТФҙУКэҫЭЦРЧФ¶ҜС§П°ЖдҝХјдәНКұјдөДДЈКҪЈ¬КөПЦБЛРЕПўФЪКұҝХО¬¶ИөДјҜіЙЈ¬ІўК№өГДЈРНҫЯУРәЬЗҝөДұнҙпДЬБҰәН·ә»ҜДЬБҰЎЈёГДЈРНФЪKineticsәНNTU-RGB+DБҪёц№ЗјЬК¶ұрКэҫЭјҜЙПУлЦчБч·Ҫ·ЁПаұИЈ¬ИЎөГБЛЦКөДМбЙэЎЈ
¶юЎўТэСФ
ИЛМе¶ҜЧчК¶ұрФЪҪьДкАҙКЗСРҫҝИИөгЈ¬ҙујТК№УГНв№ЫЎўЙо¶ИЎў№вБчЎўЙнМе№ЗјЬөИКэҫЭДЈКҪАҙНкіЙёГИООсЈ¬И»¶шИҙәцВФБЛҙшУРҙуБҝЦШТӘРЕПўөД¶ҜМ¬ИЛМе№ЗјЬЈ¬ТтҙЛЧчХЯПөНіөШФЪёГДЈМ¬ПВҪшРРСРҫҝЈ¬УРФӯФтЎўёЯР§өД·Ҫ·Ё¶Ф¶ҜМ¬ИЛМе№ЗјЬҪЁДЈЎЈ
ТФНщАыУГ№ЗјЬКэҫЭ¶јКЗјтөҘөДК№УГЖдёчёцКұјдЦЎЙПөД2D»т3D№ШҪЪЧшұкАҙ№№іЙМШХчПтБҝЈ¬ФЩ¶ФЖдҪшРРКұРт·ЦОцЈ¬ХвЦЦ·Ҫ·ЁҫЯУРҫЮҙуөДҫЦПЮРФЈәОҙАыУГЦБ№ШЦШТӘөД№ШҪЪҝХјд№ШПөЈ»І»Н¬УЪХвР©·Ҫ·ЁЈ¬ЧчХЯК№УГ№ШҪЪөДЧФИ»Б¬ҪУ№№ҪЁіц№ЗјЬНјЈ¬ІўАыУГЙсҫӯНшВзЧФ¶ҜІ¶ЧҪҝХјдҪб№№әНКұРт¶ҜМ¬ЎЈ№ШУЪЙсҫӯНшВзАаРНөДСЎФсЈ¬І»Н¬УЪТФНщК№УГ№жФтөДЎўНшёсҪб№№өДЕ·јёАпөГКэҫЭЧчОӘНшВзөДКдИлөД·ҪКҪЈ¬ЧФИ»Б¬ҪУөД№ЗјЬНјКдИлКЗТ»ёцІ»№жФтөДНјРОКэҫЭЈ¬ТтҙЛК№УГНјҫн»эЧФИ»ұИҙ«Ніҫн»эЙсҫӯНшВзCNNҫЯУРМмИ»өДУЕКЖЎЈ
»щУЪЙПКцұіҫ°Ј¬ЧчХЯЙијЖБЛУГУЪ¶ҜЧчК¶ұрөД№ЗјЬРтБРөДНЁУГұнКҫЈ¬ІўЗТҪ«НјЙсҫӯНшВзА©Х№өҪёГКұҝХНјЦР№№ҪЁіцКұҝХНјҫн»эНшВзДЈРНЈ¬іЖОӘST-GCNЎЈ¶ФУЪКұҝХНјөД№№ҪЁЈ¬ЧчХЯҪ«ИЛМе№ЗјЬ№ШҪЪЧчОӘҪЪөгЈ¬Ҫ«ҝХјдЙПИЛМе№ЗјЬөДЧФИ»Б¬ҪУЧчОӘҝХјдұЯЈ¬Ҫ«КұРтЙППаН¬ҪЪөгФЪЗ°Т»ЦЎәНәуТ»ЦЎөД¶ФУҰҪЪөгБ¬ҪУЧчОӘКұРтұЯЈ»ЛжәуФЪёГКұҝХНјЙП№№ҪЁ¶аІгКұҝХНјҫн»эЈ¬·ЦұрФЪҝХјдО¬¶ИәНКұјдО¬¶ИМбИЎРЕПўЎЈ
ұҫОДЦРЈ¬ЧчХЯөДЦчТӘ№ұПЧОӘЈә
- КЧҙОФЪ№ЗјЬ¶ҜЧчК¶ұрЦРУҰУГНјҫн»эЈ¬ІўМбіцST-GCN¶Ф¶ҜМ¬№ЗјЬҪш РРНЁУГҪЁДЈЈ»
- Хл¶Ф№ЗјЬҪЁДЈөДҫЯМеТӘЗуЈ¬ФЪST-GCNЦРМбіцҫн»эәЛЙијЖөДФӯФтЈ»
- ФЪKineticsәНNTU-RGB+DБҪёц№ЗјЬК¶ұрКэҫЭјҜЙПИЎөГБЛУЕФҪөДРФДЬЈ¬ІўјхЙЩБЛҙуБҝөДИЛ№ӨЙијЖЎЈ
ИэЎўПа№Ш№ӨЧч
1.Нјҫн»э
Нјҫн»эЦчТӘУРБҪЦЦЦчБч·Ҫ·ЁЈә
- »щУЪЖөУтЈЁspectral perspectiveЈ©өДНјҫн»э·Ҫ·ЁЈәРиТӘ¶ФКдИлҪшРРЖөУтЧӘ»»Ј¬јЖЛгБҝҙуЈ»
- »щУЪҝХУтЈЁspatial perspectiveЈ©өДНјҫн»э·Ҫ·ЁЈәЦұҪУ¶ФНјҪб№№ҪшРРҫн»эЈ¬ІЩЧч·ҪұгЎЈ
ФЪұҫОДЦРЈ¬ЧчХЯК№УГҝХУтНјҫн»э·ҪКҪЎЈ
2.»щУЪ№ЗјЬөД¶ҜЧчК¶ұр
»щУЪ№ЗјЬ¶ҜЧчК¶ұрЦчТӘҝЙТФ·ЦОӘБҪҙуАаЈә
