来源:http://blog.csdn.net/eric_sunah/article/details/54096057?utm_source=tuicool&utm_medium=referral
说明
Spark Streaming的原理说明的文章很多,这里不做介绍。本文主要介绍使用Kafka作为数据源的编程模型,编码实践,以及一些优化说明
spark streaming:http://spark.apache.org/docs/1.6.0/streaming-programming-guide.html
streaming-kafka-integration:http://spark.apache.org/docs/1.6.0/streaming-kafka-integration.html
演示环境
- Spark:1.6
- Kafka:kafka_2.11-0.9.0.1
- 实现语言:Python
编程模型
目前Spark Streaming 的kafka编程主要包括两种模型
1. 基于Receiver
2. Direct(无Receiver)
基于Receiver
这种方式利用接收器(Receiver)来接收kafka中的数据,其最基本是使用Kafka高阶用户API接口。对于所有的接收器,从kafka接收来的数据会存储在spark的executor中,之后spark streaming提交的job会处理这些数据
原理图
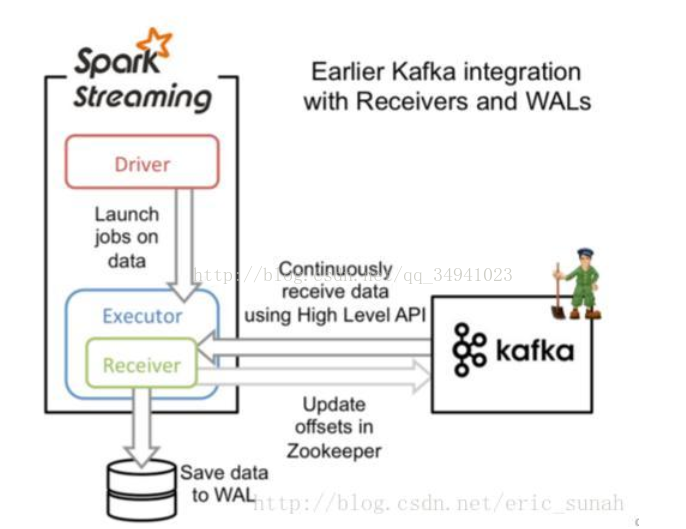
说明
- 需要借助Write Ahead Logs 来保证数据的不丢失,如果我们启用了Write Ahead Logs复制到文件系统如HDFS,那么storage level需要设置成 StorageLevel.MEMORY_AND_DISK_SER,也就是KafkaUtils.createStream(…, StorageLevel.MEMORY_AND_DISK_SER)
- 在Receiver的方式中,Spark中的partition和kafka中的partition并不是相关的,所以如果我们加大每个topic的partition数量,仅仅是增加线程来处理由单一Receiver消费的主题。但是这并没有增加Spark在处理数据上的并行度。
- 对于不同的Group和topic我们可以使用多个Receiver创建不同的Dstream来并行接收数据,之后可以利用union来统一成一个Dstream。
Direct(无Receiver)
在spark1.3之后,引入了Direct方式。不同于Receiver的方式,Direct方式没有receiver这一层,其会周期性的获取Kafka中每个topic的每个partition中的最新offsets,之后根据设定的maxRatePerPartition来处理每个batch
不同于Receiver的方式(是从Zookeeper中读取offset值,那么自然zookeeper就保存了当前消费的offset值,那么如果重新启动开始消费就会接着上一次offset值继续消费)。而在Direct的方式中,是直接从kafka来读数据,那么offset需要自己记录,可以利用checkpoint、数据库或文件记录或者回写到zookeeper中进行记录
原理图
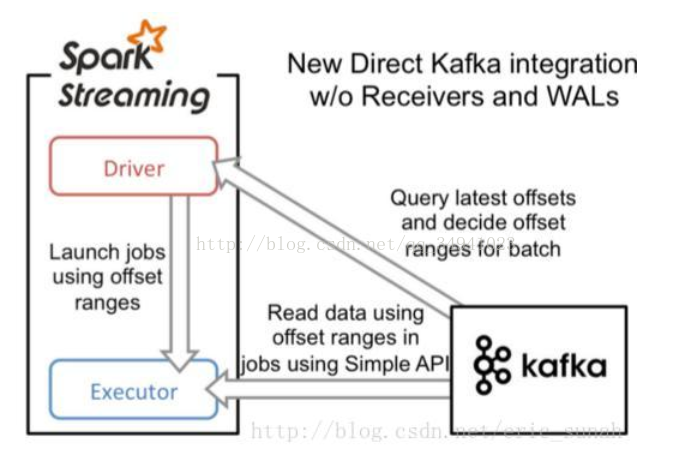
说明
- 简化的并行:在Receiver的方式中我们提到创建多个Receiver之后利用union来合并成一个Dstream的方式提高数据传输并行度。而在Direct方式中,Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据,这种映射关系也更利于理解和优化。
- 高效:在Receiver的方式中,为了达到0数据丢失需要将数据存入Write Ahead Log中,这样在Kafka和日志中就保存了两份数据,浪费!而第二种方式不存在这个问题,只要我们Kafka的数据保留时间足够长,我们都能够从Kafka进行数据恢复。
- 精确一次:在Receiver的方式中,使用的是Kafka的高阶API接口从Zookeeper中获取offset值,这也是传统的从Kafka中读取数据的方式,但由于Spark Streaming消费的数据和Zookeeper中记录的offset不同步,这种方式偶尔会造成数据重复消费。而第二种方式,直接使用了简单的低阶Kafka API,Offsets则利用Spark Streaming的checkpoints进行记录,消除了这种不一致性。
代码实践
Kafka生产者
package com.eric.kafka.producer;import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.Properties;import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;/*** Hello world!*/
