摘要
提出一种Inception的网络结构,该有提高神经网络的计算资源利用率,可以在计算资源固定的情况下,使网络变得更深、更广。这种结构的提出是基于赫布理论和多尺度处理直觉。其中GoogleLeNet,是Inception网络结构的一个特例。
引言
在目标检测的前沿,最大的收获不是简单的深层、更宽的神经网络的应用,而是深层结构与经典计算机视觉的协同作用,就例如R-CNN。
算法的性能非常重要,特别是能耗与内存的使用,他们决定了该算法是否能真实应用于网络中。
论文提出Inception网络结构是一种高效的计算机视觉深度神经网络结构,是一种模块结构。
近期工作
最近神经网络大致趋势是,增加网络深度,增加网络层宽度,利用dropout解决过拟合问题。
Inception结构大量使用了1x1卷积层,主要原因是:它可以通过降维来解决计算的瓶颈,同时也可以加深网络的深度,或者是宽度。
R-CNN是当前较好的目标检测网络,它将整个问题分解成两个子问题。1、利用低层次特征,如纹理和颜色,对目标进行区域定位。2、通过CNN网络对这些位置上分类。
动机和高层次的探索
神经网络性能最直观的提升方法是增加网络深度与宽度。但是这样的做法主要有两个缺点。一、参数更多,意味着容易出现过拟合。二、是占用更多的计算资源,假如网络体积很大,但是很多权重接近于0,这是没用的,完全是浪费资源。
解决上述两个缺点的方法是引入稀疏性和用稀疏连接替代全连接层。引入稀疏性是指用一个复杂的结构近似局部最优稀疏,以接近生物神经系统(这是Inception的核心)。生物上的稀疏性实质与这里讲述的优点区别。生物上的稀疏不只是是指神经元之间的稀疏连接与结构上的稀疏,更多是激发阈值引起。用稀疏连接替代全连接层则是通过卷积操作来构建稀疏性,这是当前网络常用的操作。
然而对于非均匀稀疏数据的计算效率是非常低的,这里非均匀稀疏数据是指某层神经元的输出情况,即加入经过卷积或某些特定结构后,某层的神经元输出矩阵是稀疏的,这会影响计算的效率。在稀疏矩阵中计算效率受‘查询’与‘缓存丢失’限制。
这引出中间步骤的问题:能否通过一个结构实现类似滤波器的稀疏性?更有研究表明,将稀疏的矩阵聚类为相对密集矩阵会有更佳的性能。所以这作者提出用一个复杂的结构来近似局部最优稀疏结构。
这就是论文提出Inception的根据。从论文图可以看出,Inception结构中包含一堆卷积核,卷积的连接是稀疏的。直观上说Inception结构的提出是试图通过一个复杂的结构(虽然是复杂结构,但带有稀疏性,可以看做将稀疏矩阵聚类为密集矩阵)来近视表示生物视觉系统的稀疏结构。同时被证明在定位上下文和目标检测中尤为有用。
结构细节
Inception的结构考虑的是将卷积神经网络近视成一个最优的局部稀疏结构,并将输出转为密集矩阵。
论文中提及‘我们假设来自较早层的每个单元对应于输入图像的某个区域,并且这些单元被filter bank’。在较低层(接近输入层),相关单元将关注局部区域的信息。之后这些局部的信息又可以通过1x1的卷积和传递到下一层。同时我们也可以通过使用更大的卷积来减少cluters(应该是卷积后输出矩阵的大小)。
为了避免patch-alignment问题,Inception结构采用的卷积核尺寸限制在1x1,3x3和5x5,经过上述卷积核,所有输出将会叠加到一个矩阵上。同时,pooling结构是当前卷积网络成功的关键,所以在增加一个并行的pooling结够。
论文中同时提出了,随着Inception结构的叠加,他们的相关输出统计会发生变化,在层次较深的地方,捕获到的更抽象特征,他们的空间集中度会降低,所以要采用更大的卷积核,所以建议在高层次中增加使用3x3,5x5的卷积核。
