1.1. �ֲ�ʽ�� ���
�����ǽ��е���Ӧ�ÿ������漰����ͬ����ʱ��������������synchronized����Lock�ķ�ʽ��������̼߳�Ĵ���ͬ�����⡣�������ǵ�Ӧ���Ƿֲ�ʽ��Ⱥ����������£���ô����Ҫһ�ָ��Ӹ��������ƣ��������ֿ�����Ľ���֮�������ͬ�����⡣
����Ƿֲ�ʽ����
1.1.1. ͼ�⣺��ƽ���Ϳ������� ģ��
�ֲ�ʽ���ĸ����ԭ�����Ƚϳ����Ѷ��������һ���Ĺ�������ȣ����ƾͼ��ˡ�
�ܾ���ǰ����һ��������һ�ھ���ˮ�ʷdz��ĺã������Ƕ�����ȡ�����ˮ��������ôһ�ڣ�������˺ܶ࣬����Ϊ����ȡˮ��ܶ�Ź������ͷ��Ѫ����
��������Ҫ��������Ǵ峤�ʾ���֭�����������һ��ƾ��ȡˮ�ķ��������߰���һ�������ˣ�ά��ȡˮ������
˵����������ܼ�ȡˮ֮ǰ����ȡ�š�������ǰ��ģ��Ϳ�����ȡˮ���ȵ�������ǰ�棬��Щ�ģ�û��������ǰ����ˣ�һ��һ�����ţ��ھ����ų�һ�ӡ�ȡˮʾ��ͼ���� ��
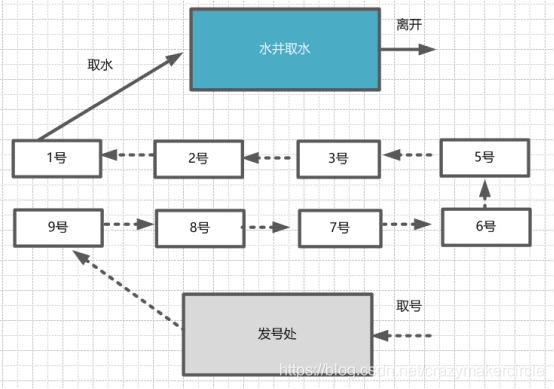
�����Ŷ�ȡˮģ�ͣ�����һ������ģ�͡�������ǰ��ĺţ�ӵ��ȡˮȨ������һ�ֵ��͵Ķ�ռ�������⣬�ȵ��ȵã�������ǰ�������ȡ��ˮ��ȡˮ֮����ֵ���һ����ȡˮ�����٣�������ͦ��ƽ�ģ�˵������һ�ֹ�ƽ����
�ڹ�ƽ��ռ���Ļ����ϣ��ٽ�һ������������������ģ�͡�
�ٶ���ȡˮʱ�Լ�ͥΪ��λ���ĸ���ͥ�κ����õ��ţ��Ϳ����ź�ȡˮ���������һ����ͥ��һ�����õ��ţ�����������ʱ�������ˮ������ȡ�š��µ��ź�ȡˮʾ��ͼ���� ��
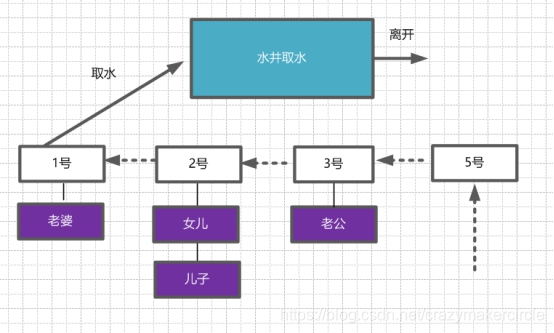
����ͼ��1�ţ��Ϲ��кţ������������ˣ�ֱ���ŵ�һ������ƾ����ٿ���ͼ��2�ţ��������ڴ�ˮ�����Ķ��Ӻ�Ů��Ҳ�������ˣ�ֱ���ŵڶ��������������ƾ���� �ȵȣ������ͬһ����ͥ������ֱ�Ӹ����źţ���������ȡ�ŴӺ�������
�����������ģ�ͣ����ǿ�����������ģ�͡�ֻҪ����������ͬһ���źţ������������ȡˮ��������ģ���У��൱��һ���������Ա������������ͽ�������������
1.1.2. ͼ�⣺ zookeeper�ֲ�ʽ����ԭ��
����������ԭ���ͻᷢ�֣�Zookeeper ��������һ���ֲ�ʽ�������ӡ�
���ȣ�Zookeeper��ÿһ���ڵ㣬����һ����Ȼ��˳������
��ÿһ���ڵ����洴���ӽڵ�ʱ��ֻҪѡ��Ĵ�������������EPHEMERAL_SEQUENTIAL ��ʱ�������PERSISTENT_SEQUENTIAL �����������ͣ���ô���µ��ӽڵ���棬�����һ�������š���������ţ�����һ�����ɵĴ����ż�һ
���磬����һ�����ڷ��ŵĽڵ㡰/test/lock����Ȼ������Ϊ���ڵ㣬������������ڵ����洴����ͬǰ���ӽڵ㣬�ٶ���ͬ��ǰΪ��/test/lock/seq-�����ڴ����ӽڵ�ʱ��ͬʱָ�����������͡�����ǵ�һ���������ӽڵ㣬��ô���ɵ��ӽڵ�Ϊ/test/lock/seq-0000000000����һ���ڵ���Ϊ/test/lock/seq-0000000001���������ƣ��ȵȡ�
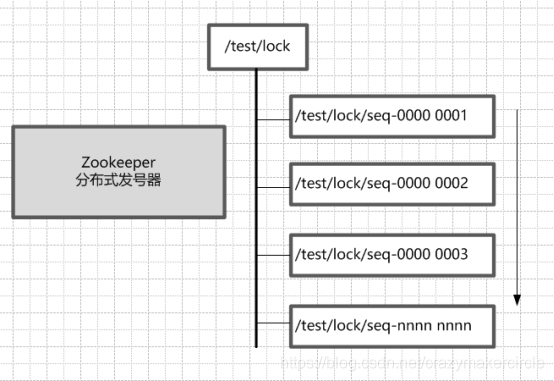
��Σ�Zookeeper�ڵ�ĵ����ԣ����Թ涨�ڵ�����С���Ǹ��������
