����ICCV2019����������ָ�����ģ�����˵��CVPR2019��DANetң���Ӧ������DANet���Լ��ҵ���һƪ����
�ٷ�Դ��
idea
��DANetһ����CCNetҲ���뽨ģ����֮���long range dependencies���������ӷḻ��contextual information������������ͼ���Դ�����������ָ�����ܡ����Ǻ�DANet��һ����CCNet�������ռ�ֱ��ϵĽ�ģ�������ǽ�ģͨ��֮�����ϵ�����������ģ�飬criss-cross attention module����Կռ�ά���ϵĽ�ģ�����ڿռ�λ�õ�һ����u�������ǽ�ģ��u��ͬһ�л���ͬһ�е�����λ�õ�����֮�����ϵ�����DANet���ܼ��ٺܶ�����������Dz�����ǣ���һ���������������������ͬһ�л���ͬһ�е�����������Ϣ��Ϊ���䣬��������ָ�����contextual information��Ȼ��ϡ��ģ�sparse������Ϊ����ָ������һ�����غ�����Χ��һЩ���صĹ�ϵ�����������⣬���������recurrent criss-cross attention module������ģһ�����غ�ȫ���������صĹ�ϵ����ʽ��ͨ���ظ�criss-cross attention module��ʵ�ֵġ���ЩmoduleҲ�Dz���shared�ġ�
main contribution
- ͬ���ǽ�ģ�ռ�ά�ȵ�pixel-wise contextual information��CCNet�ļ����������self attention����С̫���ˡ�һ��CC module,Ҫ��������һ�����ص��ͬһ�С�ͬһ��һ��(H+W-1)��ô������أ���ôӦ�������������ϣ�����������O(HW(H+W-1))���ع�DANet�Ŀռ�ע������֧��position attention module����ÿһ�����ؾ�Ҫ��(HW)�����ؽ�ģ֮�����ϵ��Ӧ�����������أ�����������O(HW*(H*W))��
- ͨ���ݹ�ķ�ʽ��CC module�����Զ�һ�����ز���ȫ�ֵ�contextual information���ᵽ������ָ������Ч����
���˿�����������Ч�ģ����Ǽ�������ķ�����CCNet��������һ�����
Method
OverView
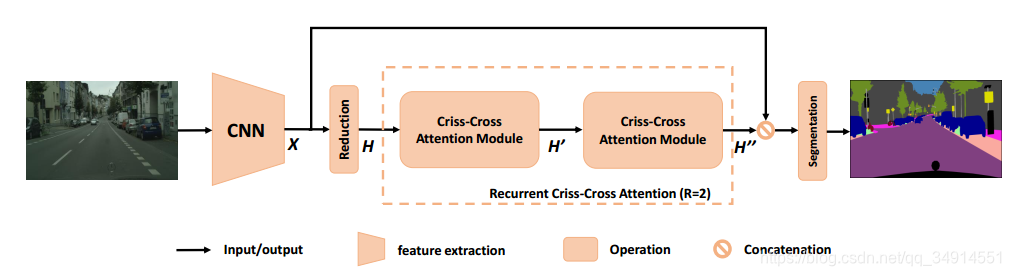
��������Ĺܵ�����ͼ��ʾ
- ����һ��ԭͼ�ͽ�backbone�����backbone���Ĺ��ģ����������stage��stride��Ϊ1��ͬʱӦ�ÿն��������������Ұ���õ�������ͼ��ԭͼ��1/8.
