Amazon Kinesis Data Firehose调研
简介
Amazon Kinesis 可让您轻松收集、处理和分析实时流数据,以便您及时获得见解并对新信息快速做出响应。
Amazon Kinesis 提供多种核心功能,可以经济高效地处理任意规模的流数据,同时具有很高的灵活性,让您可以选择最符合应用程序需求的工具。
借助 Amazon Kinesis,您可以获取视频、音频、应用程序日志和网站点击流等实时数据,也可以获取用于机器学习、分析和其他应用程序的 IoT 遥测数据。借助 Amazon Kinesis,您可以即刻对收到的数据进行处理和分析并做出响应,无需等到收集完全部数据后才开始进行处理。
实际上,Amazon Kinesis包含以下四个服务:
-
Amazon Kinesis Video Streams – 利用 Amazon Kinesis Video Streams,您可以轻松而安全地将视频从互联设备流式传输到 AWS,用于分析、机器学习 (ML) 和其他处理
-
Amazon Kinesis Data Streams – Amazon Kinesis Data Streams 是一种可扩展且持久的实时数据流服务,可以从成千上万个来源中以每秒数 GB 的速度持续捕获数据。
-
Amazon Kinesis Data Firehose – Amazon Kinesis Data Firehose 是将流数据可靠地加载到数据湖、数据存储和分析服务中的最简单方式。该服务可以捕获和转换流数据并将其传输给 Amazon S3、Amazon Redshift、Amazon Elasticsearch Service、通用 HTTP 终端节点和服务提供商(如 Datadog、New Relic、MongoDB 和 Splunk)
Amazon Kinesis Data Firehose 是一项完全托管的服务,用于实时提供数据流到 Amazon Simple Storage Service (Amazon S3)、Amazon Redshift、Amazon OpenSearch Service、Splunk,以及受支持的第三方服务提供商(包括 Datadog、Dynatrace、LogicMongoDB、New Relic 和 Sumo Logic)拥有的目标。Kinesis Data Firehose 是 Kinesis Data Firehose 与 Kinesis 流数据平台的一部分。Kinesis Data Streams、Kinesis Video Streams, 和Amazon Kinesis Data Analytics。
使用 Kinesis Data Firehose,无需编写应用程序或管理资源。您可以配置数据创建器以将数据发送到 Kinesis Data Firehose,后者自动将数据传输到您指定的目标位置。您还可以将 Kinesis Data Firehose 配置为在传输之前转换数据。
-
Amazon Kinesis Data Analytics – Amazon Kinesis Data Analytics 是通过 SQL 或 Apache Flink 实时处理数据流的最简单方法,您无需了解新的编程语言或处理框架。
重要概念
要开始使用 Kinesis Data Firehose,最好了解以下概念:
1. Kinesis Data Firehose 传输流
The underlying entity of Kinesis Data Firehose. You use Kinesis Data Firehose by creating a Kinesis Data Firehose delivery stream and then sending data to it. For more information, see Creating an Amazon Kinesis Data Firehose Delivery Stream and Sending Data to an Amazon Kinesis Data Firehose Delivery Stream.
2. record
您的数据创建器发送到 Kinesis Data Firehose 传输流的目标数据。记录最大可达 1000 KB。
3. data producer
Producers send records to Kinesis Data Firehose delivery streams. For example, a web server that sends log data to a delivery stream is a data producer. You can also configure your Kinesis Data Firehose delivery stream to automatically read data from an existing Kinesis data stream, and load it into destinations. For more information, see Sending Data to an Amazon Kinesis Data Firehose Delivery Stream.
4. 缓冲区大小(buffer size)和缓冲间隔(buffer interval)
在传输到目标之前,Kinesis Data Firehose 会将传入流数据缓冲到特定大小或特定时间的传入流数据。
Buffer Size: 是以 MB 为单位
Buffer Interval:以秒为单位。
5. 其他概念
问:什么是串流 ETL(概念)?
串流 ETL 是指实时数据从一个地方到另一个地方的处理和移动。ETL 是数据库函数提取 (extract)、转换 (transform) 和加载 (load) 的缩写。提取是指从某个源收集数据。转换是指对该数据执行的任何处理。加载是指将处理后的数据发送到目标,如仓库、数据湖或分析工具。
问:什么是 Amazon Kinesis Data Firehose?