һ��zookeeper�ֲ�ʽ����������Ҫ����һ�����ڵ㣬�����dz־ýڵ㣨PERSISTENT���ͣ���Ȼ��ÿ��Ҫ��������̶߳���������ڵ��´�������ʱ˳��ڵ㣬������ŵĵ����ԣ����Թ涨�ź���С���Ǹ�����������ԣ�ÿ���߳��ڳ���ռ����֮ǰ�������ж��Լ����ź��Dz��ǵ�ǰ��С������ǣ����ȡ����
������Zookeeper�Ľڵ�������ƣ����Ա���ռ�����ķ�ʽ������Ҹ�Ч��
ÿ���߳���ռ��֮ǰ�������Ŵ����Լ���ZNode��ͬ�����ͷ�����ʱ����Ҫɾ�����ŵ�Znode�����ųɹ�����������ź���С�Ľڵ㣬�ʹ��ڵȴ�֪ͨ��״̬����˭��֪ͨ�أ�����Ҫ�����ˣ�ֻ��Ҫ��ǰһ��Znode ��֪ͨ�Ϳ����ˡ���ǰһ��Znode ɾ����ʱ�����ֵ����Լ�ռ������ʱ��һ��֪ͨ�ڶ������ڶ���֪ͨ�����������Ĵ����Ƶ��������
Zookeeper�Ľڵ�������ƣ�����˵�ܹ��dz������ģ�ʵ�����ֻ��Ĵ����Ƶ���Ϣ���ݡ�����ķ����ǣ�ÿһ����֪ͨ��Znode�ڵ㣬ֻ��Ҫ����linsten���� watch �����ź����Լ�ǰ���Ǹ������ҽ������Լ�ǰ����Ǹ��ڵ㡣 ֻҪ��һ���ڵ㱻ɾ���ˣ��ͽ�����һ���жϣ������Լ��Dz��������С���Ǹ��ڵ㣬����ǣ���������
Ϊʲô˵Zookeeper�Ľڵ�������ƣ�����˵�Ƿdz������أ�
һ����ʽ����β��ӣ��������ǰ�棬�Ͳ����м�ض��𣿱��磬�ڷֲ�ʽ�����£����������ԭ���߷��������˻���������ԭ�����ǰ����Ǹ��ڵ�û�ܱ�����ɾ���ɹ�������Ľڵ㲻����Զ�ȴ�ô��
��ʵ��Zookeeper���ڲ����ƣ��ܱ�֤����Ľڵ��ܹ������ļ�����ɾ���ͻ�������ڴ���ȡ�Žڵ��ʱ����������ʱznode �ڵ����������znode �ڵ㣬һ����� znode �Ŀͻ�����Zookeeper��Ⱥ������ʧȥ��ϵ�������ʱ znode Ҳ���Զ�ɾ����������������Ǹ��ڵ㣬Ҳ���յ�ɾ���¼����Ӷ��������
˵Zookeeper�Ľڵ�������ƣ��Ƿdz������ġ�����һ��ԭ��
Zookeeper������β��ӣ��������ǰ��ķ�ʽ�����Ա�����ȺЧӦ����ν��ȺЧӦ����ÿ���ڵ�ҵ������нڵ㶼ȥ������Ȼ��������ӳ���������������������ѹ��������������ʱ˳��ڵ㣬��һ���ڵ�ҵ���ֻ�����������һ���ڵ��������ӳ��
1.1.3. �ֲ�ʽ���Ļ�������
���������ǻ���zookeeper��ʵ��һ�·ֲ�ʽ����
���ȶ�����һ�����Ľӿڣ��ܼ�һ������������һ������������
/*** create by ��� @ ���Ȧ**/
public interface Lock {boolean lock() throws Exception;boolean unlock();
}ʹ��zookeeperʵ�ֲַ�ʽ�����㷨���̣��������£�
��1��������ռ�ĸ��ڵ㲻���ڣ����ȴ���Znode���ڵ㡣�������Ϊ��/test/lock����������ڵ㣬������һ�ѷֲ�ʽ����
��2���ͻ��������Ҫռ���������ڡ�/test/lock���´�����ʱ����������ӽڵ㡣
�������ʹһ����������ӽڵ�ǰ�����硰/test/lock/seq-�������һ���ͻ��˶�Ӧ���ӽڵ�Ϊ��/test/lock/seq-000000000�����ڶ���Ϊ ��/test/lock/seq-000000001�����Դ����ơ�
���ǰΪ��/test/lock/�������һ���ͻ��˶�Ӧ���ӽڵ�Ϊ��/test/lock/000000000�����ڶ���Ϊ ��/test/lock/000000001�� ���Դ����ƣ�Ҳ�dz�ֱ�ۡ�
��3���ͻ��������Ҫռ����������Ҫ�жϣ��ж��Լ��������ӽڵ��Ƿ�Ϊ��ǰ�ӽڵ��б��������С���ӽڵ㡣���������Ϊ��������������ǰһ��Znode�ӽڵ�����Ϣ������ӽڵ���֪ͨ���ظ��˲���ֱ���������
��4����ȡ����ʼ����ҵ�����̡����ҵ�����̺�ɾ����Ӧ���ӽڵ㣬����ͷ����Ĺ������Ա����Ľڵ��÷ֲ�ʽ����
1.1.4. ������ʵ��
lock�����ľ����㷨�ǣ����ȳ�����ȥ�������������ʧ�ܾ�ȥ�ȴ���Ȼ�����ظ���
�������£�
@Overridepublic boolean lock() {try {boolean locked = false;locked = tryLock();if (locked) {return true;}while (!locked) {await();if (checkLocked()) {locked=true;}}return true;} catch (Exception e) {e.printStackTrace();unlock();}return false;}���Լ�����tryLock�����ǹؼ�������������Ҫ�����飺
��1��������ʱ˳��ڵ㣬���ұ����Լ��Ľڵ�·��
��2���ж��Ƿ��ǵ�һ��������ǵ�һ����������ɹ���������ǣ����ҵ�ǰһ��Znode�ڵ㣬���ұ�����·����prior_path��
tryLock���������ѡ���£�
private boolean tryLock() throws Exception {//������ʱZnodeList<String> waiters = getWaiters();locked_path = ZKclient.instance.createEphemeralSeqNode(LOCK_PREFIX);if (null == locked_path) {throw new Exception("zk error");}locked_short_path = getShorPath(locked_path);//��ȡ�ȴ����ӽڵ��б����ж��Լ��Ƿ��һ��if (checkLocked()) {return true;}// �ж��Լ��ŵڼ���int index = Collections.binarySearch(waiters, locked_short_path);if (index < 0) { // ���綶������ȡ�����ӽڵ��б�������Ѿ�û���Լ���throw new Exception("�ڵ�û���ҵ�: " + locked_short_path);}//����Լ�û�л��������Ҫ����ǰһ���ڵ�prior_path = ZK_PATH + "/" + waiters.get(index - 1);return false;}������ʱ˳��ڵ��������·������� locked_path ��Ա�С������ȡ��һ����·�������� locked_short_path ��Ա�С� �����·������һ����·����ֻ������·�������һ�㡣�ں�ȡ����Զ���ӽڵ��б��е�����·�����бȽ�ʱ����Ҫ�õ���·������Ϊ�ӽڵ��б���·�������Ƕ�·����ֻ�����һ�㡣
Ȼ����checkLocked�������ж��Ƿ��������ɹ���������ء�����Լ�û�л��������Ҫ����ǰһ���ڵ㡣�ҳ�ǰһ���ڵ��·���������� prior_path ��Ա�У��������await �ȴ�������ȥ����ʹ�á�
�ڽ���await�ȴ������Ľ���ǰ����˵��checkLocked �����жϷ�����
��checkLocked�����У��ж��Ƿ���Գ��������жϹ���ܼ���ǰ�����Ľڵ㣬�Ƿ�����һ����ȡ�����ӽڵ��б��ĵ�һ��λ�ã�
����ǣ�˵�����Գ�����������true����ʾ�����ɹ���
������ǣ�˵���������߳������ȳ�������������false��
checkLocked�����Ĵ������£�
private boolean checkLocked() {//��ȡ�ȴ����ӽڵ��б�List<String> waiters = getWaiters();//�ڵ㰴�ձ�ţ���������Collections.sort(waiters);// ����ǵ�һ���������Լ��Ѿ��������if (locked_short_path.equals(waiters.get(0))) {log.info("�ɹ��Ļ�ȡ�ֲ�ʽ��,�ڵ�Ϊ{}", locked_short_path);return true;}return false;}checkLocked�����Ƚϼ����ǻ�ȡ�������ӽڵ��б������Ҵ�С������ݽڵ����ƽ���������Ҫ������10λ���֣���Ϊǰ����һ���ġ�
����Ľ��������Լ���locked_short_pathλ���ڵ�һ���������Լ��Ѿ����������
������ʽ����ȴ�����await�Ľ��ܡ�
�ȴ�����await����ʾ��������ʧ���Ժ�ĵȴ�������ô�˴����߳�Ӧ����ʲô�أ�
private void await() throws Exception {if (null == prior_path) {throw new Exception("prior_path error");}final CountDownLatch latch = new CountDownLatch(1);//���ı��Լ���С˳��ڵ��ɾ���¼�Watcher w = new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {System.out.println("�������ı仯 watchedEvent = " + watchedEvent);log.info("[WatchedEvent]�ڵ�ɾ��");latch.countDown();}};client.getData().usingWatcher(w).forPath(prior_path);latch.await(WAIT_TIME, TimeUnit.SECONDS);}
��������һ��watcher�������������ĵ�ַ��������һ�����ص�prior_path ��Ա���������������Լ�ǰһ���ڵ�ı䶯�������Ǹ��ڵ������нڵ�ı䶯��Ȼ����latch.await������ȴ�״̬���ȵ�latch.countDown()�����ѡ�
һ��prior_path�ڵ㷢���˱䶯����ô�ͽ��̴߳ӵȴ�״̬���ѣ�����һ�ֵ��������ᡣ
���ˣ����ڼ������㷨������ɡ����ǣ����滹û��ʵ�����Ŀ����롣
ʲô�ǿ������أ�
? ֻ��Ҫ����ͬһ���߳̽�������Ĵ��룬�����ظ������ɹ����ɡ�
��ǰ���lock��������ǰ����Ͽ�������ж������������£�public boolean lock() {synchronized (this) {if (lockCount.get() == 0) {thread = Thread.currentThread();lockCount.incrementAndGet();} else {if (!thread.equals(Thread.currentThread())) {return false;}lockCount.incrementAndGet();return true;}}//...}
Ϊ�˱�ɿ����룬�ڴ�����������һ�������ļ�����lockCount �������ظ������Ĵ����������ͬһ���̼߳�����ֻ��Ҫ���Ӵ�����ֱ�ӷ��أ���ʾ�����ɹ���
1.1.5. �ͷ�����ʵ��
�ͷ�����Ҫ������������
��1�������������ļ������������0��ֱ�ӷ��أ���ʾ�ɹ����ͷ���һ�Σ�
��2�����������Ϊ0���Ƴ�Watchers������������ɾ��������Znode��ʱ�ڵ㣻
�������£�
@Overridepublic boolean unlock() {if (!thread.equals(Thread.currentThread())) {return false;}int newLockCount = lockCount.decrementAndGet();if (newLockCount < 0) {throw new IllegalMonitorStateException("Lock count has gone negative for lock: " + locked_path);}if (newLockCount != 0) {return true;}try {if (ZKclient.instance.isNodeExist(locked_path)) {client.delete().forPath(locked_path);}} catch (Exception e) {e.printStackTrace();return false;}return true;}���Ϊ�˾�����֤�̰߳�ȫ������������������ͣ�����int���ͣ�����Java�������е�ԭ�����͡���AtomicInteger��
1.1.1. �ֲ�ʽ����Ӧ�ó���
ǰ���ʵ�֣���Ҫ�ļ�ֵ��չʾһ�·ֲ�ʽ���Ļ���������ԭ����ʵ�ʵĿ����У������Ҫʹ�õ��ֲ�ʽ����������Ҫ�Լ������ӣ�����ֱ��ʹ��curator�ͻ����еĸ��ֹٷ�ʵ�ֵķֲ�ʽ�����������е�InterProcessMutex ����������
InterProcessMutex ����������ʹ��ʵ�����£�
@Test
public void testzkMutex() throws InterruptedException {CuratorFramework client=ZKclient.instance.getClient();final InterProcessMutex zkMutex =new InterProcessMutex(client,"/mutex"); ;for (int i = 0; i < 10; i++) {FutureTaskScheduler.add(() -> {try {zkMutex.acquire();for (int j = 0; j < 10; j++) {count++;}try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}log.info("count = " + count);zkMutex.release();} catch (Exception e) {e.printStackTrace();}});}Thread.sleep(Integer.MAX_VALUE);
}
����ܽ�һ��Zookeeper�ֲ�ʽ����
Zookeeper�ֲ�ʽ��������Ч�Ľ���ֲ�ʽ���⣬�����������⣬ʵ��������Ϊ��
���ǣ�Zookeeperʵ�ֵķֲ�ʽ����ʵ����һ��ȱ�㣬�Ǿ������ܲ���̫�ߡ���Ϊÿ���ڴ��������ͷ����Ĺ����У���Ҫ��̬����������˲ʱ�ڵ���ʵ�������ܡ�ZK�д�����ɾ���ڵ�ֻ��ͨ��Leader��������ִ�У�Ȼ��Leader����������Ҫ������ͬ�������е�Follower�����ϡ�
���ԣ��ڸ����ܣ��߲����ij����£�������ʹ��Zk�ķֲ�ʽ����
Ŀǰ�ֲ�ʽ�����Ƚϳ��졢�����ķ����ǻ���redis������zookeeper�Ķ��ַ���������������Ӧ�ó�����ͬ���� zookeeperֻ�����е�һ�֡�Zk�ķֲ�ʽ����Ӧ�ó�������Ҫ�߿ɿ���������̫�߲����ij����¡�
�ڲ������ܸߣ�����Ҫ��ܸߵij����£��Ƽ�ʹ�û���redis�ķֲ�ʽ����
����
��һƪ�� zookeeper + netty ʵ�ָ߲���IM ����
���Ȧ �ڼ����� �߲���IM ʵս ϵ��
- Java (Netty) ������� �ڼ�������ʵս ��Դ��Ŀʵս
- Netty Դ�롢ԭ����JAVA NIO ԭ��
- Java ������ һ����
- ���Ȧ �� ���� ����� ��