5-8以前为tensorflow2.0 ,5-8以后为tensorflow1.0
- 什么是交叉熵?
交叉熵:跟信息熵类似,值越小越好,?∑i=1mp(xi)logq(xi)-\sum_{i=1}^m{p(x_i)}{logq(x_i)}?∑i=1m?p(xi?)logq(xi?),p(x)为标签,q(x)为预测值(决策树的
信息熵 = ?∑i=1mp(xi)logp(xi)-\sum_{i=1}^m{p(x_i)}{logp(x_i)}?∑i=1m?p(xi?)logp(xi?),p(x)为每个类别的比例),其实逻辑回归的损失函数就是交叉熵,
吴恩达机器学习的数字分类神经网络使用的损失函数=ry.*log(a3) + (1 - ry).*log(1 - a3); ry为label转成的one_hot,
a3为最后一层输出logits使用sigmoid后的概率值。但是我从这个https://blog.csdn.net/tsyccnh/article/details/79163834博客上看到,如果是单分类问题即每张图片只有一个数字(显然吴恩达的例子中只有一个数字),那么应该将logits用softmax先转为概率值,然后用交叉熵计算loss=0?logq1+...+1?logqi+...loss = 0 * log^{q_1} + ... + 1*log^{q_i} + ...loss=0?logq1?+...+1?logqi?+...。如果是多分类问题(一个图片中需要识别多个数字),将logits先用sigmoid函数
转为概率值,然后对每个节点先做单节点交叉熵计算,如lossunit1=?(0?logq1+(1?0)?log1?q1)loss_{unit1} = -(0*log^{q1} + (1-0)*log^{1-q1} )lossunit1?=?(0?logq1+(1?0)?log1?q1),然后单个样本的loss = loss_{unit1} + loss_{unit2} +… ,就是吴恩达神经网络手写识别的例子 - 为什么softmax要和交叉熵联合使用,为什么softmax不和mse结合?
https://blog.csdn.net/u010365819/article/details/87937183,大致是softmax要和mse结合后的损失函数是是非凸函数
5-3 feature_columns
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
import os
import sys
import time
import sklearn
from tensorflow import kerasimport tensorflow as tf
print(tf.__version__)
print(sys.version_info)
for module in mpl, np, pd, sklearn, tf, keras:print(module.__name__, module.__version__)

5.3.1 读取数据
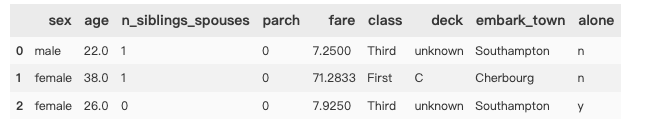
# 泰坦尼克数据集含义 = {'survived':'预测的值,有无获救', 'sex', 'age', 'n_siblings_spouses':'兄弟姐妹及配偶的人数', 'parch':'父母及孩子人数', 'fare':'船票费用','class':'仓位(高等/中等/低等)', 'deck':'船舱的位置', 'embark_town':'从哪个港口出发', 'alone':'是否独自一人'}
train_df = pd.read_csv('train.csv')
eval_df = pd.read_csv('eval.csv')
y_train = train_df.pop('survived')
y_eval = eval_df.pop('survived')
train_df.head(3)
5.3.2 离散和连续特征分类构建用于后续one_hot编码映射
categorical_columns = ['sex', 'parch', 'n_siblings_spouses', 'class', 'deck', 'embark_town', 'alone'] # 离散特征
numeric_columns = ['age', 'fare'] # 连续特征feature_columns = []
for categorical_column in categorical_columns:vocab = train_df[categorical_column].unique()print(categorical_column, vocab)feature_columns.append(tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_vocabulary_list(categorical_column, vocab)))for numeric_column in numeric_columns:feature_columns.append(tf.feature_column.numeric_column(numeric_column, dtype=tf.float32))

5.3.3 构建数据集
def make_dataset(data_df, label_df, epochs=10, shuffle=True, batch_size=32):dataset = tf.data.Dataset.from_tensor_slices( (train_df.to_dict('list'), label_df))if shuffle :dataset = dataset.shuffle(10000)dataset = dataset.repeat(epochs).batch(batch_size)return datasettrain_dataset = make_dataset(train_df, y_train, batch_size=)
5.3.4 DenseFeatures进行one_hot映射
for x,y in train_dataset.take(1):print(keras.layers.DenseFeatures(feature_columns)(x).numpy())

对上述样本结果解读:
- 1
# 13.8625是fare特征,在5.3.2中直接tf.feature_column.numeric_column,无需进行one_hot编码映射,在原始数据查找只有一条记录
train_df[train_df['fare'] == 13.8625]