Kinesis Data Firehose 是一种串流 ETL 解决方案。这是将串流数据加载到数据存储和分析工具的最简单方式。其功能包括采集、转换串流数据,并将其加载到 Amazon S3、Amazon Redshift、Amazon OpenSearch Service 和 Splunk,让您可以借助正在使用的现有业务情报工具和控制面板,进行近乎实时的分析。这是一项完全托管式服务,会自动扩展以匹配数据吞吐量,并且无需持续管理。它还可以在加载数据前对其进行批处理、压缩和加密,从而最大程度地减少目的地使用的存储量,同时提高安全性。
问:什么是 Kinesis Data Firehose 的源?
源是指您的串流数据连续生成和捕获的位置。
例如,源可以是 Amazon EC2 实例上运行的日志服务器、移动设备上运行的应用程序或 IoT 设备上的传感器。您可以使用以下方式将源连接到 Kinesis Data Firehose
- Amazon Kinesis Data Firehose API,使用的是适用于 Java、.NET、Node.js、Python 或 Ruby 的 AWS SDK。
- Kinesis 数据流,其中 Kinesis Data Firehose 可以轻松地从现有的 Kinesis 数据流读取数据,并将其加载到 Kinesis Data Firehose 目标。
- AWS 本机支持的服务,如 AWS Cloudwatch、AWS EventBridge、AWS IOT 或 AWS Pinpoint。有关完整列表,请参阅 Amazon Kinesis Data Firehose 开发人员指南。
- Kinesis Agents,这是一种独立的 Java 软件应用程序,可连续监控一组文件,并向流式传输发送新数据。
- Fluentbit,这是一种开源日志处理器和转发器。
- AWS Lambda,这是一项无服务器计算服务,让您无需预置或管理服务器即可运行代码。您可以使用写入 Lambda 函数根据触发的事件将流量从 S3 或 DynamoDB 发送到 Kinesis Data Firehose。
问:什么是 Kinesis Data Firehose 的目标?
目标是数据将交付到的数据存储。
Kinesis Data Firehose 当前支持将 Amazon S3、Amazon Redshift、Amazon OpenSearch Service、Splunk、Datadog、NewRelic、Dynatrace、Sumologic、LogicMonitor、MongoDB 和 HTTP 终端节点作为目标位置。
问:Kinesis Data Firehose 可代我管理哪些内容?
Kinesis Data Firehose 能够管理将您的数据捕获并加载到 Amazon S3、Amazon Redshift、Amazon OpenSearch Service 或 Splunk 所需的所有底层基础设施、存储、联网和配置。
您不必操心预置、部署、持续维护硬件、软件,或编写任意其他应用程序来管理这一流程。而且,Kinesis Data Firehose 还能弹性扩展,无需任何人工干预,不产生相关的开发人员开销。此外,Kinesis Data Firehose 还可在一个 AWS 区域的三个设施之间同步复制数据,在将数据传输到目标的同时,提供高可用性和持久性。
问:如何使用 Kinesis Data Firehose?
注册 Amazon Web Services 后,您可以按照以下步骤开启使用 Kinesis Data Firehose:
- 通过 Firehose 控制台或 CreateDeliveryStream 操作创建 Kinesis Data Firehose 传输流。您可以选择在传输流中配置 AWS Lambda 函数,以便在加载原始数据之前进行准备和转换。
- 使用 Amazon Kinesis Agent 或 Firehose API 配置数据创建器,以持续地向传输流发送数据。
- Firehose 会自动和持续地将数据加载到您指定的目标。
问:什么是 Kinesis Data Firehose 的传输流?
传输流是 Kinesis Data Firehose 的基础实体。
您通过创建传输流然后向其发送数据的方式来使用 Firehose。您可以通过 Firehose 控制台或 CreateDeliveryStream 操作创建 Kinesis Data Firehose 传输流。有关更多信息,请参阅创建传输流。
问:什么是 Kinesis Data Firehose 的记录?
记录是您的数据创建器发送到传输流的重要数据。
记录的最大大小(进行 Base64 编码前)为 1024KB。
问:Kinesis Data Firehose 有哪些限制?
