说明
- 原文链接。
- 此处将Session-based Recommendation直译为会话推荐,有地方意译为短序列推荐。
- 此处将external memory译为外部记忆,直译话为外部存储器(外存),short-term memory译为短期记忆,直译的话为短期存储器。
标题
- 题目:STMAP:基于会话推荐的短期注意/记忆优先模型
- 作者:
Qiao Liu University of Electronic Science and Technology of China Chengdu, China
Yifu Zeng University of Electronic Science and Technology of China Chengdu, China
Refuoe Mokhosi University of Electronic Science and Technology of China Chengdu, China
Haibin Zhang University of Electronic Science and Technology of China Chengdu, China
摘要
基于匿名会话的用户行为预测是基于web的行为建模研究中的一个难题,其主要原因是用户行为的不确定性和信息的有限性。递归神经网络的最新进展为解决这一问题带来了很有前景的方法,长期短期记忆模型被证明能够有效地从以前的点击中获取用户的一般兴趣。但是,现有的方法都没有明确考虑用户当前操作对其下一步操作的影响。在这项研究中,我们认为长期记忆模型可能不足以建模长会话,长会话通常包含用户兴趣漂移所导致的意外点击。提出了一种新的短期注意/记忆优先模型,该模型能够从会话上下文的长期记忆中获取用户的一般兴趣,同时考虑用户从最后一次点击的短期记忆中获取当前兴趣。通过2015年RecSys挑战赛和2016年CIKM杯的三个基准数据集,对所提出的注意力机制的有效性和有效性进行了广泛评估。数值结果表明,该模型在所有试验中均达到了最优性能。
1. 介绍
基于会话的推荐系统(SRS)是现代商业网络系统的重要组成部分,通常用于改善用户体验,建议根据用户在浏览器会话行为编码,和推荐的任务是预测用户的下一个操作(点击一个条目)基于动作的序列在当前会话[5,21]。最近的研究强调了在各种推荐系统中使用递归神经网络(RNNs)的重要性,其中RNNs在基于会话的推荐任务中的应用在过去几年取得了显著的进展[6,17]。虽然RNN模型已经被证明可以从一系列的[20]动作中获取用户的一般兴趣,但是学习如何从会话中进行预测仍然是一个具有挑战性的问题,这主要是由于用户行为固有的不确定性和浏览器会话[18]提供的有限信息。
根据现有的文献,几乎所有基于RNN的SRS模型都只考虑将会话建模为一个项目序列,而没有明确考虑到用户兴趣随[6]时间的漂移,这在实践中可能存在问题。例如,如果用户刚刚点击了某个特定的数码相机链接并将其记录到会话中,那么用户的下一个操作很可能是响应当前操作。(1)如果当前的操作是在做出购买决定之前浏览产品描述,那么用户很可能在下一步访问另一个数码相机品牌目录。(2)如果当前的操作是将摄像头添加到购物车中,那么用户的浏览兴趣可能会转向其他外设,如存储卡。在这种情况下,向该用户推荐另一款数码相机并不是一个好主意,尽管该会话的初始意图是购买一台数码相机(正如前面的操作所反映的那样)。
在典型的SRS任务中,会话由一系列命名项组成,用户兴趣隐藏在这些隐式的反馈(例如,点击)中。为了进一步提高RNN模型的预测精度,需要具备对这种隐式反馈的长期兴趣和短期兴趣的学习能力。正如Jannach等人[7]所指出的,用户的短期兴趣和长期兴趣对于推荐都是非常重要的,但是传统的RNN架构并不是为了同时区分和利用这两类兴趣而设计的。
在本研究中,我们考虑通过在SRS模型中引入一种新的动作优先机制,即短期注意/记忆优先(STAMP)模型来解决这个问题,该模型可以同时考虑用户的整体兴趣和当前兴趣。在STAMP中,用户的一般兴趣由外部记忆捕获,该记忆由会话前缀中的所有历史点击(包括最后一次点击)构建,这就是术语“记忆”的含义。术语“最后一次点击”表示会话前缀的最后一次操作(项),SRS的目标是预测“下一次点击”与此“最后一次点击”的关系。在本研究中,我们使用最后一次点击的嵌入来代表用户当前的兴趣,并在此基础上建立了注意力机制。由于最后一次点击是外部记忆的组成部分,所以可以认为是用户兴趣的短期记忆。同样,建立在最后一次点击之上的用户注意力也可以被看作是短期的注意力。据我们所知,这是第一次尝试在构建基于会话的推荐的神经注意模型时同时考虑长/短期记忆。本研究的主要贡献如下:
- 我们介绍了一个短期的注意力/记忆优先模型,该模型学习:(a)一个具有跨会话项的均匀嵌入空间;(b)一个新的神经注意力模型,用于基于会话的推荐系统的下一次点击预测。
- 我们提出了一种新的注意力机制来实现STAMP模型,在该模型中,注意力权重是根据会话上下文计算的,并根据用户当前的兴趣进行增强。输出的注意力向量被解读为用户时间兴趣的组合表示,并且比其他基于神经注意力的解决方案对用户兴趣随时间的漂移更敏感。因此,它能够同时捕获用户的长期兴趣(响应最初的目的)和短期注意(当前兴趣)。通过对比研究,验证了该注意机制的有效性和有效性。
- 提出的模型分别在两个真实世界的数据集上进行了评估,分别是2015年RecSys的Yoochoose数据集和2016年CIKM Cup的Diginetica数据集。实验结果表明,本文提出的注意机制是一种先进的注意机制。
2. 相关工作
基于会话的推荐是推荐系统的一个子任务,它根据用户会话内的隐式反馈进行推荐。这是一项具有挑战性的任务,因为通常假定用户是匿名的,并且用户偏好(例如评级)没有明确地提供,相反,只有一些积极的观察(例如购买或点击)可提供给决策者[4]。在过去的几年里,越来越多的研究关注一直致力于SRS的挑战问题,根据他们的模型假设,普遍的方法可分为两种归类:全局注意力模型识别用户的一般[兴趣3],和局部模型强调用户的时间兴趣[19]。
获取用户一般兴趣的一种方法是基于用户的整个购买/点击历史的协同过滤(CF)方法。例如,矩阵分解(MF)方法[8]使用潜在向量来表示一般兴趣,这些兴趣是通过分解由整个历史事务数据组成的用户-项目矩阵来估计的。另一种方法称为邻域方法[14],它试图根据会话中项目的共同出现情况计算出的项目相似性来提出建议。第三种方法是基于马尔可夫链(MC)的模型[3,15],该模型利用用户动作之间的顺序连接进行预测。