- Ȼ��1*1�ľ�����ά���õ�H��
- H����һ��criss-cross attention module �õ�H��H'H�������ʱ��H���е�ÿ��λ�ö������˺�u��ͬһ�л���ͬһ�е�context information
- H������һ����ͬ�ṹ����ͬ������cc module���õ���H��������H�����е�ÿ��λ�ã�������ȫ���Ե�contextual information
- ���һ���ָ���������Ԥ������
criss-cross attention module
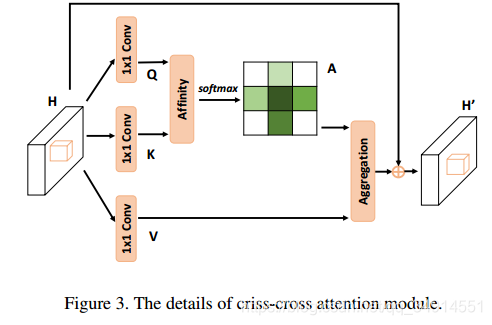
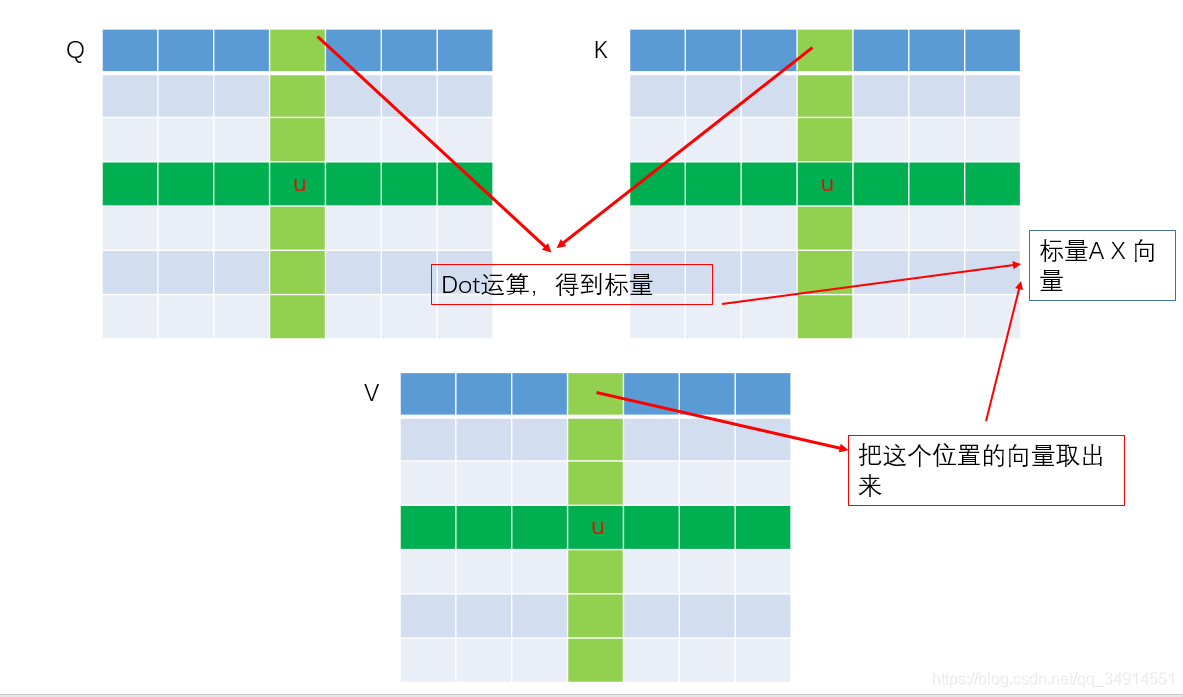
����ģ��ṹ�Ľ��ܣ��ص�Ӧ����Affinity��Aggregation���H��ά����RC��H��WR^{C\times H\times W}RC��H��W
- Q��K������RC���H��WR^{C' \times H\times W}RC����H��W��C��<CC' < CC��<C
- V ��RC��H��WR^{C\times H\times W}RC��H��W
Affinity����
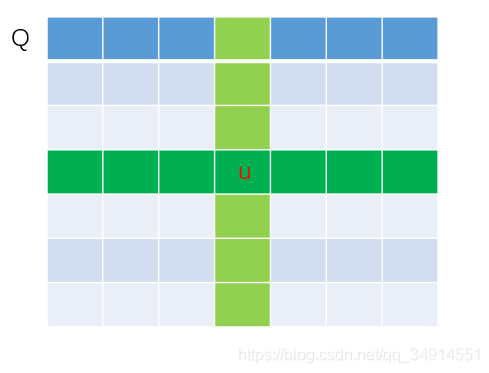
��Q�ϵ�һ��u������Qu��Rc��Q_u \in R^{c'}Qu?��Rc������ɫ��λ�ú���ɫ��λ�ã����Ǻ�u��ͬһ�л���ͬһ�еĵ�Ԫ��
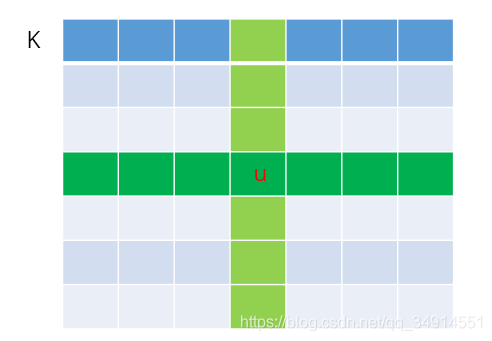
��K�е���ͬλ���ϣ��Ѻ�u��ͬһ�л�ͬһ�е����Ե�Ԫ���뵽������u\Omega_u��u?,��ô������u\Omega_u��u?����H+W-1������ΪC����������
Affinity�������£�
di,u=Qu��i,uTd_{i,u} = Q_u \Omega_{i,u}^Tdi,u?=Qu?��i,uT?
