��������������
centos6.8+sqoop1.4.6
����sqoop��Ҫ������hadoop����������Ҫ�õ�hbase����Ҫ����zookeeper����hive��mysql��ϵ���ݿ�֮������ݵ���/�������ڴ˻����������������Ѵ�á�
һ��sqoop��װ����
1 ��sqoop-env.sh(mv from sqoop-tmplate-env.sh)����������Լ��Ļ����Լ����������á�
export HADOOP_COMMON_HOME=/usr/SFT/hadoop-2.7.2
export HADOOP_MAPRED_HOME=/usr/SFT/hadoop-2.7.2
export HIVE_HOME=/usr/SFT/hive-1.2.1
export ZOOKEEPER_HOME=/usr/SFT/zookeeper-3.4.12
export ZOOCFGDIR=/usr/SFT/zookeeper-3.4.12
export HBASE_HOME=/usr/SFT/hbase-1.3.1
2 ��mysql-connector jar��������libĿ¼��
3 �����Ƿ�װ�ɹ�
bin/sqoop help
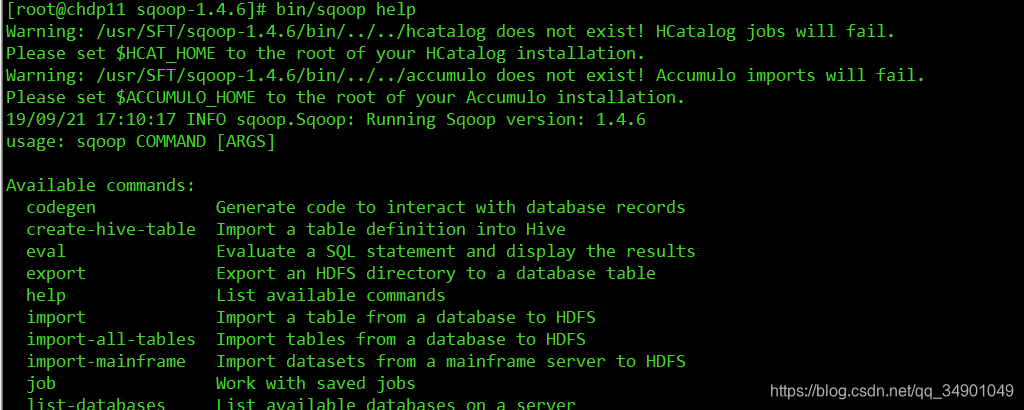
4 �����Ƿ��ܹ����ӵ�mysql������ʾ��Ŀ�����ݿ������Ϣ�����Ѿ����Գɹ�������
/usr/SFT/sqoop-1.4.6/bin/sqoop list-databases --connect jdbc:mysql://chdp11:3306/ --username root --password root
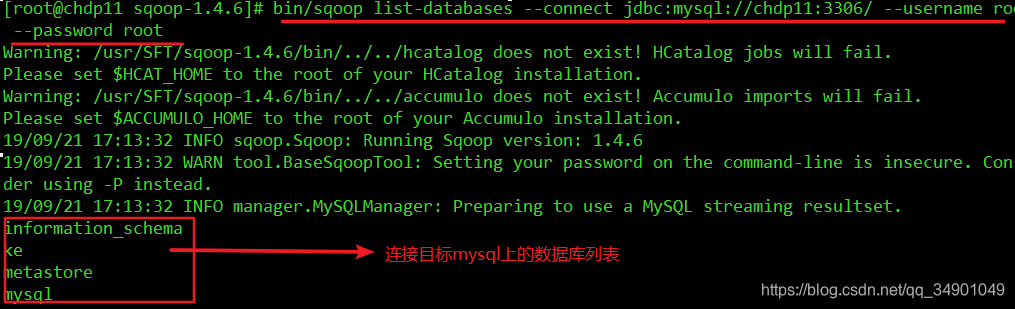
������һ����ظ�����sqoop��Hadoop��������ϵ��Ӫ�ģ���˾����ױ��������ˣ�
���루import�����ݴӹ�ϵ�����ݿ⣨��mysql�����뵽�����ݴ洢�ܹ���hive hbase�� ������export�����ݴӴ����ݴ洢�ܹ�������ϵ�����ݿ⣨��mysql��
������������
1��mysql������
����������������
create table stu(
id varchar(10) primary key auto_increment ,
name varchar(20),
age int(10)
);
˳�㸴ϰ��mysql�������ַ�ʽ�������ݣ�������Ϊ�Ƚ��Ͻ��ķ�����ָ���в��롣
insert into stu values(null,'wangwu' , 13);
insert into stu(id,name,age) values(null,'alex' , 16);
insert into stu(name,age) values('tom' , 14);
2 ȫ�����뵽hdfs(��ָ��Ŀ¼�����ڻ��Զ�����)
#load all of data frome target table
bin/sqoop import \
--connect jdbc:mysql://chdp11:3306/test \
--username root \
--password root \
--table stu \
--target-dir /sqoop/data \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"
���Կ���������MR����
3 ���ֱ����ݲ�ѯ���뵽hdfs(ע���Ǽ�ѯ)
#ע��$�ڱ�˫���Ű���ʱ���ַ�ת������
#query table to import , using��must�� $CONDITIONS in where clause to remain data orderly
bin/sqoop import \
--connect jdbc:mysql://chdp11:3306/test \
--username root \
--password root \
--query 'select name,age from stu where age<=15 and $CONDITIONS;'
--target-dir /sqoop/data \
--delete-target-dir \
--num-mappers 1 \
4 ָ���� ���й��˵��뵽hdfs��ʵ���õıȽ��٣�
bin/sqoop import \
--connect jdbc:mysql://chdp11:3306/test \
--username root \
--password root \
--table stu \
--columns name,age \
--where id="1" \
--target-dir /sqoop/data \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"
5 ���뵽hive
bin/sqoop import \
--connect jdbc:mysql://chdp11:3306/test \
--username root \
--password root \
--table stu \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "\t" \
--hive-overwrite \
--hive-table sq_stup
ע��
1 ���ݵ���ʱ�Ƚ������ϴ���hdfs����ʱĿ¼�������ƶ���hiveԪ���ݶ�Ӧ������Ŀ¼,
��һ�ε������Ч��������̫����Ϊ�ڶ����ƶ����ݣ�mv��ʱֻ����namenode
Ԫ���ݣ��������ƶ�ʵ�����ݴ�ŵ�λ�á�
2 �����ݵ�������hive������ָ��������Զ�������
6 ���뵽hbase
#split by ָ�����rowkeyƴ��ʱ�ķָ���������rowkey�ᱻ��ϳɡ�id-age����ģʽ/usr/SFT/sqoop-1.4.6/bin/sqoop import \
