1.solr7����Ҫ��
solr7��Ҫjava8����������Ҫ�ڻ������������� JAVA_HOME������
2.solr ��װ
���ص�ַ https://lucene.apache.org/solr/mirrors-solr-latest-redir.html ������Ϊ7.4�汾
��solr5��ǰsolr����������tomcat��Ϊ���������Ǵ�solr5�Ժ�solr�ڲ�����jetty������������ͨ��binĿ¼�нű�ֱ�����������Ǵ�solr5�Ժ��solr4���������DZ�������һ��������Ӧ�á�
��solr5֮��solr��ʵ�ر����װ�װ���а�װ����֮���ڽ�ѹ��ֱ������bin��solr��solr��������ɵ������ˡ���


ע�⣺������ֱ���������б� log4j2.xml (�ļ�����Ŀ¼������������ȷ��) ����ʱ��û�����������Ӱ������
������ֱ�ӷ��� http://localhost:8983/solr/#/
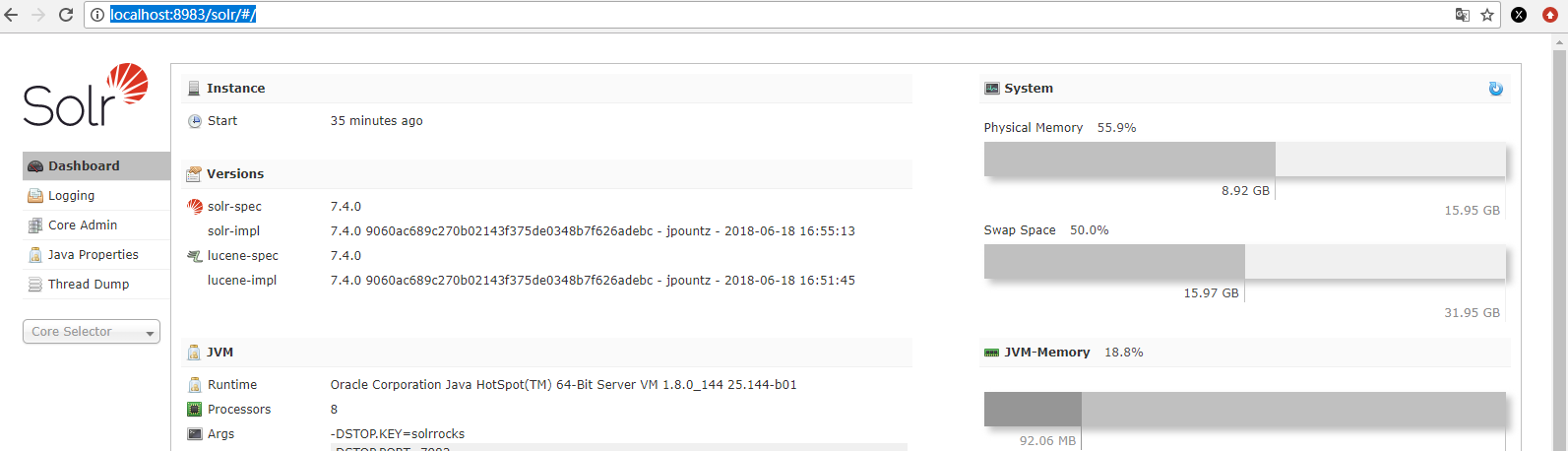