- »щУЪКЦ№ӨМШХчөД·Ҫ·ЁЈәјҙК№УГКЦ¶ҜЙијЖөДМШХч№ШҪЪФЛ¶ҜөД¶ҜМ¬РЕПўЈ»ЦчТӘөДКЦ№ӨМШХчУРЈә№ШҪЪ№мјЈөДРӯ·ҪІоҫШХуЎў№ШҪЪПа¶ФО»ЦГ»тКҘМеІҝО»Ц®јдөДРэЧӘУлЖҪТЖЈ»
- »щУЪЙо¶ИС§П°өД·Ҫ·ЁЈәФЪТФНщЈ¬ёГ·Ҫ·ЁЦчТӘКЗК№УГөЭ№йЙсҫӯНшВз(RNN)әНҫн»эЙсҫӯНшВз(CNN)ЎЈ
ФЪұҫОДЦРЈ¬ЧчХЯМбіцөДST-GCNКЧҙОК№УГНјҫн»эЙсҫӯНшВз(GCN)Ј¬К№ЖдҝЙТФАыУГНјҫн»эөДҫЦІҝРФәНКұРт¶ҜМ¬РЕПўёьәГёь·ҪұгөДС§П°ИЛМе¶ҜЧчөДұнКҫЎЈ
ЛДЎўКұҝХНјҫн»эНшВз
ПЦУР·Ҫ·ЁТСҫӯЦӨГчБЛЙнМеІҝО»өДҫЦІҝРЕПў¶Ф№ЗјЬ¶ҜЧчК¶ұрИООсК®·ЦУРР§Ј¬ТтҙЛЧчХЯұгТэУГҙЛ·Ҫ·ЁЦРөД№ЗјЬРтБРұнКҫөДІгҙОРФәНҫЦІҝРФЈ¬К№УГЙсҫӯНшВзҪшРРКөПЦЈ¬ҙУ¶ш№№ҪЁіцБЛ»щУЪ№ЗјЬ¶ҜЧчК¶ұрИООсЙПөДST-GCNДЈРНЎЈ
1.ДЈРНБчіМёЕКц
ИзНј1ЛщКҫЈ¬ФЪST-GCNНшВзЦРЈәКЧПИК№УГЧЛМ¬№АјЖ·Ҫ·ЁҙУЖХНЁКУЖөКэҫЭЦР»сИЎ№ЗјЬКэҫЭЈ¬ІўАыУГёГКэҫЭ№№ҪЁіцКұҝХ№ЗјЬРтБРНјЧчОӘКұҝХНјҫн»эНшВзST-GCNөДКдИлЈ»Ц®әуК№УГ¶аІгКұҝХНјҫн»эНшВзҪшРРҫн»эЈ¬ЦрІҪФЪНјЙПЙъіЙёьёЯІгҙОөДМШХчНјЈ»ЧоәуУГұкЧјөДSoftmax·ЦАаЖчҪ«Жд·ЦАаОӘПаУҰөД¶ҜЧчАаұрЈ¬ХыёцДЈРННЁ№э·ҙПтҙ«ІҘТФ¶ЛөҪ¶ЛөД·ҪКҪҪшРРСөБ·ЎЈ

Нј1 ST-GCNНшВз
2.№№Фм№ЗјЬНј
ФЪST-GCNЦРЈ¬БоУөУР![]() ёцҪЪөгәН
ёцҪЪөгәН![]() ЦЎөД№ЗјЬРтБРКұҝХНј¶ЁТеОӘ
ЦЎөД№ЗјЬРтБРКұҝХНј¶ЁТеОӘ![]() Ј¬ЖдҝЙКУ»ҜәуИзНј1ЛщКҫЈ»ЖдЦРЈә
Ј¬ЖдҝЙКУ»ҜәуИзНј1ЛщКҫЈ»ЖдЦРЈә
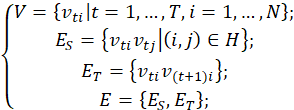
ЖдЦРөДҪЪөгјҜәПОӘ![]() Ј¬ЗТЖдЦРөДөЪt
Ј¬ЗТЖдЦРөДөЪt![]() ЦЎөДөЪi
ЦЎөДөЪi![]() ҪЪөгөДМШХчПтБҝ
ҪЪөгөДМШХчПтБҝ![]() УРЈә
УРЈә
ИфК№УГopenposeМбИЎөД№ЗјЬКэҫЭЈ¬ФтЖд![]() ОӘёГҪЪөгөДЧшұкПтБҝәН№АјЖЦГРЕ¶ИЧйіЙЈ»¶шKineticsәНNTU-RGB+DКэҫЭјҜөД
ОӘёГҪЪөгөДЧшұкПтБҝәН№АјЖЦГРЕ¶ИЧйіЙЈ»¶шKineticsәНNTU-RGB+DКэҫЭјҜөД![]() ОӘёГҪЪөгөДЧшұкПтБҝЎЈ
ОӘёГҪЪөгөДЧшұкПтБҝЎЈ
ЖдЦРөДұЯјҜәП°ьАЁ![]() әН
әН![]() Ј¬·ЦұрЦёҝХјдұЯ(spatial edges)әНКұРтұЯ(temporal edges)Ј»
Ј¬·ЦұрЦёҝХјдұЯ(spatial edges)әНКұРтұЯ(temporal edges)Ј»![]() ЦёТ»ЧйЧФИ»Б¬ҪУөДИЛМе№ШҪЪЎЈ
ЦёТ»ЧйЧФИ»Б¬ҪУөДИЛМе№ШҪЪЎЈ

Нј2 №ЗјЬРтБРКұҝХНј
3.№ЗјЬНјөДЧУјҜ»®·Ц
