ת�����в��ģ�https://www.cnblogs.com/liuwei6/p/6837674.html
һ��Э��������Coprocessor
1�� ��Դ
Hbase ��Ϊ�������ݿ��������ڸ��������������������������������������ִ ����͡�����������Ȳ��������磬�ھɰ汾��(<0.92)Hbase �У�ͳ�����ݱ������������� Ҫʹ�� Counter ������ִ��һ�� MapReduce Job ���ܵõ�����Ȼ HBase �����ݴ洢���м���
�� MapReduce���ܹ���Ч�������ݱ��ķֲ�ʽ���㡣Ȼ���ںܶ�����£���һЩ���� �ӻ��߾ۺϼ����ʱ�� ���ֱ�ӽ�������̷����� server �ˣ��ܹ�����ͨѶ�������Ӷ��� �úܺõ��������������ǣ� HBase �� 0.92 ֮��������Э������(coprocessors)��ʵ��һЩ����
���ĵ������ԣ��ܹ��������������������ӹ�����(ν������)�Լ����ʿ��Ƶȡ�
2��Э�����������֣� observer �� endpoint
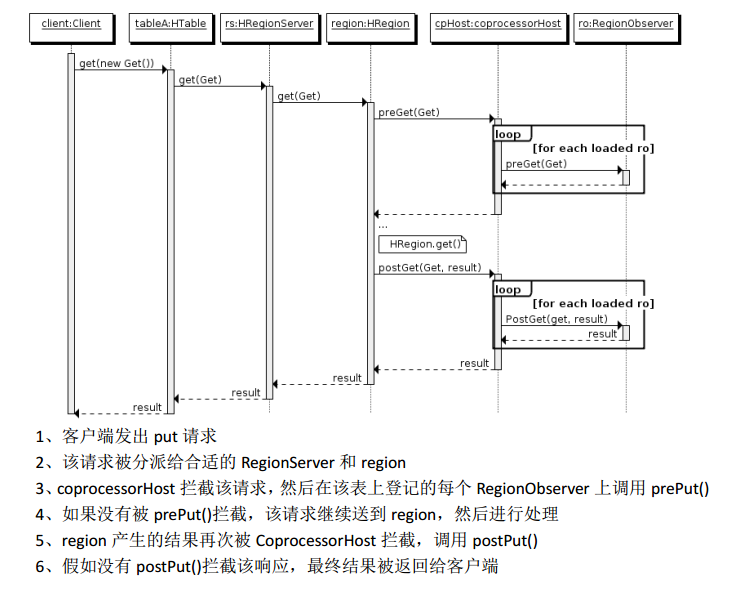
(1) Observer �����ڴ�ͳ���ݿ��еĴ�������������ijЩ�¼���ʱ������Э�������ᱻ Server �˵��á�Observer Coprocessor ����һЩɢ���� HBase Server �˴����е� hook ���ӣ� �ڹ̶����¼�����ʱ�����á����磺 put ����֮ǰ�й��Ӻ��� prePut���ú����� put ����
ִ��ǰ�ᱻ Region Server ���ã��� put ����֮������ postPut ���Ӻ���
�� HBase0.92 �汾Ϊ�������ṩ�����ֹ۲��߽ӿڣ�
�� RegionObserver���ṩ�ͻ��˵����ݲ����¼����ӣ� Get�� Put�� Delete�� Scan �ȡ�
�� WALObserver���ṩ WAL ��ز������ӡ�
�� MasterObserver���ṩ DDL-���͵IJ������ӡ��紴����ɾ���������ݱ��ȡ�
�� 0.96 �汾������һ�� RegionServerObserver
��ͼ���� RegionObserver Ϊ���ӽ��� Observer ����Э��������ԭ����
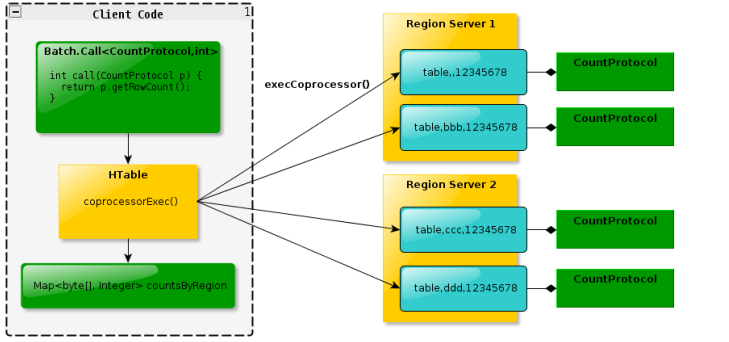
(2) Endpoint Э���������ƴ�ͳ���ݿ��еĴ洢���̣��ͻ��˿��Ե�����Щ Endpoint Э�� ����ִ��һ�� Server �˴��룬���� Server �˴���Ľ�����ظ��ͻ��˽�һ��������� �����÷����ǽ��оۼ����������û��Э�����������û���Ҫ�ҳ�һ�ű��е�������ݣ���
max �ۺϲ������ͱ������ȫ��ɨ�裬�ڿͻ��˴����ڱ���ɨ��������ִ�������ֵ�� �����������ķ��������õײ㼯Ⱥ�IJ����������������м��㶼���е� Client ��ͳһִ �У��Ʊ�Ч�ʵ��¡����� Coprocessor���û����Խ������ֵ�Ĵ��벿�� HBase Server �ˣ�
HBase �����õײ� cluster �Ķ���ڵ㲢��ִ�������ֵ�IJ���������ÿ�� Region ��Χ�� ִ�������ֵ�Ĵ��룬��ÿ�� Region �����ֵ�� Region Server �˼�������������� max ֵ���ظ��ͻ��ˡ��ڿͻ��˽�һ������� Region �����ֵ��һ���������ҵ����е����ֵ��
���������ִ��Ч�ʾͻ���ߺܶ�
��ͼ�� EndPoint �Ĺ���ԭ����
(3)�ܽ�
Observer ������Ⱥ�������Ŀͻ��˲��������п����в�ͬ����Ϊ����
Endpoint ������չ��Ⱥ���������Կͻ���Ӧ�ÿ����µ���������
observer ������ RDBMS �еĴ���������Ҫ�ڷ���˹���
endpoint ������ RDBMS �еĴ洢���̣���Ҫ�� client �˹���
observer ����ʵ��Ȩ���������ȼ����á���ء� ddl ���ơ� ���������ȹ���
endpoint ����ʵ�� min�� max�� avg�� sum�� distinct�� group by �ȹ���
����Э���������ط�ʽ
Э�������ļ��ط�ʽ�����֣����dz�֮Ϊ��̬���ط�ʽ�� Static Load�� �Ͷ�̬���ط�ʽ �� Dynamic Load���� ��̬���ص�Э��������֮Ϊ System Coprocessor����̬���ص�Э�������� ֮Ϊ Table Coprocessor
1����̬����
ͨ���� hbase-site.xml ����ļ���ʵ�֣� ����ȫ�� aggregation���ܹ��������еı��� �����ݡ�ֻ��Ҫ�������´��룺
| 1 2 3 4 |
|
����Ϊ���� table ������һ�� cp class�������á� ,���ָ���ض�� class
2����̬����
���ñ� aggregation��ֻ���ض��ı���Ч��ͨ�� HBase Shell ��ʵ�֡�
disable ָ������ hbase> disable 'mytable'
���� aggregation
hbase> alter 'mytable', METHOD => 'table_att','coprocessor'=>
'|org.apache.Hadoop.hbase.coprocessor.AggregateImplementation||'
����ָ���� hbase> enable 'mytable'
3���������

����������������
row key �� HBase ������ B+ tree �ṹ������洢�ģ����� scan ������Ƚ�Ч�ʡ������� row key �洢������ column value �洢 id ֵ���������� ������� Hbase �������Ľṹ��
���� HBase ����û�ж��������� Secondary Index�����ƣ�����������������ֻ�ܵ��������� RowKey��Ϊ����֧�ֶ�������ѯ����������Ҫ�����п�����Ϊ��ѯ�������ֶ�һһƴ�ӵ� RowKey �У����� HBase �����м�Ϊ����������
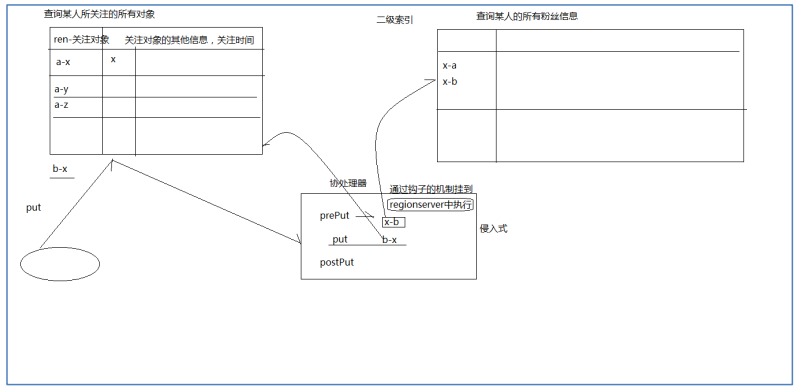
���罻��Ӧ���У�������Ҫ���ټ������û��Ĺ�ע�б� guanzhu��ͬʱ������Ҫ��������� �ֻ��ķ�˿�б� fensi��Ϊ��ʵ������������ʵ���ǽ������Ż�Ϊ����ı���
����һ����ע��Ϣʱ��Ϊ�˼���Ӧ�ö�ά�������������ĸ��������� Observer Э������ʵ �֣