���������ĵ�����㣬�õ�������i��1��H+W-1�仯�������һ��λ��u���ܵõ�H+W-1��ֵ�������е�һ��HW��λ�á�����(HW*(H+W-1))��ֵ���γ�D����D����channelά�Ƚ���softmax���͵õ���A��attention map����
Aggregation ����
��V�е�λ��u��ȡ��Vu��RcV_u \in R^cVu?��Rc��ͬʱ�õ�������u\Phi_u��u?����������ǰ�������V�е�λ��u����uͬһ�л���ͬһ�е�������Ԫ��������Ҳ����˵����u\Phi_u��u?���У�H+W-1��������ΪC��������
Hu��=��i�ʨO��u�OAi,u��i,u+HuH'_u = \sum_{i \in |\Phi_u|} A_{i,u} \Phi_{i,u} + H_uHu��?=i���O��u?�O��?Ai,u?��i,u?+Hu?
Ai,uA_{i,u}Ai,u?�DZ�������A�е�λ��u��Ӧ�����������У���i��ֵ��
��i,u\Phi_{i,u}��i,u?�Ǽ�����u\Phi_u��u?�е�i������������
���������������ͼ��ʾ��
���һ���Ӧ�˽ṹͼ�е���������ߣ���skip connection��
recurrent criss-cross attention
�������recurrent ��ʹ�õ�����

������Ϊ��������ͬһ�к�ͬһ�����ع�ϵ�Ľ�ģ����������ָ���Ȼ��sparse�ġ���������������õݹ�ķ�ʽ��ʹ��CC module����Module֮���Dz��������ġ�ʹ������CC module���������һ�����ص㣬��ģ����ȫ�����ص����ϵ��
��ʽ���ǣ�
- H����һ��CC module �õ� H��
- H�� ����һ��CC module �õ�H����
- H��'�Ͱ�����ȫ�ֵ�contextual information����dense�ġ�
��Ϊɶ���ݹ�ʹ������CC module���Ϳ��Դ��������Ч���أ�

������ƽ������ϵ�У���ɫ��Ҫ�����Լ�����Ϣȥ��ɫ������ҹ涨�ߵ�·��ֻ��ֱ�У���ֻ�����������ߡ���ɫ�㵽��Ŀ�ĵأ�������Ҫ������
����������CCNetҲ�����������˼�롣

H��'��Ȼ����ֱ�ӻ��H�е�ȫ�����ص���Ϣ����ȴͨ����ӵķ�ʽ��ȡ�ˡ�����˵����ͼ���½���ɫ�Ŀ�������ɫ�����Ϣ���ڵ�һ��CC module�У���ɫ�����Ϣ��add�����Ϸ������·��Ŀ����ˣ��ڵ�2��CC module�У����Ϸ��Ŀ�����·��Ŀ鱻add����ɫ�����ˡ�������
���ò�������õģ���������� ʵ�����ݾͲ�������ˡ