上述模型探讨了用户的一般兴趣或当前兴趣。但是,先前的当前兴趣为基础的推荐系统很少考虑顺序之间的交互项不相邻的会话中,尽管总体兴趣为基础的推荐系统是善于捕捉用户的口味,但很难调整其建议用户最近购买没有显式地建模相邻连接[19]。理想情况下,一个好的推荐应该能够探索顺序行为,以及考虑用户的一般兴趣推荐,因为这两个因素可能会相互作用,影响用户的下一次点击。因此,一些研究人员试图通过考虑这两种用户兴趣来改进SRS模型。Rendle等人[13]提出了一种混合模型FPMC,将MF和MC的力量结合起来,对序列行为和总体兴趣进行建模,用于下一个篮子的推荐,从而获得比只考虑短期兴趣或长期兴趣更好的效果。Wang等人[19]提出了一种混合表示学习模型,该模型采用两层层次结构来建模用户的顺序行为和从他们的最后交易中获得的一般兴趣。但是,它们都只能对相邻操作之间的局部顺序行为建模,而不考虑会话上下文所传递的全局信息。
最近的研究表明,深度神经网络在序列数据的建模方面是非常有效的。受自然语言处理领域[16]最新进展的启发,一些基于深度学习的解决方案被开发出来,其中一些代表了SRS研究领域的最新水平[2,5,6,10]。Hidasi等人使用带有门控递归单元的深度递归神经网络对会话数据建模,该模型直接从给定会话中的前一次点击中学习会话表示,并为下一步操作提供建议。这是首次尝试应用RNN网络来解决SRS问题,由于RNNs提供的顺序建模能力,他们的模型可以考虑到用户的历史行为,从而预测下一步的行动。Tan等人提出了一种数据扩充技术来提高基于会话的推荐的rns性能。Yu等人提出了一个动态递归模型,该模型利用RNN学习用户在不同时间对每个篮子的一般兴趣的动态表示,并捕获篮子之间的全局顺序行为。
上面提到的大多数神经网络模型都是在SRS中实现的,通过使用相同的操作操作每个上下文点击项,允许模型以隐式的方式捕获下一次点击和上一次点击之间的相关性。最后一个时间步的隐藏状态也包含了序列的信息,重点放在最靠近下一次点击[1]的部分,因此可能会忘记一些距离较远的物品的一般兴趣特征。为了解决这个问题,引入了各种模型来捕获项目之间的相关性和更准确的一般兴趣。Hu等人提出了一种宽频带结构的神经网络(SWIWO)来学习用户会话上下文。它通过梳理当前会话中的所有项嵌入来构造会话上下文,根据与目标项的响应的相对距离,为每个项赋予一个固定的权重。Li等人提出了一种基于RNN的编译码器模型(NARM),该模型将RNN的最后一个隐藏状态作为连续行为,利用前一次点击的隐藏状态进行注意力计算,捕捉给定会话中的主要目的(一般兴趣)。另一个最近的相关工作是时间-LSTM模型[21],它是LSTM的一个变体。time - lstm通过使用时间门来控制最后消费物品的影响和存储时间间隔来建模用户的长期兴趣,从而同时考虑短期兴趣和长期兴趣,但是在大多数实际数据集中没有提供时间戳,所以这里不考虑它。
差异:我们的模型与SWIWO和NARM有显著差异。SWIWO以一种固定的方式确定会议中每个项目的权重,我们认为这在实践中是有争议的。在STAMP中,通过显式地考虑每个历史点击和最后一次点击之间的相关性,并计算给定会话的动态权重,所提出的注意机制可以帮助缓解这种矛盾。另外,NARM结合了主要目的和顺序行为,以获得将它们视为同等重要的补充特性的会话表示。而STAMP则明确强调了最后一次点击所反映的当前兴趣,从而捕捉到之前点击所产生的当前兴趣和一般兴趣的混合特征,从而明确地将最后一次点击的重要性引入到推荐系统中,而NARM只捕捉一般兴趣。可以在STAMP中增强短期兴趣,以便在兴趣漂移的情况下准确捕获用户当前的兴趣,特别是在长会话中。
3. 方法
3.1 形式化描述
典型的基于会话的推荐系统建立在历史会话的基础上,根据当前用户会话进行预测。每个会话,用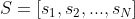 表示。,由一系列操作(用户点击的项目)组成,其中
表示。,由一系列操作(用户点击的项目)组成,其中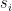 表示在第
表示在第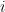 步点击的项目(ID)。
步点击的项目(ID)。 ,
, 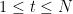 表示会话
表示会话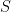 在
在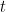 时刻截断的动作序列的前缀,令
时刻截断的动作序列的前缀,令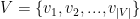 表示SRS系统中唯一项目的集合,称为项目字典。
表示SRS系统中唯一项目的集合,称为项目字典。
令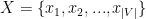 表示关于项目字典
表示关于项目字典 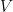 的嵌入向量。STMAP模型对
的嵌入向量。STMAP模型对 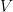 中的每一个项目
中的每一个项目 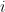 学习一个
学习一个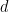 维实值嵌入
维实值嵌入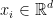 。其中,符号
。其中,符号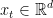 表示嵌入当前会话前缀
表示嵌入当前会话前缀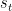 的最后一次点击
的最后一次点击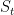 。我们的模型的目标是预测下一个可能的点击(即
。我们的模型的目标是预测下一个可能的点击(即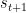 )基于给定的会话前缀
)基于给定的会话前缀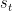 。确切地说,我们的模型构造和训练一个分类器去对项目字典
。确切地说,我们的模型构造和训练一个分类器去对项目字典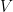 里每一个候选项学习生成一个得分,令
里每一个候选项学习生成一个得分,令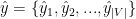 表示得分向量,其中
表示得分向量,其中 表示项目
表示项目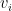 的得分。在得到预测结果后,
的得分。在得到预测结果后,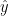 里的元素按降序排名,相对应的物品topk分数用于推荐。为了表述方便,我们将三个向量的三线性积定义为:
里的元素按降序排名,相对应的物品topk分数用于推荐。为了表述方便,我们将三个向量的三线性积定义为:
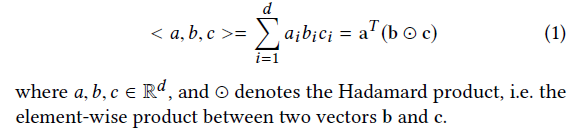
3.2 短期记忆优先模型(STMP)