public class ProcuderSample {private final Producer<String, String> producer;public final static String TOPIC = "spark_streaming_test_topic";public final static Integer BATCH_SIZE = 2000;private ProcuderSample() {Properties props = new Properties();// 此处配置的是kafka的端口props.put("metadata.broker.list", "server1-2-5-24-138:9092,server1-3-5-24-139:9092,server1:9092");// 配置value的序列化类props.put("serializer.class", "kafka.serializer.StringEncoder");// 配置key的序列化类props.put("key.serializer.class", "kafka.serializer.StringEncoder");props.put("request.required.acks", "-1");producer = new Producer<String, String>(new ProducerConfig(props));}public void deadLoopSendMessage(){int recordCount=0;List<KeyedMessage<String, String>> tmpList=new ArrayList<KeyedMessage<String, String>>();while(true){Random rand=new Random();// 批量发送数据
// String randResult=recordCount+":"+rand.nextInt(100);String randResult=rand.nextInt(10)+"";tmpList.add(new KeyedMessage<String, String>(TOPIC, randResult , randResult));if (tmpList.size()%BATCH_SIZE==0){producer.send(tmpList);tmpList.clear();}
// producer.send(new KeyedMessage<String, String>(TOPIC, randResult , randResult));recordCount+=1;}}public static void main(String[] args) {new ProcuderSample().deadLoopSendMessage();}
}Receiver方式收取数据
# encoding:utf-8
__author__ = 'eric.sun'"""演示如何使用Spark Streaming 通过Kafka Streaming实现WordCount执行命令:./spark-submit --master spark://server1-1-5-24-137:7077 --packages org.apache.spark:spark-streaming-kafka_2.10:1.6.0 ../examples/kafka_streaming.py > logKafka数据源程序:https://github.com/Eric-aihua/practise.git/java_cookbook/cookbook/src/main/java/com/eric/kafka/producer/ProcuderSample.java
"""from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtilsdef start():sconf=SparkConf()# sconf.set('spark.streaming.blockInterval','100')sconf.set('spark.cores.max' , 8)sc=SparkContext(appName='KafkaWordCount',conf=sconf)ssc=StreamingContext(sc,2)numStreams = 3kafkaStreams = [KafkaUtils.createStream(ssc,"server1-2-5-24-138:2181,server1-3-5-24-139:2181,server1-4-5-24-140:2181","streaming_test_group",{"spark_streaming_test_topic":1}) for _ in range (numStreams)]unifiedStream = ssc.union(*kafkaStreams)print unifiedStream#统计生成的随机数的分布情况result=unifiedStream.map(lambda x:(x[0],1)).reduceByKey(lambda x, y: x + y)result.pprint()ssc.start() # Start the computationssc.awaitTermination() # Wait for the computation to terminateif __name__ == '__main__':start()
Direct方式收取数据