ФЪ№№јЬәГ№ЗјЬНјәуЈ¬ЧчХЯ¶ФЖдҪшРРБЛНј»®·ЦІЩЧчЈЁИзНј2ЛщКҫ,ЖдЦРНј2-(a)ОӘЖХНЁ№ЗјЬНјЈ©Ј¬ҙУ¶шҝЙТФК№УГ¶аЦЦҫн»эәЛҪшРРҫн»эЎЈұҫОДЦРЧчХЯК№УГөД»®·ЦІЯВФОӘҝХјдҪб№№»®·Ц·ҪКҪ(Spatial configuration partitioning)ЈЁИзНј2-(d)ЛщКҫЈ©Ј¬Ҫ«ЖдҪб№№НјБЪҪУҫШХу»®·ЦОӘ3ёцЧУҫШХуЈ¬јҙТвО¶ЧЕҪ«Ҫб№№Нј»®·Ц3ёцЧУНјЈәЖдЦРөЪТ»ёцЧУјҜБ¬ҪУБЛҝХјдО»ЦГЙПұИёщҪЪөгёьФ¶АлХыёц№ЗјЬөДБЪҫУҪЪөгЈ¬өЪ¶юёцЧУјҜБ¬ҪУБЛёьҝҝҪьЦРРДөДБЪҫУҪЪөгЈ¬өЪИэёцЧУјҜОӘёщҪЪөгұҫЙнЈ¬·ЦұрұнКҫБЛАлРДФЛ¶ҜЎўПтРДФЛ¶ҜәНҫІЦ№өДФЛ¶ҜМШХчЎЈіэБЛХвЦЦ»®·Ц·ҪКҪНвЈ¬ЧчХЯ»№·ЦұріўКФБЛОЁТ»»®·Ц(Uni-labeling partitioning)·ҪКҪЈЁИзНј2-(b)ЛщКҫЈ©ЈәҪ«ҪЪөгөДБЪҫУҪЪөг»®·ЦОӘТ»ёцЧУјҜәН»щУЪҫаАлөД»®·Ц (Distance partitioning)·ҪКҪЈЁИзНј2-(c)ЛщКҫЈ©ЈәҪ«ҪЪөгөДБЪҫУҪЪөгәНёщҪЪөг»®·ЦОӘ2ёцЧУјҜЈ»ө«КөСйР§№ыҫщІ»јСЎЈ

Нј3 №ЗјЬНј·ЦЗшІЯВФ
4.КұҝХНјҫн»эНшВз
ФЪҪйЙЬНјҫн»эЦ®З°Ј¬ЧчХЯПИТФCNNФЪөҘЦЎ№ЗјЬНјКдИлөДҫн»эҫЩАэЈ¬Іў¶ФЖдҫн»э№«КҪҪшРРНЖ№гёЕАЁЈ¬өГөҪёьјУНЁУГөДҫн»э№«КҪЈ¬јҙёш¶ЁТ»ёцәЛҙуРЎОӘ![]() өДҫн»эЛгЧУЎўКдИлМШХчУіЙд
өДҫн»эЛгЧУЎўКдИлМШХчУіЙд![]() әННЁөАКэc
әННЁөАКэc![]() Ј»ҝХјдО»ЦГx
Ј»ҝХјдО»ЦГx![]() ФЪөҘёцНЁөАөДҫн»эКдіцҝЙТФ¶ЁТеОӘЈә
ФЪөҘёцНЁөАөДҫн»эКдіцҝЙТФ¶ЁТеОӘЈә
![]() (1)
(1)
ЖдЦРІЙСщәҜКэ![]() Ј¬јҙёщҫЭҫн»эәЛІЙСщіцҪшРРҫн»эІЩЧчөДМШХчөгЈ¬ФЪ№ЗјЬНјЦРГ¶ҫЩіцёГО»ЦГ
Ј¬јҙёщҫЭҫн»эәЛІЙСщіцҪшРРҫн»эІЩЧчөДМШХчөгЈ¬ФЪ№ЗјЬНјЦРГ¶ҫЩіцёГО»ЦГ![]() өДБЪҫУЎЈ¶шИЁЦШәҜКэ
өДБЪҫУЎЈ¶шИЁЦШәҜКэ![]() МṩҪшРРҫн»эөДИЁЦШПтБҝЈ¬УГАҙУлІЙСщіцөД
МṩҪшРРҫн»эөДИЁЦШПтБҝЈ¬УГАҙУлІЙСщіцөД![]() О¬МШХчПтБҝјЖЛгДЪ»эЎЈ
О¬МШХчПтБҝјЖЛгДЪ»эЎЈ
ФЪҝХУтНјҫн»эЦРЈ¬ҝХјдУтБЪҪУҫШХуОӘ![]() Ј¬ИфҪЪөг
Ј¬ИфҪЪөг![]() әН
әН![]() ЦұҪУПаБ¬Ј¬Фт
ЦұҪУПаБ¬Ј¬Фт![]() Ј¬ЖдУаОӘ0Ј»ТФҙЛАҙұнКҫҝХјдУтНјҪб№№Ј»
Ј¬ЖдУаОӘ0Ј»ТФҙЛАҙұнКҫҝХјдУтНјҪб№№Ј»
ЖдІЙСщәҜКэ![]() ҝЙРҙіЙЈә
ҝЙРҙіЙЈә
![]() (2)
(2)
ЖдЦР![]() ұнКҫ
ұнКҫ![]() өҪ
өҪ![]() өДЧо¶МВ·ҫ¶Ј¬ІОКэ
өДЧо¶МВ·ҫ¶Ј¬ІОКэ![]() ҝШЦЖЛщІЙСщөДБЪҫУНјөДҝХјд·¶О§ЎЈ
ҝШЦЖЛщІЙСщөДБЪҫУНјөДҝХјд·¶О§ЎЈ
ІўЗТУЙЙПКцЧчХЯҪ«БЪҫУ»®·ЦОӘ3ёцЧУНјЈ¬ІўЗТҪ«ГҝёцЧУНјЦРөДГҝёцҪЪөг![]() ·ЦұрНЁ№эУіЙдәҜКэ