所提出的STAMP模型是基于短期记忆优先模型(STMP)构建的,如图1所示。

从图1可以看出,STMP模型采用两个embeddings (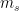 和
和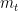 )作为输入,其中
)作为输入,其中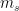 表示用户对当前会话的总体兴趣,它被定义为会话的外部记忆的平均值:
表示用户对当前会话的总体兴趣,它被定义为会话的外部记忆的平均值:

其中,外部记忆指的是当前会话前缀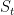 的项目嵌入序列。符号
的项目嵌入序列。符号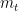 表示用户在该会话中的当前兴趣,在本研究中,最后点击的
表示用户在该会话中的当前兴趣,在本研究中,最后点击的 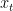 用于表示用户当前的兴趣:
用于表示用户当前的兴趣: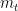 =
= 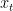 。因为
。因为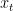 是从会话的外部记忆中取出的,所以我们称它为用户兴趣的短期记忆。然后利用两个MLP网络对一般兴趣和当前兴趣进行特征提取。图1中所示的MLP单元的网络结构彼此相同,不同之处在于它们具有独立的参数设置。使用一个简单的没有隐含层的MLP进行特征提取,对
是从会话的外部记忆中取出的,所以我们称它为用户兴趣的短期记忆。然后利用两个MLP网络对一般兴趣和当前兴趣进行特征提取。图1中所示的MLP单元的网络结构彼此相同,不同之处在于它们具有独立的参数设置。使用一个简单的没有隐含层的MLP进行特征提取,对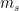 的操作定义为:
的操作定义为:
![]()
其中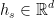 表示输出状态,
表示输出状态, 为加权矩阵,
为加权矩阵,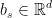 为偏置向量。是一个非线性激活函数(我们在本研究中使用tanh)。状态向量
为偏置向量。是一个非线性激活函数(我们在本研究中使用tanh)。状态向量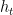 关于
关于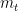 的计算方法与
的计算方法与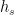 类似。对于给定的候选项
类似。对于给定的候选项 ,其得分函数定义为:
,其得分函数定义为:
![]()
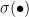 表示sigmod函数。让
表示sigmod函数。让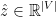 表示的向量由三线性积
表示的向量由三线性积 ,每一个
,每一个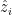 (
(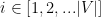 )表示加权用户兴趣表示与当前会话前缀
)表示加权用户兴趣表示与当前会话前缀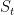 和候选项
和候选项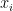 之间的非标准化余弦相似度。然后由softmax处理得到输出
之间的非标准化余弦相似度。然后由softmax处理得到输出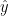 的函数:
的函数:
![]()
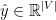 表示模型的输出向量,代表一个概率分布覆盖每一个项目
表示模型的输出向量,代表一个概率分布覆盖每一个项目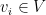 ,每个元素
,每个元素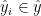 表示的概率事件,第六项将显示为接下来点击在这个会话。对于任何给定的会话前缀
表示的概率事件,第六项将显示为接下来点击在这个会话。对于任何给定的会话前缀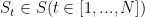 ,损失函数被定义为预测结果
,损失函数被定义为预测结果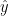 的交叉熵:
的交叉熵:

其中,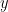 表示只激活于
表示只激活于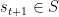 (ground truth)的one-hot向量。例如,如果
(ground truth)的one-hot向量。例如,如果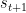 表示项目字典
表示项目字典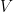 中的第
中的第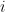 个元素
个元素 ,如果
,如果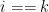 ,则
,则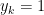 如果
如果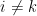 ,则
,则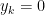 。然后使用迭代随机梯度下降(SGD)优化器优化交叉熵损失。
。然后使用迭代随机梯度下降(SGD)优化器优化交叉熵损失。
从STMP的定义模型方程(4)可以看到,它使得预测接下来点击基于内积的候选项和加权用户兴趣,通过双线性加权用户兴趣的代表组成的长期记忆(平均历史点击)和短期记忆(上一次点击)。这个三线性组合模型的有效性验证在4.5节中,实验结果证明该短期记忆的优先级机制可以非常有效地捕获用户的暂时兴趣,预测再次点击,达到最先进的性能在所有基准数据集。
