�ο�
���İ�������Դ��ͽ��⣬ͨ������ͺ��߷ָ��˸���ģ�飬ͬʱ��վ�䱸�˲��������������ڸ���С���п�����ת��ϣ������Ķ����ܶ�BERT����̵��˽⡣ͬʱ����ͨ��pycharm��vscode�ȹ��߶�bertԴ����е������ԣ����Ե���Ӧ��ģ���ٶԱȿ����½ڵĽ��⡣
��ƪ�½�����HHuggingFace/Transformers, 48.9k Star����ѧϰ�����½ڵ�ȫ��������huggingface bert��ע�����ڰ汾���½Ͽ죬���ܴ��ڲ������4.4.2�汾ΪHuggingFace ��һ���ܲ�λ��ŦԼ����������˳��������̣�����Ͳ��� BERT �������źŲ�����ʵ�ֻ��� pytorch �� BERT ģ�͡���һ��Ŀ�����Ϊ pytorch-pretrained-bert���ڸ�����ԭʼЧ����ͬʱ���ṩ�����õķ����Է�������һǿ��ģ�͵Ļ����Ͻ��и�����ˣ���о���
����ʹ�����������ӣ���һ��ĿҲ��չ��Ϊһ���ϴ�Ŀ�Դ�������ϲ��˸���Ԥѵ������ģ���Լ������� Tensorflow ��ʵ�֣������� 2019 ���°������Ϊ Transformers����ֹд����ʱ��2021 �� 3 �� 30 �գ���һ��Ŀ�Ѿ�ӵ�� 43k+ ��star������˵ Transformers �Ѿ���Ϊ��ʵ�ϵ� NLP �������ߡ�

ͼ��BERT�ṹ����ԴIrEne: Interpretable Energy Prediction for Transformers
���Ļ��� Transformers �汾 4.4.2��2021 �� 3 �� 19 �շ�������Ŀ�У�pytorch ��� BERT ��ش��룬�Ӵ���ṹ������ʵ����ԭ�����Լ�ʹ�õĽǶȽ��з�����
��Ҫ�������ݣ�
- BERT Tokenization �ִ�ģ�ͣ�BertTokenizer��
- BERT Model ����ģ�ͣ�BertModel��
- BertEmbeddings
- BertEncoder
- BertLayer
- BertAttention
- BertIntermediate
- BertOutput
- BertPooler
- BertLayer
1-Tokenization�ִ�-BertTokenizer
��BERT �йص� Tokenizer ��Ҫд��models/bert/tokenization_bert.py�С�
import collections
import os
import unicodedata
from typing import List, Optional, Tuplefrom transformers.tokenization_utils import PreTrainedTokenizer, _is_control, _is_punctuation, _is_whitespace
from transformers.utils import logginglogger = logging.get_logger(__name__)VOCAB_FILES_NAMES = {
"vocab_file": "vocab.txt"}PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"bert-base-uncased": "https://huggingface.co/bert-base-uncased/resolve/main/vocab.txt",}
}PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"bert-base-uncased": 512,
}PRETRAINED_INIT_CONFIGURATION = {
"bert-base-uncased": {
"do_lower_case": True},
}def load_vocab(vocab_file):"""Loads a vocabulary file into a dictionary."""vocab = collections.OrderedDict()with open(vocab_file, "r", encoding="utf-8") as reader:tokens = reader.readlines()for index, token in enumerate(tokens):token = token.rstrip("\n")vocab[token] = indexreturn vocabdef whitespace_tokenize(text):"""Runs basic whitespace cleaning and splitting on a piece of text."""text = text.strip()if not text:return []tokens = text.split()return tokensclass BertTokenizer(PreTrainedTokenizer):vocab_files_names = VOCAB_FILES_NAMESpretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAPpretrained_init_configuration = PRETRAINED_INIT_CONFIGURATIONmax_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZESdef __init__(self,vocab_file,do_lower_case=True,do_basic_tokenize=True,never_split=None,unk_token="[UNK]",sep_token="[SEP]",pad_token="[PAD]",cls_token="[CLS]",mask_token="[MASK]",tokenize_chinese_chars=True,strip_accents=None,**kwargs):super().__init__(do_lower_case=do_lower_case,do_basic_tokenize=do_basic_tokenize,never_split=never_split,unk_token=unk_token,sep_token=sep_token,pad_token=pad_token,cls_token=cls_token,mask_token=mask_token,tokenize_chinese_chars=tokenize_chinese_chars,strip_accents=strip_accents,**kwargs,)if not os.path.isfile(vocab_file):raise ValueError(f"Can't find a vocabulary file at path '{vocab_file}'. To load the vocabulary from a Google pretrained ""model use `tokenizer = BertTokenizer.from_pretrained(PRETRAINED_MODEL_NAME)`")self.vocab = load_vocab(vocab_file)self.ids_to_tokens = collections.OrderedDict([(ids, tok) for tok, ids in self.vocab.items()])self.do_basic_tokenize = do_basic_tokenizeif do_basic_tokenize:self.basic_tokenizer = BasicTokenizer(do_lower_case=do_lower_case,never_split=never_split,tokenize_chinese_chars=tokenize_chinese_chars,strip_accents=strip_accents,)self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab, unk_token=self.unk_token)@propertydef do_lower_case(self):return self.basic_tokenizer.do_lower_case@propertydef vocab_size(self):return len(self.vocab)def get_vocab(self):return dict(self.vocab, **self.added_tokens_encoder)def _tokenize(self, text):split_tokens = []if self.do_basic_tokenize:for token in self.basic_tokenizer.tokenize(text, never_split=self.all_special_tokens):# If the token is part of the never_split setif token in self.basic_tokenizer.never_split:split_tokens.append(token)else:split_tokens += self.wordpiece_tokenizer.tokenize(token)else:split_tokens = self.wordpiece_tokenizer.tokenize(text)return split_tokensdef _convert_token_to_id(self, token):"""Converts a token (str) in an id using the vocab."""return self.vocab.get(token, self.vocab.get(self.unk_token))def _convert_id_to_token(self, index):"""Converts an index (integer) in a token (str) using the vocab."""return self.ids_to_tokens.get(index, self.unk_token)def convert_tokens_to_string(self, tokens):"""Converts a sequence of tokens (string) in a single string."""out_string = " ".join(tokens).replace(" ##", "").strip()return out_stringdef build_inputs_with_special_tokens(self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None) -> List[int]:"""Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating andadding special tokens. A BERT sequence has the following format:- single sequence: ``[CLS] X [SEP]``- pair of sequences: ``[CLS] A [SEP] B [SEP]``Args:token_ids_0 (:obj:`List[int]`):List of IDs to which the special tokens will be added.token_ids_1 (:obj:`List[int]`, `optional`):Optional second list of IDs for sequence pairs.Returns::obj:`List[int]`: List of `input IDs <../glossary.html#input-ids>`__ with the appropriate special tokens."""if token_ids_1 is None:return [self.cls_token_id] + token_ids_0 + [self.sep_token_id]cls = [self.cls_token_id]sep = [self.sep_token_id]return cls + token_ids_0 + sep + token_ids_1 + sepdef get_special_tokens_mask(self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False) -> List[int]:"""Retrieve sequence ids from a token list that has no special tokens added. This method is called when addingspecial tokens using the tokenizer ``prepare_for_model`` method.Args:token_ids_0 (:obj:`List[int]`):List of IDs.token_ids_1 (:obj:`List[int]`, `optional`):Optional second list of IDs for sequence pairs.already_has_special_tokens (:obj:`bool`, `optional`, defaults to :obj:`False`):Whether or not the token list is already formatted with special tokens for the model.Returns::obj:`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token."""if already_has_special_tokens:return super().get_special_tokens_mask(token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True)if token_ids_1 is not None:return [1] + ([0] * len(token_ids_0)) + [1] + ([0] * len(token_ids_1)) + [1]return [1] + ([0] * len(token_ids_0)) + [1]def create_token_type_ids_from_sequences(self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None) -> List[int]:"""Create a mask from the two sequences passed to be used in a sequence-pair classification task. A BERT sequencepair mask has the following format:::0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1| first sequence | second sequence |If :obj:`token_ids_1` is :obj:`None`, this method only returns the first portion of the mask (0s).Args:token_ids_0 (:obj:`List[int]`):List of IDs.token_ids_1 (:obj:`List[int]`, `optional`):Optional second list of IDs for sequence pairs.Returns::obj:`List[int]`: List of `token type IDs <../glossary.html#token-type-ids>`_ according to the givensequence(s)."""sep = [self.sep_token_id]cls = [self.cls_token_id]if token_ids_1 is None:return len(cls + token_ids_0 + sep) * [0]return len(cls + token_ids_0 + sep) * [0] + len(token_ids_1 + sep) * [1]def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:index = 0if os.path.isdir(save_directory):vocab_file = os.path.join(save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"])else:vocab_file = (filename_prefix + "-" if filename_prefix else "") + save_directorywith open(vocab_file, "w", encoding="utf-8") as writer:for token, token_index in sorted(self.vocab.items(), key=lambda kv: kv[1]):if index != token_index:logger.warning(f"Saving vocabulary to {vocab_file}: vocabulary indices are not consecutive."" Please check that the vocabulary is not corrupted!")index = token_indexwriter.write(token + "\n")index += 1return (vocab_file,)class BasicTokenizer(object):def __init__(self, do_lower_case=True, never_split=None, tokenize_chinese_chars=True, strip_accents=None):if never_split is None:never_split = []self.do_lower_case = do_lower_caseself.never_split = set(never_split)self.tokenize_chinese_chars = tokenize_chinese_charsself.strip_accents = strip_accentsdef tokenize(self, text, never_split=None):"""Basic Tokenization of a piece of text. Split on "white spaces" only, for sub-word tokenization, seeWordPieceTokenizer.Args:**never_split**: (`optional`) list of strKept for backward compatibility purposes. Now implemented directly at the base class level (see:func:`PreTrainedTokenizer.tokenize`) List of token not to split."""