有关限制的信息,请参阅开发人员指南中的 Amazon Kinesis Data Firehose 限制。
工作原理
Amazon Kinesis Data Firehose 是一项提取、转换、加载 (ETL) 服务,可以将串流数据以可靠方式捕获、转换和提供到数据湖、数据存储和分析服务中。
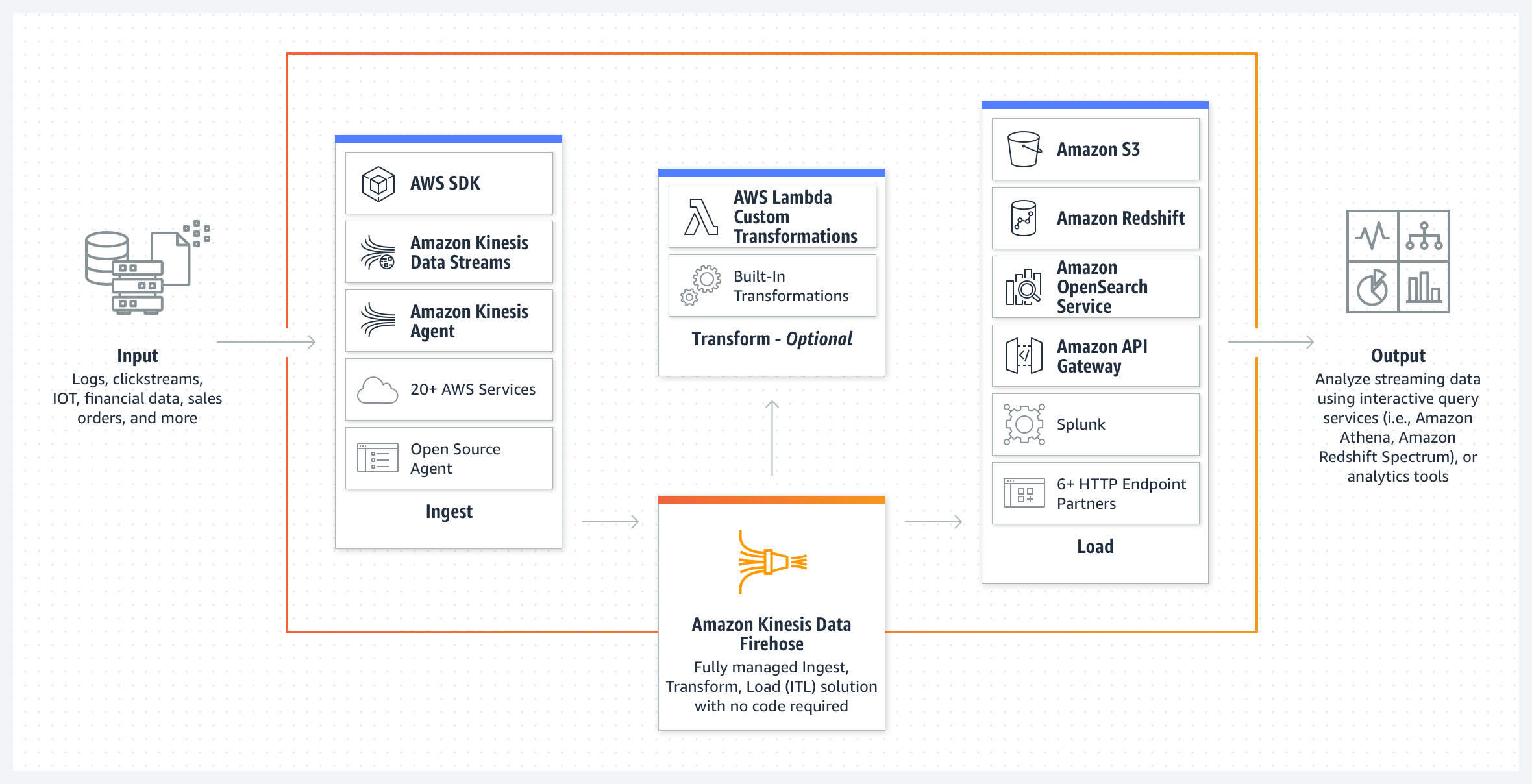
使用以及优势
使用流程
详情操作见视频: Kinesis Data Firehose快速入门
优势

- 易于使用
- 与亚马逊云科技服务集成
- 无服务数据转换
- 近乎实时
- 无需持续管理
- 按实际用量付费
功能
轻松启动和配置
您只需在 AWS 管理控制台中单击几下,即可启动 Amazon Kinesis Data Firehose 并创建传输流,从而将数据加载到 Amazon S3、Amazon Redshift、Amazon OpenSearch Service、HTTP 终端节点、Datadog、New Relic、MongoDB 或 Splunk 中。
您可以通过调用 Firehose API 或运行我们在数据源上提供的 Linux 代理,将数据发送给传输流。然后,Kinesis Data Firehose 将数据持续加载到指定的目标位置。
近乎实时地加载新数据
您可以指定批处理大小或批处理间隔,以控制数据上传到目标位置的速度。
例如,如果您想要在将新数据发送到传输流的 60 秒内接收新数据,则可以将批处理间隔设置为 60 秒。此外,您还可以指定是否压缩数据。该服务支持常见的压缩算法,包括 GZip、兼容 Hadoop 的 Snapy、Zip 和 Snapy。在上传数据前先对其进行批处理和压缩,以便您控制在目标位置接收新数据的速度。
弹性扩展以处理各种不同的数据吞吐量
启动后,您的传输流将在限制范围内,自动向上和向下扩展,按每秒数 GB 或更高的输入数据速率进行处理,并在您为传输流指定的级别上维持数据延迟。无需人工干预或维护。
Apache Parquet 或 ORC 格式转换
Kinesis Data Firehose 支持 Apache Parquet 和 Apache ORC 等列式数据格式适合用于通过 Amazon Athena、Amazon Redshift Spectrum、Amazon EMR 等服务和其他基于 Hadoop 的工具交付成本高效的存储和分析服务。
在将数据存入 Amazon S3 之前,Kinesis Data Firehose 可以将传入数据的格式从 JSON 转换成 Parquet 或 ORC 格式,这样您就可以节省存储和分析成本。
将分区数据交付给 S3
使用静态或动态定义的键(如“customer_id”或“transaction_id”),在交付给 S3 之前动态划分串流数据。
Kinesis Data Firehose 通过这些键对数据进行分组,并交付到键唯一的 S3 前缀中,使您能够更轻松地使用 Athena、EMR 和 Redshift Spectrum 在 S3 中执行高性能、成本高效的分析。 了解详情 ?