然而,从方程2可以看出,当从当前会话的外部记忆建模用户的一般兴趣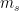 时,STMP模型将会话前缀中的每一项视为同样重要的是,我们认为这在获取用户兴趣漂移问题(可能造成意想不到的点击),特别是在长期会话是存在问题的。因此,我们提出了一个注意力模型来解决这个问题,这个模型已经被证明能够有效地捕获长序列中的注意力漂移。我们提出的注意模型是基于STMP模型设计的,它与STMP的思想是一样的,即它也优先考虑短期注意,因此我们称之为短期注意/记忆优先模型(STAMP)。
时,STMP模型将会话前缀中的每一项视为同样重要的是,我们认为这在获取用户兴趣漂移问题(可能造成意想不到的点击),特别是在长期会话是存在问题的。因此,我们提出了一个注意力模型来解决这个问题,这个模型已经被证明能够有效地捕获长序列中的注意力漂移。我们提出的注意模型是基于STMP模型设计的,它与STMP的思想是一样的,即它也优先考虑短期注意,因此我们称之为短期注意/记忆优先模型(STAMP)。
3.3 STAMP模型
STAMP模型的架构如图2所示。从图2中可以看到,这两个模型之间唯一的区别是,STMP模型中的用户一般兴趣的抽象特征向量(状态向量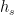 )计算平均的外部记忆,而STAMP模型中的
)计算平均的外部记忆,而STAMP模型中的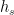 计算来自于一个基于用户一般兴趣的注意力层(一个实值向量
计算来自于一个基于用户一般兴趣的注意力层(一个实值向量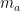 ),这是由注意机制所产生,称为注意力网络。
),这是由注意机制所产生,称为注意力网络。
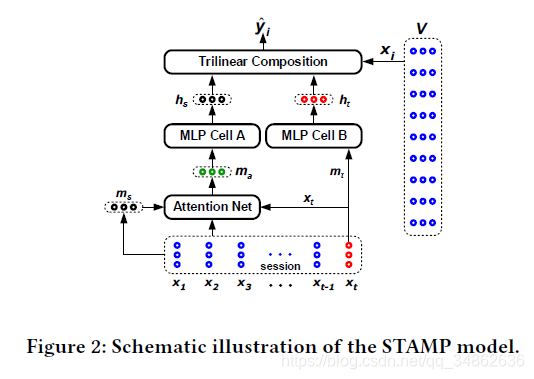
提出注意力网络包括两个部分:(1)一个简单的前馈神经网络(FNN)负责为每个项目在当前会话前缀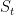 生成注意力权重(2)注重力复合函数负责计算基于注意力的用户一般兴趣
生成注意力权重(2)注重力复合函数负责计算基于注意力的用户一般兴趣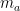 。用于计算注意力的FNN定义为:
。用于计算注意力的FNN定义为:
![]()
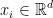 表示第
表示第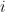 个项目
个项目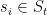 ,
,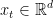 表示最近一次点击的项目,
表示最近一次点击的项目, 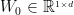 是一个加权向量,
是一个加权向量,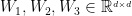 为加权矩阵,
为加权矩阵,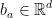 为偏置向量,
为偏置向量,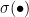 表示sigmod函数。
表示sigmod函数。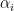 代表在当前会话前缀下项目
代表在当前会话前缀下项目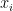 的注意力系数。从方程7可以看到注意力系数的计算基于一个会话前缀的嵌入目标项目
的注意力系数。从方程7可以看到注意力系数的计算基于一个会话前缀的嵌入目标项目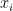 , 最近一次点击的项目
, 最近一次点击的项目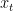 和会话表示
和会话表示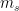 ,因此,它能够捕捉目标项目之间的相关性和长/短期记忆用户的兴趣。值得注意的是,在公式7中,短期记忆被明确地考虑,这与相关的著作有明显的不同,这就是为什么我们提出的注意模型被称为短期注意优先模型。
,因此,它能够捕捉目标项目之间的相关性和长/短期记忆用户的兴趣。值得注意的是,在公式7中,短期记忆被明确地考虑,这与相关的著作有明显的不同,这就是为什么我们提出的注意模型被称为短期注意优先模型。
在相对于当前会话前缀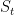 下获得注意力系数向量
下获得注意力系数向量 后,当前会话前缀
后,当前会话前缀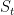 下基于用户的一般兴趣的注意力
下基于用户的一般兴趣的注意力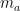 ,可以计算如下,并将
,可以计算如下,并将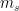 代入进去:
代入进去:
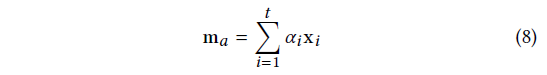
3.4 短期记忆模型
为了评估本研究的基本理念的有效性,也就是说,将根据会话(序列的动作)优先分配给用户的短期注意力/记忆行为决策,在本节中,我们提出一个短期记忆(STMO)模型,使预测的下一次点击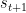 只基于当前会话前缀
只基于当前会话前缀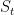 的上一次点击
的上一次点击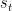 。与STMP模型类似,STMO模型中使用了一个没有隐藏层的简单MLP来进行特性抽象。MLP将上一次点击
。与STMP模型类似,STMO模型中使用了一个没有隐藏层的简单MLP来进行特性抽象。MLP将上一次点击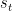 作为输入,输出一个向量
作为输入,输出一个向量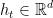 ,正如STMP中的“MLP CELL B”(见图1),定义为:
,正如STMP中的“MLP CELL B”(见图1),定义为:
![]()
其中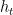 表示输出状态,
表示输出状态,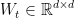 为加权矩阵,
为加权矩阵,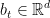 为偏置向量。为激活函数tanh。那么对于给定的候选项