上面Inception结构存在一个重要的问题―‘计算量’,在深层的卷积网络中,适度数量的5x5卷积操作是被禁止的。一旦加入了pooling操作,这个问题就尤为突出。将pooling与卷积结构合并输出,将会大大增加输出数量。
为了解决这个问题,提出‘降维’的想法。论文中提出使用1x1的卷积核进行降维。1x1的卷积核不仅可以降维,同时还有修正线性特性。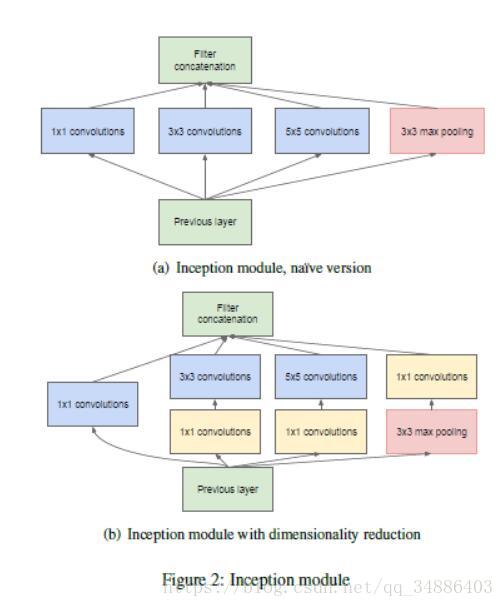
Inception网络是指由Inception模块堆积而成的网络,偶尔在Inception模块之间使用步长为2的max-pooling对网络进行采用。由于技术原因,在高层次中使用Inception模块,在底层仍使用传统的卷积网络效果更好。
这个结构一个有用的地方是:他可以显著的增加每个阶段的神经元数量,但又不会造成下个阶段非常大的计算复杂度。他是通过在大型卷积前使用1x1卷积核进行降维实现。
此外,该设计遵循的实际直觉是,视觉信息应该在不同的尺度上进行处理,然后进行聚类,以便下一阶段能够同时从不同的尺度中提取特征。
GoogLeNet
该网络是他们比赛中使用的网络结构。
所有的卷积,包括初始模块中的卷积,都采用了线性校正激活。在RGB颜色空间中,我们网络中接收场的大小为224×224,平均为零。
具体结构如下图。
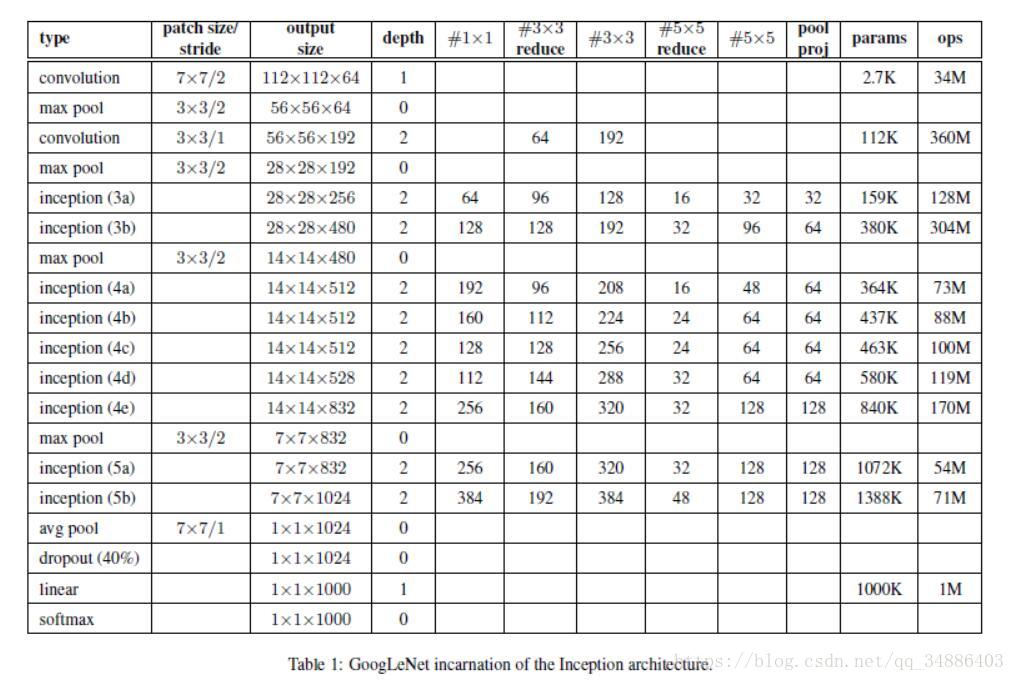
这个网络接受域(输入数据维度)为224X224的彩色图片,同时要将输入数据调整为零均值。图中“#3X3 reduce”表示在3X3的卷积核的执行前面需要加入1X1的卷积核,以降低维度。同时整个网络使用的激活函数都是ReLU。
网络的设计要考虑计算效率与实用性。
在网络最后部分,连接输出标签的,常使用全连接层,因为这样比较容易训练网络,通常是这样做,但不是一定的,本文不想此处产生较大影响,即主要训练前面的网络。
因为网络比较深,考虑到梯度反向传播的问题,在中间层增加的辅助分类器,在训练阶段,辅助分类器的误差以0.3的权重加到主网络的误差上面。在测试时候去掉辅助分类器。
具体结构中,1X1卷积数为128,dropout概率为0.7
训练方法
一种经过比赛证明有用的图片预处理方法,可以随意裁剪8%到100%的图像区域,但要保持横纵比在【3/4,4/3】间隔
分类挑战竞赛与结果
Top-1:最后能正确分类
Top-5:只有正确分类的类别排在前5就行
上述的分类都是根据分类分数进行。
除了本文中提到的训练技术之外,我们还在测试中采用了一系列的技术来获得更高的性能,下面我们将对这些技术进行描述。
1、训练了7个GoogleNet,使用它们进行共同分类。它们仅在抽样方法和随机输入图像顺序上存在差异。
2、在测试中,使用更具有竞争性的Cropping approach,将图片resize成256,288,320,352的4个大小维度,分别取它们左,中,右的三张图片,如果是人物图片,就取上,中,下的三张。然后对于每张图片,取4个角和中心构成224X224,并且原来的也resize成224X224,再取最后它们的镜像。
3、在多个crop上使用所有分类器上,对Softmax概率进行平均,以获得最终的预测结果。
目标检测挑战竞赛与结果
结论
我们的结果证明可以用易于获得的密集结构来逼近预期的最优稀疏结构,以此来提升计算机视觉神经网络的性能。这种方法的主要优点是,与较浅和较窄的结构相比,在计算需求略有增加的情况下,能显著提升网络的性能。我们的对象检测工作很有竞争力,尽管没有使用上下文,也没有执行边框回归,这表明了Inception体系结构的优势。未来的工作应该要创建更稀疏更精细的结构,同时将Inception用于更多的领域。
个人总结
整篇论文读了有2、3遍,到现在仍有点晕乎乎的,感觉作者写的东西有点难懂,可能是英语不好的原因吧。中间有3部分没有写笔记,感觉没什么好写的。