- 2
# 使用pprint查看特征的先后顺序为['age','alone','class','deck','embark_town','fare','n_siblings_spouses','parch','sex']
import pprint
for x,y in train_dataset.take(1):pprint.pprint(x)

- 3

5-4 keras_to_estimater
model = keras.models.Sequential([keras.layers.DenseFeatures(feature_columns),keras.layers.Dense(100, activation='relu'),keras.layers.Dense(100, activation='relu'),keras.layers.Dense(2, activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy', optimizer=keras.optimizers.SGD(lr=0.01),metrics = ['accuracy'])train_dataset = make_dataset(train_df, train_df, epochs=100) # 当train_df为数值型时用sparse_categorical_crossentropy,他会将train_df先转成one-hot编码,是one-hot编码时用categorical_crossentropy
eval_dataset = make_dataset(eval_df, y_eval, epochs=1, shuffle=False)
history = model.fit(train_dataset, validation_data=eval_dataset,steps_per_epoch = len(train_df)//32,validation_steps = len(eval_df) // 32,epochs = 100)使用estimator
estimator = keras.estimator.model_to_estimator(model)
estimator.train(input_fn = lambda: make_dataset(train_df, y_train, epochs=100)) # 该版本有错误,应该是对那些转为feature的数据集的数据不兼容
# input_fn的函数必须返回(features, label)元祖,但不能有参数
5-5 预定义estimator
5.5.1 BaselineClassifier 分类器,相当于随机猜测,根据标签值随机猜测
output_dir = 'baseline_model'
if not os.path.exists(output_dir):os.mkdir(output_dir)baseline_estimator = tf.compat.v1.estimator.BaselineClassifier(model_dir=output_dir,n_classes=2)
baseline_estimator.train(input_fn = lambda : make_dataset(train_df, y_train, epochs=100))
# baseline_estimator.train( input_fn = fun('t') )
baseline_estimator.evaluate(input_fn=lambda : make_dataset(eval_df, y_eval, epochs=1, shuffle=False, batch_size=20))
5.5.2 LinearClassifier
linear_output_dir = 'linear_model'
if not os.path.exists(linear_output_dir):os.mkdir(linear_output_dir)linear_estimator = tf.estimator.LinearClassifier(model_dir=linear_output_dir, n_classes=2,feature_columns=feature_columns)
linear_estimator.train(input_fn = lambda : make_dataset(train_df, y_train, epochs=100))
linear_estimator.evaluate(input_fn=lambda :make_dataset(eval_df, y_eval, epochs=1, shuffle=False))
5.5.3 DNNClassifier
dnn_output_dir = 'dnn_model'
if not os.path.exists(dnn_output_dir):os.mkdir(dnn_output_dir)dnn_estimator = tf.estimator.DNNClassifier(model_dir=dnn_output_dir, n_classes=2,feature_columns=feature_columns,hidden_units = [128,128],activation_fn=tf.nn.relu,optimizer='Adam')
dnn_estimator.train(input_fn = lambda : make_dataset(train_df, y_train, epochs=100))
dnn_estimator.evaluate(input_fn=lambda :make_dataset(eval_df, y_eval, epochs=1, shuffle=False))