# union() returns a new set by concatenating the two sets.never_split = self.never_split.union(set(never_split)) if never_split else self.never_splittext = self._clean_text(text)# This was added on November 1st, 2018 for the multilingual and Chinese# models. This is also applied to the English models now, but it doesn't# matter since the English models were not trained on any Chinese data# and generally don't have any Chinese data in them (there are Chinese# characters in the vocabulary because Wikipedia does have some Chinese# words in the English Wikipedia.).if self.tokenize_chinese_chars:text = self._tokenize_chinese_chars(text)orig_tokens = whitespace_tokenize(text)split_tokens = []for token in orig_tokens:if token not in never_split:if self.do_lower_case:token = token.lower()if self.strip_accents is not False:token = self._run_strip_accents(token)elif self.strip_accents:token = self._run_strip_accents(token)split_tokens.extend(self._run_split_on_punc(token, never_split))output_tokens = whitespace_tokenize(" ".join(split_tokens))return output_tokensdef _run_strip_accents(self, text):"""Strips accents from a piece of text."""text = unicodedata.normalize("NFD", text)output = []for char in text:cat = unicodedata.category(char)if cat == "Mn":continueoutput.append(char)return "".join(output)def _run_split_on_punc(self, text, never_split=None):"""Splits punctuation on a piece of text."""if never_split is not None and text in never_split:return [text]chars = list(text)i = 0start_new_word = Trueoutput = []while i < len(chars):char = chars[i]if _is_punctuation(char):output.append([char])start_new_word = Trueelse:if start_new_word:output.append([])start_new_word = Falseoutput[-1].append(char)i += 1return ["".join(x) for x in output]def _tokenize_chinese_chars(self, text):"""Adds whitespace around any CJK character."""output = []for char in text:cp = ord(char)if self._is_chinese_char(cp):output.append(" ")output.append(char)output.append(" ")else:output.append(char)return "".join(output)def _is_chinese_char(self, cp):"""Checks whether CP is the codepoint of a CJK character."""# This defines a "chinese character" as anything in the CJK Unicode block:# https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)## Note that the CJK Unicode block is NOT all Japanese and Korean characters,# despite its name. The modern Korean Hangul alphabet is a different block,# as is Japanese Hiragana and Katakana. Those alphabets are used to write# space-separated words, so they are not treated specially and handled# like the all of the other languages.if ((cp >= 0x4E00 and cp <= 0x9FFF)or (cp >= 0x3400 and cp <= 0x4DBF) #or (cp >= 0x20000 and cp <= 0x2A6DF) #or (cp >= 0x2A700 and cp <= 0x2B73F) #or (cp >= 0x2B740 and cp <= 0x2B81F) #or (cp >= 0x2B820 and cp <= 0x2CEAF) #or (cp >= 0xF900 and cp <= 0xFAFF)or (cp >= 0x2F800 and cp <= 0x2FA1F) #): #return Truereturn Falsedef _clean_text(self, text):"""Performs invalid character removal and whitespace cleanup on text."""output = []for char in text:cp = ord(char)if cp == 0 or cp == 0xFFFD or _is_control(char):continueif _is_whitespace(char):output.append(" ")else:output.append(char)return "".join(output)class WordpieceTokenizer(object):"""Runs WordPiece tokenization."""def __init__(self, vocab, unk_token, max_input_chars_per_word=100):self.vocab = vocabself.unk_token = unk_tokenself.max_input_chars_per_word = max_input_chars_per_worddef tokenize(self, text):"""Tokenizes a piece of text into its word pieces. This uses a greedy longest-match-first algorithm to performtokenization using the given vocabulary.For example, :obj:`input = "unaffable"` wil return as output :obj:`["un", "##aff", "##able"]`.Args:text: A single token or whitespace separated tokens. This should havealready been passed through `BasicTokenizer`.Returns:A list of wordpiece tokens."""output_tokens = []for token in whitespace_tokenize(text):chars = list(token)if len(chars) > self.max_input_chars_per_word:output_tokens.append(self.unk_token)continueis_bad = Falsestart = 0sub_tokens = []while start < len(chars):end = len(chars)cur_substr = Nonewhile start < end:substr = "".join(chars[start:end])if start > 0:substr = "##" + substrif substr in self.vocab:cur_substr = substrbreakend -= 1if cur_substr is None:is_bad = Truebreaksub_tokens.append(cur_substr)start = endif is_bad:output_tokens.append(self.unk_token)else:output_tokens.extend(sub_tokens)return output_tokens
class BertTokenizer(PreTrainedTokenizer):"""Construct a BERT tokenizer. Based on WordPiece.This tokenizer inherits from :class:`~transformers.PreTrainedTokenizer` which contains most of the main methods.Users should refer to this superclass for more information regarding those methods...."""