为偏置向量。为激活函数tanh。那么对于给定的候选项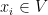 ,得分函数定义为
,得分函数定义为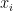 与
与 的内积:
的内积:
![]()
在获得得分向量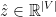 ,可以基于排名计算方程5,或优化模型的参数方程6的基础上像STMP模型一样做出预测。
,可以基于排名计算方程5,或优化模型的参数方程6的基础上像STMP模型一样做出预测。
4. 实验
4.1 数据集和数据准备
我们在两个数据集上评估提出的模型,第一个数据集名为Yoochoose,来自RecSys的15 Challenge 1,它包含从电子商务网站收集的六个月点击流,其中训练集只包含会话事件。另一个是来自CIKM Cup 20162的Diginetica数据集,在本研究中只使用了交易数据。
跟[5]和[10]一样,我们过滤掉长度为1的会话和两个数据集中出现次数少于5次的项。Yoochoose的测试集由与训练集相关的随后几天的会话组成,我们过滤掉在训练集中没有出现的点击(项目)。对于Diginetica,唯一的区别是我们使用随后一周的会话进行测试。在预处理阶段之后,Yoochoose数据集中的37,483个条目仍有7,966,257个会话,31,637,239次点击,Diginetica数据集中的43,097个条目有202,633次会话,982,961次点击。
与[17]相同,我们使用一个序列分割预处理,用于输入会话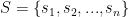 ,我们生成序列和对应的标签
,我们生成序列和对应的标签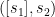 ,
, 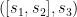 …
…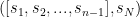 ,用于在两个数据集上进行培训和测试,证明是有效的。由于Yoochoose训练集相当大,根据[17]实验,对最近分数的训练比对整个分数的训练效果更好,所以我们使用最近分数的1/64和1/4的训练序列。三个数据集的统计数据如表1所示。
,用于在两个数据集上进行培训和测试,证明是有效的。由于Yoochoose训练集相当大,根据[17]实验,对最近分数的训练比对整个分数的训练效果更好,所以我们使用最近分数的1/64和1/4的训练序列。三个数据集的统计数据如表1所示。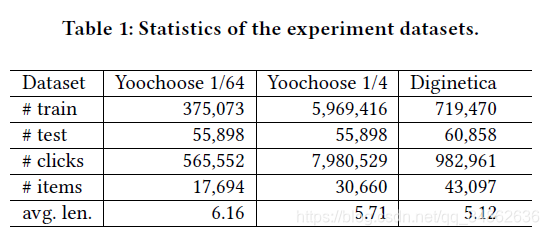
4.2 基线
下列模型,包括最新的和最相关的工作,被用作评估STAMP模型表现的基线:
- POP:一个简单的SRS模型,总是根据训练集中的出现频率推荐项目。
- item- knn[14]:一个item-to-item模型,基于候选项与会话中现有项之间的余弦相似性,推荐与现有项相似的项。包含了一个约束,以避免在[4,20]中很少访问的项目之间的高相似性。
- FPMC[13]:最先进的混合模型,用于下一个篮子的推荐。为了实现基于会话的推荐,我们在计算推荐分数时没有考虑用户的潜在表示。
- GRU4Rec[5]:基于RNN的深度学习模型,用于基于会话的推荐,该模型由GRU单元组成,利用会话并行的小批量训练过程,并在训练过程中使用基于排序的损失函数。
- GRU4Rec+[17]:基于GRU4Rec的aim模型,采用两种技术来提高GRU4Rec的性能,包括数据扩充过程和考虑输入数据分布变化的方法。
- NARM[10]:基于RNN的最先进的模型,使用注意力机制从隐藏状态捕获主要目的,并将其与序列行为相结合,作为最终表示,生成推荐。
4.3 评估
我们使用以下指标来评估SRS模型的性能,这些指标在其他相关工作中也被广泛使用。
P@20: P@K评分被广泛用于SRS领域预测准确性的测量。P @ K表示测试用例的比例,其中正确的推荐项目位于排名列表的前K位。在本文中,所有的测试都使用P@20,定义为:
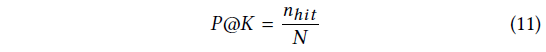
其中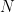 为SRS系统G中测试数据的个数,
为SRS系统G中测试数据的个数, 为在前
为在前 个排序列表中拥有所需要的项的情况的个数,当
个排序列表中拥有所需要的项的情况的个数,当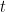 出现在
出现在 的排序列表的前
的排序列表的前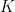 个位置时,发生
个位置时,发生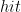 。
。
MRR@20:所需项目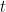 排名倒数的平均值。如果排名大于20,则排名倒数为0。
排名倒数的平均值。如果排名大于20,则排名倒数为0。
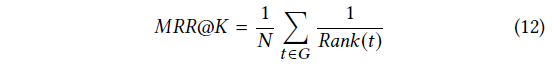
MRR是范围[0,1]的归一化得分,其值的增加反映了大多数“命中”在推荐列表的排名顺序中会出现更高的位置,这表明相应的推荐系统性能更好。
4.4 参数
超参数是通过在所有数据集里广泛网格搜索来进行优化,最好的模型在验证集中基于P@20分数早期停止选取,。超参数网格搜索范围如下:嵌入维数d{50、100、200、300},学习率η{0.001,0.005,0.01,0.1,1},学习速率衰减λ在{0.75,0.8,0.85,0.9,0.95,1.0}。根据平均性能,在这项研究中,我们使用以下超参数所有的测试在两个数据集:{d: 100,η: 0.005,λ: 1.0}。小批量设置:批量大小:512,epoch:30。所有的加权矩阵都是通过正态分布N(0,0.052)的抽样初始化的,所有的偏置都设置为零。所有的嵌入项都是用正态分布N(0,0.0022)随机初始化的,然后与其他参数联合训练。
4.5 下一次点击预测
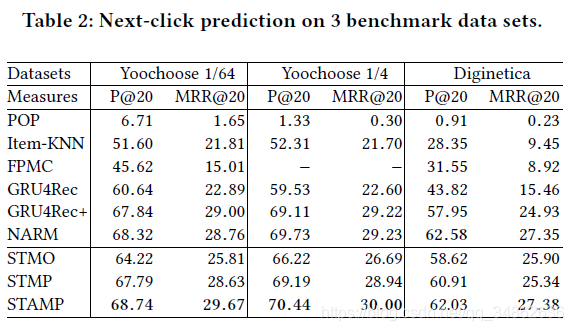
为了展示所提模型的整体性能,我们将其与最先进的项目推荐方法进行了比较,所有基准数据集的数值结果如表2所示,其中每一列的最佳结果以黑体突出显示。从表2可以看出,STAMP在Yoochoose数据集和Diginetica数据集上的P@20和MRR@20都达到了最先进的性能,验证了所提模型的有效性和有效性。从表2可以得出以下意见:
Item-KNN和FPMC等传统方法的性能不具有竞争力,仅优于朴素的POP模型。这些结果帮助验证的重要性,考虑到用户的行为(交互)结果表明,基于会话的推荐任务提出建议仅仅基于同现流行的物品(流行),或者只是在连续转换项目可能非常问题做出准确的建议。此外,这样的全局解决方案可能会耗费时间和内存,因此无法扩展到大型数据集。
