字典这个数据结构活跃在所有 Python 程序的背后,即便你的源码里并没有直接用到它。
--- A.M.Kuchling
什么是可散列的数据类型
- 如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变的,而且这个对象需要实现
__hash__()方法。另外可散列的对象还要有__qe__()方法,这样才能跟其他键做比较。如果两个可散列的对象是相等的,那么它们的散列值一定是一样的。 - 原子不可变数据类型(
str,bytes和数值类型) 都是可散列类型,frozenset也是可散列的。元组只有当它包含的所有元素都是可散列类型的情况下,它才是可散列的。
字典推导
一个例子
>>> A = [(1, 'a'), (2, 'b'), (3, 'c')]
>>> a_dict = {
number: val for number, val in A}
>>> a_dict
{
1: 'a', 2: 'b', 3: 'c'}
常见的映射方法
用 setdefault 处理找不到的键
一个例子
>>> index = {
}
>>> occurrences = index.get('hello', []) #第一次查询
>>> occurrences
[]
>>> occurrences.append(1)
>>> index['hello'] = occurrences # 第二次查询
而当使用 setdefault 时仅需查询一次。
>>> index = {
}
>>> index.setdefault('hello', []).append(1) # 只调用一次
>>> index['hello']
[1]映射的弹性键查询
- 为了方便起见,就算某个键在映射里不存在时,我们也希望在通过这个键读取值的时候能得到一个默认值。
defaultdict 处理找不到的键的一个选择
- 在实例化一个
defaultdict的时候,需要给构造方法提供一个可调用的对象,这个可调用对象会在__getitem__碰到找不到的键的时候被调用,让__getitem__返回某种默认值。 - 这个用来生成默认值的可调用对象存放在名为
default_factory的实例属性里。 - 所有这一切背后的功臣其实是特殊方法
__missing__。它会在defaultdict遇到找不到的键的时候调用default_factory, 而实际上这个特性是所有映射类型都可以选择去支持的。
一个例子
>>> import collections
>>> index = collections.defaultdict(list)
>>> index['hello'].append(1) #只调用一次
>>> index['hello']
[1]
注意
defaultdict里的default_factory只会在__getitem__里被调用,在其他方法里面完全不会发挥作用。比如dd是个defaultdict,k是个找不到的键,dd[k]这个表达式会调用default_factory创造某个默认值,而dd.get(k)则会返回None。
特殊方法 __missing__
- 当有一个类继承了
dict, 然后这个继承类提供了__missing__方法,那么在__getitem__碰到找不到的键的时候,Python就会自动调用它, 而不是抛出一个KeyError异常。
注意
__missing__ 方法只会被 __getitem__ 调用 (比如在表达式d[k]中)。 提供 __missing__ 方法对 get 或者 __contains__ (in 运算符会用到这个方法) 这些方法的使用没有影响。
一个例子
class MyDict(dict):def __missing__(self, key):return "missing..."def get(self, key, default=None):try:return self[key]except KeyError:return defaulta = MyDict()print(a['apple'])
print(a.get('apple'))
print('apple' in a)""" output: missing... missing... False """
字典的变种
collectios.OrderedDict
- 添加键的时候会保持顺序,因此键的迭代次序总是一致的。
collectios.ChainMap
- 该类型可以容纳数个不同的映射对象,然后在进行键查找操作的时候,这些对象会被当作一个整体被逐个查找,直到键被找到位置。
一个例子
Python 3.6.9 (default, Apr 18 2020, 01:56:04)
[GCC 8.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from collections import ChainMap
>>> a = {
"x":1, "z":3}
>>> b = {
"y":2, "z":4}
>>> c = ChainMap(a, b)
>>> c
ChainMap({
'x': 1, 'z': 3}, {
'y': 2, 'z': 4})
>>> c['x']
1
>>> c['z']
3
>>> c['z'] = 8
>>> c
ChainMap({
'x': 1, 'z': 8}, {
'y': 2, 'z': 4})