BertTokenizer �ǻ���BasicTokenizer��WordPieceTokenizer�ķִ�����
- BasicTokenizer�������ĵ�һ����������㡢�ո�ȷָ���ӣ��������Ƿ�ͳһСд���Լ������Ƿ��ַ���
- ���������ַ���ͨ��Ԥ�������ӿո������ַָ
- ͬʱ����ͨ��never_splitָ����ijЩ�ʲ����зָ
- ��һ���ǿ�ѡ�ģ�Ĭ��ִ�У���
- WordPieceTokenizer�ڴʵĻ����ϣ���һ�����ʷֽ�Ϊ�Ӵʣ�subword����
- subword ���� char �� word ֮�䣬����һ���̶ȱ����˴ʵĺ��壬���ܹ��չ˵�Ӣ���е�������ʱ̬���µĴʱ���ը��δ��¼�ʵ� OOV��Out-Of-Vocabulary�����⣬���ʸ���ʱ̬���ȷָ�������Ӷ���С�ʱ���Ҳ������ѵ���Ѷȣ�
- ���磬tokenizer ����ʾͿ��Բ��Ϊ��token���͡�##izer�������֣�ע�����һ���ʵġ�##����ʾ����ǰһ���ʺ��档
BertTokenizer �����³��÷�����
- from_pretrained���Ӱ����ʱ��ļ���vocab.txt����Ŀ¼�г�ʼ��һ���ִ�����
- tokenize�����ı����ʻ��߾��ӣ��ֽ�Ϊ�Ӵ��б���
- convert_tokens_to_ids�����Ӵ��б�ת��Ϊ�Ӵʶ�Ӧ�±���б���
- convert_ids_to_tokens ������һ���෴��
- convert_tokens_to_string���� subword �б�����##��ƴ�ӻشʻ��߾��ӣ�
- encode�����ڵ����������룬�ֽ�ʲ�����������γɡ�[CLS], x, [SEP]���Ľṹ��ת��Ϊ�ʱ���Ӧ�±���б������������������루�������ֻȡǰ���������ֽ�ʲ�����������γɡ�[CLS], x1, [SEP], x2, [SEP]���Ľṹ��ת��Ϊ�±��б���
- decode�����Խ� encode �����������Ϊ�������ӡ�
�Լ����������ķ�����
bt = BertTokenizer.from_pretrained('bert-base-uncased')
bt('I like natural language progressing!')
# {
'input_ids': [101, 1045, 2066, 3019, 2653, 27673, 999, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
Downloading: 100%|��������������������| 232k/232k [00:00<00:00, 698kB/s]
Downloading: 100%|��������������������| 28.0/28.0 [00:00<00:00, 11.1kB/s]
Downloading: 100%|��������������������| 466k/466k [00:00<00:00, 863kB/s]
{
'input_ids': [101, 1045, 2066, 3019, 2653, 27673, 999, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
2-Model-BertModel
�� BERT ģ���йصĴ�����Ҫд��/models/bert/modeling_bert.py�У���һ�ݴ�����һǧ���У����� BERT ģ�͵Ļ����ṹ�ͻ���������ģ�͵ȡ�
����� BERT ģ�ͱ������ַ�����
class BertModel(BertPreTrainedModel):"""The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer ofcross-attention is added between the self-attention layers, following the architecture described in `Attention isall you need <https://arxiv.org/abs/1706.03762>`__ by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.To behave as an decoder the model needs to be initialized with the :obj:`is_decoder` argument of the configurationset to :obj:`True`. To be used in a Seq2Seq model, the model needs to initialized with both :obj:`is_decoder`argument and :obj:`add_cross_attention` set to :obj:`True`; an :obj:`encoder_hidden_states` is then expected as aninput to the forward pass."""
BertModel ��ҪΪ transformer encoder �ṹ�������������֣�
- embeddings����BertEmbeddings���ʵ�壬���ݵ��ʷ��Ż�ȡ��Ӧ��������ʾ��
- encoder����BertEncoder���ʵ�壻
- pooler����BertPooler���ʵ�壬��һ�����ǿ�ѡ�ġ�
ע�� BertModel Ҳ��������Ϊ Decoder�����������в���������һ���ֵ����ۡ�
���潫���� BertModel ��ǰ�������и��������ĺ����Լ�����ֵ��
def forward(self,input_ids=None,attention_mask=None,token_type_ids=None,position_ids=None,head_mask=None,inputs_embeds=None,encoder_hidden_states=None,encoder_attention_mask=None,past_key_values=None,use_cache=None,output_attentions=None,output_hidden_states=None,return_dict=None,): ...
