说明
- 原文链接。
- 此处翻译不全,仅到其主要思想部分。
标题
- 题目:Dual Sequential Prediction Models Linking Sequential Recommendation and Information Dissemination
- 作者:
Qitian Wu1, Yirui Gao1, Xiaofeng Gao1?, Paul Weng2, Guihai Chen1
1Shanghai Key Laboratory of Scalable Computing and Systems,
Department of Computer Science and Engineering, Shanghai Jiao Tong University
2UM-SJTU Joint Institute, Shanghai Jiao Tong University
echo740@sjtu.edu.cn,gaoyirui98@gmail.com,gao-xf@cs.sjtu.edu.cn,paul.weng@sjtu.edu.cn,gchen@cs.sjtu.edu.cn
- 摘要
序列推荐(sequential recommendation)和信息传播(information dissemination)是序列信息检索的两大问题,这两个问题的共同目标是基于过去观察到的交互来预测未来的用户-项目交互。区别在于前者处理的是用户点击项目的历史记录,而后者关注的是项目“感染”用户的历史记录,本文从新的角度出发,提出了将这两种思维范式统一起来的双序列预测模型。一个以用户为中心的模型将用户的交互历史序列作为输入,捕获用户的动态状态,并根据用户过去的单击日志近似计算给定项目的下一次交互的条件概率。一个以项目为中心的模型利用项目的历史,捕获项目的动态状态,并基于项目过去的感染记录近似给定用户下一次交互的条件概率。为了利用这一双重信息,我们设计了一种新的训练机制,让两个模型互相进行博弈,利用对手的预测分数设计反馈信号来指导训练。结果表明,与单序列推荐或信息传播模型相比,对偶模型能更好地区分假阴性样本和真阴性样本。在四个真实数据集上的实验证明了该模型相对于某些强基线的优越性,以及两个模型之间双重训练机制的有效性。
- 介绍
记录用户和项之间的交互的序列数据在许多实际场景中是普遍存在的。序列信息检索中一个众所周知的研究问题是基于观测来预测未来的交互作用。在推荐系统中,平台可以根据用户的购买或浏览记录,尝试为每个用户推荐商品。在社交网络服务,一些用户生成的物品(如微博,图片或视频)可能会产生一个巨大的数量的股票或转发,和一个想要预测谁将影响下一个项目的历史的基础上被感染的用户(借用流行病学中的一个术语,将信息传播和病毒感染进行类比)。这两种情况分别对应两个经典的序列预测问题:序列推荐[9,16,29,40,46]和信息传播[28,30,34,45]。这两个问题具有双重结构,如图1所示。

已有的研究采取不同的观点,发展了不同的思维流派,分别处理这两个预测任务。一方面,对于序列推荐(图1.a),以前的工作倾向于根据用户u点击Iu的历史,模拟用户u点击(转发或共享取决于域)下一项i的条件概率,P(点击| (u, i), Iu)。例如,他们采用马尔科夫链[9,29]、时间感知SVD[23]、平移模型[13,14]、RNN模型[16,35,44]以及自注意力机制[20,46]来近似这个条件概率。另一方面,对于信息传播(图1.b),以往的研究一般是根据项目i的被感染用户Ui历史,考虑下一个用户u被项目i感染的条件概率,即P(点击| (u, i),Ui)。这些方法包括流行病模型[30,33]、随机点过程[2,32,45]、回归模型[25,26]以及递归神经网络[3,6]。而这两种思维方式有各自的理论基础,可以捕捉到用户行为(或项目影响力)的时间依赖性。他们假设一个项目的属性(或用户的兴趣)是静态的,因此忽略了对方的时间依赖性。事实上,一方面,对于序列推荐,当来自不同社区的用户点击时,项目的属性往往会动态变化,这可能会随着时间的推移而改变项目对用户的吸引力。另一方面,在信息传播过程中,用户在接触不同的物品时,其兴趣会发生变化,这就启发我们考虑不同的用户偏好。
