好久没读论文了,因为最近要写一篇二区论文,就没怎么在读新论文了。今天有点闲空,写一篇关于人像分割的论文,同时还有代码实践。
官方代码以及论文地址
研究背景
人像精细分割属于语义分割的子任务。但一般的语义分割网络用来做人像精细分割效果都不太行。作者给出了如下理由:
- 人脸占据图像至少10%的面积
- 在强光照下,边界会模糊,不适合语义分割,但这种情况却在自拍照中常见。
- 分割网络很大,不适合移动端实时快速的人像分割。
网络结构
因为注重速度,所以网络其实很简单。backbone是mobileNetV2, 然后u-net结构作为decoder。decoder就是转置卷积+residual block。 conv换成depthwise conv。
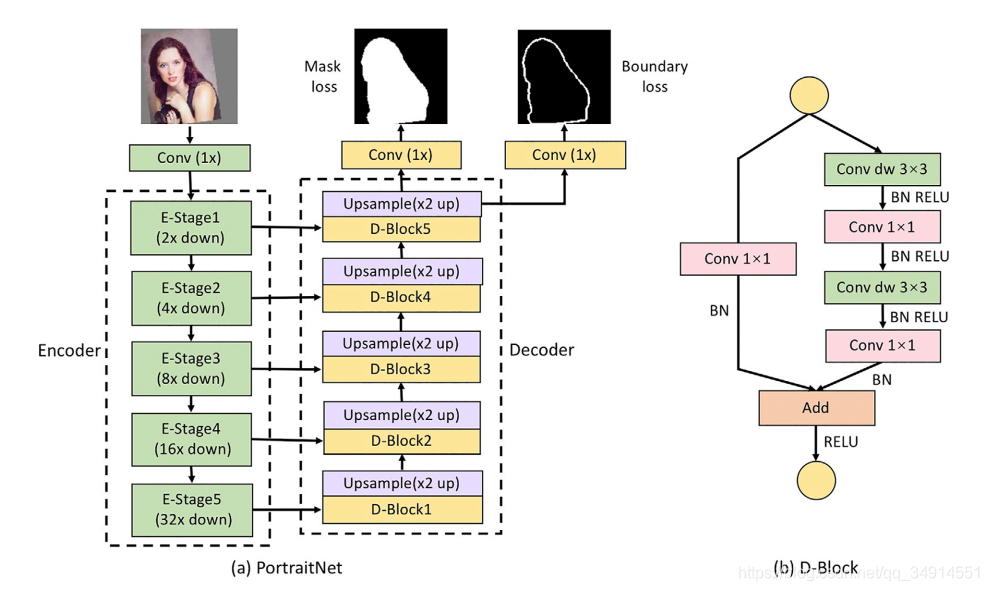
如上图所示,设计的D-block就是残差block,把3*3的conv换为depthwise conv。总体结构还是很容易看懂的。
两个额外的loss
注意到上图的mask loss和boundary loss。其中mask loss就是用来计算像素分类的二值交叉熵loss。除了boundary loss,还有一个consistency constraint loss。
boundary loss
首先为了保证网络的娇小,不能就因为想优化边界就增加额外的分支,所以作者就在最后一层,增加了一个conv层。用来预测边界。边界的label来自对分割gt的canny算子的输出。设置线宽为4.
因为边界占据图像很小的部分,为了避免极度的样本不均衡的样子。所以用的是focal loss。
lambda设置为很小的值,10-4

consistency constraint loss
自拍照有时候在不同的光照条件下,会得到亮度不一样,但是内容确实相同的照片,这些图像的label都是一致的。但网络可能会因为这些图像像素值不同,得到不同的分割预测。为了避免这个问题,作者提出了一致性限制loss。目的就是让这些有光照带来的影响不会对最终的分割结果有影响。从而得到更加稳定的效果。
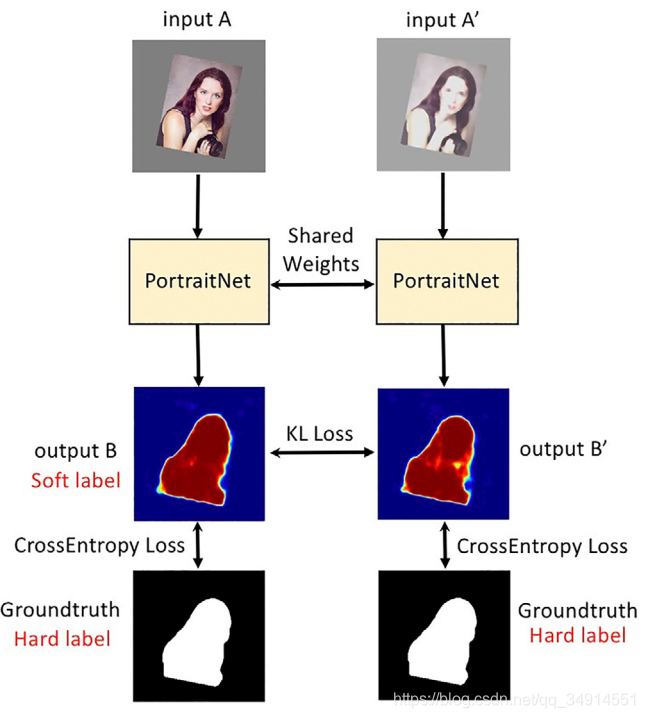
这个辅助loss的示意图从上图看出。假设A是原图经过数据增强得到的。A’是将A改变对比度等得到的。这个张图内容相同,经过网络分别得到B和B’,是heatmap,即网络最后的输出图。B和B’都去和GT参与计算loss。
从理论上来说,A’的质量差A一些,所以B’的质量也差B一些。但是A’仅仅是模拟光线变化得到的,A’的内容和A一致,我们自然希望B’和B相同。为此,作者提出使用B作为B’的软标签,在B和B’之间计算 KL loss。

Lm′L_m'Lm′?是用GT和B, B’得到的loss,就是普通的BCE。
LcL_cLc?是KL loss。T是软标签系数,用来软化标签的。
另外B和B’是没有经过softmax的logits。loss公式里面的p都市经过softmax的。
而q是则是带有软化系数的softmax得到的。

代码实践
作者开放了源码和模型,可以直接使用。源码也很好读。
这是按照阈值为0.5分割的结果。可以看出人物的大部分区域都已经覆盖了,也仅有很少的区域被误判。另外头发有一部分没有分割出来。

下图是将前景提出,虚化背景,模拟景深模式的效果(右图)

总体来说,2019年2月提出的portraitNet是很不错的工作了。速度确实快。
另外,portraitNet其实已经被extremeC3Net(2019年七月)和SINet(2019年11月)超越了。以后也会带来这两篇论文的解读,两篇论文是同一作者,一个韩国人。