所有的神经网络基线都明显优于传统模型,从而证明了深度学习技术在该领域的有效性。GRU4Rec+通过使用数据扩充技术来改进GRU4Rec的性能,该技术将单个会话划分为几个子会话进行培训。虽然GRU4Rec+没有修改GRU4Rec的模型结构,但是它们都只考虑了顺序行为,可能会遇到用户兴趣漂移的困难。由于NARM不仅使用带有GRU单元的RNN对序列行为进行建模,而且使用注意机制来捕捉主要目的,这表明了建议中主要目的信息的重要性,因此NARM在基线中取得了最好的性能。这是合理的,因为当前会话项的一部分可能反映用户的主要目的并与下一项有关。
在我们提出的模型中,STAMP模型在两次实验中都获得了Yoochoose数据集上最高的P@20和MRR@20,并在Diginetica数据集上获得了相似的结果。STMO模型无法从当前会话中以前的点击中获取一般兴趣信息,因此每当遇到相同的最后一次点击时,它都会生成相同的推荐,尽管给出了不同的会话。在我们提出的模型中,该模型的性能最差,这并不奇怪,因为它不能利用一般兴趣信息。但是与传统的机器学习方法如item - knn和FPMC相比,STMO的性能有了明显的提高,这说明我们提出的模型框架具有学习有效的均匀项嵌入表示的能力。STMP作为STMO的扩展,只是使用平均池函数生成会话表示作为长期兴趣,并应用最后一次点击信息来捕获短期兴趣。它在所有三个实验中都优于STMO,与GRU4Rec+的性能相当,但略逊于NARM。正如预期的那样,考虑到会话上下文信息和最后一次点击信息都适合这个任务,因为STMP能够更好地为给定的会话提出基于会话的建议。与STMP相比,STAMP应用了item-level attention机制,在三个实验中分别对P@20和MRR@20分别提高了0.95%、1.25%、1.12%和1.04%、1.06%、2.04%。结果表明,生成的会话表示以这种方式比平均池功能,更有效的证实,并不是所有的物品在当前会话下建议,同样重要的是在生成和重要项目的一部分可以被提议的注意机制模型感兴趣的有用特性;最新的结果证明了STMAP方法的有效性。
4.6 比较STAMP和NARM
基于会话的推荐系统已经成为许多电子商务系统不可或缺的一部分,帮助用户从大量的库存中挑选出感兴趣的商品。事实上,一个电子商务网站总有超过105个项目,大多数用户只对查看真实世界推荐系统[6]的第一页上的推荐感兴趣。为了验证我们提出的性能邮票模型和最近的最先进的NARM模型在实际生产环境中,推荐系统可以只显示几个项目,相关的项目应该在推荐列表中的前几项[12]。因此,为了模拟实际情况,我们分别用P@5、MRR@5、P@10和MRR@10来评价推荐质量。结果总结在表3中,并认为实验结果可能在一定程度上反映了它们在实际生产环境中的性能。我们可以观察到,STAMP在这个任务中表现良好,在模拟生产环境中,在更严格的规则下进行评估时,它的竞争力要比NARM强得多。我们的模型一直比NARM表现得更好,并且在三个实验中都显示出明显的优势,证明了同时考虑一般兴趣和短期兴趣的有效性,以及所学习项目嵌入的有效性。结果表明,从以上实验结果和4.5小节的主要结果可以看出,本文提出的STAMP倾向于给出更准确的建议。
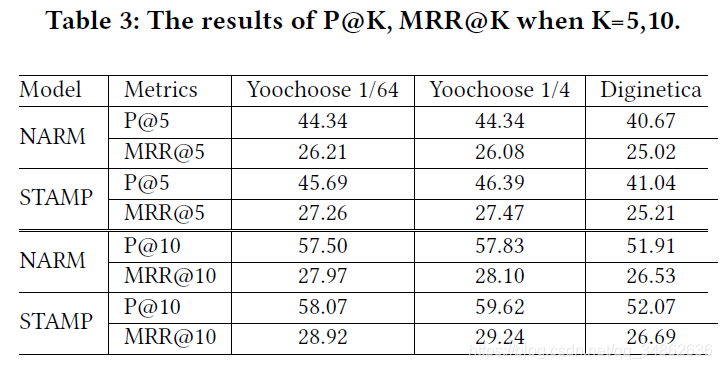
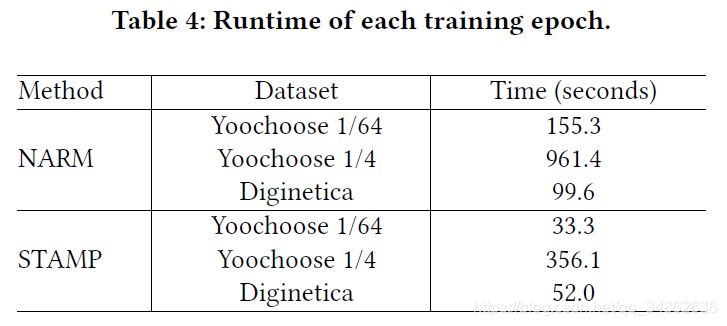
我们也记录了递归神经模型NARM的运行时间和所提出的STAMP方法。我们用相同的100维嵌入向量实现这两个模型,并在相同的GPU服务器上测试它们。表4给出了三个数据集上每个epoch的训练时间,说明STAMP比NARM更有效。我们认为这是因为NARM模型在每个GRU单元中包含许多复杂的操作,我们提出的模型更简单、更快,因为它引入了一个简化的神经模型,以节省处理顺序输入时的重复计算成本。上述结果表明,在实际应用中,由于基于会话的推荐系统总是包含大量的会话和项目,因此计算效率是关键,因此STAMP可能更适合于实际应用。
4.7 上一次点击的作用
在本节中,我们设计了一系列对比模型,验证了在会话上下文的基础上应用最后一次点击信息进行基于会话的推荐的有效性:
- STMP-:在STMP的基础上,不使用最后一次点击项嵌入三线性层。
- STMP:本文提出的STMP模型。
- STAMP-:在STAMP的基础上,不使用最后一次点击的item嵌入到三线层。
- STAMP:本文提出的STAMP模型。
表5中的数值结果表明,最后一次点击与会话上下文向量相结合的所有模型的性能都比没有点击的模型要好。结果证明,使用最后一次点击对特定会话的推荐有积极作用。我们的模型是基于同时捕捉长期和短期再次点击,提高最后点击信息,我们认为这是有利的在handlinglong会话期间用户的再次点击可能会改变长期浏览和用户的下一个动作可能更最后点击相关,反映了短期兴趣。为了验证上次点击的效果,我们研究了不同会话长度的P@20, Yoochoose 1/64数据集的结果如图3所示。

我们首先给出了改变STMP、STAMP和NARM会话长度的实验结果,如图3(a)所示。我们可以观察到,当会话长度大于20时,NARM的性能与STMP和STAMP相比迅速下降。这表明短期兴趣优先模型在处理长会话时可能比NARM更强大。另一方面,在图3(b)中,我们发现STMP和STAMP在长度为1到30之间时的P@20结果明显高于各自对应的模型,而没有分别将最后一次点击输入到三线性层。原因是,在最后一次点击或会话表示中捕获当前兴趣后,STMP和STAMP可以更好地为下一次点击推荐建立用户兴趣模型。对于较长的会话长度,STMP-和STMP之间以及STAMP-和STAMP之间的性能差距会变得更大。这证明,虽然从会议内容中获取一般兴趣很重要,但明确利用临时兴趣可以提高建议的质量。此外,STAMP-优于STMP-这是由STAMP中的注意机制捕获的混合兴趣导致的,而STMP只考虑一般兴趣;这说明了基于会话的推荐任务中最后一次点击信息的重要性。
4.8 所提出模型的比较
为了进一步验证不同模型的有效性和有效性,这些模型包括仅从最后一次点击中获取用户兴趣的模型、将最后一次点击与会话上下文结合的模型和最后应用注意机制的模型;我们通过对不同会话长度的比较研究来比较这些模型,以展示它们在不同情况下的性能和优势。为了达到这个目的,我们将会话分为两组:“短”表示会话的长度为5个事件或更少,而“长”表示具有5个事件以上的会话,其中5几乎是所有原始数据集中会话的平均总长度。Yoochoose和Diginetica的测试数据集中,短组会话占70.10%和76.40%,长组会话占29.90%和23.60%。对于每种方法,我们计算每个数据集上每个长度组的P@20和MRR@20的结果。Yoochoose和Diginetica的实验结果分别如图4 (a)和(b)所示。