--connect jdbc:mysql://chdp11:3306/test \
--username root \
--password root \
--table stu \
--columns "id,name,age" \
--column-family "info" \
--hbase-create-table \
--hbase-row-key "id","age" \
--hbase-table "sq_stup" \
--num-mappers 1 \
--split-by "_"
ע��
��hive�ı��Զ�������ͬ��sqoop1.4.6ֻ֧��HBase1.0.1֮ǰ�İ汾�Զ�������
�����õ���hbase-1.3.1�������ڴ�֮ǰ�ȴ���һ�±���
hive (default)>create 'sq_stup','info'
7 ���ݵ�����mysql
HIVE/HDFS��RDBMS/usr/SFT/sqoop-1.4.6/bin/sqoop export \
--connect jdbc:mysql://chdp11:3306/test \
--username root \
--password root \
--table stu \
--columns "name,age" \
--num-mappers 1 \
--export-dir /sqoop/data \
--input-fields-terminated-by "\t"
ע��
1��Mysql������������ڣ������Զ��������ʶ�Ҫ���д���
2���ڴ˵������ݹ����������ִ�����ʱ�����ڿ���̨��ӡ��ֻ�ܲ鿴��ʷ�������ˣ��ǵ�����yarn��ʷ��������
3��ע���ԭ����Ҫ��Ŀ�����ݵ�����������һһ��Ӧ�Լ���������Ҫ��ȣ����ָ��Ҫ������������
Sqoop���뵼��Null�洢һ��������
4��Hive�е�Null�ڵײ����ԡ�\N�����洢����MySQL�е�Null�ڵײ����Null��Ϊ�˱�֤�������˵�һ���ԡ��ڵ�������ʱ���èCinput-null-string�ͨCinput-null-non-string������������������ʱ���èCnull-string�ͨCnull-non-string��
5��Sqoop���ݵ���һ��������
��Sqoop�ڵ�����Mysqlʱ��ʹ��4��Map����������2������ʧ�ܣ��Ǵ�ʱMySQL�д洢����������Map����������ݣ���ʱ�ϰ����ÿ���������������ݡ�����������ʦ��������ʧ�ܺ�������Ⲣ���ս�ȫ��������ȷ�ĵ���MySQL���Ǻ����ϰ��ٴο��������ݣ����ֱ��ο�����������֮ǰ�IJ�һ�£��������������Dz������ġ�
������http://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html
Since Sqoop breaks down export process into multiple transactions, it is possible that a failed export job may result in partial data being committed to the database. This can further lead to subsequent jobs failing due to insert collisions in some cases, or lead to duplicated data in others. You can overcome this problem by specifying a staging table via the --staging-table option which acts as an auxiliary table that is used to stage exported data. The staged data is finally moved to the destination table in a single transaction.
�Cstaging-table��ʽ
sqoop export --connect jdbc:mysql://192.168.137.10:3306/user_behavior --username root --password root --table stu --columns username,password --fields-terminated-by ��\t�� --export-dir ��/user/hive/warehouse/tmp.db/stu${day}�� --staging-table stu --clear-staging-table --input-null-string ��\N��
�����ű����
ʹ�ýű����Է��㶨ʱ���������ִ��
1 ����һ��.opt�ļ���дsqoop�ű�
#sq_expToMysql.optexport
--connect jdbc:mysql://chdp11:3306/test
--username root
--password root
--table stu
--columns "name,age"
--num-mappers 1
--export-dir /sqoop/data
--input-fields-terminated-by "\t"
2 ʹ��sqoop����ִ�иýű�
/usr/SFT/sqoop-1.4.6/bin/sqoop --options-file sq_expToMysql.opt
�ġ���������
1��sqoop export��������ʱ������ Can��t export data, please check failed map task log��NoSuchElementException
2�� ERROR sqoop.Sqoop: Error while expanding arguments