�������ҳ��ͱ�ʾsolr�����ɹ�
3.����core
���admin core ���봴��core���� ע�⣺������instanceDir��dataDir ����ڣ�������������solr-7.4.0\server\solr Ŀ¼����ȥ����Ŀ¼
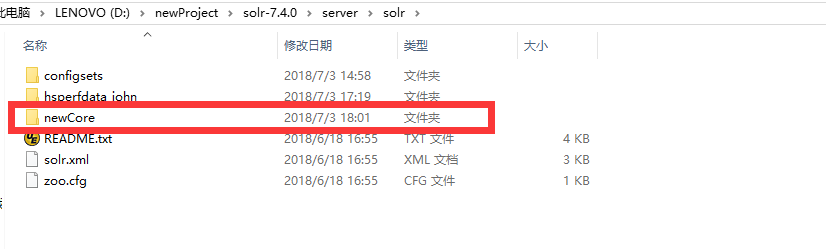
��Ŀ¼�µ�conf�ļ����ǿɴ�solr\configsets\sample_techproducts_configs�и���
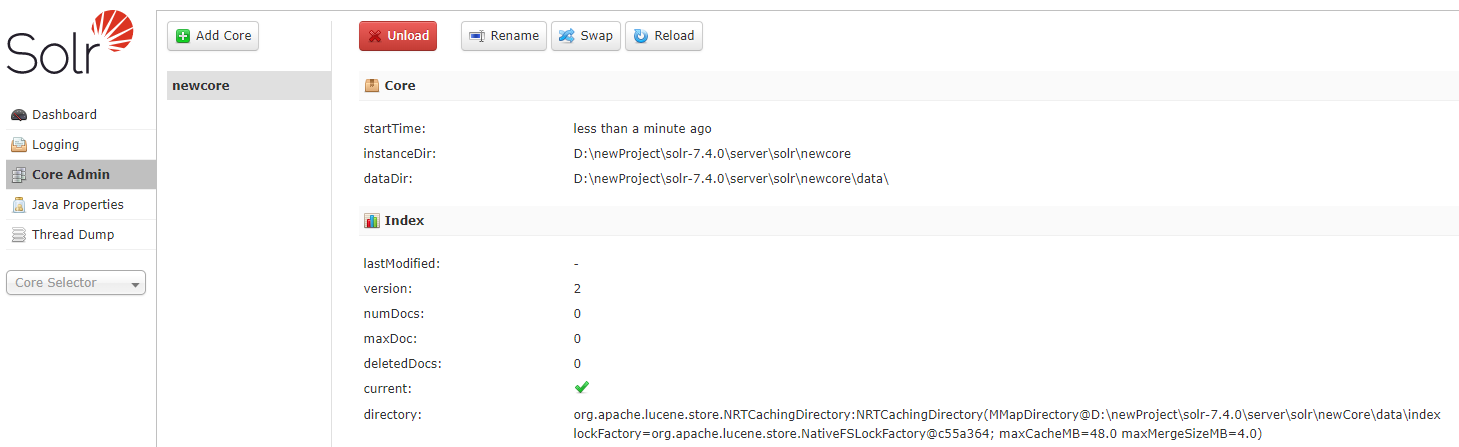
�������븴�ƺú���������ҳ���ϴ���core �����ɹ�
4.����IK�ִ�
���ص�ַ��https://pan.baidu.com/s/1Dbma2vAepBSsCag_EztTTw
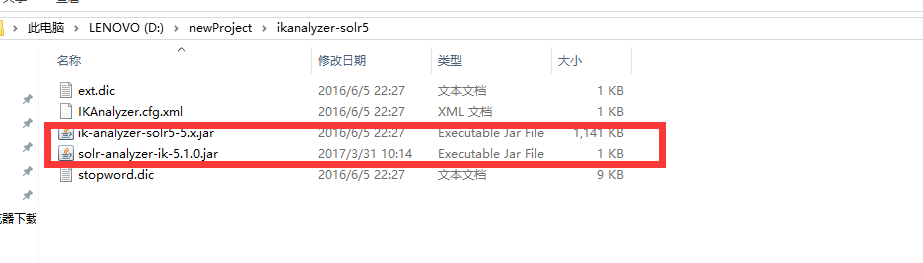
���ؽ�ѹ�� ������jar�ļ����Ƶ�solr-7.4.0\server\solr-webapp\webapp\WEB-INF\lib��
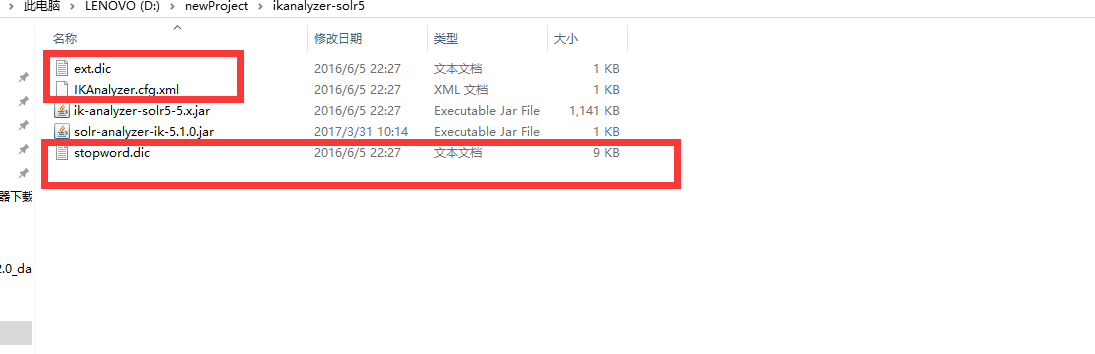
