��Դ��http://mocom.xmu.edu.cn/article/show/587f103faa2c3f280956e7b6/0/1
Word2Vec ��һ�������� ��Ƕ�루Word Embedding�� �����������Լ���ÿ����������������Ͽ���µ� �ֲ�ʽ��������Distributed Representation����ֱ�ӱ���Ϊ������������������ʾ������һ���̶��Ͽ̻�ÿ�����ʵ����塣����ʵ�������������ǵĴ������������ռ���Ҳ��ӽ�����ʹ�ô������������ģ���Ӿ�ȷ�����Ը������з��������³���ԡ��������ѱ�֤����������Ȼ���Դ������⣬�磺�������룬��ע���⣬ʵ��ʶ��������о��зdz���Ҫ�����á�
? Word2vec��һ��Estimator��������һϵ�д����ĵ��Ĵ�����ѵ��word2vecmodel����ģ�ͽ�ÿ������ӳ�䵽һ���̶���С��������word2vecmodelʹ���ĵ���ÿ�������ƽ���������ĵ�ת��Ϊ������Ȼ���������������ΪԤ����������������ĵ����ƶȼ���ȵȡ�
? Word2Vec��������ģ�ͣ���һ�� CBOW ����˼����ͨ��ÿ���ʵ������Ĵ��ڴʴ�������Ԥ�����ĴʵĴ������������ Skip-gram����˼����ͨ��ÿ�����Ĵ���Ԥ���������Ĵ��ڴʣ�������Ԥ�������������ĴʵĴ����������ַ���ʾ��ͼ����ͼ��ʾ��
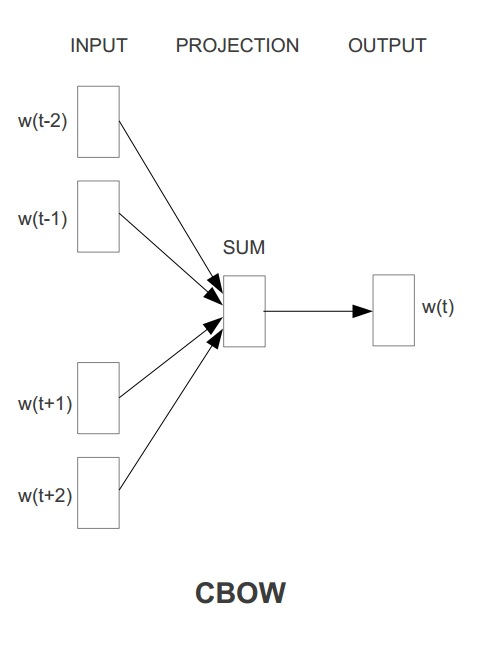
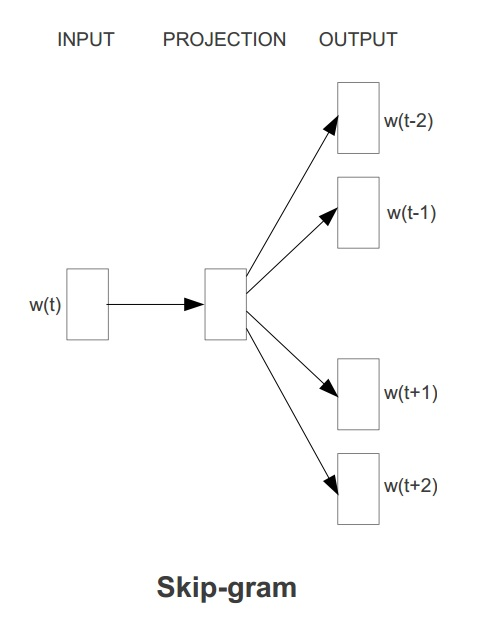
������ml���У�Word2vec ��ʵ��ʹ�õ���skip-gramģ�͡�Skip-gram��ѵ��Ŀ����ѧϰ�ʱ��������ֲ������Ż�Ŀ�����ڸ������ĴʵĴ�����������£����������Ȼ������ 1TT��t=1sumj=kj=?klogp(wt+j|wt)1T��t=1Tsumj=?kj=klogp(wt+j|wt) ���У�w1w1 .... wtwt ��һϵ�д����У����� wtwt �������Ĵʣ��� wt+j(j��[?k,k])wt+j(j��[?k,k]) �������Ĵ����еĴʡ� �������ÿһ�������Ĵ��ڴ� wiwi �ڸ������Ĵ� wjwj �µ��������������� Softmax �������൱��Sigmoid�����ĸ�ά��չ�棩����ʽ���м��㣬����ʽ��ʾ������ uwuw �� vwvw �ֱ������ǰ�ʵĴ������Լ���ǰ�����ĵĴ�������ʾ��
p(wi|wj)=exp(uwiTvwj)sumVl=1exp(uTlvwj)p(wi|wj)=exp(uwiTvwj)suml=1Vexp(ulTvwj)
? ��ΪSkip-gramģ��ʹ�õ�softmax�����Ϊ���ӣ����ԣ�ml�����������Word2Vecʵ�ֲ�������ͬ�IJ��ԣ�ʹ��Huffman�������� ���Softmax(Hierachical Softmax) �����������Ż���ʹ�� logp(wi|wj)log?p(wi|wj) ����ĸ��Ӷȴ� O(V)O(V) �½��� O(log(V))O(log(V))��
? ������Ĵ�����У�����������һ���ĵ�������һ���������д���һ���ĵ�������ÿһ���ĵ������ǽ���ת��Ϊһ�������������������������Ա����ݵ�һ��ѧϰ�㷨��
? ���ȣ�����Word2Vec����Ҫ�İ���
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.ml.feature.Word2Vec
? ������������SparkContext������һ��SQLContext������sc��һ���Ѿ����ڵ�SparkContext��Ȼ����sqlContext.implicits._��ʵ��RDD��Dataframe����ʽת����
scala> val sqlContext = new SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@225a9fc6scala> import sqlContext.implicits._
import sqlContext.implicits._
? Ȼ���������������У�ÿ������һ���ĵ���
scala> val documentDF = sqlContext.createDataFrame(Seq(| "Hi I heard about Spark".split(" "),| "I wish Java could use case classes".split(" "),| "Logistic regression models are neat".split(" ")| ).map(Tuple1.apply)).toDF("text")
documentDF: org.apache.spark.sql.DataFrame = [text: array]
? �½�һ��Word2Vec��������Ӧ�IJ�����������������������ά��Ϊ3������IJ����������Բμ�http://spark.apache.org/docs/1.6.2/api/scala/index.html#org.apache.spark.ml.feature.Word2Vec��
scala> val word2Vec = new Word2Vec().| setInputCol("text").| setOutputCol("result").| setVectorSize(3).| setMinCount(0)
word2Vec: org.apache.spark.ml.feature.Word2Vec = w2v_e2d5128ba199
? ����ѵ�����ݣ���fit()��������һ��Word2VecModel��
scala> val model = word2Vec.fit(documentDF)
model: org.apache.spark.ml.feature.Word2VecModel = w2v_e2d5128ba199
? ����Word2VecModel���ĵ�ת�������������
scala> val result = model.transform(documentDF)
result: org.apache.spark.sql.DataFrame = [text: array, result: vector]scala> result.select("result").take(3).foreach(println)
[[0.018490654602646827,-0.016248732805252075,0.04528368394821883]]
[[0.05958533100783825,0.023424440695505054,-0.027310076036623544]]
[[-0.011055880039930344,0.020988055132329465,0.042608972638845444]]
? ���ǿ��Կ����ĵ���ת��Ϊ��һ��3ά��������������Щ���������Ϳ��Ա�Ӧ�õ���صĻ���ѧϰ�����С