�����Ķ�����Semantic Soft segmentation

���ļ��
��Semantic Soft segmentation����Ҫ�����һ�����ھ�ȷ��ʾ�����ɣ�soft transitions���ķ�����ͨ���������������ָSemantic Soft Segmentation�� ��дΪSSS���ĸ�������ȷ��ʾ�����ɡ�SSS��һ���Ӧ��ͼ������������������ĵ�layers�����ڸ��Ӷ����б��ֳ���ȷ�������� ��
? ���ߴ������ĽǶȴ����������ָ����⡣����������ͼ�����������ɫ��Ϣ��ͨ��ʹ��ѵ�����ڳ��������ľ������������ɵĸ�������Ϣ���ϡ����������һ��ͼ�ṹ������Ӧ��Laplacian��������������н�ʾ��������Լ�����֮��������ɡ����ͨ������һ���ռ�仯�IJ�ϡ���ģ�ͣ���ģ�Ϳ��Ը��������������ɸ������IJ㣬������ͼ��༭��������ʾ��ʹ��soft segments�������ɵ���ɸ��ӵ�ͼ��༭����
����������
��������ͼ���Զ����������ָ��������ֽ�Ϊ��ʾ����������IJ�ͬ�㣬������������Ⱥ������������ɡ�
ÿһ���ÿһ������ͨ��ʹ����������[0,1]\alpha \in [0,1]����[0,1]������ǿ��ʾ����=0\alpha=0��=0��ʾ��ȫ������=1\alpha=1��=1��ʾ��ȫ�������м�ֵ���ʾ��ͬˮƽ�IJ������ȡ�ʹ��һ�����ӵ�ͼ��ģ�ͽ���������
(R,G,B)input=��i��i(R,G,B)i��i��i=1(R,G,B)_{input}=\sum_i \alpha_i(R,G,B)_i\\ \sum_i \alpha_i=1 (R,G,B)input?=i��?��i?(R,G,B)i?i��?��i?=1
�����������RGB���ر�ʾΪ��ÿ����iii �ж�Ӧ��Ȩ����i\alpha_i��i?�µĺͣ�����Լ����\alpha����ÿ�������еĺ�Ϊ1��
���ĵķ�����spectral matting������ͬ��ʽ������ͨ�������ָʽ��Ϊһ�����������������⡣���еĺ��IJ�����Laplacian����LLL�Ĺ�����LLL���Ա�ʾͼ����ÿ����������ͬһ���ָ�Ŀ����ԡ�spectral matting��ʹ�õͼ��ľֲ�ɫ�ʷֲ���������ʹ�÷Ǿֲ���Ϣ��������Ϣ����ǿ���������
����֪ʶ
Spectral matting
? ���ĵķ��������� Levin���˵Ĺ����ϣ�Levin�����״������matting Laplacian�ĸ��ͨ��ʹ�þֲ���ɫ�ֲ�������һ������ LLL �����������һ��local batch �ϻ�ȡÿ�����ص����й�ϵ�����͵���5��5��batch��������������������û�Լ��ʱ����С�����κ��� ��?TL��?\vec\alpha^TL\vec\alpha��TL�������� ��?\vec\alpha����ʾһ��������� ��\alpha��ֵ�������ѧ��ʽ��������LLLС����ֵ��Ӧ�������Ը�����mattes�к���Ҫ�����á����������Ľ��ۣ����Ǻ���ʹ����Щ�������������ָÿһ�����ָ��� LLL��KKK ����С����ֵ��Ӧ������������ϣ��������matting sparsity�����磺��С�����ֲ����ij��֡��ָ�����С��һ����������=0or1\alpha=0\ or\ 1��=0 or 1����������ȷ����
arg?min?y?i��i,p(�O��ip�O��+�O1?��ip�O��),with��?i=Ey?i,subjectto:��i��ip=1\arg \min \limits_{\vec y_i}\sum\limits_{i,p}(|\alpha_{ip}|^\gamma+|1-\alpha_{ip}|^\gamma),with\ \vec\alpha_i=E\vec y_i,\ \ subject\ to:\sum\limits_i \alpha_{ip}=1 argy?i?min?i,p��?(�O��ip?�O��+�O1?��ip?�O��),with ��i?=Ey?i?, subject to:i��?��ip?=1
���� ��ip\alpha_{ip}��ip? �ǵ� iii ���ָ�ĵ� ppp �������ϵ� ��\alpha��ֵ�� EEE �� KKK ����С�����������ɵľ���y?i\vec y_iy?i?����Ӧ��Ȩ����������\gamma�� ��һ������ϡ�������һ����������
? spectral matting��ʶ�����һ������ʱ���Ժܺò�������Ľ����������Ҫ�����Ǵ����ೡ���Ͷ����������������Ҫ��ԭ�л��������Ӹ��Ӹ�����Ϣ��
Affinity and Laplacian matrices
Levin���˽�������ʽ��һ����С�����Ż����⣬��ֱ������һ��Laplacian����һ������ķ����DZ���ÿһ������֮��Ĺ�ϵ(Affinity) [Aksoy et al.2017a]. ������������ص����ض��и���Ŀ�������ͬ�� ��\alpha��ֵ��0������ص����ض��Ƕ����ģ������ƹ�ϵ�����ض�Ӧ���в�ͬ��ֵ�����IJ��õ��ǹ�ϵ��һ�������ݴ˶�Ӧһ��������Laplacian����
L=D?12(D?W)D?12L=D^{-\frac{1}{2}}(D-W)D^{-\frac{1}{2}} L=D?21?(D?W)D?21?
���� WWW�ǰ����������ضԽ��ƹ�ϵ�ķ���D����һ���Ⱦ����ǶԽǾ���
�Ǿֲ���ɫ��ϵ(Nonlocal Color Affinity)
? Ϊ�˱�ʾ�ϴ�Χ�����ض�֮��Ĺ�ϵ�����߶�����һ�����ӵĵͼ���ϵ��(low-level affinity term)����������˻���ͼ��Ĺ��ȷָover-segmentation��������������guided sampling����ʹ��SLIC[Achanta et al.2012] ����2500�������أ�Ȼ������������֮��Ľ��ƹ�ϵ (Affinity)������������һ���뾶�ڵ����г����ض�Ӧ��ͼ��СС��20%�����ַ������ŵ���ÿ���������㹻�����Ϊ�����أ���ϡ������Ȼ�ܸߣ���Ϊʹ�õ���ÿ�������صĵ������������ҿ���ʹ�ýϴ�İ뾶���ӿ��ܶϿ������������������С��20%��ͼ��ߴ�ľ���ָ�ij����� sss �� ttt ���������ǵ����ĵ���ɫ��ϵ��color affinity��ws,tCw_{s,t}^Cws,tC?��
ws,tC=(erf(ac(bc?��cs?ct��))+1)/2w_{s,t}^C=(erf(a_c(b_c-\parallel c_s-c_t\parallel))+1)/2 ws,tC?=(erf(ac?(bc??��cs??ct?��))+1)/2
���� cs,ct��[0,1]c_s,c_t\in [0,1]cs?,ct?��[0,1] �dz����صľ�ֵ��ɫ, erf �Ǹ�˹������ac,bca_c, b_cac?,bc? �ǿ���affinity�½������ʺͱ�Ϊ0����ֵ��
����ʹ�õIJ���ֵΪ: ac=50,bc=0.05a_c=50, b_c =0.05ac?=50,bc?=0.05.