5-6 交叉特征实战
# 离散和连续特征分类构建用于后续的映射
categorical_columns = ['sex', 'parch', 'n_siblings_spouses', 'class', 'deck', 'embark_town', 'alone'] # 离散特征
numeric_columns = ['age', 'fare'] # 连续特征feature_columns = []
for categorical_column in categorical_columns:vocab = train_df[categorical_column].unique()print(categorical_column, vocab)feature_columns.append(tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_vocabulary_list(categorical_column, vocab)))for numeric_column in numeric_columns:feature_columns.append(tf.feature_column.numeric_column(numeric_column, dtype=tf.float32))# 添加交叉特征
# age : [1,2,3] gender = ['male', 'female']
# 生成交叉特征 : [(1.'male'), (1,'female'), ..., (3,'female')]
# hash_bucket_size 作用,因为交叉特征的量可能太多,比如2个原始特征size=100,那么交叉特征的size=10000个,作为输入
# 太大,需要进行减少 ,减少过程 hash(10000 value) % 100, 这样每次使用的交叉特征就只有100个feature_columns.append(tf.feature_column.indicator_column(tf.feature_column.crossed_column(['age', 'sex'], hash_bucket_size=100)))
下面再用BaselineClassifier,LinearClassifier,DNNClassifier进行训练,训练过程和5.5一致。
为什么使用交叉特征: 在wide&deep模型中,离散特征使用交叉特征能更细节的记住一个人
结论: 发现dnn模型增加了交叉特征后,accuracy还降低了,base方法没变化,linear方法升高,说明增加交叉特征
对提升每个模型的作用不同。如果想在dnn模型中使用交叉特征,那就需要使用wide&deep模型,因为单纯加入只会
减少精确率
5-8 使用tf1.0计算图构建
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all),(x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
# 数据归一化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1,1)).reshape(-1, 28 * 28)
x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1,1)).reshape(-1, 28 * 28)
x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1,1)).reshape(-1, 28 * 28)
x_train_scaled.shape, y_train.shape
((55000, 784), (55000,))
5.8.1 使用x,y 占位符构建网络
hidden_units = [100, 100]
class_num = 10x = tf.placeholder(tf.float32, [None, 28 * 28]) # None代表batch_size的大小,可以输入任意值
y = tf.placeholder(tf.int64, [None]) # None代表batch_size大小,不知道batch_size多少,先占位# 开始构建网络层
# 输出层到隐藏层构建
input_for_next_layer = x
for hidden_unit in hidden_units:Input_for_next_layer = tf.layers.dense(input_for_next_layer, hidden_unit, activation=tf.nn.relu)# logits: 最后一层输出,还没用激活函数
logits = tf.layers.dense(input_for_next_layer, class_num) # loss: 1. 使用softmax将logits转换为概率prob ; 2. labels -> one_hot;3. 计算交叉熵corss_entropy损失函数loss = tf.losses.sparse_softmax_cross_entropy(labels=y, logits=logits) # 将labels转成one_hot编码 # 过去accuracy
prediction = tf.argmax(logits, axis=1) # 求出每一行的最大值对应的索引,若logits为1位数组如[1,2,3],那么axis只能等于0,
# 因为一维数组默认是认为列,这里的logits是二维
correct_predition = tf.equal(prediction, y)
accuracy = tf.reduce_mean(tf.cast(correct_predition, tf.float64))train_op = tf.train.AdamOptimizer(1e-3).minimize(loss) # 1e-3为learning_rate
init = tf.global_variables_initializer()
batch_size = 20
epochs = 10
train_steps_for_epoch = len(x_train_scaled) // batch_sizedef eval_with_sess(sess, x, y, accuracy, images, labels, batch_size):eval_steps = len(images) // batch_sizeeval_accuracies = []for step in range(eval_steps):batch_data = images[step*batch_size: (step+1)*batch_size]batch_label = labels[step*batch_size: (step+1)*batch_size]accuracy_val = sess.run(accuracy, feed_dict={
x: batch_data,y: batch_label})eval_accuracies.append(accuracy_val)return np.mean(eval_accuracies)with tf.Session() as sess:sess.run(init)for epoch in range(epochs):for step in range(train_steps_for_epoch):batch_data = x_train_scaled[step*batch_size: (step+1)*batch_size]batch_label = y_train[step*batch_size: (step+1)*batch_size]loss_val, accuracy_val, _ = sess.run([loss, accuracy, train_op], feed_dict = {
x: batch_data,y: batch_label}) print("\r [Train] epoch: %d, step: %d , loss: %3.5f , accuracy %3.5f" %(epoch, step, loss_val, accuracy_val), end="") # mac下\r与换行符\r冲突valid_accuracy = eval_with_sess(sess, x, y, accuracy, x_valid_scaled, y_valid, batch_size)print("\t[Valid] acc : %2.2f " % (valid_accuracy) )
5-9 tf.dataset 取消x,y占位符构建网络
# 避免后面类型错误
y_train = np.asarray(y_train, dtype=np.int64)
y_valid = np.asarray(y_valid, dtype=np.int64)
y_test = np.asarray(y_test, dtype=np.int64)def make_dataset(images, labels, epochs, batch_size, shuffle=True):dataset = tf.data.Dataset.from_tensor_slices((images, labels))if shuffle :dataset = dataset.shuffle(10000)dataset = dataset.repeat(epochs).batch(batch_size)return datasetbatch_size = 20
epochs = 10
hidden_units = [100, 100]
class_num = 10
5.9.1 make_one_shot_iterator 构建网络,无法在session中feed训练集及验证集
# make_one_shot_iterator
# 1. 自动初始化 2. 不能被重新初始化 make_initializable_interator能重新初始化加载训练集验证集数据
dataset = make_dataset(x_train_scaled, y_train, epochs, batch_size)
dataset_iter = dataset.make_one_shot_iterator()
x, y = dataset_iter.get_next()# x = tf.placeholder(tf.float32, [None, 28 * 28]) # x,y 已经生成
# y = tf.placeholder(tf.int64, [None])
input_for_next_layer = x
for hidden_unit in hidden_units:Input_for_next_layer = tf.layers.dense(input_for_next_layer, hidden_unit, activation=tf.nn.relu)
logits = tf.layers.dense(input_for_next_layer, class_num)
loss = tf.losses.sparse_softmax_cross_entropy(labels=y, logits=logits)
prediction = tf.argmax(logits, axis=1)
correct_predition = tf.equal(prediction, y)
accuracy = tf.reduce_mean(tf.cast(correct_predition, tf.float64))
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss) # 1e-3为learning_rateinit = tf.global_variables_initializer()
train_steps_per_epoch = len(x_train_scaled) // batch_sizewith tf.Session() as sess:sess.run(init)for epoch in range(epochs):for step in range(train_steps_per_epoch):loss_val, accuracy_val, _ = sess.run( [loss, accuracy, train_op]) print("\r [Train] epoch: %d, step: %d , loss: %3.5f , accuracy %3.5f" %(epoch, step, loss_val, accuracy_val), end="") # mac下\r与换行符\r冲突print()

