±³¾°
سïزه±كشµ¼ى²âزر¾±ن³ةءثز»¸ِضً½¥خüز¹ط×¢µؤ¼ئثم»ْتس¾ُبخخٌ·½دٍ£¬زٍخھئنثûµؤ¼ئثم»ْتس¾ُبخخٌ»لسذ°ïضْ£¬سبئنتا¶ش·ض¸îءىسٍ،£
شعسïزه±كشµ¼ى²âضذ£¬سذز»ہàبخخٌ¸ü¾كجôص½ذش£¬²»½ِ½«سïزه±كشµ¼ى²â³ِہ´£¬»¹زھ½«±كشµتôسعؤؤز»ہࣨcategory-aware£©ز²¼ى²â³ِہ´£¬صâتاز»¸ِ¶àlabel·ضہàµؤختج⣬¼´±كشµدٌثطµؤlabel²»تاز»ضض،£¾ظ¸ِہ×س£؛
ز»¸ِبثµؤ±كشµµؤز»²؟·ضز²ا،ا،تاز»¶°½¨ضµؤ±كشµ£¬ؤاأ´صâ²؟·ضµؤ±كشµµؤlabel¾حسذء½ہà،£
ثùزش one hot±àآë²»ؤـسأسعصâضضlabel
¹ظ·½´ْآëت¹سأءثuint32ہ´±يت¾label£¬°´صصخ»تہ´إذ¶ددٌثطµؤlabel£¬بç¹ûدٌثطتôسعµعز»ہàز²تôسعµع5ہ࣬ؤاأ´ثûµؤlabel¾حتا1000،010001£¬ز»¹²32خ»ت×ض£¬×î¸كخ»´ْ±يlossتا·ٌ¼ئثمصâ¸ِرù±¾،£
1 ض÷زھث¼آ·
شعحّآçµؤةè¼ئةد£¬²»ؤـ؛حسïزه·ض¸îµؤةè¼ئز»ضآ£¬²»ؤـت¹سأencorder£¬زٍخھ±كشµتôسعµح¼¶جطص÷£¬ذèزھ´سµحµ½¸كµؤةè¼ئحّآç،£¶ّسïزهتôسع¸ك¼¶جطص÷£¬²إ؟ةزشسأdecorder½ل¹¹£¬²»¶د¶ش¸ك¼¶سïزهجطص÷refine،£
ض÷¸ةحّآç²ةسأresnet101£¬ا°3¸ِstageµؤجطص÷¶¼ثحµ½²àجطص÷جلب،ئ÷£¨side extractor£©£¬ب»؛َ؛ح×î؛َز»¸ِstageµؤجطص÷×ِز»¸ِبع؛د£¬سأسع¼à¶½¼ئثمloss،£
بç¹ûت¾ف¼¯سذkہ࣬شٍحّآç×î؛َµؤتن³ِس¦¸أخھ؛ٌ¶بخھkµؤجطص÷ح¼£¬أ؟¸ِدٌثطخ»ضأ¶¼سذkخ¬دٍء؟،£دٍء؟µؤضµأèتِتôسع¶شس¦µؤہà±ًµؤ¸إآت،£صâتاز»¸ِ¶àlabel·ضہàختجâ،£
ض÷زھ¹²دي£؛
- خھءث½â¾ِ¸ذضھہà±ًµؤ±كشµ¼ى²â£¬جل³ِءثز»ضض¶àlabel·ضہàµؤ؟ٍ¼ـ£¬±بئً´«ح³¶àہà·½·¨£¬جلةءثذشؤـ
- جل³ِذآس±µؤ¼ٍ½àµؤ½ل¹¹£¬²¢²»¶شresentµؤ¶¥²م½ّذذ¼à¶½£¬¶ّتاہûسأµح¼¶جطص÷£¨µ×²مجطص÷£©شِا؟¸ك¼¶جطص÷سأسع·ضہà،£ح¬ت±×ِءثتµرéض¤أ÷¶شresnetµؤ¶¥²م½ّذذ¼à¶½²¢²»ؤـµأµ½؛أµؤ½ل¹û،£
- شعsbd؛حcityscapesت¾ف¼¯ةدب،µأstate of the artµؤذ§¹û
2 ¹ط¼üزھثط
2.1ثًت§؛¯تµؤةè¼ئ