# encoding:utf-8
__author__ = 'eric.sun'"""演示如何使用Spark Streaming 通过Kafka Direct Streaming实现WordCount执行命令:./spark-submit --master spark://server1-1-5-24-137:7077 --packages org.apache.spark:spark-streaming-kafka_2.10:1.6.0 ../examples/kafka_streaming.py > logKafka数据源程序:https://github.com/Eric-aihua/practise.git/java_cookbook/cookbook/src/main/java/com/eric/kafka/producer/ProcuderSample.java使用Direct的好处1:根据topic的分区数默认的创建对应数量的rdd分区数2:Receiver的方式需要通过Write AHead Log的方式确保数据不丢失,Direct的方式不需要3:一次处理:使用Kafka Simple API对数据进行读取,使用checkpoint对offset进行记录问题:基于Zookeeper的Kafka监控工具不能获取offset的值了,需要在每次Batch处理后,可以对Zookeeper的值进行设置"""from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtilsdef start():sconf=SparkConf()sconf.set('spark.cores.max' , 8)sc=SparkContext(appName='KafkaDirectWordCount',conf=sconf)ssc=StreamingContext(sc,2)brokers="server1-2-5-24-138:9092,server1-3-5-24-139:9092,server1-4-5-24-140:9092"topic='spark_streaming_test_topic'kafkaStreams = KafkaUtils.createDirectStream(ssc,[topic],kafkaParams={"metadata.broker.list": brokers})#统计生成的随机数的分布情况result=kafkaStreams.map(lambda x:(x[0],1)).reduceByKey(lambda x, y: x + y)#打印offset的情况,此处也可以写到Zookeeper中#You can use transform() instead of foreachRDD() as your# first method call in order to access offsets, then call further Spark methods.kafkaStreams.transform(storeOffsetRanges).foreachRDD(printOffsetRanges)result.pprint()ssc.start() # Start the computationssc.awaitTermination() # Wait for the computation to terminateoffsetRanges = []def storeOffsetRanges(rdd):global offsetRangesoffsetRanges = rdd.offsetRanges()return rdddef printOffsetRanges(rdd):for o in offsetRanges:print "%s %s %s %s %s" % (o.topic, o.partition, o.fromOffset, o.untilOffset,o.untilOffset-o.fromOffset)if __name__ == '__main__':start()调优总结
Spark streaming+Kafka的使用中,当数据量较小,很多时候默认配置和使用便能够满足情况,但是当数据量大的时候,就需要进行一定的调整和优化,而这种调整和优化本身也是不同的场景需要不同的配置。
- 合理的批处理时间(batchDuration):几乎所有的Spark Streaming调优文档都会提及批处理时间的调整,在StreamingContext初始化的时候,有一个参数便是批处理时间的设定。如果这个值设置的过短,即个batchDuration所产生的Job并不能在这期间完成处理,那么就会造成数据不断堆积,最终导致Spark Streaming发生阻塞。而且,一般对于batchDuration的设置不会小于500ms,因为过小会导致SparkStreaming频繁的提交作业,对整个streaming造成额外的负担。在平时的应用中,根据不同的应用场景和硬件配置,我设在1~10s之间,我们可以根据SparkStreaming的可视化监控界面,观察Total Delay来进行batchDuration的调整
- 合理的Kafka拉取量(maxRatePerPartition重要):对于Spark Streaming消费kafka中数据的应用场景,这个配置是非常关键的,配置参数为:spark.streaming.kafka.maxRatePerPartition。这个参数默认是没有上线的,即kafka当中有多少数据它就会直接全部拉出。而根据生产者写入Kafka的速率以及消费者本身处理数据的速度,同时这个参数需要结合上面的batchDuration,使得每个partition拉取在每个batchDuration期间拉取的数据能够顺利的处理完毕,做到尽可能高的吞吐量,而这个参数的调整可以参考可视化监控界面中的Input Rate和Processing Time
- 缓存反复使用的Dstream(RDD):Spark中的RDD和SparkStreaming中的Dstream,如果被反复的使用,最好利用cache,将该数据流缓存起来,防止过度的调度资源造成的网络开销。可以参考观察Scheduling Delay参数
