上个博客笔记是有关多任务学习的内容,如下:
- 问题陈述
- 模型,目标,优化
- 挑战
- 现实世界多任务学习的案例研究
链接:课程笔记: stanford cs330 deep muti-task learning and meta-learning -- multitask_transfer_1_Ss苓的博客-CSDN博客
这次内容是上个博客内容的下篇,迁移学习,内容如下:
- 预训练和微调
多任务学习与迁移学习的区别和联系
多任务学习是一个模型同时进行多个任务的训练,目标是在这多个任务中表现良好。
迁移学习是在解决源任务,比如任务a之后,通过将源任务学到的知识迁移到目标任务,比如任务b上。目标是要求在目标任务表现良好。
迁移学习是多任务学习的一种有效解决方案(反之亦然)
迁移学习的应用场景或能解决的问题
- 让机器在一所房子里学习到的指令,在另一个房子里也能做相同的指令。
- 将机器人在模拟领域学习到的东西转移到现实世界领域。
- 可以将一家医院学习到的医疗数据转移到另外一家医院,有些时候无法获取到前一家医院的图像信息,但可以利用在前一家医院学习到的知识。
- 从学习更简单的任务(例如捡起积木)转移到更难的任务(例如捡起不规则形状的物体)。
总结:
- 在计算能力有限情况下,如果任务a的数据集非常大,不想在迁移到任务b时继续训练任务a,可以使用迁移学习
- 当不需要同时解决两个任务的时候,可以利用在任务a学习到的知识迁移到任务b上。比如上面的2举例,我们并不关心在模拟领域训练的任务结果如何,而关心的是现实世界中的任务训练效果。
实现迁移学习的方法--fine-tuning(微调)
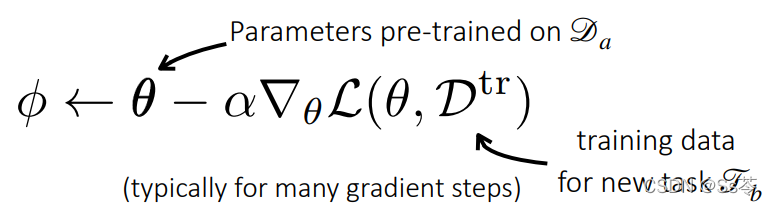
就是在目标任务上的数据集进行参数的梯度更新,而这个更新是基于源任务学习到的参数上进行的。从下表可以看出,使用了源任务学习到的迁移知识来分别在两个新任务训练(PASCAL和SUN),即第一行数据,效果比使用随机初始化的参数的训练效果好很多,即第二行数据。

获取预训练参数的方法:
- ImageNet分类任务
- 在大数据量语言数据集corpora训练的模型(BERT, LMs)
- 其他无监督学习技术
- 任务你拥有的大型的、多样的数据集
预训练的模型一般不用自己从头开始训练来获得,网上已经有很多预训练好的模型可供使用。
进行微调的一些通用的实践例子:
- 使用较小学习率来微调。这样就不会破坏具有较大学习率的预训练网络中的内容。
- 在较早的层次使用较小的学习率。因为通常在网络中较早层次具有更通用的特征,比如图像分类网络中的边缘检测器。
- 冻结较层次的学习率,可以设置为0,然后逐渐依次解冻,直到有效地训练了网络的后面部分。
- 重新初始化最后一层,可以快速学习并适用新任务。
- 通过交叉验证来查找超参数。可以通过对下游目标任务的交叉验证来搜索这些不同的设计选择和超参数。
- 模型结构的选择起到关键作用。比如ResNet残差网络结构,它比其他网络架构相比,更容易于梯度在网络中传播。
下面这个例子说明了在小数据量的目标数据集上做迁移学习的微调,效果并不好。横坐标是数据量,从左往右数据量逐渐增加,纵坐标是错误率,显然随着数据量的增加,迁移学习效果越好。
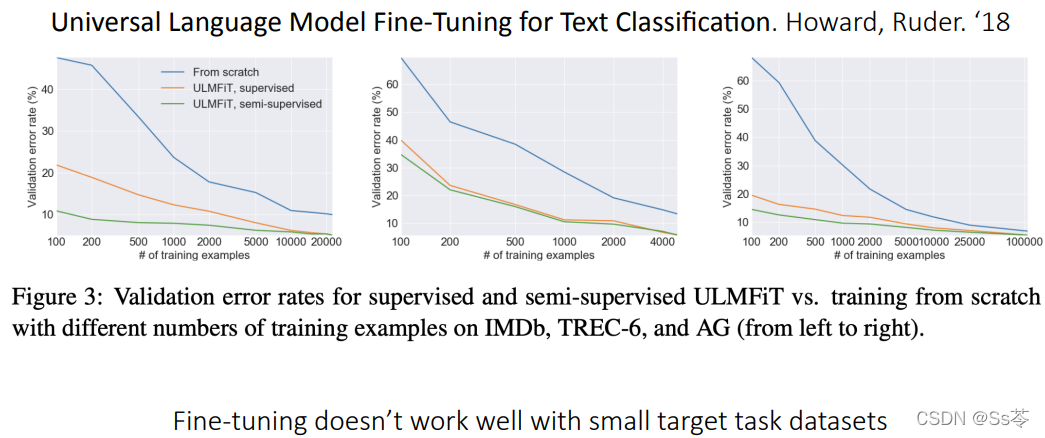
这也正是引出元学习的过渡例子,因为元学习可以在小样本数据得到好的训练效果。