
1、Introduction
这里主要介绍了:强化学习是可以根据用户实时的反馈,捕捉用户的动态喜好,,实时更新策略(policy),还能实现长期收益的最大化。与其他不同的是,这里是生成一个网页的物品(网页版商城),是2D的,而不是1D的流式推荐(手机版商城)。
(ps:对于手机用户来说,一般用户最关注的是第一个商品,把他最感兴趣的放在第一个就好了,但是对于页面来说,很难说用户最喜欢关注哪个地方,每个人的关注点可能不太一样,第一行第一个不一定是最好的,所以需要学习。)
2、模型结构
2.1 Overview
这里用的就是强化学习了。
将推荐任务当作一个Markov Decision Process,利用强化学习去优化推荐策略。
1)state space S:就是生成用户的当前兴趣,这个是基于用户以前的历史数据(浏览、反馈等)
2)Action space A:![]() 基于状态s,生成一个页面的M个物品。
基于状态s,生成一个页面的M个物品。
3)Reward R: 状态s下采取动作a,用户的反馈是什么(点击、购买、跳过),就会获得一个reward
4)Transition P: 状态s下采取动作a,转移到下一个状态s' 的概率(由于这里是model free的模型,所以就不需要预测这个转移概率)
5)衰减因子 γ:0~1之间的一个数字,表示用户有多重视未来的奖励。如果γ=0,则模型只注重当下的奖励,γ=1,模型在预测当前价值的时候要考虑未来所有的奖励
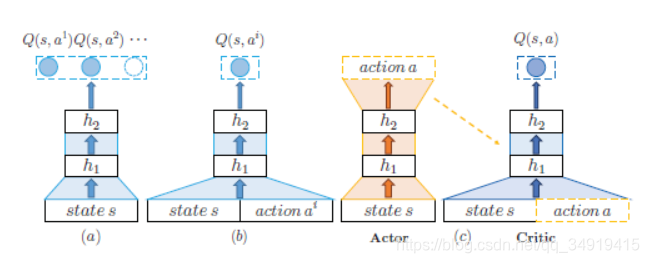
他这里用的是Actor-Critic的方法,critic用的是DQN,所以不需要储存Q-table
不选下图a方法的原因:给出一个state,要计算所有action的Q value,计算量太大
不选下图b方法的原因:
![]() 根据求最优解的公式,还是要算max Q,也就还是要算下一个状态的所有a,计算量还是很大。
根据求最优解的公式,还是要算max Q,也就还是要算下一个状态的所有a,计算量还是很大。
所以用c方法,先用actor选出action a,再让critic去计算,在当前state,选择action a的Q value是多少。
![]()
2.2 Actor的结构
有三个挑战:1、初始兴趣(state)是什么。 2、学习实时兴趣的时候,要捕捉用户的什么兴趣,用户喜欢的物品在页面哪个位置。3、怎么生成、展示一个2D的页面。
2.2.1 Initial State 初始状态
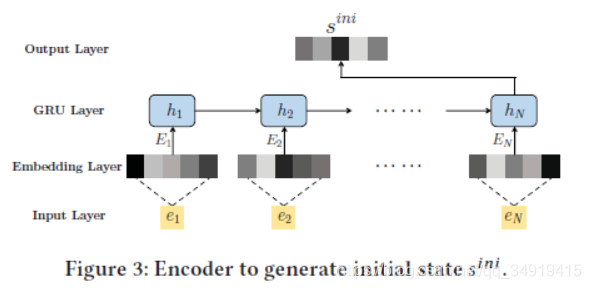
输入用户最近购买、点击的物品e。
e是公司根据过往数据预训练好的的表达向量。
![]() 通过线性、激活、输入gru,获得最终的initial state。gru的公式就不写了。
通过线性、激活、输入gru,获得最终的initial state。gru的公式就不写了。
2.2.2 Real-time State 实时状态
因为是推荐一个页面的推荐系统,且一次推荐M个,所以输入是![]() ,是用户对每M个物品的反馈。
,是用户对每M个物品的反馈。
![]()
e是与训练的表达。c是类别(category),是一个one hot向量。f是反馈(feedback)(点击、跳过、购买),也是一个one hot向量。
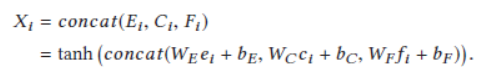
将他们过线性层再拼接起来。获得一个物品的综合表达X
由于我们的网页是h行w列,所以构造一个 h×w|X| 大小的矩阵 Pt
为了将这个矩阵综合成一个低维度的表达,我们使用卷积。![]()
对于每一次我们给用户一个页面P,他都会给我们一个反馈。我们把p输入gru,我们使用attention去计算每个hidden的权重,加权求和得到最终的state。

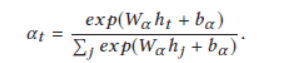

2.2.3 获得action
使用 deconvolution neural network (DeCNN) 去获得action
![]()
生成一个h×w|X| 大小的矩阵。但是生成的物品的表达可能和与训练好的不同,所以需要map一下,之后会提到。
2.3 Critic的结构
要把state和action输入到function中计算Q value。
但是我们2.2.3计算出来的a是二维的,比较麻烦,所以用卷积,化成一维的。然后使用DQN网络就可以啦。
![]()
(吐槽:折腾来折腾去的,这几个卷积层是同一个吗?)
3 训练和测试
3.1.1 online 训练过程(使用真实的购物网站训练)
因为生成的e可能是不存在的,所以我们要map到最像的那个。
使用cos相似度计算。

为了降低计算消耗,先把![]() 计算好。 max Q*也是要计算这个的。
计算好。 max Q*也是要计算这个的。
mapping的算法如下,保证在一个page里面,不会有两个一样的物品。

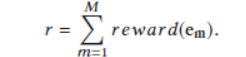
3.1.2 offline 的训练过程(使用用户的历史数据训练)
我们使用用户的历史数据来训练Actor-Critic。但是实际上,我们预测的a和真实的a是不一样的,无论预测的a是什么,真实的a都是不变的。(由于是基于历史数据,用户看到什么和操作什么都是不可改变的。所以真实a永远不变。)所以我们要减少预测a和真实a的差距。reward实用真实a计算的。
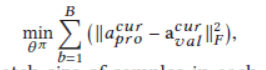
3.1.3 训练算法
Critic的loss函数就和一般的Q learning的是一样的。参数μ'和π'是被固定的参数。莫烦python DQN pytorch代码详解
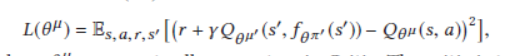

对于actor,我们希望他的总分期望越来越大。
(policy gradient:其实每个动作的概率都在增加,但是,如果这个action的奖励更多,他增加的幅度更大。总体上,好的action更大。)

offline 训练的不同是,第8行的选择,用真实值,第13行之前,需要最小化预测和真实action的。
3.2 测试过程

reward:跳过0分,点击1分,购买5分。
offline的测试就是将所有物品排序,下一次用户点击、购买的要排的尽量靠前。
