1、Rank1(CMC,Cumulative Matching Characteristics)
Rank1是我们在阅读ReID相关论文中最常见的两个指标之一,它的计算如下:
1)首先定义一个指示函数表示 q,i 两张图片是否具有相同标签:
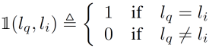
2)那么计算rank1时,只需统计所有查询图片与他们的第一个返回结果是否相同,Q为全体查询图片query的集合, 为q这张查询图片对应的图像库中第 i 个返回结果的标签:
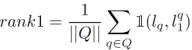
Rank1可以表示图像的第一检索目标的准确率,同样的计算方式也可以获得Rank5,Rank10等指标。
2、MAP
在ReID中MAP表示所有检索结果的准确率,是常用的两个ReID指标之一。计算过程如下:
1)P:精度,即对某一张probe图片,计算前k个返回结果中与查询图片相同ID的数量比例。
2)AP@n:平均精度,即在前n个返回结果中,只对那些返回结果正确的位置的精度进行平均,即nq为q这张查询图片在前k个返回结果中有多少个正确返回结果。
3)mAP@n:对所有probe图片,均计算其AP,将这些结果求均值。
完整公式如下:
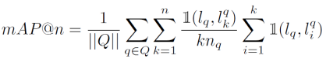
3、ROC
ROC曲线是检测、分类、识别任务中很常用的一项评价指标。曲线上每个点反映着对同一信号刺激的感受性。具体到识别任务中就是,ROC曲线上的每一点反映的是不同的阈值对应的FP(false positive)和TP(true positive)之间的关系。
ROC曲线越靠近点(0,1)则效果越好。
4、mINP
mINP是在2020年初发表的《Deep Learning for Person Re-identifification: A Survey and Outlook》中提到的一个指标。
该指标是为了评价一个模型搜索到最难找到样本的能力。
大致意思是现在的指标只是考虑在召回的前k中去做评价,这样是不准确的,有一些正确样本排序排在很后但是已有的评价指标没有去考虑到它们,为此作者觉得需要加入个惩罚项(NP,negative penalty)来考虑该问题。

mINP计算如下:
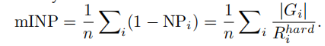
可以结合下图理解公式:

其中,绿色代表正确匹配,红色代表错误匹配,INP = 1-NP。