×÷خھ¶àlabel·ضہàختج⣬×شب»²»ؤـسأ¶à·ضہàختجâµؤ½»²وىط×ِثًت§ءث،£¶àlabel·ضہà؛ح¶à·ضہ಻تاز»رùµؤ¸إؤî،£
¼ظةèIIIتاتنبëح¼دٌ£¬labelتاز»×é·ض±وآتز»رùµؤ¶ضµح¼دٌ{
Y?1,Y?2,...,Y?k\overline Y_1,\overline Y_2,...,\overline Y_kY1?,Y2?,...,Yk?}،£
ؤاأ´¶àlableµؤثًت§؛¯تخھ
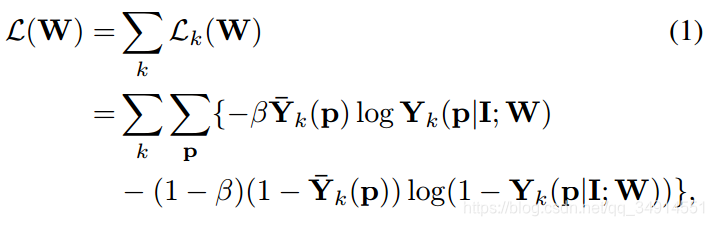
¦آ تا·ا±كشµدٌثطµمµؤ±بہ£¬سأہ´ئ½؛âرù±¾µؤ²»¾ùذش،£pض»أ؟ز»¸ِدٌثطخ»ضأ،£
¸أثًت§؛¯ت؛ـ؛أ½âتح£¬؟ةزشتس×÷¶شأ؟ز»ہà±ً¶¼½ّذذز»´خ¶·ضہàµؤ½»²وىط،£×î؛َ½«k¸ِ½ل¹ûµ¼س
2.2 حّآç½ل¹¹
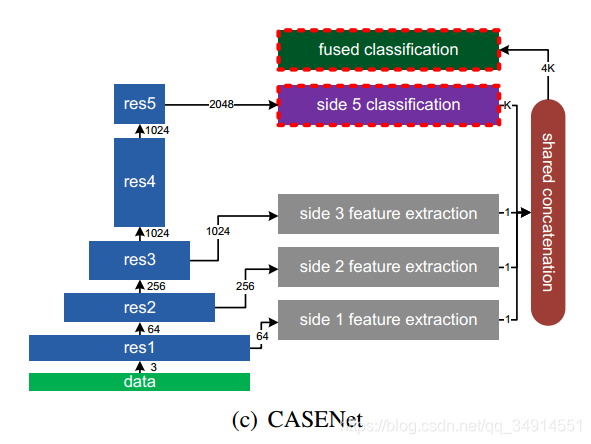
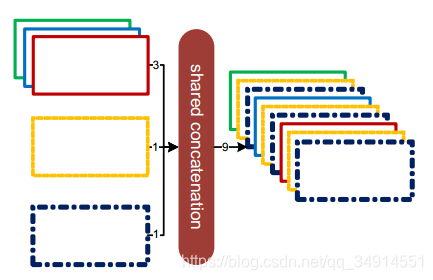
ئنضذfused classificationسأµؤتاgroup¾ي»،£
حّآçسذ¼¸¸ِجطµم£؛
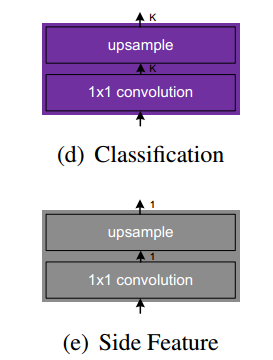
- ¶شا°ب¸ِstageµؤجطص÷جلب،جطص÷£¬تن³ِح¨µہخھ1
- ¶شµع5¸ِstage×ِ·ضہ࣬تن³ِkµؤح¨µہµؤجطص÷
- زشةدء½¸ِؤ£؟鶼سذةد²ةرù»·½ع£¬±£ض¤ءثتن³ِµؤ·ض±وآت؛حشح¼ز»ضآ
- شعconcatµؤ²؟·ض£¬²ةسأµؤتاsliceµؤ·½ت½×ِconcat£¬صâ¸ِثمتا؛ـذآس±ءث،£
×÷صكبدخھ£¬µ×²مجطص÷µؤ¸ذتـز°سذدق£¬ثùزشبأا°¼¸²مب¥×ِسïزه·ضہàتا²»؛دہيµؤ£¬ثùزشا°3¸ِجطص÷½ِ½ِ×÷خھجطص÷تنبëµ½ءيز»¸ِside feature extractorضذ،£
ثùزشسïزه·ضہàس¦¸أ½ّذذ²إ¸ك²مضذ£¬زٍخھ¸ك²مجطص÷سذ؛ـا؟µؤ¸ك¼¶ذإد¢،£
ح¬ت±µ×²مجطص÷زٍخھ¾كسذ¸ü¼سدêد¸µؤ±كشµخ»ضأذإد¢؛ح½ل¹¹ذإد¢£¬سأہ´شِا؟¸ك²مµؤ·ضہàبخخٌتاسذ°ïضْµؤ،£ثùزشةè¼ئءثصâرùµؤ½ل¹¹£؛ا°ب²مµؤµح¼¶جطص÷£¬بع؛دµ½µع5¸ِstageµؤ¸ك¼¶جطص÷×î؛َµؤ¼à¶½،£
2.3بç؛خؤـجهدضتاµح¼¶جطص÷°ïضْ¸ك¼¶جطص÷سأسع·ضہàؤط£؟
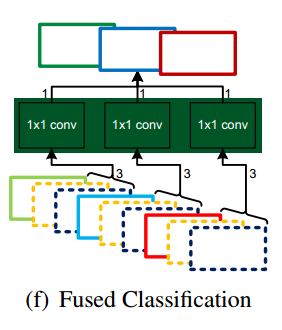