·ЦұрНЁ№эУіЙдәҜКэ![]() УіЙдөҪЖдЧУјҜұкЗ©
УіЙдөҪЖдЧУјҜұкЗ©![]() Ј¬јҙҪ«БЪҪУҫШХу»®·ЦОӘ
Ј¬јҙҪ«БЪҪУҫШХу»®·ЦОӘ![]() Ўў
Ўў![]() әН
әН![]() Ј¬·ЦұрҙъұнёщҪЪөгЎўПтРДФЛ¶ҜМШХчҪЪөгәНАлРДФЛ¶ҜМШХчҪЪөгЈ»ФтЖдИЁЦШәҜКэ
Ј¬·ЦұрҙъұнёщҪЪөгЎўПтРДФЛ¶ҜМШХчҪЪөгәНАлРДФЛ¶ҜМШХчҪЪөгЈ»ФтЖдИЁЦШәҜКэ![]() ҝЙРҙОӘЈә
ҝЙРҙОӘЈә
![]() (3)
(3)
ТтҙЛЈ¬ФЪҝХјдУтЙПөДНјҫн»э№«КҪҝЙРҙОӘЈә
![]() (4)
(4)
Н¬АнЈ¬ФЪКұјдУтЦРЈ¬ЖдКұјдУтБЪҪУҫШХуОӘ![]() Ј¬УГАҙұнКҫБ¬РшЦЎЦ®јд№ШҪЪөД№мјЈЎЈ
Ј¬УГАҙұнКҫБ¬РшЦЎЦ®јд№ШҪЪөД№мјЈЎЈ
ЖдІЙСщәҜКэ![]() ҝЙРҙіЙЈә
ҝЙРҙіЙЈә
![]() (5)
(5)
ЖдЦР![]() ҝШЦЖКұјдУтҫн»эөДҫн»э·¶О§Ј¬јҙРиТӘҫЫәПөДКұјдіЯ¶ИЈ¬ІўЗТНЁ№эјтөҘөДУіЙдәҜКэ
ҝШЦЖКұјдУтҫн»эөДҫн»э·¶О§Ј¬јҙРиТӘҫЫәПөДКұјдіЯ¶ИЈ¬ІўЗТНЁ№эјтөҘөДУіЙдәҜКэ![]() Ј¬Ҫ«КұУтБЪҪУҫШХу»®·ЦОӘ
Ј¬Ҫ«КұУтБЪҪУҫШХу»®·ЦОӘ![]() ·ЭЈә
·ЭЈә![]() Ј»№КЖдИЁЦШәҜКэ
Ј»№КЖдИЁЦШәҜКэ![]() ҝЙРҙОӘЈә
ҝЙРҙОӘЈә
![]() (6)
(6)
ЛщТФЈ¬ФЪКұјдУтЙПөДҫн»э№«КҪҝЙРҙОӘЈә
![]() (7)
(7)
»щУЪЙПКцГиКцЈ¬ОТГЗҫНҝЙТФ№№ҪЁіцКұҝХУтНјҫн»эөДГчИ·өДҫн»эЛгЧУЎЈ
ОеЎўST-GCNНшВзКөПЦ
ФЪ№№ҪЁНкіЙКұҝХУтөДНјҫн»эЛгЧУЦ®әуЈ¬ҪУПВАҙЧчХЯұг№№ҪЁБЛҫЯМеКөПЦST-GCNөДҫЯМеКөПЦ·ҪКҪЈәБоКдИлМШХчНј![]() Ј¬ЖдЦР
Ј¬ЖдЦР![]() ·ЦұрұнКҫКдИлНЁөАКэЎў№ШјьЦЎЦЎКэәН№ШҪЪөгКэБҝЈ»ОӘКөПЦST-GCNЈ¬Фт№«КҪ(4)РтёДРҙОӘЈә
·ЦұрұнКҫКдИлНЁөАКэЎў№ШјьЦЎЦЎКэәН№ШҪЪөгКэБҝЈ»ОӘКөПЦST-GCNЈ¬Фт№«КҪ(4)РтёДРҙОӘЈә
![]() (8)
(8)
ЖдЦРЈә![]() ЦёөЪ
ЦёөЪ![]() ёц·ЦЗшөД№йТ»»ҜБЪҪУҫШХуЈ»ЗТ
ёц·ЦЗшөД№йТ»»ҜБЪҪУҫШХуЈ»ЗТ![]() ОӘ¶ИҫШХуЈ¬
ОӘ¶ИҫШХуЈ¬![]() ЙиЦГОӘ0.001Ј¬ұЬГвҝХРРЎЈ
ЙиЦГОӘ0.001Ј¬ұЬГвҝХРРЎЈ![]() КЗ
КЗ![]() ҫн»эФЛЛгөДҝЙСөБ·ИЁЦШПтБҝЎЈ
ҫн»эФЛЛгөДҝЙСөБ·ИЁЦШПтБҝЎЈ![]() КЗТ»ёцјтөҘөДЧўТвБҰСЪДӨҫШХуЈ¬ҙъұнГҝёц№ШҪЪөДЦШТӘРФЈ»
КЗТ»ёцјтөҘөДЧўТвБҰСЪДӨҫШХуЈ¬ҙъұнГҝёц№ШҪЪөДЦШТӘРФЈ»![]() ОӘөг»эІЩЧчЎЈ
ОӘөг»эІЩЧчЎЈ
¶ФУЪКұјдҫн»э¶шСФЈ¬Ждҫн»э№«КҪ(7)ҝЙёДРҙОӘЈә
![]() (9)
(9)
ЖдЦР![]() КЗҫн»эәЛҙуРЎОӘKtЎБ1
КЗҫн»эәЛҙуРЎОӘKtЎБ1![]() өД2Dҫн»эІЩЧчЎЈ