5.9.2 make_initializable_interator , 在make_dataset中添加占位符,可在session中feed训练集及验证集
epochs = 10
batch_size = 128images_placeholder = tf.placeholder(tf.float32, [None, 28*28])
labels_placeholder = tf.placeholder(tf.int64, (None,))dataset = make_dataset(images_placeholder, labels_placeholder, epochs=10, batch_size=batch_size)
dataset_iter = dataset.make_initializable_iterator()
x, y = dataset_iter.get_next()hidden_units = [100, 100]
class_num = 10
input_for_next_layer = x
for hidden_unit in hidden_units:Input_for_next_layer = tf.layers.dense(input_for_next_layer, hidden_unit, activation=tf.nn.relu)
logits = tf.layers.dense(input_for_next_layer, class_num)
loss = tf.losses.sparse_softmax_cross_entropy(labels=y, logits=logits)
prediction = tf.argmax(logits, axis=1)
correct_predition = tf.equal(prediction, y)
accuracy = tf.reduce_mean(tf.cast(correct_predition, tf.float64))
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss) # 1e-3为learning_rateinit = tf.global_variables_initializer()
train_steps_per_epoch = len(x_train_scaled) // batch_size
valid_steps = len(x_valid_scaled) // batch_sizedef eval_with_sess(sess, images, labels ):sess.run(dataset_iter.initializer, feed_dict={
images_placeholder: images,labels_placeholder: labels,})return np.mean([sess.run(accuracy) for step in range(valid_steps)])with tf.Session() as sess:sess.run(init)for epoch in range(epochs):sess.run(dataset_iter.initializer, feed_dict={
images_placeholder: x_train_scaled,labels_placeholder: y_train})for step in range(train_steps_per_epoch):loss_val, accuracy_val, _ = sess.run([loss, accuracy, train_op])print("\r [Train] epoch: %d, step: %d , loss: %3.5f , accuracy %3.5f" %(epoch, step, loss_val, accuracy_val), end="") # mac下\r与换行符\r冲突valid_accuracy = eval_with_sess(sess, x_valid_scaled, y_valid)print("\t valid acc: %3.5f"% valid_accuracy)
5-11 estimator
train_df = pd.read_csv('train.csv')
eval_df = pd.read_csv('eval.csv')
y_train = train_df.pop('survived')
y_eval = eval_df.pop('survived')
train_df.head(3)
# 离散和连续特征分类构建用于后续的映射
categorical_columns = ['sex', 'parch', 'n_siblings_spouses', 'class', 'deck', 'embark_town', 'alone'] # 离散特征
numeric_columns = ['age', 'fare'] # 连续特征feature_columns = []
for categorical_column in categorical_columns:vocab = train_df[categorical_column].unique()print(categorical_column, vocab)feature_columns.append(tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_vocabulary_list(categorical_column, vocab)))for numeric_column in numeric_columns:feature_columns.append(tf.feature_column.numeric_column(numeric_column, dtype=tf.float32))# 构建数据集
def make_dataset(data_df, label_df, epochs=10, shuffle=True, batch_size=32):dataset = tf.data.Dataset.from_tensor_slices( (data_df.to_dict('list'), label_df))if shuffle :dataset = dataset.shuffle(10000)dataset = dataset.repeat(epochs).batch(batch_size)return dataset.make_one_shot_iterator().get_next()def model_fn(features, labels, mode, params):# model 运行状态 PREDICT, EVAL,TRAINinput_for_next_layer = tf.feature_column.input_layer(features, params['feature_columns'])for n_unit in params['hidden_units']:input_for_next_layer = tf.layers.dense(input_for_next_layer, units=n_unit, activation=tf.nn.relu)logits = tf.layers.dense(input_for_next_layer, params['n_classes'], activation=None)predicted_classes = tf.argmax(logits, 1)if mode == tf.estimator.ModeKeys.PREDICT:pretictions = {
"class_ids": predicted_classes[:, tf.newaxis],"probabilities": tf.nn.softmax(logits),"logits": logits}return tf.estimator.EstimatorSpec(mode, predictions=pretictions)loss= tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)accuracy = tf.metrics.accuracy(labels=labels, predictions= predicted_classes, name='acc_op') # 这里的accuracy会累积,不用手写求和后求平均metrics = {
"accuracy": accuracy}if mode == tf.estimator.ModeKeys.EVAL:return tf.estimator.EstimatorSpec(mode, loss=loss, eval_metric_ops=metrics)optimizer = tf.train.AdamOptimizer() # 在梯度下降时自适应调整learning_rate,不会导致梯度很大时的学习步长太大,性能差表现好,表现好:不太会发散train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())if mode == tf.estimator.ModeKeys.TRAIN:return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)output_dir = "tf_1.0_customized_estimator"
if not os.path.isdir(output_dir): os.mkdir(output_dir)estimator = tf.estimator.Estimator(model_fn = model_fn,model_dir= output_dir,params = {
"feature_columns": feature_columns,"hidden_units": [100, 100],"n_classes": 2}
)
estimator.train(input_fn = lambda: make_dataset(train_df, y_train, epochs=100))estimator.evaluate(lambda : make_dataset(eval_df, y_eval, epochs=1))