���ֹ�ϵ�����ϱ�֤����ɫ�dz����Ƶ������ڸ��ӳ����ṹ�е������ԣ���Ч������ͼ��

�������ϵ��High-Level Semantic Affinity��
? ��Ȼ�Ǿֲ���ɫ��ϵ�ڷָ���������˽ϴ�Χ������ã�������Ȼ��һ���ͼ�������ʵ���������û�и�����Ϣ������£��ָ���Ȼ�����ϲ����ڲ�ͬ�������ɫ���Ƶ�ͼ������Ϊ�˴��������������������Ƶ�Ƭ�Σ�����������һ�������ϵ��������������ͬһ������������ؽ��з��飬������ֹ���Բ�ͬ��������ؽ��з��顣���ǻ��ڶ���ʶ�������е���ǰ������������ײ������ص�ÿ�����ص�����������ͨ��ʹ�������������Ӧ�����������ɵ���������Ӧ��ʹ�ã�����������ص� ppp �� qqq ���ڵ���ͬ�Ķ��� fpf_pfp? �� fqf_qfq?, ��ô�� ��fp?fq�Ρ�0\parallel f_p -f_q \parallel\equiv 0��fp??fq?����0�����ҶԲ�ͬ�ָ�����ĵ��������� rrr ��$ f_rӦ��ԶԶ��ͬ��Ӧ��ԶԶ��ͬ��Ӧ��ԶԶ��ͬ��\parallel f_p-f_q\parallel\ll \parallel f_p-f_r\parallel$
? ����ÿ�������� sss�����ǽ����ľ�ֵ�������� f~s\widetilde f_sf
?s?��������ϵ�������������ǿ������������������������������s,ts, ts,t֮��Ĺ�ϵ��
ws,tS=erf(as(bs?��f~s?f~t��))w_{s,t}^S=erf\left(a_s(b_s-\parallel \widetilde f_s-\widetilde f_t\parallel)\right) ws,tS?=erf(as?(bs??��f
?s??f
?t?��))
����֮���Ч�����£�
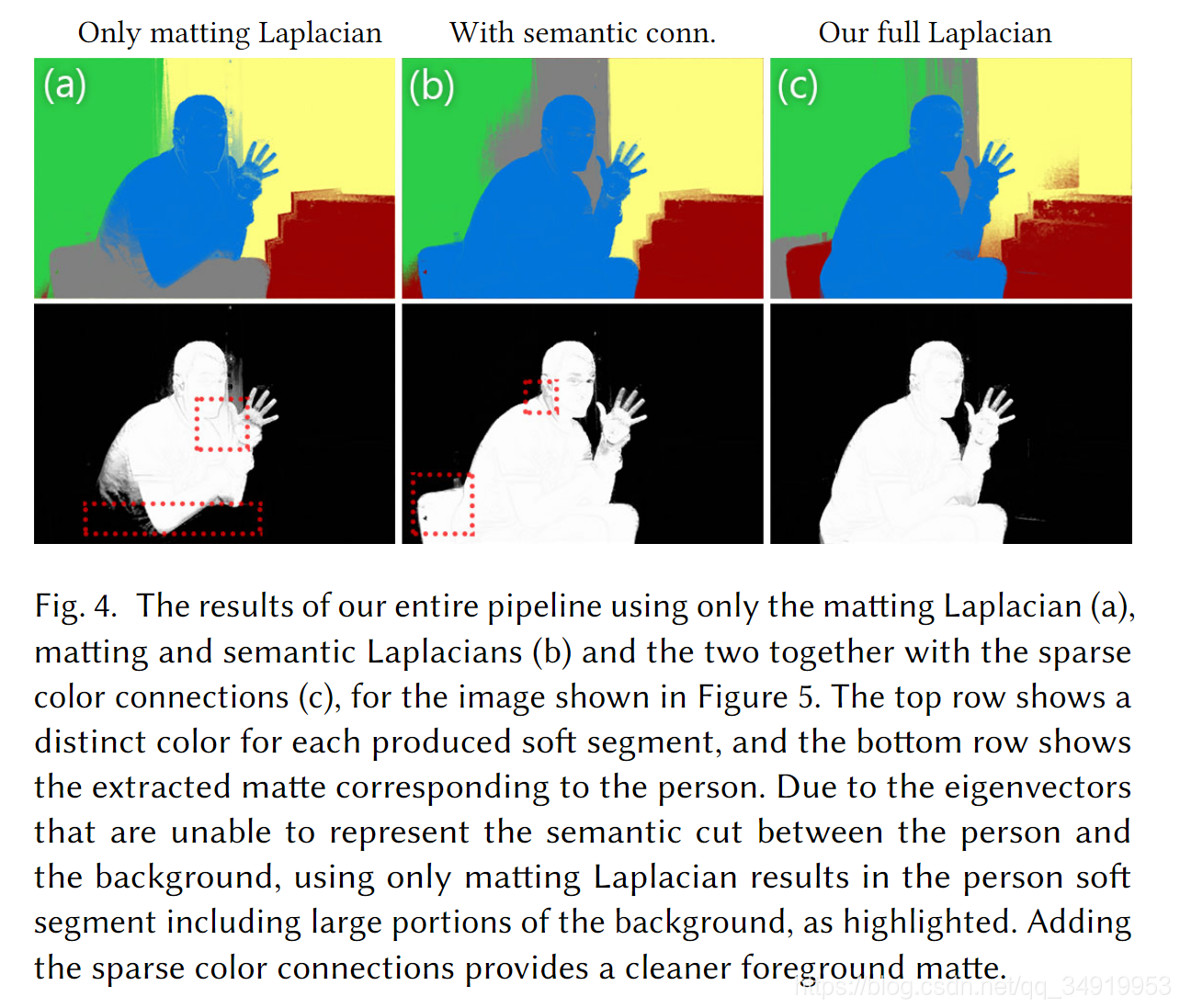
ͼ���Ľ���(Creating the Layers)
Laplacian������γ�(Forming the Laplacian matrix)
����Laplacian����ͨ��֮ǰ���ӵĹ�ϵ�����У�
L=D?12(D?(WL+��SWS��CWC))D?12L=D^{-\frac{1}{2}}(D-(W_L+\sigma_SW_S\sigma_CW_C))D^{-\frac{1}{2}} L=D?21?(D?(WL?+��S?WS?��C?WC?))D?21?
���� WLW_LWL?�ǰ���matting��ϵ�ľ���WCW_CWC? �ǰ����Ǿֲ���ɫ��ϵ�ľ���WSW_SWS? �ǰ��������ϵ�ľ�����S,��C\sigma_S, \sigma_C��S?,��C? �ǿ�����Ӧ����Ӱ�����IJ�����ȫ������Ϊ0.01