��solr-7.4.0\server\solr-webapp\webapp\WEB-INF\classesĿ¼���½�һ��classesĿ¼�������������ļ����ƽ�ȥ
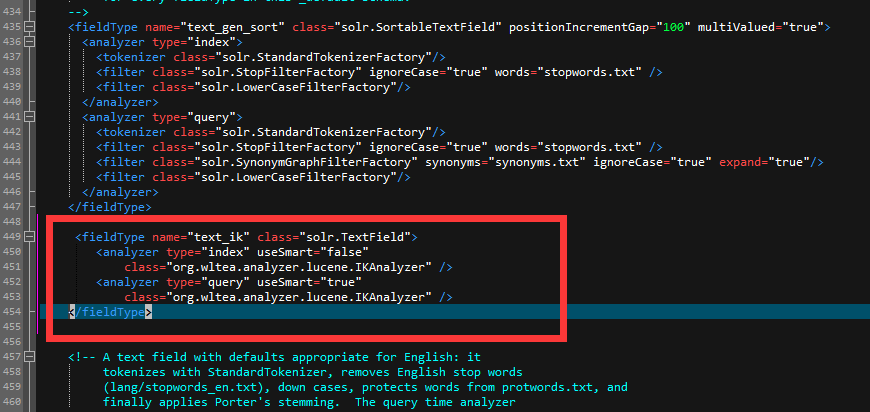
����֮ǰ������core ��solr-7.4.0\server\solr\newCore\conf�´�managed-schema.xml �������´��룺
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" useSmart="false"class="org.wltea.analyzer.lucene.IKAnalyzer" /><analyzer type="query" useSmart="true"class="org.wltea.analyzer.lucene.IKAnalyzer" /> </fieldType>
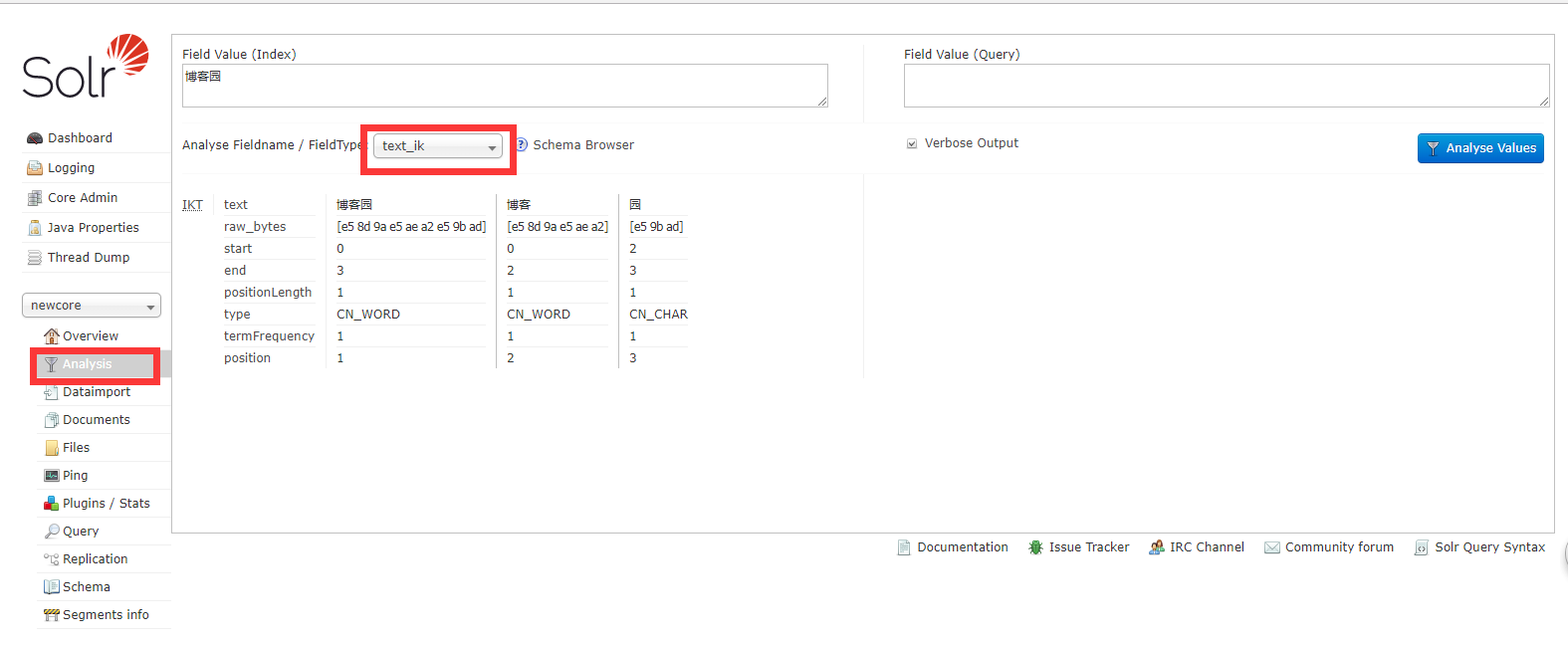
����solr ���·��� ѡ���֮ǰ������core
ѡ��Analysis ����Ҫ���������� ѡ��FieldTypeΪtext_ik ���Է��ִַʳɹ