өД2Dҫн»эІЩЧчЎЈ
ФЪКөПЦST-GCNНшВзКұЈ¬ІОКэ![]() әН
әН![]() ·ЦұрЙиЦГОӘ1әН9Ј¬·ЦұрұнХчҝХјдёРКЬТ°әНКұјдёРКЬТ°өДҙуРЎЎЈИ»¶шХвБҪёцІОКэ¶јКЦ№ӨЙиЦГЈ¬І»ҪцИұ·ҰБй»оРФЈ¬»№К№өГДЈРНөДКұҝХёРКЬТ°¶јК®·ЦУРПЮЎЈ
·ЦұрЙиЦГОӘ1әН9Ј¬·ЦұрұнХчҝХјдёРКЬТ°әНКұјдёРКЬТ°өДҙуРЎЎЈИ»¶шХвБҪёцІОКэ¶јКЦ№ӨЙиЦГЈ¬І»ҪцИұ·ҰБй»оРФЈ¬»№К№өГДЈРНөДКұҝХёРКЬТ°¶јК®·ЦУРПЮЎЈ
БщЎўКөСй
1.КэҫЭјҜУлЖА№АұкЧј
ЈЁ1Ј©Kinetics-skeletonКэҫЭјҜЈә
ёГКэҫЭјҜ°ьә¬ҙУYouTubeјмЛчөДҙуФј300000ёцКУЖөЖ¬¶ОЎЈЗТ»®·Ц240000ёцКУЖөЖ¬¶ООӘСөБ·јҜЎў20000ёцКУЖөЖ¬¶ООӘСйЦӨјҜЎЈХвР©КУЖөәӯёЗБЛ¶аҙп400ёцИЛАа¶ҜЧчАаЈ¬ҙУИХіЈ»о¶ҜЎўМеУэіЎҫ°өҪёҙФУөД»Ҙ¶Ҝ¶ҜЧчЎЈГҝёцКУЖөЖ¬¶ОҙуФј10ГлЎЈёГКэҫЭјҜҪцМṩûУР№ЗјЬКэҫЭөДФӯКјКУЖөЖ¬¶ОЎЈ
ОӘБЛ»сөГ№ЗјЬКэҫЭЈ¬ЧчХЯКЧПИҪ«ЛщУРКУЖөөД·ЦұжВКөчХыОӘ340ЎБ256Ј¬ІўҪ«ЦЎЛЩВКЧӘ»»ОӘ30 FPSЎЈИ»әуЈ¬ЧчХЯК№УГOpenPoseЧЛМ¬№АјЖ№ӨҫЯАҙ№АјЖКУЖөЖ¬¶ОЦРөДГҝёцЦЎЙПөД18ёц№ШҪЪөДО»ЦГЎЈOpenPoseёшіцБЛПсЛШЧшұкПөЦРөД2DЧшұк(XЈ¬Y)әН18ёцИЛМе№ШҪЪөДЦГРЕ¶ИөГ·ЦЎЈТтҙЛЈ¬ЧчХЯК№УГТ»ёцФӘЧй(XЈ¬YЈ¬C)АҙұнКҫГҝёц№ШҪЪЈ¬Т»ёц№ЗјЬЦЎұ»јЗВјОӘТ»ёц18ФӘЧйөДКэЧйЎЈ¶ФУЪ¶аИЛЗйҝцЈ¬ЧчХЯФЪГҝёцЖ¬¶ОЦРСЎФсЖҪҫщБӘәПЦГРЕ¶ИЧоёЯөД2ёцИЛЎЈ
ЈЁ2Ј©NTU-RGB+DКэҫЭјҜЈә
ёГКэҫЭјҜ°ьә¬60ёц¶ҜЧчАаЦРөД56880ёцКУЖөСщұҫЎЈЖдЦРАпГжөД¶ҜЧчҝЙ·ЦОӘИэҙуАаЈәИХіЈ¶ҜЧчЎўҪ»»Ҙ¶ҜЧчәНТҪБЖЧҙҝцЈ»
ёГКэҫЭјҜ°ьә¬ГҝёцСщұҫөДRGB КУЖөЎўЙо¶ИНјРтБРЎў3D №ЗчАКэҫЭәНәмНв (IR) КУЖөЎЈІўУЙИэёц Kinect V2 Па»ъН¬КұІ¶»сЎЈЖдЦР3D №ЗчАКэҫЭ°ьә¬ГҝИЛ 25 ёцЙнМе№ШҪЪөД 3D Чшұк(X,Y,Z)Ј¬ЗТГҝёцКУЖөСщұҫЦРЦБ¶а°ьә¬БҪИЛөДЙнМе№ЗјЬЈ»
ЖдЦРёГКэҫЭјҜУөУРБҪёцЖАјЫЧјФтЈ¬¶ФУҰУЪБҪЦЦСөБ·јҜУлІвКФјҜ»®·ЦұкЧјЈә
Cross-Subject(X-Sub)Јә°ҙХХИЛОпIDАҙ»®·ЦСөБ·јҜәНІвКФјҜЈ¬СөБ·јҜ40320ёцСщұҫЈ¬ІвКФјҜ16560ёцСщұҫЈ¬ЖдЦРҪ«ИЛОпIDОӘ 1, 2, 4, 5, 8, 9, 13, 14, 15,16, 17, 18, 19, 25, 27, 28, 31, 34, 35, 38өД20ИЛЧчОӘСөБ·јҜЈ¬КЈУаөДЧчОӘІвКФјҜЈ»јҙСөБ·СщұҫАҙЧФТ»ёцСЭФұЧУјҜЈ¬¶шК№УГКЈУаСЭФұөДСщұҫҪшРРЖА№АЈ»