然而,同时建模双边时间依赖关系并把分布P(点击| (u, i),Iu,Ui)作为目标会带来一系列挑战。首先,它引入了较高的计算代价,因为:(i)我们需要两个连续的单元来分别捕获两个历史序列中的时间动态,(ii)两个序列中的元素可能两两成对地形成O(n2)个隐状态。其次,由于目标函数的复杂性,模型更容易陷入局部最优或梯度消失。第三,由于我们只观察到积极的样本,我们需要从未观察到的相互作用中抽取足够的消极样本进行训练。这样的阴性样本可能包含大量的假阴性样本,这将导致错误的方向训练。
在本文中,我们以全新的视角提出了对偶序列预测模型(Dual Sequential Prediction Models, DEEMS),利用序列预测与信息传播问题的双重结构,巧妙地解决了上述局限性和挑战。它由双序列预测模型组成,可以由任何依赖于时间的单元(如RNN或自注意力模块)指定。一个模型以用户为中心,将用户点击项目的历史记录作为输入,并捕获用户兴趣转移时隐藏的动态状态。另一个模型以项目为中心,利用受感染用户的项目历史作为输入,对项目影响力变化中的动态模式进行编码。这两种模型的训练与之前的方法有很大的不同:我们让它们玩一个游戏,在这个游戏中,每个模型轮流尝试匹配另一个模型的预测。更具体地说,在以用户为中心的模型被训练的一轮中,一个用户u和一个项目i之间的观察交互被采样,该模型预测一个代表基于用户u的历史发生交互的概率的分数,即P(点击| (u, i), Iu)。将相同的样本输入到以项目为中心的模型,该模型提供分数P(点击| (u, i),Ui)。后一个预测分数被当作“标签”,用来计算两个分数之间的差异(称为“对冲损失”),作为反馈来训练以用户为中心的模型。然后,在下一轮中,他们交换角色,重复类似的过程来训练以项目为中心的模型。利用该方案,对偶模型相互补偿,信息交换达到一致。
认为同时捕获能够有效表达用户和项目状态的时间动态的特征,而基于对冲损失的训练使其能够跳出各自的局部最优。更重要的是,来自另一个模型的反馈可以帮助一个模型区分假阴性样本和真阴性样本,进一步提高了预测精度和模型的鲁棒性。为了验证该方法,我们对来自Amazon产品平台的四个真实数据集进行了广泛的实验,并与八个序列推荐和信息传播的强大基线进行了比较。结果表明,与现有方法相比,该方法在精度和AUC方面都有显著提高。一系列模型简化测试进一步证明了这种双重机制和训练方法的优越性。
我们的贡献总结如下:
?我们建议将顺序信息检索的两个学派——序列推荐和信息传播——统一起来,利用这两个学派的信息进行预测。
?我们设计了一种新的训练方法,让两个模型互相玩游戏,利用对手的输出来定义训练的对冲损失。这种机制有助于区分假阴性样本。
?我们在四个实际数据集上进行了广泛的实验,并与八个强大的竞争对手进行了比较。结果表明,对偶模型优于单一模型,在不同的预测条件下,预测精度都有较大的提高。
- 准备
用户-物品交互经典表示为矩阵R = { rui}M×N,其中M和N分别表示用户数量和物品数量。我们关注隐式反馈,它意味着矩阵R由0和1组成,即 rui = 1表示用户u点击了项目 i,否则rui = 0。然而,对于序列预测问题,每次交互都对应一个时间戳t,它记录交互发生的时间。因此,我们采用三元组(u, i, t)来表示一个用户-项目交互,而T = {(u, i, t)}表示所有观察到的交互。对于T和给定时间t,我们定义两个历史序列如下。
定义2.1(项目历史序列):对于用户u,我们将项目序列Iut= { i | (u, i, t′)∈T, t′< t } = { i1, i2, …}作为用户u的历史项目点击序列。