- 设置合理的GC:长期使用Java的小伙伴都知道,JVM中的垃圾回收机制,可以让我们不过多的关注与内存的分配回收,更加专注于业务逻辑,JVM都会为我们搞定。对JVM有些了解的小伙伴应该知道,在Java虚拟机中,将内存分为了初生代(edengeneration)、年轻代young generation)、老年代(oldgeneration)以及永久代(permanentgeneration),其中每次GC都是需要耗费一定时间的,尤其是老年代的GC回收,需要对内存碎片进行整理,通常采用标记-清楚的做法。同样的在Spark程序中,JVMGC的频率和时间也是影响整个Spark效率的关键因素。在通常的使用中建议:–conf “spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC”
- 设置合理的CPU资源数:CPU的core数量,每个executor可以占用一个或多个core,可以通过观察CPU的使用率变化来了解计算资源的使用情况,例如,很常见的一种浪费是一个executor占用了多个core,但是总的CPU使用率却不高(因为一个executor并不总能充分利用多核的能力),这个时候可以考虑让么个executor占用更少的core,同时worker下面增加更多的executor,或者一台host上面增加更多的worker来增加并行执行的executor的数量,从而增加CPU利用率。但是增加executor的时候需要考虑好内存消耗,因为一台机器的内存分配给越多的executor,每个executor的内存就越小,以致出现过多的数据spill over甚至out of memory的情况
- 设置合理的parallelism:partition和parallelism,partition指的就是数据分片的数量,每一次task只能处理一个partition的数据,这个值太小了会导致每片数据量太大,导致内存压力,或者诸多executor的计算能力无法利用充分;但是如果太大了则会导致分片太多,执行效率降低。在执行action类型操作的时候(比如各种reduce操作),partition的数量会选择parent RDD中最大的那一个。而parallelism则指的是在RDD进行reduce类操作的时候,默认返回数据的paritition数量(而在进行map类操作的时候,partition数量通常取自parent RDD中较大的一个,而且也不会涉及shuffle,因此这个parallelism的参数没有影响)。所以说,这两个概念密切相关,都是涉及到数据分片的,作用方式其实是统一的。通过spark.default.parallelism可以设置默认的分片数量,而很多RDD的操作都可以指定一个partition参数来显式控制具体的分片数量。 在SparkStreaming+kafka的使用中,我们采用了Direct连接方式,前文阐述过Spark中的partition和Kafka中的Partition是一一对应的,我们一般默认设置为Kafka中Partition的数量。
- 使用高性能的算子:(1)使用reduceByKey/aggregateByKey替代groupByKe(2)使用mapPartitions替代普通map(3) 使用foreachPartitions替代foreach(4) 使用filter之后进行coalesce操作5 使用repartitionAndSortWithinPartitions替代repartition与sort类操作
- 使用Kryo优化序列化性能
主要有三个地方涉及到了序列化
- 在算子函数中使用到外部变量时,该变量会被序列化后进行网络传输(见“原则七:广播大变量”中的讲解)。
- 将自定义的类型作为RDD的泛型类型时(比如JavaRDD,Student是自定义类型),所有自定义类型对象,都会进行序列化。因此这种情况下,也要求自定义的类必须实现Serializable接口。
- 使用可序列化的持久化策略时(比如MEMORY_ONLY_SER),Spark会将RDD中的每个partition都序列化成一个大的字节数组。
对于这三种出现序列化的地方,我们都可以通过使用Kryo序列化类库,来优化序列化和反序列化的性能。Spark默认使用的是Java的序列化机制,也就是ObjectOutputStream/ObjectInputStream API来进行序列化和反序列化。但是Spark同时支持使用Kryo序列化库,Kryo序列化类库的性能比Java序列化类库的性能要高很多。官方介绍,Kryo序列化机制比Java序列化机制,性能高10倍左右。Spark之所以默认没有使用Kryo作为序列化类库,是因为Kryo要求最好要注册所有需要进行序列化的自定义类型,因此对于开发者来说,这种方式比较麻烦。
以下是使用Kryo的代码示例,我们只要设置序列化类,再注册要序列化的自定义类型即可(比如算子函数中使用到的外部变量类型、作为RDD泛型类型的自定义类型等):
// 创建SparkConf对象。 val conf = new SparkConf.setMaster(...).setAppName(...) //设置序列化器为KryoSerializer。
conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer") //注册要序列化的自定义类型。
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))