Cross-View(X-View)Јә°ҙПа»ъIDАҙ»®·ЦСөБ·јҜәНІвКФјҜЈ¬Па»ъ1ІЙјҜөДСщұҫЧчОӘІвКФјҜЈ¬Па»ъ2әН3өДСщұҫЧчОӘСөБ·јҜЈ¬СщұҫКэ·ЦұрОӘ18960әН37920ЎЈЖдЦРПа»ъөДЙиЦГ№жФтОӘЈәИэёцПа»ъЈ¬Па»ъөДҙ№ЦұёЯ¶И¶јКЗТ»СщөДЈ¬Л®ЖҪҪЗ¶И·ЦұрОӘ-45ЎгЎў0ЎгәН45ЎгЎЈ
2.КөСйҪб№ы
ИзНј4Ј¬Нј5ЛщКҫЈ¬·ЦұрST-GCNФЪKineticsәНNTU-RGB+DКэҫЭјҜЙПөД¶ҜЧчК¶ұрЧјИ·ВКЎЈ

Нј4 ST-GCNФЪKineticsКэҫЭјҜөДЧјИ·ВК

Нј5 ST-GCNФЪNTU-RGB+DКэҫЭјҜөДЧјИ·ВК
БщЎўЧЬҪбУлХ№Ны
ұҫОДЦчТӘМбіцБЛТ»ЦЦРВУұөД»щУЪ№ЗјЬөД¶ҜЧчК¶ұрДЈРНЈәКұҝХНјҫн»эНшВз(ST-GCN)ЎЈёГДЈРНФЪ№ЗјЬРтБРЙП№№ФмБЛТ»ЧйКұҝХНјҫн»эЎЈІўЗТФЪБҪёцҙу№жДЈКэҫЭјҜЙПЖдК¶ұрҫ«¶И¶јУЕУЪПЦУРөД»щУЪ№ЗјЬөДЛг·ЁЎЈ
ҙЛНвЈ¬ST-GCNЛщІ¶»сөД¶ҜМ¬№ЗјЬРтБРЦРөДФЛ¶ҜРЕПўУлRGBДЈМ¬өДКэҫЭРЕПўКЗ»ҘІ№өДЎЈЗТЧчОӘНјҫн»эФЪ№ЗјЬ¶ҜЧчК¶ұрИООсөДҝӘЙҪЦ®ЧчЈ¬ST-GCNДЈРНТІОӘОҙАҙөД№ӨЧчҝӘұЩБЛөАВ·ЎЈФЪҪ«АҙөДСРҫҝЦРЈ¬ИзәОҪ«іЎҫ°Ўў¶ФПуәНҪ»»ҘөИЙППВОДРЕПўИЪИлST-GCNКЗШҪҙэҪвҫцөДОКМвЎЈ
ЖЯЎўёДҪшУлЛјҝј
ХвЖӘВЫОДКЗПгёЫЦРҙу-ЙММАҝЖјјБӘәПКөСйКТYanөИИЛФЪ2018ДкAAAI »бТйЦР·ўұнөДВЫОД[2]ЎЈУЙУЪПИЗ°өД·Ҫ·ЁОЮ·ЁЦұҪУК№УГ№ЗјЬКэҫЭөДНјҪб№№Ј¬ЖдЦРКЧҙОУҰУГGCN¶Ф№ЗјЬКэҫЭҪшРРҪЁДЈЈ¬ёГДЈРНКЧПИТФ№ШҪЪОӘНјөД¶ҘөгЈ¬ТФИЛМеҪб№№әНКұјдөДЧФИ»БӘПөОӘНјөДұЯЈ¬№№ФмТ»ёцКұҝХНј[1]Ј¬Іў»щУЪҙЛНјҪшРРКұҝХҫн»эҙУ¶ш№№ҪЁіцКұҝХНјҫн»эНшВзЈ¬јтіЖОӘST-GCNЎЈST-GCNҝӘұЩБЛНјҫн»эФЪ¶ҜЧчК¶ұрУҰУГөДПИәУЈ¬јёәхЛщУРөД»щУЪGCNөД¶ҜЧчК¶ұрИООс¶ј»бІОҝјЖдЛјПлЎЈ
1. ST-GCNөДИұөг
ФЪЙПКцST-GCNНшВзДЈРНөДұнКцЦРЈ¬І»ДС·ўПЦЈ¬ЛдИ»ЖдУөУРРн¶аУЕөгЈ¬ө«КЗST-GCNөДИұөгТІК®·ЦГчПФЈә
ЎӨST-GCNЦРөДИЛМе№ЗјЬНјКЗИЛОӘКЦ№Ө¶ЁТеөДЈ¬ПЮЦЖәуГжөДНшВзС§П°өҪ№ЗјЬНјЦРөДұШТӘ№ШБӘУлРВҪЁБ¬ҪУЈ¬АэИзЈәФЪК¶ұрИзЎ°№ДХЖЎұЈ¬Ў°ФД¶БЎұөИУлИЛОӘКЦ№Ө¶ЁТеөДИЛМе№ЗјЬНјҝХјдЙППаҫаЙхФ¶өДЛ«КЦјдөД№ШПөЦБ№ШЦШТӘөД¶ҜЧчКұ[3]Ј¬НшВзәЬДСС§П°өҪЖдЦРөД№ШБӘЈ¬ТІәЬДС¶ФёГФӯұҫІ»ҙжФЪөДұЯҪшРРРВҪЁТФҪЁБўБ¬ҪУЈ¬әЬҙуіМ¶ИЙПҪөөНБЛ¶ҜЧчК¶ұрөДҫ«¶ИЈ»
ЎӨіэҙЛЦ®НвЈ¬ST-GCNЦРөДНшВзҪб№№КЗ·ЦІгҪб№№Ј¬ГҝТ»Іг¶јҙъұнБЛІ»Н¬ІгҙОөДУпТеРЕПў[4]Ј¬И»¶шЧчХЯЛщІЙУГөДКЗТ»ёцИ«ҫЦ№М¶ЁөДНшВзНШЖЛҪб№№НјЈ¬өјЦВёГНшВзОЮ·ЁБй»оөД¶ФёчІгЦРөДУпТеҪшРРҪЁДЈЈ¬ЗТУЙУЪ№М¶ЁөДИ«ҫЦНшВзНШЖЛҪб№№Ј¬ЖдёРКЬТ°Т°І»№»Бй»о[5]Ј¬ТІОЮ·ЁМбИЎ¶аіЯ¶ИөДРЕПў[6]Ј»
