本节课程主要关于元学习的内容,包括:
- 问题制定
- 通用元学习算法
- 黑盒适应方法
- GPT-3例子学习
一、元学习的问题阐述
关于元学习的两种观点:
机械的观点和概率的观点。
机械的观点:
- 深度网络能够读取整个数据集来对新数据进行预测。
- 训练这样的网络利用了一个元数据集,这个元数据集包含许多数据集,每个数据集都用于一个不同的任务。
概率的观点:
- 从一组任务中提取允许用于新任务的有效学习的先验知识。
- 用这些先验知识和(小)训练数据来推断最有可能的后验参数,进而学习一项新任务。
本次的课程都是以第一种观点为视角来探讨元学习。
元学习的运作机制 --- 举例
下面是一个分类任务,左边是训练数据集,有五个类别,每个类别仅有一个训练样本,我们期望的是模型能够在看到左边的训练数据集后,能能够有效分类出右边的新的测试数据,因此元学习本质是是学习如何学习这些图像的分类任务。

元学习分为两部分阶段,元训练阶段和元测试阶段,元训练阶段是用来学习如何学习分类图像任务,元训练阶段是当元训练阶段学到知识后,就准备好了如何解决新的少量样本学习问题,就能快速有效解决新的少量样本分类问题。

这个元学习问题的例子有不同的任务,每个任务对应一个图像分类任务。实际上,元学习不仅是应用于图像分类任务,也可用于语言生成任务,机器人技能学习任务,可以解决任何类型的机器学习问题。
元学习的运作机制 --- 总结
给定n个任务![]() ,能够快速的解决新的任务
,能够快速的解决新的任务![]()
关键假设:元训练的任务和元测试的任务都来源于相同的任务分布,
![]()
即任务之间必须共享结构。
元学习的过程:目的是找到所有训练任务之间的共同结构,并在学习新任务时利用该结构,这样它可以用比从头来时训练更少的数据来学习它。
一些多个不同的任务的可应用元学习的举例:
- 从不同的语言识别手写数字
- 为不同的用户提供垃圾邮件过滤器
- 世界上不同区域的物种分类
- 一个机器人执行不同的任务
Q:设置多少任务数量比较好?即n的值应该设置为多少?
A:越多越好。在许多方面,这类似于机器学习需要许多的数据来训练。如果有更多的任务,那有 更高的可能在一项新的任务上做得更好。但不同的是,每个任务不一定需要大量的数据,只需要有更多的任务来覆盖更广泛的分布。
元学习的术语介绍
| support set(支持集) | 任务训练数据集 |
| query set (查询集) | 任务测试数据集 |
| N-way k-shot | N-way表示有N个选择分类,k-shot表示每个类别有k个样本数据 |
下面这个例子就有5-way,1-shot。

不同类型学习的问题设置总结
| 多任务学习 | 一次性解决多个不同的任务 |
| 迁移学习 | 通过解决源任务来学习知识并将知识迁移到目标任务,使辅助目标任务的解决 |
| 元学习 | 给定多个不同的任务,学习元知识后能快速解决新任务 |
注意:
- 在迁移学习和元学习中,一般使无法直接访问到先前的任务。
- 三种类型的学习设置中,都是需要共享一定的结构。
二、通用的元学习算法
评估元学习算法的基准
Omniglot 数据集:有出自于50种不同语言的字母表的1623个字符,每种字符包含了20个不同的示例,如下图所示。
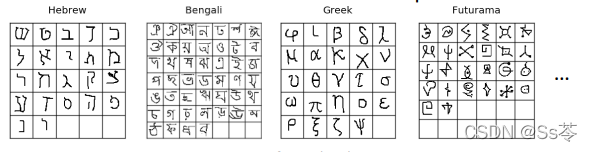
一般选择多类别小样本的数据,这样能够更好的反映现实世界中的数据。因为在现实世界中,我们并没有看到1000个不同的叉子和勺子的实例,也不曾见过1000个不同的水瓶,等等。我们所见到的物体、所见到的文字等,都只能看到每个类别的几个实例,都是看到了更多类别的多样性,因此,多类别小样本的数据集更具有吸引力,更符合现实的情景。
其他用于小样本图像分类任务的数据集有:tieredImageNet, CIFAR, CUB, CelebA,等
另外一种看待元学习问题的观点
在监督学习方面尤其会按照这个观点来实现元学习。
看待监督学习问题的一种方法是:给定输入 x、给定图像和输出 y。 我们建模一个从 x 预测 y 的模型。 我们使用数据集在模型上执行预测操作,如下图所示。
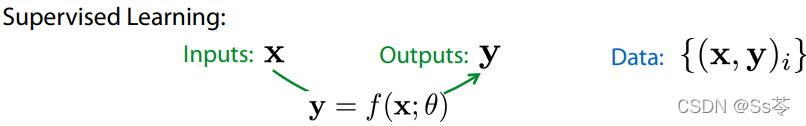
与此类似, 我们可以将元监督学习问题视为,给定具有 k 个示例的数据集和一个新的数据点。 我们想要 预测的相应标签 。 因此,本质上可以把元学习问题视为接受一个数据集和 一个新数据点的问题,从该训练数据集中学习一些东西,并做出一个预测 ,希望能够推广到这个新的测试数据点以预测 。这样做的方式类似于监督学习。
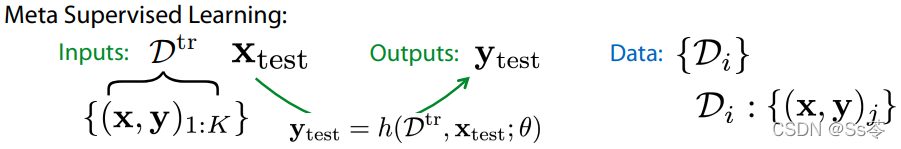
但是在这种情况下,数据是对应于一个多个数据集的数据集, 其中每个数据集都有超过 k 个示例, 因此可以对 k 个样本进行采样以用于训练数据集中。 并且至少有一个用于衡量这里的泛化。
这种方式有什么用?
这种观点实际上很有用,因为它在许多方面将元学习问题简化为弄清楚我们可能想要如何设计这个函数 h 以及我们想要如何优化这个函数 h。
元学习算法的一种通用方法是:首先,选择这个函数的一种形式,它基本上接收一个数据集,从该数据集中学习一些东西,并对新的数据点进行预测。其次,选择如何使用元训练学习到的知识 -- 如针对某个最大似然目标优化该学习器的参数。