- input_ids������ tokenizer �ִʺ�� subword ��Ӧ���±��б���
- attention_mask���� self-attention �����У���һ�� mask ���ڱ�� subword �������Ӻ� padding �����𣬽� padding �������Ϊ 0��
- token_type_ids����� subword ��ǰ�������ӣ���һ��/�ڶ���/ padding����
- position_ids����ǵ�ǰ�����ھ��ӵ�λ���±ꣻ
- head_mask�����ڽ�ijЩ���ijЩע����������Ч����
- inputs_embeds������ṩ�ˣ��ǾͲ���Ҫinput_ids����� embedding lookup ����ֱ����Ϊ Embedding ���� Encoder ���㣻
- encoder_hidden_states����һ������ BertModel ����Ϊ decoder ʱ�����ã���ִ�� cross-attention ������ self-attention��
- encoder_attention_mask��ͬ�ϣ��� cross-attention �����ڱ�� encoder ������� padding��
- past_key_values���������ò���ǰ�Ԥ�ȼ���õ� K-V �˻����룬�Խ��� cross-attention �Ŀ�������Ϊԭ���ⲿ�����ظ����㣩��
- use_cache����������һ�����������أ����� decoding��
- output_attentions���Ƿ��м�ÿ��� attention �����
- output_hidden_states���Ƿ��м�ÿ��������
- return_dict���Ƿ�ֵ�Ե���ʽ��ModelOutput �࣬Ҳ���Ե��� tuple �ã����������Ĭ��Ϊ�档
ע�⣬����� head_mask ��ע�����������Ч�����������ᵽ��ע����ͷ��֦��ͬ����������ijЩע�����ļ�������������һϵ����
����������£�
# BertModel��ǰ�����ز���if not return_dict:return (sequence_output, pooled_output) + encoder_outputs[1:]return BaseModelOutputWithPoolingAndCrossAttentions(last_hidden_state=sequence_output,pooler_output=pooled_output,past_key_values=encoder_outputs.past_key_values,hidden_states=encoder_outputs.hidden_states,attentions=encoder_outputs.attentions,cross_attentions=encoder_outputs.cross_attentions,)
���Կ���������ֵ���������� encoder �� pooler �������Ҳ����������ָ������IJ��֣�hidden_states �� attention �ȣ���һ������encoder_outputs[1:]������ȡ�ã�
# BertEncoder��ǰ�����ز��֣��������encoder_outputsif not return_dict:return tuple(vfor v in [hidden_states,next_decoder_cache,all_hidden_states,all_self_attentions,all_cross_attentions,]if v is not None)return BaseModelOutputWithPastAndCrossAttentions(last_hidden_state=hidden_states,past_key_values=next_decoder_cache,hidden_states=all_hidden_states,attentions=all_self_attentions,cross_attentions=all_cross_attentions,)
���⣬BertModel �������µķ��������� BERT ��ҽ��и��ֲ�����
- get_input_embeddings����ȡ embedding �е� word_embeddings �����������֣�
- set_input_embeddings��Ϊ embedding �е� word_embeddings ��ֵ��
- _prune_heads���ṩ�˽�ע����ͷ��֦�ĺ���������Ϊ{layer_num: list of heads to prune in this layer}���ֵ䣬���Խ�ָ�����ijЩע����ͷ��֦��
** ��֦��һ�����ӵIJ�������Ҫ��������ע����ͷ���ֵ� Wq��Kq��Vq ��ƴ�Ӻ�ȫ���Ӳ��ֵ�Ȩ�ؿ�����һ���µĽ�С��Ȩ�ؾ���ע���Ƚ�ֹ grad �ٿ���������ʵʱ��¼��������ͷ�Է��±����������ο�BertAttention���ֵ�prune_heads����.**
from transformers.models.bert.modeling_bert import *
class BertModel(BertPreTrainedModel):"""The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer ofcross-attention is added between the self-attention layers, following the architecture described in `Attention isall you need <https://arxiv.org/abs/1706.03762>`__ by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.To behave as an decoder the model needs to be initialized with the :obj:`is_decoder` argument of the configurationset to :obj:`True`. To be used in a Seq2Seq model, the model needs to initialized with both :obj:`is_decoder`argument and :obj:`add_cross_attention` set to :obj:`True`; an :obj:`encoder_hidden_states` is then expected as aninput to the forward pass."""def __init__(self, config, add_pooling_layer=True):super().__init__(config)self.config = configself.embeddings = BertEmbeddings(config)self.encoder = BertEncoder(config)self.pooler = BertPooler(config) if add_pooling_layer else Noneself.init_weights()def get_input_embeddings(self):return self.embeddings.word_embeddingsdef set_input_embeddings(self, value):self.embeddings.word_embeddings = valuedef _prune_heads(self, heads_to_prune):"""Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See baseclass PreTrainedModel"""for layer, heads in heads_to_prune.items():self.encoder.layer[layer].attention.prune_heads(heads)@add_start_docstrings_to_model_forward(BERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))@add_code_sample_docstrings(tokenizer_class=_TOKENIZER_FOR_DOC,checkpoint=_CHECKPOINT_FOR_DOC,output_type=BaseModelOutputWithPoolingAndCrossAttentions,config_class=_CONFIG_FOR_DOC,)def forward(self,input_ids=None,attention_mask=None,token_type_ids=None,position_ids=None,head_mask=None,inputs_embeds=None,encoder_hidden_states=None,encoder_attention_mask=None,past_key_values=None,use_cache=None,output_attentions=None,output_hidden_states=None,return_dict=None,):r"""encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention ifthe model is configured as a decoder.encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used inthe cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:- 1 for tokens that are **not masked**,- 0 for tokens that are **masked**.past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`(those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`.use_cache (:obj:`bool`, `optional`):If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed updecoding (see :obj:`past_key_values`)."""output_attentions = output_attentions if output_attentions is not None else self.config.output_attentionsoutput_hidden_states = (output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states)return_dict = return_dict if return_dict is not None else self.config.use_return_dictif self.config.is_decoder:use_cache = use_cache if use_cache is not None else self.config.use_cacheelse:use_cache = Falseif input_ids is not None and inputs_embeds is not None:raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")elif input_ids is not None:input_shape = input_ids.size()batch_size, seq_length = input_shapeelif inputs_embeds is not None:input_shape = inputs_embeds.size()[:-1]batch_size, seq_length = input_shapeelse:raise ValueError("You have to specify either input_ids or inputs_embeds")device = input_ids.device if input_ids is not None else inputs_embeds.device# past_key_values_lengthpast_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0if attention_mask is None:attention_mask = torch.ones(((batch_size, seq_length + past_key_values_length)), device=device)if token_type_ids is None:if hasattr(self.embeddings, "token_type_ids"):buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)token_type_ids = buffered_token_type_ids_expandedelse:token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]# ourselves in which case we just need to make it broadcastable to all heads.extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape, device)# If a 2D or 3D attention mask is provided for the cross-attention# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]if self.config.is_decoder and encoder_hidden_states is not None:encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)if encoder_attention_mask is None:encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)else:encoder_extended_attention_mask = None# Prepare head mask if needed# 1.0 in head_mask indicate we keep the head# attention_probs has shape bsz x n_heads x N x N# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)embedding_output = self.embeddings(input_ids=input_ids,position_ids=position_ids,token_type_ids=token_type_ids,inputs_embeds=inputs_embeds,past_key_values_length=past_key_values_length,)encoder_outputs = self.encoder(embedding_output,attention_mask=extended_attention_mask,head_mask=head_mask,encoder_hidden_states=encoder_hidden_states,encoder_attention_mask=encoder_extended_attention_mask,past_key_values=past_key_values,use_cache=use_cache,output_attentions=output_attentions,output_hidden_states=output_hidden_states,return_dict=return_dict,)sequence_output = encoder_outputs[0]pooled_output = self.pooler(sequence_output) if self.pooler is not None else Noneif not return_dict:return (sequence_output, pooled_output) + encoder_outputs[1:]return BaseModelOutputWithPoolingAndCrossAttentions(last_hidden_state=sequence_output,pooler_output=pooled_output,past_key_values=encoder_outputs.past_key_values,hidden_states=encoder_outputs.hidden_states,attentions=encoder_outputs.attentions,cross_attentions=encoder_outputs.cross_attentions,)
2.1-BertEmbeddings
��������������͵õ���

ͼ��Bert-embedding
- word_embeddings�������� subword ��Ӧ��Ƕ�롣
- token_type_embeddings�����ڱ�ʾ��ǰ�����ڵľ��ӣ�������������� padding�����ӶԼ�IJ��졣
3�� position_embeddings��������ÿ���ʵ�λ��Ƕ�룬��������ʵ�˳�� transformer �����е���Ʋ�ͬ����һ����ѵ�������ģ�������ͨ�� Sinusoidal ��������õ��Ĺ̶�Ƕ�롣һ����Ϊ����ʵ�ֲ�������չ�ԣ�����ֱ��Ǩ�Ƶ������ľ����У���
���� embedding ����Ȩ����ӣ���ͨ��һ�� LayerNorm+dropout ����������СΪ(batch_size, sequence_length, hidden_size)��
** ����ΪʲôҪ�� LayerNorm+Dropout �أ�ΪʲôҪ�� LayerNorm ������ BatchNorm�����Բο�һ�������Ļش�transformer Ϊʲôʹ�� layer normalization�������������Ĺ�һ��������**
class BertEmbeddings(nn.Module):"""Construct the embeddings from word, position and token_type embeddings."""def __init__(self, config):super().__init__()self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load# any TensorFlow checkpoint fileself.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)self.dropout = nn.Dropout(config.hidden_dropout_prob)# position_ids (1, len position emb) is contiguous in memory and exported when serializedself.position_embedding_type = getattr(config, "position_embedding_type", "absolute")self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))if version.parse(torch.__version__) > version.parse("1.6.0"):self.register_buffer("token_type_ids",torch.zeros(self.position_ids.size(), dtype=torch.long, device=self.position_ids.device),persistent=False,)def forward(self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None, past_key_values_length=0):if input_ids is not None:input_shape = input_ids.size()else:input_shape = inputs_embeds.size()[:-1]seq_length = input_shape[1]if position_ids is None:position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]# Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs# when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves# issue #5664if token_type_ids is None:if hasattr(self, "token_type_ids"):buffered_token_type_ids = self.token_type_ids[:, :seq_length]buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)token_type_ids = buffered_token_type_ids_expandedelse:token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)if inputs_embeds is None:inputs_embeds = self.word_embeddings(input_ids)token_type_embeddings = self.token_type_embeddings(token_type_ids)embeddings = inputs_embeds + token_type_embeddingsif self.position_embedding_type == "absolute":position_embeddings = self.position_embeddings(position_ids)embeddings += position_embeddingsembeddings = self.LayerNorm(embeddings)embeddings = self.dropout(embeddings)return embeddings
2.2-BertEncoder
������� BertLayer����һ�鱾��û���ر���Ҫ˵���ĵط���������һ��ϸ��ֵ�òο������� gradient checkpointing �����Խ���ѵ��ʱ���Դ�ռ�á�
gradient checkpointing ���ݶȼ��㣬ͨ�����ٱ���ļ���ͼ�ڵ�ѹ��ģ��ռ�ÿռ䣬�����ڼ����ݶȵ�ʱ����Ҫ���¼���û�д洢��ֵ���ο����ġ�Training Deep Nets with Sublinear Memory Cost������������ʾ��ͼ
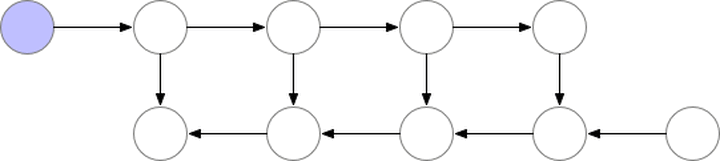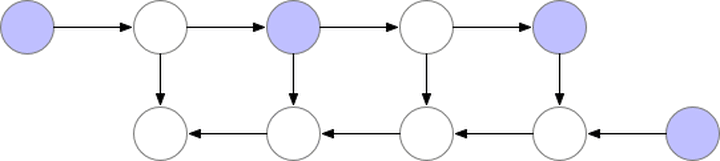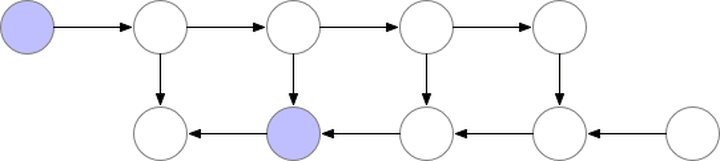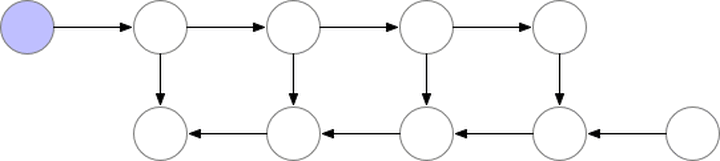
ͼ��gradient-checkpointing
�� BertEncoder �У�gradient checkpoint ��ͨ�� torch.utils.checkpoint.checkpoint ʵ�ֵģ�ʹ�������ȽϷ��㣬���Բο��ĵ���torch.utils.checkpoint - PyTorch 1.8.1 documentation����һ���Ƶľ���ʵ�ֱȽϸ��ӣ��ڴ˲���չ����
������һ���ߣ��ͽ����� Encoder ��ijһ�㣺
class BertEncoder(nn.Module):def __init__(self, config):super().__init__()self.config = configself.layer = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)])def forward(self,hidden_states,attention_mask=None,head_mask=None,encoder_hidden_states=None,encoder_attention_mask=None,past_key_values=None,use_cache=None,output_attentions=False,output_hidden_states=False,return_dict=True,):all_hidden_states = () if output_hidden_states else Noneall_self_attentions = () if output_attentions else Noneall_cross_attentions = () if output_attentions and self.config.add_cross_attention else Nonenext_decoder_cache = () if use_cache else Nonefor i, layer_module in enumerate(self.layer):if output_hidden_states:all_hidden_states = all_hidden_states + (hidden_states,)layer_head_mask = head_mask[i] if head_mask is not None else Nonepast_key_value = past_key_values[i] if past_key_values is not None else Noneif getattr(self.config, "gradient_checkpointing", False) and self.training:if use_cache:logger.warning("`use_cache=True` is incompatible with `config.gradient_checkpointing=True`. Setting ""`use_cache=False`...")use_cache = Falsedef create_custom_forward(module):def custom_forward(*inputs):return module(*inputs, past_key_value, output_attentions)return custom_forwardlayer_outputs = torch.utils.checkpoint.checkpoint(create_custom_forward(layer_module),hidden_states,attention_mask,layer_head_mask,encoder_hidden_states,encoder_attention_mask,)else:layer_outputs = layer_module(hidden_states,attention_mask,layer_head_mask,encoder_hidden_states,encoder_attention_mask,past_key_value,output_attentions,)hidden_states = layer_outputs[0]if use_cache:next_decoder_cache += (layer_outputs[-1],)if output_attentions:all_self_attentions = all_self_attentions + (layer_outputs[1],)if self.config.add_cross_attention:all_cross_attentions = all_cross_attentions + (layer_outputs[2],)if output_hidden_states:all_hidden_states = all_hidden_states + (hidden_states,)if not return_dict:return tuple(vfor v in [hidden_states,next_decoder_cache,all_hidden_states,all_self_attentions,all_cross_attentions,]if v is not None)return BaseModelOutputWithPastAndCrossAttentions(last_hidden_state=hidden_states,past_key_values=next_decoder_cache,hidden_states=all_hidden_states,attentions=all_self_attentions,cross_attentions=all_cross_attentions,)