ЎӨST-GCNјЖЛгёҙФУ¶И№эёЯЈ¬ЗТУЙУЪНјҫн»эёчҪЪөгЦ®јдөДРЕПўПа»ҘҫЫәПЈ¬ҙ«Ніdropout¶ФЖдОЮР§Ј¬өјЦВ№эДвәП[7]Ј»
ёщҫЭҙЛПо№ӨЧчЈ¬Рн¶аҝЖСРИЛФұФЪҙЛ»щҙЎЙПЧцБЛҙуБҝөДПа№Ш№ӨЧчЈ¬УЙУЪКЦ№Ө¶ЁТеНјөДҫЦПЮРФЈ¬2s-AGCNУлMS-AAGCNТэИлБЛ¶аЦЦЧФККУҰөДНШЖЛНјЈ¬¶ш¶ФУЪ·ЦІгҪб№№Ј¬ОӘ·Ҫұг¶ФёчІгУпТеҪшРРҪЁДЈЈ¬SGCNМбіцБЛТ»ёцНЁөАИЪәПДЈҝй (CAMM)Ј»ЧоәуУЙУЪёЯјЖЛгёҙФУ¶ИshiftGCNҪ«shiftІЩЧчТэИлНјҫн»эҙъМжҫн»эөДМШХчИЪәПІЩЧчЈ¬іэҙЛЦ®НвDC-GCN_ADGМбіцБЛDC-GCNЈЁDeCoupling Graph Convolutional NetworkЈ©Нјҫн»эНшВзЈ¬ҝЙТФФЪІ»ФцјУјЖЛгБҝөДН¬КұФцЗҝНјҫн»эөДұнҙпДЬБҰЈ¬ІўМбіцБЛADGЈЁattention-guided DropGraphЈ©ИЎҙъФӯКјdropoutЈ¬ҪвҫцБЛНјҫн»э№эДвәПөДОКМвЎЈ
°ЛЎўІОҝјОДПЧ
[1] Ren, B. , Liu, M. , Ding, R. , & Liu, H. . (2020). A survey on 3d skeleton-based action recognition using learning method.
[2] Sijie Yan, Yuanjun Xiong, and Dahua Lin. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In AAAI, 2018.
[3] Lei Shi, Yifan Zhang, Jian Cheng, and Hanqing Lu. Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition. In CVPR, 2019.
[4] W. Yang, J. Zhang, J. Cai, and Z. Xu, "Shallow Graph Convolutional Network for Skeleton-Based Action Recognition," Sensors (Basel), vol. 21, no. 2, Jan 11 2021, doi: 10.3390/s21020452.
[5] Ke Cheng, Yifan Zhang, Xiangyu He, Weihan Chen, Jian Cheng, and Hanqing Lu. Skeleton-Based Action Recognition with Shift Graph Convolutional Network. In CVPR, 2020.
[6] H. Xia and X. Gao, "Multi-Scale Mixed Dense Graph Convolution Network for Skeleton-Based Action Recognition," IEEE Access, vol. 9, pp. 36475-36484, 2021, doi: 10.1109/access.2020.3049029.
[7] K. Cheng, Y. Zhang, C. Cao, L. Shi, J. Cheng and H. Lu. Decoupling GCN with DropGraph Module for Skeleton-Based Action Recognition. In ECCV, 2020.