ϡ�軯Լ��(Constrained sparsification)
��ȡ LLL �����100����С����ֵ��Ӧ����������������ʽ���Ż��������� ��=0.8\gamma =0.8��=0.8
arg?min?y?i��i,p(�O��ip�O��+�O1?��ip�O��),with��?i=Ey?i,subjectto:��i��ip=1\arg \min \limits_{\vec y_i}\sum\limits_{i,p}(|\alpha_{ip}|^\gamma+|1-\alpha_{ip}|^\gamma),with\ \vec\alpha_i=E\vec y_i,\ \ subject\ to:\sum\limits_i \alpha_{ip}=1 argy?i?min?i,p��?(�O��ip?�O��+�O1?��ip?�O��),with ��i?=Ey?i?, subject to:i��?��ip?=1
��ֱ��������������ʹ��k-means��������ʼ��spectral matting��ͬ������������������ fff ��ʾ������ʹ��k-means���ࡣ�����ij�ʼ���볡�����������һ�£����ҿ��Բ������õ����ָ��ʵ���У����������������40�㣬��ȥ������Ҫ��15-25�㡣��ʹ�� k=5k=5k=5 ��k-means�㷨����һ��������ƽ������������ʾ�IJ���Ҫ�㡣���ַ�����ֱ�ӽ�100����������ϡ�軯Ϊ5����ã���Ϊ���ּ�����ٻ�ʹ�������Լ�����Ҳ�������õĽ�����ر�����mattte sparsity���档���⣬��ʧһ���ԣ����Խ��ָ�������Ϊ5����Ȼ������ֿ������û����ݳ������ã����Ǹ��ݹ۲죬��Դ����ͼ����˵���Ǻ����ġ���Ϊ��5���㱻Լ�������������������������ӿռ��ڣ��������ȵ�ϡ�����Ǵ��ŵģ��ڲ�����������İ�������������ͨ�������Dz����ܵġ�
Լ���Աȼ���ͼ��

�ſ�ϡ�軯(Relaxed sparsification)
Ϊ�˸��Ʋ��ϡ���ԣ�ѡ��ſ���������������������ϵ�Լ��������ͨ������ϵ�� yi?y_i?yi?? ������������ͨ������ ��\alpha����
���ȣ��ſ��ӿռ�Լ�������ҽ�ȷ�����ɵIJ㱣�ֿ���ʹ��ϡ�軯Լ�������д����IJ� ��^\hat{\alpha}��^��
EF=��ip(��ip?��^ip)2E_F = \sum\limits_{ip}(\alpha_{ip}-\hat{\alpha}_{ip})^2 EF?=ip��?(��ip??��^ip?)2
ͬʱ�ſ��ۼ�Ϊ1��Ҫ����Ϊ��Լ�����ɵ�����ϵͳ�У�
EC=��p(1?��i��ip)2E_C=\sum\limits_{p}\left(1-\sum\limits_{i}\alpha_{ip}\right)^2 EC?=p��?(1?i��?��ip?)2
���У���ip\alpha_{ip}��ip? ��ʾ�ڵ� iii ���ϵ� ppp �����ص� ��\alpha�� ֵ��������Laplacian LLL������������������� L=D?12(D?(WL+��SWS��CWC))D?12L=D^{-\frac{1}{2}}(D-(W_L+\sigma_SW_S\sigma_CW_C))D^{-\frac{1}{2}}L=D?21?(D?(WL?+��S?WS?��C?WC?))D?21? �Ŀռ䴫����
EL=��i��?iTL��?iE_L = \sum \limits_{i}\vec\alpha_i^TL\vec \alpha_i EL?=i��?��iT?L��i?
��������ƶ���һ����Ӧͼ�����ݵ�ϡ�������ֱ�۵أ�������������ͼ���е���ɫ���ɣ���Ϊ����������£�����Ӧ����������Ԫ��֮��Ĺ��ɣ����磬̩���ܺͱ���֮���ģ�����ɡ� ����ʹ�����ֹ۲�������һ���ռ�仯��ϡ��������
ES=��i,p�O��ip�O��~p+�O1?��ip�O��~pwith��~p=min?(0.9+��?cp��,1)E_S=\sum\limits_{i,p}|\alpha_{ip}|^{\widetilde \gamma_p}+|1-\alpha_{ip}|^{\widetilde \gamma_p}\ with\ \widetilde \gamma_p=\min(0.9+\parallel \nabla c_p\parallel,1) ES?=i,p��?�O��ip?�O��
?p?+�O1?��ip?�O��
?p? with ��
?p?=min(0.9+��?cp?��,1)
����Щ�����һ�𣬿��Եõ���
E=EL+ES+EF+��ECE=E_L+E_S+E_F+\lambda E_C E=EL?+ES?+EF?+��EC?

������������(Semantic Feature Vectors)
�ڸ߲���������ʱ����ͬ��������ص������������ƣ���ͬ��������ص�����������ͬ.
���������Dz�������ָ���������ģ��ѵ�������ɵ�.
��������� DeepLab-ResNet-101 ��Ϊ������ȡ����������ѵ���Dz��õ��Ƕ���ѧϰ���������ͬ������������ L2 ����(������ N-Pair loss)
�� COCO-Stuff ���ݼ��Ͻ�������ָ������ѵ��. ���� guided filter ���������ɵ� feature map ��ͼ����б�Ե����. Ȼ����� PCA ���� feature map ά�ȵ� 3. ���һ����������ֵ�� [0, 1].