2.2.1.1 BertAttention
����Ϊ attention ��ʵ�־������û�뵽��Ҫ����һ�㡭�����У�self ��Ա���Ƕ�ͷע������ʵ�֣��� output ��Աʵ�� attention ���ȫ���� +dropout+residual+LayerNorm һϵ�в�����
class BertAttention(nn.Module):def __init__(self, config):super().__init__()self.self = BertSelfAttention(config)self.output = BertSelfOutput(config)self.pruned_heads = set()
���Ȼ��ǻص���һ�㡣��������������ᵽ�ļ�֦�������� prune_heads ������
def prune_heads(self, heads):if len(heads) == 0:returnheads, index = find_pruneable_heads_and_indices(heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads)# Prune linear layersself.self.query = prune_linear_layer(self.self.query, index)self.self.key = prune_linear_layer(self.self.key, index)self.self.value = prune_linear_layer(self.self.value, index)self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)# Update hyper params and store pruned headsself.self.num_attention_heads = self.self.num_attention_heads - len(heads)self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_headsself.pruned_heads = self.pruned_heads.union(heads)
����ľ���ʵ�ָ������£�
-
find_pruneable_heads_and_indices�Ƕ�λ��Ҫ������ head���Լ���Ҫ������ά���±� index�� -
prune_linear_layer���� Wk/Wq/Wv Ȩ�ؾ�����ͬ bias���а��� index ����û�б���֦��ά�Ⱥ�ת�Ƶ��µľ���
�������͵���ͷϷ����Self-Attention �ľ���ʵ�֡�
class BertAttention(nn.Module):def __init__(self, config):super().__init__()self.self = BertSelfAttention(config)self.output = BertSelfOutput(config)self.pruned_heads = set()def prune_heads(self, heads):if len(heads) == 0:returnheads, index = find_pruneable_heads_and_indices(heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads)# Prune linear layersself.self.query = prune_linear_layer(self.self.query, index)self.self.key = prune_linear_layer(self.self.key, index)self.self.value = prune_linear_layer(self.self.value, index)self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)# Update hyper params and store pruned headsself.self.num_attention_heads = self.self.num_attention_heads - len(heads)self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_headsself.pruned_heads = self.pruned_heads.union(heads)def forward(self,hidden_states,attention_mask=None,head_mask=None,encoder_hidden_states=None,encoder_attention_mask=None,past_key_value=None,output_attentions=False,):self_outputs = self.self(hidden_states,attention_mask,head_mask,encoder_hidden_states,encoder_attention_mask,past_key_value,output_attentions,)attention_output = self.output(self_outputs[0], hidden_states)outputs = (attention_output,) + self_outputs[1:] # add attentions if we output themreturn outputs
2.2.1.1.1 BertSelfAttention
Ԥ������һ�����˵��ģ�͵ĺ�������Ҳ��Ψһ�漰����ʽ�ĵط������Խ������������롣
��ʼ�����֣�
class BertSelfAttention(nn.Module):def __init__(self, config):super().__init__()if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):raise ValueError("The hidden size (%d) is not a multiple of the number of attention ""heads (%d)" % (config.hidden_size, config.num_attention_heads))self.num_attention_heads = config.num_attention_headsself.attention_head_size = int(config.hidden_size / config.num_attention_heads)self.all_head_size = self.num_attention_heads * self.attention_head_sizeself.query = nn.Linear(config.hidden_size, self.all_head_size)self.key = nn.Linear(config.hidden_size, self.all_head_size)self.value = nn.Linear(config.hidden_size, self.all_head_size)self.dropout = nn.Dropout(config.attention_probs_dropout_prob)self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":self.max_position_embeddings = config.max_position_embeddingsself.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)self.is_decoder = config.is_decoder
-
������Ϥ�� query��key��value ����Ȩ�غ�һ�� dropout�����ﻹ��һ����һ���� position_embedding_type���Լ� decoder ��ǣ�
-
ע�⣬hidden_size �� all_head_size ��һ��ʼ��һ���ġ�����ΪʲôҪ���������һ�ٵ�������һ������������Ȼ����Ϊ�����Ǹ���֦�������������� attention head �Ժ� all_head_size ��Ȼ��С�ˣ�
-
hidden_size ������ num_attention_heads ������������ bert-base Ϊ����ÿ�� attention ���� 12 �� head��hidden_size �� 768������ÿ�� head ��С�� attention_head_size=768/12=64��
-
position_embedding_type ��ʲô���������¿���֪����.