×¢زâµ½£¬side featureµؤتن³ِح¨µہخھ1£¬classificationµؤتن³ِح¨µہخھk£¬ز²تاہà±ًµؤتنبë،£shared concatµؤ×ِ·¨تا£¬¶شclassificationµؤأ؟ز»¸ِجطص÷ح¼£¨for map in k maps£©£¬ا°3¸ِstageµؤتن³ِ¶¼²ه¶سإإ½ّب¥£¬ثùزش×îضصµؤجطص÷ح¼ح¨µہتا4*kµؤ،£
¶ّازfused classificationضذ£¬سأµ½µؤتاgroup¾ي»£¬ثنب»ت¾زâح¼ضذز»¸ِ¾ي»؛ث¶ش؛ٌ¶بخھ3µؤجطص÷ح¼¾ي»£¬µ«تµ¼تحّآçصâہïتاأ؟4¸ِmapز»×é×ِ¾ي»£¬أ؟ثؤ¸ِmap£¬ئنضذز»¸ِہ´×شسع¸ك¼¶جطص÷£¬ت£دآب¸ِہ´×شسعµح¼¶جطص÷،£
×ـجهµؤث¼آ·¼ûشخؤ£؛

2.4 ¼سبëإٍصحزٍ×س
زٍخھذق¸ؤءثresnetµؤ½ل¹¹£¬stride¸ؤ±نءث£¬×î؛َµؤجطص÷ح¼µؤ·ض±وآتتاشہ´µؤ1/8£¬ثùزش¸ذتـز°ز²±نذ،ءث،£خھءثشِ´َ¸ذتـز°£¬شعstride±¾ہ´خھ2µؤ²مض®؛َµؤ¾ي»²م¶¼تاسأ؟ص¶´¾ي»،£
3 تµرé
×÷صكشعsbd؛حcityscapesةد×ِءث²âتش،£
خز½سدآہ´½ِ½éةـش¤´¦ہي²؟·ض£¬زٍخھصâ²إتا¶شخزأا¸´دض´ْآëسذ°ïضْµؤ،£تµرé½ل¹û£¬¾كجهµؤ±يدضاë×شذذ²خ؟¼آغخؤ،£
3.1 implementation details
؟¼آاµ½بث¹¤±ê×¢؛حصوتµµؤ±كشµ´وشع´يخَ±ê×¢؛حlabelءىسٍµؤدٌثطµؤlabelسض¾كسذ²»أ÷ب·µؤہà±ًذإد¢£¬×÷صكةْ³ةءث¸ü´ضز»µمµؤlabelخھحّآçµؤرµء·GT،£صâ؟ةزشح¨¹شعlabel±كشµµؤءعسٍؤعر°صز؛ح·ض¸î±êا©²»ز»رùخ»ضأµؤدٌثط£¬°رصâذ©دٌثطز²¹éخھ±كشµµأµ½،££¨زھخزثµض±½سسأذخج¬ر§²ظ×÷ز²ذذ°ة£©
³ءث¶شlabelµؤش¤´¦ہي£¬»¹سذ¼¸µمد¸½عذèزھ×¢زâ£؛
- resnetت¹سأ؟ص¶´¾ي»£¬شع³ءثµعز»¸ِconv£¬؛ح1x1µؤ¾ي»£¬ئنثûµؤ¾ي»¶¼ت¹سأ؟ص¶´آتخھ2µؤ¾ي»،£
- ت¹سأش¤رµء·ؤ£ذح£¬شعms cocoةدµؤ×ِش¤رµء·
- ²خت؛حت¾فشِا؟¼ûدآ


´ْآë
خزؤ؟ا°صشع¸´دضسïزه±كشµ¼ى²âµؤ·½·¨£¬؟ٍ¼ـ²¢²»ت¹سأcasenet£¬»ùسعBDCNµؤ،£بç¹ûذ§¹û؛أµؤ»°£¬ز²»ل؟ھش´µؤ،£سذذثب¤اëشعدآ·½ءôرش£¬½ىت±خز»لح¨ضھ´َ¼ز،£
update on 2019.7.15
CPPR2019 µؤSTEAL ت¹سأءثCASENetحّآç×÷خھbackbone£¬´َ¼ز؟ةزشب¥GitHubةدثرث÷ز»دآ،£STEALµؤذشؤـزر¾³¬¹ءثCASENet