ҫЕЎўST-GCNЦРНјҫн»эКөПЦҪІҪв
ФҙҙъВлБҙҪУЈәGitHub - yysijie/st-gcn: Spatial Temporal Graph Convolutional Networks (ST-GCN) for Skeleton-Based Action Recognition in PyTorch![]() https://github.com/yysijie/st-gcn
https://github.com/yysijie/st-gcn
ЧўТвЈ¬ұҫІҝ·ЦЦ»ЧЕЦШҪйЙЬНјҫн»эөДКөПЦІЩЧчІҝ·ЦЈ¬¶аУРІ»И«ГжЦ®ҙҰЎЈТтҙЛұҫІҝ·ЦөДҪІҪвККәПУЪ¶БХЯПИСРҫҝФҙҙъВлИ»әуЕдәПХвІҝ·ЦөДДЪИЭ°пЦъАнҪвөДЧчУГЎЈ
КЧПИ¶ФУЪKinetics-skeletonКэҫЭјҜАҙЛөЈ¬ST-GCNГҝІгНшВзөДКдіцИзПВЈЁІОҝјБЛЦӘәхЧчХЯЈә
ЧчХЯЈәИХЦӘ
БҙҪУЈәhttps://www.zhihu.com/question/276101856/answer/638672980
АҙФҙЈәЦӘәхЈ©
Ў° # N*M(256*2)/C(3)/T(150)/V(18)
InputЈә[512, 3, 150, 18]
ST-GCN-1Јә[512, 64, 150, 18]
ST-GCN-2Јә[512, 64, 150, 18]
ST-GCN-3Јә[512, 64, 150, 18]
ST-GCN-4Јә[512, 64, 150, 18]
ST-GCN-5Јә[512, 128, 75, 18]
ST-GCN-6Јә[512, 128, 75, 18]
ST-GCN-7Јә[512, 128, 75, 18]
ST-GCN-8Јә[512, 256, 38, 18]
ST-GCN-9Јә[512, 256, 38, 18]
ҝХјдО¬¶ИКЗ№ШҪЪөДМШХчЈЁҝӘКјОӘ 3Ј©Ј¬КұјдөДО¬¶ИКЗ№ШјьЦЎКэЈЁҝӘКјОӘ 150Ј©ЎЈФЪҫӯ№эЛщУР ST-GCN өҘФӘөДКұҝХҫн»эә󣬹ШҪЪөДМШХчО¬¶ИФцјУөҪ 256Ј¬№ШјьЦЎО¬¶ИҪөөНөҪ 38ЎЈ
ёцИЛёРҫхХвСщЙијЖКЗТтОӘЈ¬ИЛөД¶ҜЧчҪЧ¶ОІўІ»¶аЈ¬ө«КЗГҝёцҪЧ¶ОДЪөД¶ҜЧчұИҪПёҙФУЎЈұИИзЈ¬Т»ёц»УёЯ¶ы·тЗтёЛөД¶ҜЧчҝЙДЬЦ»РиТӘ·ЦҪвОӘ 5 ІҪЈ¬ө«КЗГҝТ»ІҪөДКЦІҝЎўСьІҝәНҪЕІҝ¶ҜЧчТӘЗуИҙұИҪП¶аЎЈЎұ
ФӯҙъВлДЈРНОӘЈә
ЖдЦРst_gcnЦРЦчТӘ°ьә¬gcnәНtcnөДІҝ·ЦЎЈХвАпЦчТӘҪйЙЬұИҪП

¶шConvTemporalGraphicalөДinitОӘЈә

¶шConvTemporalGraphicalөДforwardәҜКэОӘЈәЈЁХвАпҫНКЗХжХэҪшРРНјҫн»эІЩЧчөДІҝ·ЦЈ¬·Цұр¶ФУҰУЪ№«КҪЈә
ЧўТвЈәЖдКөST-GCNЦРөДНјҫн»э№«КҪҝЙТФјт»ҜөШРҙіЙЈәZ = AЎҜ XWЈ»
ЖдЦРZОӘНјҫн»эөДКдіцЈ¬XОӘНјҫн»эөДКдИлЈ¬AЎҜОӘ№йТ»»ҜәуөДБЪҪУҫШХуЎЈ
ФЪұҫҙъВлЦРЙПКц№«КҪҝЙ·ЦОӘБҪёцІҪЦиЈЁ¶ФУҰУЪПВГжҙъВлЧўКНІҝ·ЦөДБҪёцІҪЦиЈ©Јә
ІҪЦиТ»ЎўёьРВРЕПўЈәZ1 = XW
ІҪЦи¶юЎўҫЫјҜБмУтРЕПўЈәZ = AЎҜZ1
ТэЙкЈәЖдКөТ»°гНјҫн»эІЩЧч¶јКЗПИҪшРРБЪУтРЕПўҫЫјҜЦ®әуФЩёьРВөДЈ¬ХвАпST-GCNҙъВлУлЖдІ»Т»ЦВЎЈ
Ј©

ХвАпҫНКЗ¶ФЙПНјҙъВлЦРНјҫн»эІЩЧчөДТ»ёцИ«ҫЦёЕКцЎЈХвІҝ·ЦКЗЧФјәУГipadКЦРҙ»ӯөДНјЈ¬І»М«әГҝҙЈ¬ЗлҙујТ¶а¶а°ьәӯЎЈ


І©ОДІОҝјЈә
ЧчХЯЈәИХЦӘ
БҙҪУЈәhttps://www.zhihu.com/question/276101856/answer/638672980
АҙФҙЈәЦӘәх