定义2.2(用户历史序列):对于项目i,我们将项目序列Uit= { i | (u, i, t′)∈T, t′< t } = { u1, u2, …}作为项目i的历史用户感染序列。
我们现在进一步地形式化序列预测问题。
定义2.3(序列预测问题):给定已观测到的用户项目交互记录T,序列预测问题在于预测用户u和项目i在某个时间t内未观测到的潜在交互。
上述一般性问题可以归结为两种具体形式:序列推荐问题和信息传播问题。对于序列推荐,我们依赖于每个用户的项目序列的历史Iut,目的是预测将要被点击的项目。在这种情况下,模型需要估计条件概率P(点击| (u, i), Iut)。对于信息传播,我们考虑每个项目的历史感染用户序列Uit,并试图预测与该项目交互的潜在用户。在这里,模型需要估计P(点击| (u, i),Uit)。事实上,这两个问题有着相同的目标,即预测用户和项目之间未来的交互,但采用不同的方面来处理预测。在这篇论文中,我们建议将这两种思想统一起来,并通过一个双人游戏来利用双重信息进行预测。
- 提出的模型
在本节中,我们提出了我们的模型(对偶序列预测模型),其框架如图2所示。我们首先介绍了利用顺序推荐和信息传播模型之间的双重结构的通用模型。在此基础上,详细阐述了模型中时序预测单元的技术指标。最后,我们分解模型的有效性,以帮助理解是如何工作的。
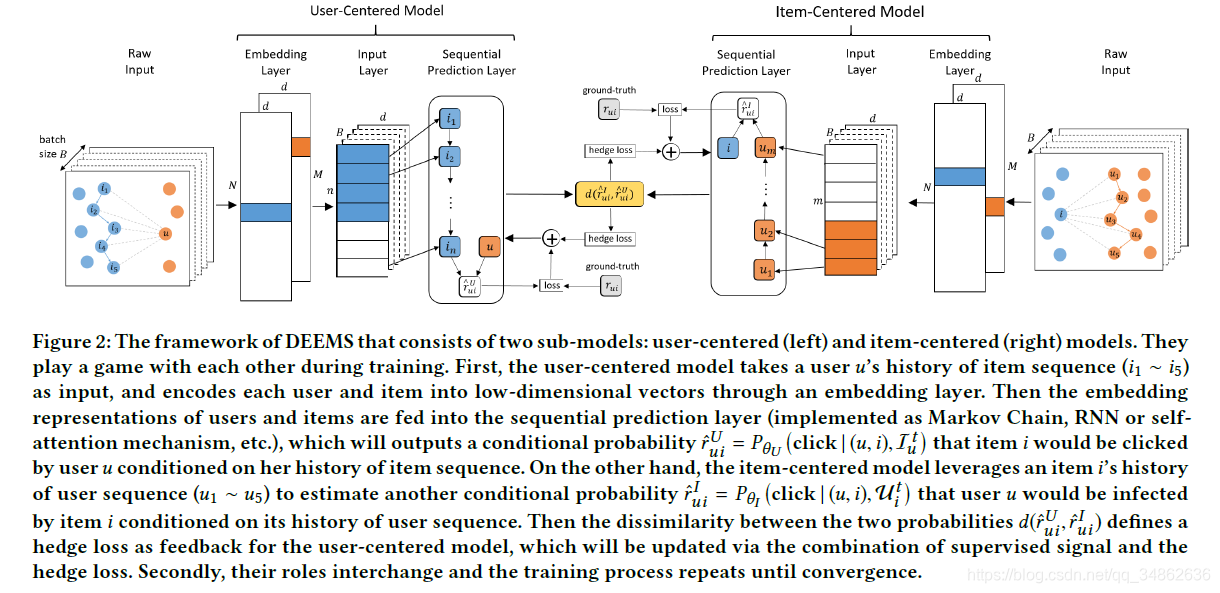
3.1对偶序列预测模型
从交互三重集合T中,我们可以得到每个(u, i, t)的历史项目序列Iut和历史用户序列Uit。如图2所示,DEEMS包含两个模型:以用户为中心的模型和以项目为中心的模型。以用户为中心的模型需要Iut作为输入,捕捉用户兴趣的动态模式,并估计条件概率P(点击| (u, i), Iut),项目i将被用户u点击,条件是用户u的历史项目序列。
相比之下,以项目为中心的序列模型需要Uit作为输入项,建模项目根据时间变化的影响力,近似条件概率P(点击| (u, i),Uit),用户u会被项目i感染,条件是项目i的历史用户序列。
嵌入层。为了更好地编码用户和项目的特性,我们表示每个用户(项目)作为一个低维向量。我们首先将用户u编码为独热列向量tu∈RM,如果用户u是第k个用户,对于k∈[M](表示[M] ={1,…,M}),其中只有第k个值为1,其他值为0。类似地,项目i被编码成一个独热列向量ei∈RN。对于用户,我们定义P∈Rd×M,其中d为嵌入维数,pu = Ptu表示用户u的嵌入向量,反映用户的静态偏好和兴趣。同样,对于项目,我们定义矩阵 Q∈Rd×N, qi = Qei表示项目i的嵌入向量,表示项目的静态属性和影响。其中以用户为中心的模型和以项目为中心的模型是两个自包含的模型,因此我们采用了独立的嵌入参数。具体来说,我们使用PU和QU (PI和QI)为嵌入参数,以用户(项目)为中心,并将相应的嵌入向量表示为pUu和qUi (pIu和qIi)。嵌入参数与后续序列预测层一起学习,实现端到端训练。
序列预测层。接下来,分别通过两个模型中的序列预测层获取用户状态和项目状态的时序相关性。该模型以用户为中心,将项目序列的历史Iut作为输入,输出一个隐藏的向量stu,反映用户的动态兴趣。具体地说,我们有
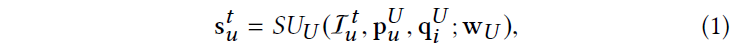
其中 SUU (·;wU ) 代表一个序列单元(包括马尔可夫链、 RNN 或 自注意力模型等) ,参数为wU . 相似的,以项目为中心的模型将用户历史序列Uit作为输入,并计算lit来表示项目i影响力的动态特征。具体地说,我们有:
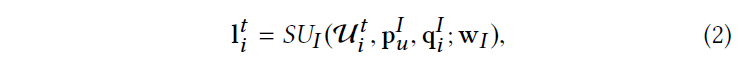
其中SUI (·;wI ) 代表一个序列单元参数为wU .