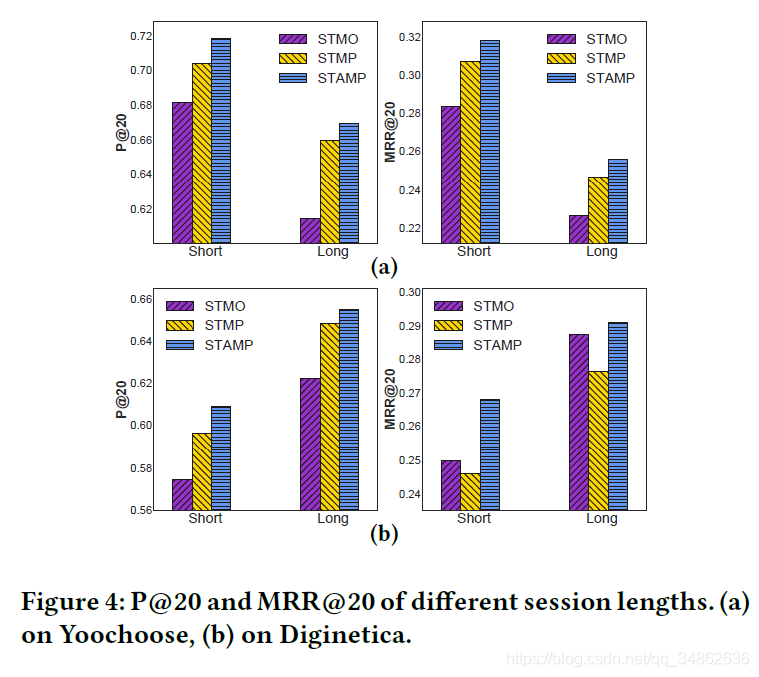
图4 (a)显示了Yoochoose的结果。我们可以看到,与短组相比,长组中所有方法的P@20和MRR@20的结果都更低,这突出了在此数据集上针对长会话提出基于会话的建议的挑战。我们怀疑这可能是因为难以捕获用户的兴趣漂移随着会话增长的长度。除了STMP和邮票比STMO两组和利润率变得更广泛的会话长度增加,这意味着一个模型考虑两将军和当前兴趣可能更强大的处理长会议,相比只有最后点击信息申请建议。这证实了我们的直觉,即会话上下文和最后一次点击信息可以同时有效地用于了解用户兴趣并预测基于会话的推荐中的下一个选择项。
图4 (b)显示了Diginetica上的结果。STMO具有比STMP更好的MRR@20结果,并且随着会话长度的增加,这个差距从0.38%增长到1.11%。这可能表明STMP的平均聚集有其不利之处,会影响推荐中正确条目的排名,STMO的结果也可能意味着短期兴趣对准确推荐的有效性。总的来说,STAMP仍然是性能最好的模型,它也强调了需要有效的会话表示来获得混合兴趣,这证明了所提出的注意机制的优点。
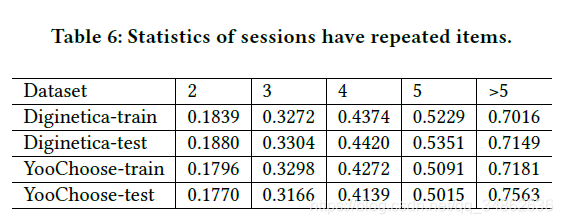
此外,图4显示了Yoochoose数据集上的短组和长组之间的趋势与Diginetica数据集上的趋势有很大的不同。为了解释这一现象,我们分析了这两个数据集,并显示了重复点击的会话的比例。在两个数据集中,就会话长度而言,点击至少出现两次)。从表6可以看出,与Diginetica数据集相比,在Yoochoose中重复点击的会话比例在短组中较小,在长组中较大。从这些结果中,我们发现在会话中的重复点击对推荐有影响,推荐与模型性能成反比。这可能是因为重复的点击可能会强调不重要的条目中的无效信息,从而使获取与下一个操作相关的用户兴趣变得困难。在STAMP中,我们使用短期注意优先级对用户兴趣进行建模,即注意机制从给定会话中选择重要的项目来建模用户兴趣。这两种方法都可以有效地减轻会话中重复点击的影响。相反,只有最后一次点击或平均点击信息用于其他方法,这些模型通常会丢失重要信息,并且无法克服与重复点击相关的问题。这证明了短期注意优先级的有效性和所提出的注意机制。
4.9 进一步研究
在本节中,我们反复从Yoochoose测试集中随机选择多组示例进行分析,它们始终显示相同的模式。图5展示了所提出的项目级注意机制的注意结果及其优点。
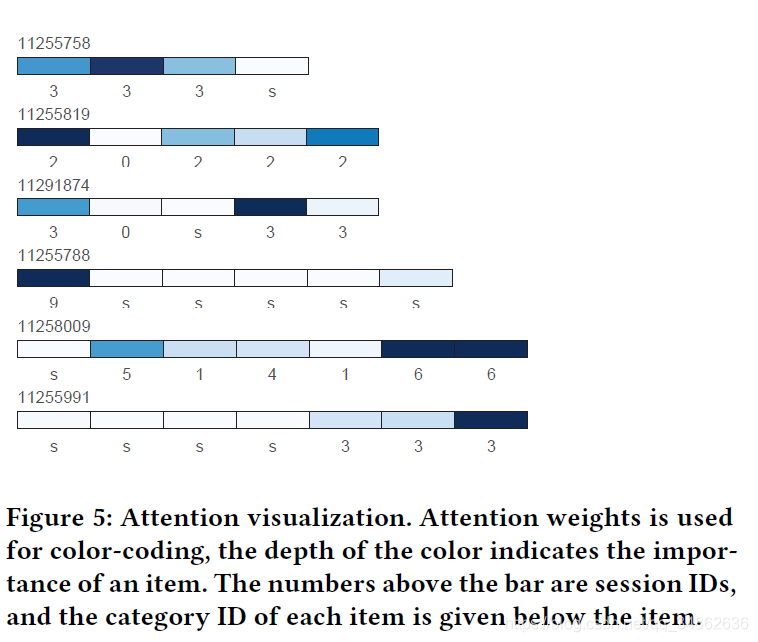
在图5中,颜色的深度表示一个项目的重要性,颜色越深的项目越重要。由于在缺乏具体项目信息的情况下,很难直接评价每个上下文项目与目标项目之间的关联,因此注意力机制的有效性可以部分地基于项目的类别来解释。例如,在会话11255991中,我们可以观察到与目标项目具有相同类别的项目比其他项目具有更大的注意权重。项目的类别可以在一定程度上反映用户的兴趣,与目标项目相同类别的项目的权重越高,可以部分证明注意力机制可以捕捉用户的兴趣,为下一步的行动服务。
我们的方法能够突出显示决定下一步操作的许多因素,如图5所示。首先,并不是所有的项目在决定下一个动作时都是重要的,我们的方法能够选择重要的项目并忽略无意的点击。其次,虽然一些重要的项目不在会话中当前操作的附近,但是我们的方法可以将它们标记为重要的,我们认为这表明我们的模型能够捕获用户的兴趣,从而响应最初的或主要的目的。第三,位置接近会话结束的项的权重通常更大,特别是较长的会话中的最后一个点击项。这证明了我们的直觉,即用户的预期操作可能更多地响应当前操作。结果表明,所提出的注意机制对特定会话中的兴趣漂移非常敏感,能够正确地捕捉当前的兴趣,这也是为什么STAMP能够超越其他主要关注长期兴趣的模型的原因之一。此外,结果表明,重要的项目可以捕获,而不管它们的位置(i。在一个特定的会议中(如会议的开始或结束)。会话11255788,11255819)。这证明了我们的猜想,我们提出的项目级注意机制可以从全局的角度捕获关键的项目,从而构建一般兴趣和当前兴趣的混合特征。因此,基于可视化结果,我们认为,所提出的项目级注意力机制通过计算注意力权重,抓住了预测会话中下一个动作的重要部分,使模型能够同时考虑长期兴趣和短期兴趣,并做出更准确和有效的建议。
5. 总结
在本文中,我们提出了一个基于会话推荐的短期注意/记忆优先级模型。研究结果表明:(1)用户的下一步行为主要受会话前缀的最后一次点击的影响,而我们的模型可以通过时态兴趣表示有效地利用这些信息。(2)所提出的注意机制能够有效地捕捉会话的长期和短期兴趣,实证结果表明,在注意机制的帮助下,我们的模型在所有数据集上都达到了最新的性能。
参考文献
[1] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. In Proceedings of ICLR’15. CoRR, Scottsdale, USA.
[2] Hidasi Balázs, Massimo Quadrana, Alexandros Karatzoglou, and Domonkos Tikk. 2016. Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations. In Proceedings of ACM RecSys’16. ACM, Boston, Massachusetts, USA, 241–248.
[3] Wanrong Gu, Shoubin Dong, and Zhizhao Zeng. 2014. Increasing recommended effectiveness with markov chains and purchase intervals. Neural Computing and Applications 25, 5 (2014), 1153–1162.
[4] Xiangnan He, Hanwang Zhang, Min-Yen Kan, and Tat-Seng Chua. 2016. Fast matrix factorization for online recommendation with implicit feedback. In Proceedings of ACM SIGIR’16. ACM, Pisa, Italy, 549–558.
[5] Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2015. Session-based recommendations with recurrent neural networks. In Proceedings of ICLR’15 (May 2 - 4). CoRR, San Juan, Puerto Rico.
