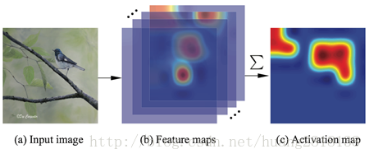
聚合(aggregation)指的是在Backbone输出的特征图聚合成一个特征向量来表征一个目标。,如下图表示的GAP。
1、Attention pooling
Attention是近年来比较热门的一个方向,它最初源于computer vision领域,是模仿人类视觉的一个杰出成果。人类的眼睛在观察图像是并不会一视同仁,而是将attention放在真正感兴趣的部分。如果机器可以学会只学习最有用的部分,无疑将大大提高学习效率。这就是attention机制想要实现的。
Attention最经典的用法是通过一个分支学习mask,并将mask点乘到原图上,将注意力集中在图中可以表征物体信息的位置上。
2、Avg Pooling
Avg Pooling,也称为Global Avg Pooling,是ReID中最常见的操作之一,将特征全局平均池化为一个特征向量,用该特征向量来表征目标。
3、Max Pooling
最大池化(max pooling),同理平均池化,在最后输出的特征图中找到值最大的特征向量来表征目标。
4、Gem Pooling
介于mean pooling和max pooling之间,二者是其特殊形式.通过调节参数p,可以关注不同细度的区域
公式:

Pk是可以学习的参数,在pk = 1时为平均池化,在pk趋于无穷的时候为最大池化。
5、R-MAC
R-MAC(Regional Maximum Activation of Convolutions)来自于2015年发表在cs.CV上的论文《PARTICULAR OBJECT RETRIEVAL WITH INTEGRAL MAX-POOLING OF CNN ACTIVATIONS》,是基于卷积的区域最大激活计算特征向量。
Backbone网络最后输出为WxHxC大小的图片,R-MAC对此特征提取可以表示为下式:
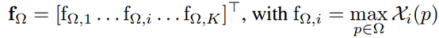
其中?代表各个局部区域,p是某一个具体的局部区域,Xi是第i个通道提取特征的算法(如上述的pooling方法),上式计算出了各个通道中值最大的局部区域。
该方法提取了原始图中最重要的区域,这就是Regional Maximum activations of convolutions (R-MAC),可译为局部最大化卷积激活特征。
6、SPoC
SPoC操作来自于发表在ICCV 2015的《Aggregating deep convolutional features for
image retrieval》,这个方法用到了加权的方法,对靠近中心的权重给大,对远离的权重给小,再做Avg Pooling。
7、CroW
CroW来自于ECCVW 2016《Cross-dimensional weighting for aggregated deep convolutional features》一文,提出了一种用于空间和通道的加权池方法。
空间上的加权方法和SPoC一致,区别在于CroW 使用的深度卷积网络的最后一个池化层的输出,SPoC使用的是最后一个卷积层的输出。SPoC在spatial weighting时,首先使用了中心化操作,CroW则从当层输出的空间激励项spatial activations得到spatial weighting。再通道上,CroW使用的是从通道稀疏中得到 channel weighting(具体获得方式可以去看论文)。
8、局部特征聚合
发表在ACCV2018的《SCPNet: Spatial-Channel Parallelism Network for Joint Holistic and Partial Person Re-Identification》提出了一个聚合局部特征的方式,如下图所示,将特征进行拼接,并构建相应的损失函数进行学习,这体现在结构上,而不是pooling操作上,是一种非全局的特征聚合方式。

9、SCDA
SCDA发表于IEEE TIP 2017的《Selective convolutional descriptor aggregation for fine-grained image retrieval》,主要思想是基于无监督的注意力机制获得每一个特征图的局部描述,再根据特征映射激活的总和保留有用的深度描述符,作为特征向量。在旷视PyRetri开源库中有集成,实际上也是可以应用在ReID的一种特征聚合方法。