ReID任务在大多数情况下都是多任务学习,主流是分为两个任务,一个是构建id loss,通过分类损失,来学习对应不同id的损失,另一种是triple loss为主的通过特征向量直接构建的损失,学习类内的相似性和类内的区分性,让不同的特征向量直接的区分度更高,让相同的特征向量更加趋同。
1、Cross-entropy loss
交叉熵是常见的分类损失,用来描述了两个概率分布之间的距离,当交叉熵越小说明二者之间越接近。
1)普通交叉熵损失
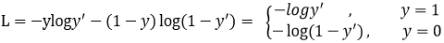
y’是经过激活函数的输出,所以在0-1之间。可见普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。
2)label smooth
当然在ReID的过程中还是存在很多的负样本,类别越多负样本的数量越大,为了做好负样本的损失构建而不是忽略负样本,可以在交叉熵中引入label smooth的操作,与传统交叉熵不同,不强制将类别考虑为0/1,而是有一定概率计算,具体公式如下:
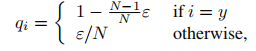
目的是由于一些id的图片量太少了,防止过度拟合训练集。这个策略也是提高了模型的泛化能力的,防止对训练集中的类别过度拟合,根据查阅资料这个也是一个好的策略。
3)Focal loss
普通的交叉熵损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。而focal loss对这个问题做了一定的优化,减少简单样本的损失占比,提高难样本的损失占比。
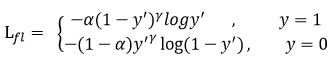
2、Triplet loss
Triplet loss最初是在FaceNet的论文中提出,可以较好地学到人脸的embedding,相似的图像在embedding空间里是相近的,可以判断是否是同一个人脸。其训练目标是使具有相同标签的样本在embedding空间尽量接近,使具有不同标签的样本在embedding空间尽量远离。
1)普通triplet loss
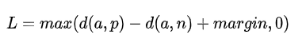
其中,a:anchor 原点
p:positive 与a同一类别的样本
n:negative 与a不同类别的样本
2)难样本采样三元组损失(Triplet loss with batch hard mining, TriHard loss)
难样采样三元组损失(本文之后用TriHard损失表示)是三元组损失的改进版。传统的三元组随机从训练数据中抽样三张图片,这样的做法虽然比较简单,但是抽样出来的大部分都是简单易区分的样本对。如果大量训练的样本对都是简单的样本对,那么这是不利于网络学习到更好的表征。大量论文发现用更难的样本去训练网络能够提高网络的泛化能力,而采样难样本对的方法很多。论文提出了一种基于训练批量(Batch)的在线难样本采样方法――TriHard Loss。
TriHard损失的核心思想是:对于每一个训练batch,随机挑选 P 个ID的行人,每个行人随机挑选 K 张不同的图片,即一个batch含有 P×K 张图片。之后对于batch中的每一张图片 a ,我们可以挑选一个最难的正样本和一个最难的负样本和 a 组成一个三元组。

其中 α 是人为设定的阈值参数。TriHard损失会计算 a 和batch中的每一张图片在特征空间的欧式距离,然后选出与 a 距离最远(最不像)的正样本 p 和距离最近(最像)的负样本 n 来计算三元组损失。通常TriHard损失效果比传统的三元组损失要好。
3、Arcface loss
Arcface来自于《ArcFace: Additive Angular Margin Loss for Deep Face Recognition》 一文,是Amsoftmax的改进版本,而Asoftmax又是Amsoftmax的改进版本。
Asoftmax的计算公式为:
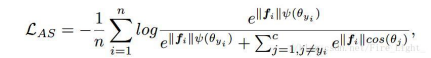
其中,
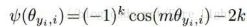
而在Amsoftmax中,作者认为,Asoftmax是用m乘以θ,而AMSoftmax是用cosθ减去m,这是两者的最大不同之处:一个是角度距离,一个是余弦距离。使用传统的Softmax的时候,角度距离和余弦距离是等价的。
但是当我们试图要推动决策边界的时候,角度距离和余弦距离就有所不同了。最终的决策边界是和余弦相关的,根据cos的性质,优化角度距离比优化余弦距离更有效果,因为余弦距离相对更密集之所以选择cosθ-m而不是cos(θ-m),这是因为我们从网络中得到的是W和f的内积,如果要优化cos(θ-m)那么会涉及到arccos操作,计算量过大。
所以Amsoftmax的计算公式:

在Arcface中,这个工作的作者认为角度距离比余弦距离在对角度的影响更加直接,又将损失改进为以下公式:
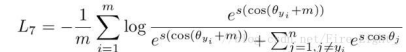
4、Circle loss
Circle loss是CVPR 2020 的一篇工作,在损失上统一了triplet loss和id loss。
本文提出了基于一对相似性优化的深度特征学习方法,以此来最大化类内相似性 ,最小化类间相似性 。我们发现大部分损失函数(Triplet Loss,Softmax Loss)将 ,嵌入到相似对中并缩小(-)因为每个相似性分数上的惩罚强度被限制为相等,因此这种优化方法是不灵活的。而正常情况是,如果相似性分数远远偏离了最佳值,就应该赋予更大的惩罚强度。为此,我们只需要对每个相似性重新加权,以强调优化程度低的相似性分数。由于它的决策边界是圆形的而得名Circle Loss。Circle Loss对于两种基本的深度特征学习方法(类别标签和样本对标签)有统一的公式。分析表明,相比于损失函数优化(-),Circle Loss为更明确的收敛目标提供了一种更灵活的优化方法。
最终公式如下:

这个的数学推导有点麻烦,可参考:https://zhuanlan.zhihu.com/p/120676832
作者在github中也提到了,在很多任务中,circle loss都有不错的表现。