[6] Liang Hu, Longbing Cao, Shoujin Wang, Guandong Xu, Jian Cao, and Zhiping Gu. 2017. Diversifying Personalized Recommendation with User-session Context. In Proceedings of IJCAI’17. IJCAI, Melbourne, Australia, 1858 – 1864.
[7] Dietmar Jannach, Lukas Lerche, and Michael Jugovac. 2015. Adaptation and Evaluation of Recommendations for Short-term Shopping Goals. In Proceedings of ACM RecSys’15 (September 16 - 20). ACM, Vienna, Austria, 211–218.
[8] Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization techniques for recommender systems. Computer 42, 8 (2009).
[9] Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep learning. Nature 521, 7553 (2015), 436–444.
[10] Jing Li, Pengjie Ren, Zhumin Chen, Zhaochun Ren, and Jun Ma. 2017. Neural Attentive Session-based Recommendation. In Proceedings of ACM CIKM’17. Singapore, Singapore, 1419–1428.
[11] Minh-Thang Luong, Hieu Pham, and Christopher D.Manning. 2015. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of EMNLP’15 (September 17 - 21). Association for Computational Linguistics, Lisbon, Portugal, 1412–1421.
[12] Massimo Quadrana, Alexandros Karatzoglou, Hidasi Balázs, and Paolo Cremonesi. 2017. Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks. In Proceedings of ACM RecSys’17. ACM, Como, Italy, 130–137.
[13] Steffen Rendle, Christoph Freudenthaler, and Lars Schmidt-Thieme. 2010. Factorizing personalized Markov chains for next-basket recommendation. In Proceedings of WWW’10. ACM, Raleigh, North Carolina, USA, 811–820.
[14] Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. 2001. Item-based collaborative filtering recommendation algorithms. In Proceedings of WWW’01. ACM, 285–295.
[15] Guy Shani, David Heckerman, and Ronen I Brafman. 2005. An MDP-based recommender system. JMLR 6, Sep (2005), 1265–1295.
[16] Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. 2014. Sequence to Sequence Learning with Neural Networks. In Proceedings of NIPS’14 (December 08 - 13). MIT Press, Montreal, Canada, 3104–3112.
[17] Yong Kiam Tan, Xinxing Xu, and Yong Liu. 2016. Improved Recurrent Neural Networks for Session-based Recommendations. In Proceedings of DLRS’16 (September 15 - 15). ACM, Boston, MA, USA, 17–22.
[18] Bartlomiej Twardowski. 2016. Modelling Contextual Information in Session- Aware Recommender Systems with Neural Networks. In Proceedings of ACM RecSys’16 (September 15 - 19). ACM, Boston, MA, USA, 273–276.
[19] Pengfei Wang, Jiafeng Guo, Yanyan Lan, Jun Xu, Shengxian Wan, and Xueqi Cheng. 2015. Learning Hierarchical Representation Model for NextBasket Recommendation. In Proceedings of ACM SIGIR’15. ACM, Santiago, Chile, 403–412.
[20] Feng Yu, Qiang Liu, Shu Wu, Liang Wang, and Tieniu Tan. 2016. A Dynamic Recurrent Model for Next Basket Recommendation. In Proceedings of ACM SIGIR’16 (July 17 - 21). ACM, Pisa, Italy, 729–732.
[21] Yu Zhu, Hao Li, Yikang Liao, BeidouWang, Ziyu Guan, Haifeng Liu, and Deng Cai. 2017. What to Do Next: Modeling User Behaviors by Time-LSTM. In Proceedings of IJCAI’17 (August 19 - 25). IJCAI, Melbourne, Australia, 3602–360.