把称为元参数。这个函数通常被称为学习器(learner),从某种意义上 说,它从数据集中学习一些东西,并应用它学到的东西来预测 x 测试的标签。
三、黑盒适应方法
实际上,最简单的实例化方法就是我所说的黑盒适应。
关键思想:
(1)训练一个神经网络来表示学习器![]() ,该学习器接受输入数据集并输出 一组参数
,该学习器接受输入数据集并输出 一组参数![]()
(2) 使用具有这些参数的模型预测测试数据点![]()
如下图所示:
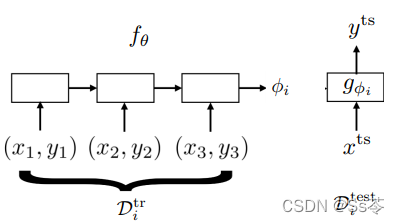
而上述的(2)过程,与标准的监督学习是没有区别的,可以说是等效的。

将学习器的模型代入到上图的L损失,就可以得到完整的元学习损失:
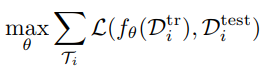
元学习的过程:
- 采样任务
- 采样类别不重合的训练数据集(支持集)和测试数据集(查询集)
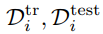 ,如下图所示
,如下图所示 - 计算学习器学习到的一组元参数
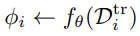
- 使用测试集(查询集)来更新任务参数
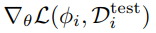

注意,我们有时并不需要使用到网络中所有输出的参数,因为可能只要一部分就已经足够了,所以可以提取出低维的特征参数来用于后续的预测。
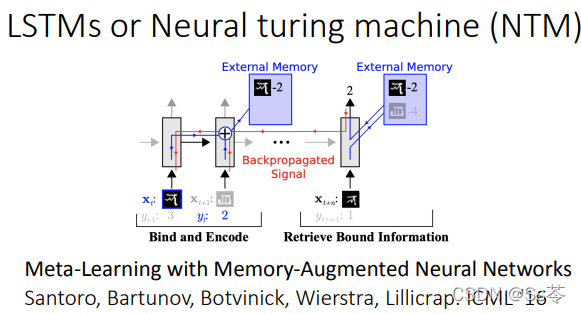
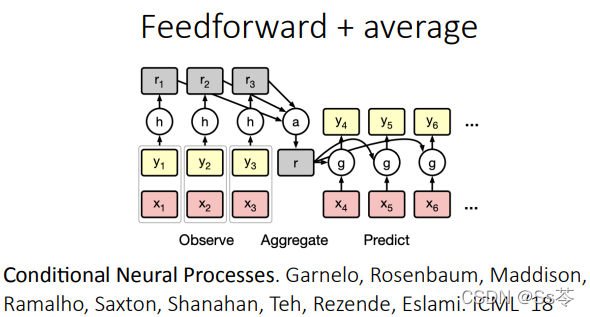
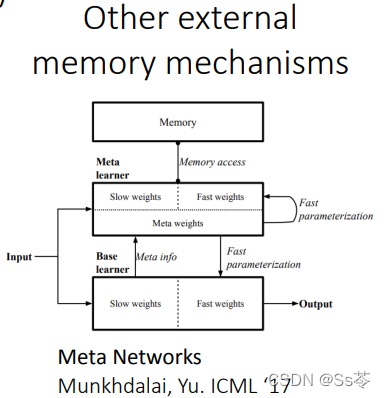
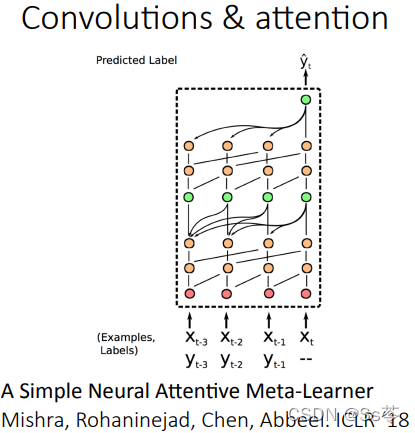
学习器网络结构
学习器网络结构的选择有很多,如下图所示,有兴趣的可以自行查阅相关的网络详细了解,这里就不一一介绍。
GPT-3例子学习:
略