集成数据转换
您可以配置 Amazon Kinesis Data Firehose 以便准备流数据,然后再将其加载到数据存储中。
只需从 AWS 管理控制台中的 Amazon Kinesis Data Firehose 传输流配置选项卡中选择一个 AWS Lambda 函数即可。
Amazon Kinesis Data Firehose 会自动将该函数应用到每个输入数据记录,然后将转换后的数据加载到目标位置。
Amazon Kinesis Data Firehose 可以提供预构建的 Lambda 蓝图,用于将 Apache 日志和系统日志等常用数据源转换为 JSON 格式和 CSV 格式。您可以原样使用预构建的蓝图,对其进行进一步自定义,或者编写自己的自定义函数。您也可以对 Amazon Kinesis Data Firehose 进行配置,使其自动重试失败的任务并备份原始流数据。了解详情 ?
支持多个数据目标位置
Amazon Kinesis Data Firehose 当前支持将 Amazon S3、Amazon Redshift、Amazon OpenSearch Service、HTTP 终端节点、Datadog、New Relic、MongoDB 和 Splunk 作为目标位置。
您可以指定目标位置 Amazon S3 存储桶、Amazon Redshift 表、Amazon OpenSearch Service 域、通用 HTTP 终端节点,或应在其中加载数据的服务提供商。
可选的自动加密
Amazon Kinesis Data Firehose 提供在将数据上传到目标位置后自动加密数据的选项。
作为传输流配置的一部分,您可以指定 AWS Key Management System (KMS) 加密密钥。
性能监控指标
Amazon Kinesis Data Firehose 通过控制台以及 Amazon CloudWatch 显示数个指标,包括提交的数据量、上传到目标位置的数据量、从来源传输到目标位置的时间、传输流限制范围、限制的记录数,以及上传成功率。
您可以使用这些指标监控传输流的运行状况,采取任何必要的操作,如修改目标位置、设置接近限制范围的警报,同时确保服务正在提取数据,并将数据加载到目标位置。
按实际使用量付费的定价模式
使用 Amazon Kinesis Data Firehose,您只需为通过该服务传输的数据量和转换格式的数据量(如果适用)付费。
您还需要支付适用的 Amazon VPC 交付和数据传输费用。
没有最低费用,也没有预付承诺。无需人工操作、扩展和维护基础设施或自定义应用程序来捕获和加载流数据。
应用场景
-
使用 Amazon Kinesis Data Firehose 和 Amazon EMR 中的 Apache Spark 优化流式数据处理
Amazon Kinesis Data Firehose 可以将传入的多个小消息缓冲到更大的记录中,然后再将它们传送到 Amazon S3 存储桶。它根据两个条件执行此操作:缓冲区大小(最大 128 MB)和缓冲区间隔(最多 900 秒)。只要满足这些条件中的任何一个,就会触发记录传送。
-
EKK—基于AWS托管服务的日志收集分析系统
-
使用 Amazon Kinesis 快速构建流式数据分析架构
-
利用 AWS Comprehend 打造近实时文本情感分析
参考资料
1. Amazon Kinesis Data Firehose 常见问题
2. Kinesis Data Firehose快速入门
3. Amazon Kinesis Data Firehose开发人员指南(官网)
4. Feature Demo Video Dynamic Partitioning with Amazon Kinesis Data Firehose Amazo
5. Amazon Kinesis Data Firehose 资源