collections.Counter
- 这个映射类型会给键准备一个整数计数器,每更新一个键的时候都会增加这个计数器。
一个例子
>>> import collections
>>> ct = collections.Counter('absfbababsdgva')
>>> ct
Counter({
'a': 4, 'b': 4, 's': 2, 'd': 1, 'g': 1, 'f': 1, 'v': 1})
>>> ct.update('asbsababaera')
>>> ct
Counter({
'a': 9, 'b': 7, 's': 4, 'e': 1, 'd': 1, 'g': 1, 'f': 1, 'r': 1, 'v': 1})
collections.UserDict
- 这个类其实就是把标准
dict用纯Python 又实现了一遍。 UserDict是让用户继承写子类的。
不可变映射类型
- 从 Python3.3 开始,
types模块中引入了一个封装类名叫MappingProxyType。 如果给这个类一个映射, 它会返回一个只读的映射视图。虽然是个只读视图,但它是动态的。这意味着如果对原映射做出了改动,我们能够通过这个视图观察到,但无法通过这个视图对原映射做出修改。
一个例子
Python 3.6.9 (default, Apr 18 2020, 01:56:04)
[GCC 8.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from types import MappingProxyType
>>> d = {
1:'A'}
>>> d_proxy = MappingProxyType(d)
>>> d_proxy
mappingproxy({
1: 'A'})
>>> d_proxy[2] = 'B'
Traceback (most recent call last):File "<stdin>", line 1, in <module>
TypeError: 'mappingproxy' object does not support item assignment
>>>
>>> d[2]='B'
>>> d_proxy
mappingproxy({
1: 'A', 2: 'B'})
集合
集合的初始化
>>> s = {
1} # 更快
>>> type(s)
<class 'set'>
>>> s
{
1}
>>> s = set([1]) # 慢
>>> s
{
1}
用 dis.dis (反汇编函数)来看看两个方法的字节码的不同
>>> from dis import dis
>>> dis('{1}')1 0 LOAD_CONST 0 (1)2 BUILD_SET 14 RETURN_VALUE
>>> dis('set([1])')1 0 LOAD_NAME 0 (set)2 LOAD_CONST 0 (1)4 BUILD_LIST 16 CALL_FUNCTION 18 RETURN_VALUE
- 前者更快更易读,Python 会利用一个专门的叫作
BUILD_SET的字节码来创建集合。 - 后者Python必须先从 set 这个名字查询构造方法,然后新建一个列表,最后再把这个列表传入到构造方法里。
集合推导
一个例子
>>> s = {
i for i in range(3, 40)}
>>> s
{
3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39}
dict 和 set 的背后
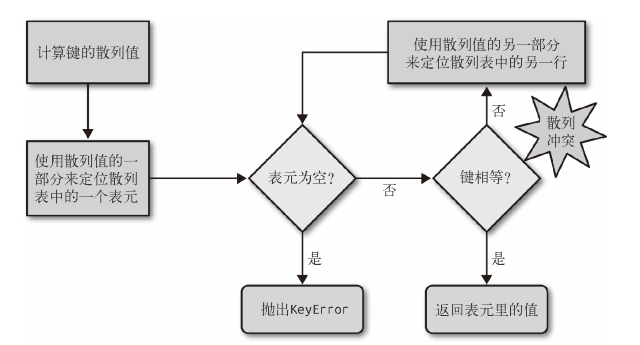
散列表
- 散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组),在一般的数据结构教材中,散列表里的单元通常叫作表元(bucket)。在
dict的散列表当中, 每个键值对都占用一个表元,每个表元都有两个部分,一个是对键的引用,另一个是对值的引用。因为所有标语那的大小一致,所以可通过偏移量来读取某个表元。 - Python 会设法保证大概有三分之一的表元是空的,所以在要达到这个阈值的时候,原有的散列表会被复制到一个更大的空间里面。
散列值和相等性
- 内置的
hash()方法可以用于所有的内置类型对象。 如果是自定义对象调用hash()的话,实际上运行的是自定义的__hash__。如果两个对象在比较的时候是相等的,那它们的散列值必须相等,否则散列表就不能正常运行了。
散列表算法
dict 的实现及其导致的结果
-
键必须是可散列的, 一个可散列的对象必须满足一下要求。
- 支持
hash()函数,并且通过__hash__()方法所得到的散列值是不变的。 - 支持通过
__eq__()方法来检测相等性。 - 若
a == b为真, 则hash(a) == hash(b)也为真。
- 支持
-
字典在内存上的开销巨大。
-
键查询很快
-
键的次序取决于添加顺序
-
往字典里添加新键可能会改变已有键的顺序
-
不要对字典同时进行迭代和修改。
set 的实现以及导致的结果
- 集合里的元素必须是可散列的。
- 集合很消耗内存。
- 可以很高效地判断元素是否存在于某个集合。
- 元素的次序取决于被添加到集合里的次序。
- 往集合里添加元素,可能会改变集合里的已有元素的次序。
终于写完了,下一章将会介绍文本和字节序列。