5-12 tf1.0与tf2.0区别
静态图和动态图
- tf1.0: Sess, feed_dict, placeholder被移除
- tf1.0: make_one_shot(initializavble)_iterator被移除
- tf2.0: eager mode, @tf.function, AutoGraph
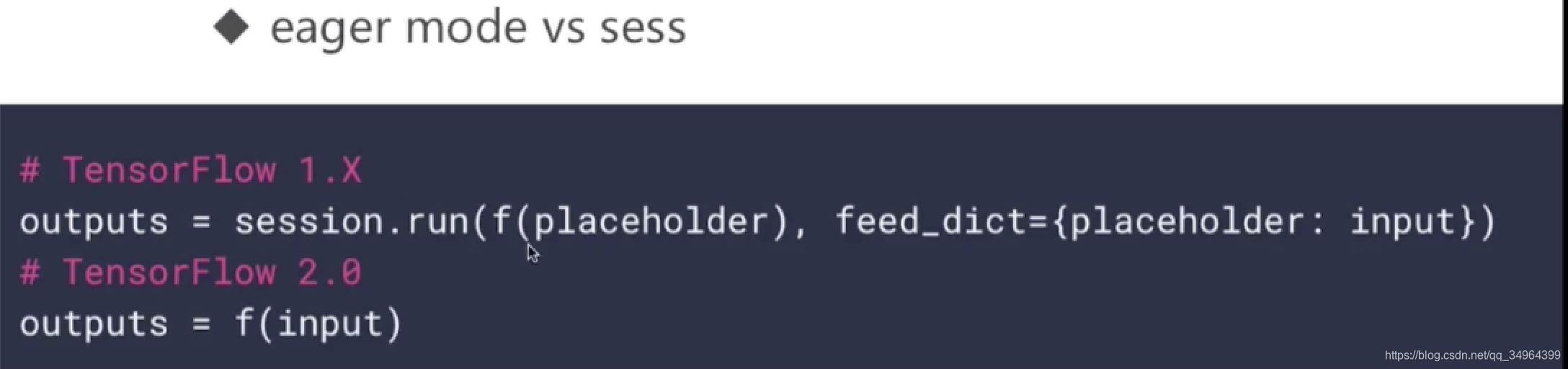
- tf.function与AutoGraph
- 性能好
- 可以导出导入为SavedModel(如:for/while->tf.while_loop, uf->tf.cond, for _ in dataset -> dataset.reduce)
API变动
- tf有2000个API,500个在根空间下
- 一些空间被建立了但是没有包含所有的API(如tf.round没有在tf.math下)
- 有些在跟空间下,但是很少被使用tf.zeta
- 有些经常使用,不在根空间下tf.manip
- 有些空间层次太深
- tf.saved_model.signature_constants.CLASSIFY_INPUTS -> tf.saved_model.CLASSIFY_INPUTS
- tf2.0的API大多放在tf.keras下