然后我们利用用户嵌入pUu (pIu),项目嵌入qUi (qIi)和用户动态兴趣stu (项目动态影响lit)预测交互概率。对于以用户为中心的模型,预测得分定义为:
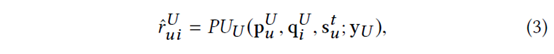
其中 PUU (·; yU ) 代表 一个一般的预测单元,参数为yU .同样,对于以项目为中心的模型,预测得分定义为:
![]()
其中 PUI (·; yI ) 代表 一个一般的预测单元,参数为yI .
我们将进一步讨论SUU(·;wU)、SUI(·;wI)、PUU(·; yU ), 和PUI (·; yI )在3.2节中。为了保持符号简洁,我们使用θU,θI分别表示在以用户为中心和以项目为中心模型的所有参数, θU = [PU ,QU ,wU ,yU ], θI = [PI ,QI ,wI ,yI ].。
输出层。用户u与项目i交互的最终预测概率为平均得分,即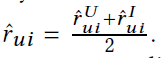
Loss 和训练。首先,我们希望输出预测分数![]() 和
和![]() 可以分别接近于真实的条件概率
可以分别接近于真实的条件概率![]() 和
和![]() 。交叉熵损失可以用来衡量预测分数
。交叉熵损失可以用来衡量预测分数![]()
![]() 和真实标签
和真实标签![]() 的差异。
的差异。
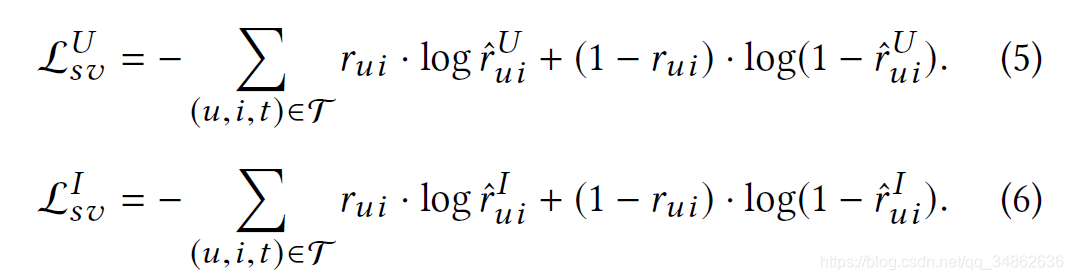
这里,![]() 和
和![]() 分别为以用户为中心和以项目为中心的监督 损失函数。
分别为以用户为中心和以项目为中心的监督 损失函数。
为了利用双重信息,使这两个顺序模型相互补偿,我们让他们玩双人游戏并且处理一个预测与另一个模型预测的差异(表示为![]() ),作为一个反馈。由于这两种预测都是概率性的,所以差异度量的一个自然候选项是交叉熵。数学上,以用户为中心的模式,
),作为一个反馈。由于这两种预测都是概率性的,所以差异度量的一个自然候选项是交叉熵。数学上,以用户为中心的模式, ![]() 和
和 ![]() 的差异为:
的差异为:

以项目为中心的模式, 对应的形式为:
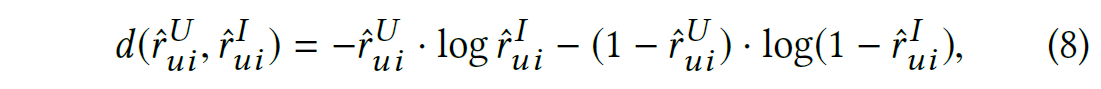
为了测量![]() 和
和![]() 的差异。我们称 (7)和(8) 为对偶模型给出的预测的对冲损失。有趣的是,还可以使用其他(可能是对称的)距离度量,如L1距离d(x,y) = |x?y |, L2距离d(x,y) = |x?y |2, logistic距离d(x,y) = 1 /(1+exp(?|x?y |)),高斯函数d(x,y) = exp(|x?y |2/c),等等。在实验部分,我们将讨论不同距离度量下的模型性能。
的差异。我们称 (7)和(8) 为对偶模型给出的预测的对冲损失。有趣的是,还可以使用其他(可能是对称的)距离度量,如L1距离d(x,y) = |x?y |, L2距离d(x,y) = |x?y |2, logistic距离d(x,y) = 1 /(1+exp(?|x?y |)),高斯函数d(x,y) = exp(|x?y |2/c),等等。在实验部分,我们将讨论不同距离度量下的模型性能。
对于一个正例的交互(u, i, t),我们选取K个未观察到的相互作用(uk, ik, tk) (k = 1,…,K)作为负样本。则对偶模型的对冲损失可表示为:
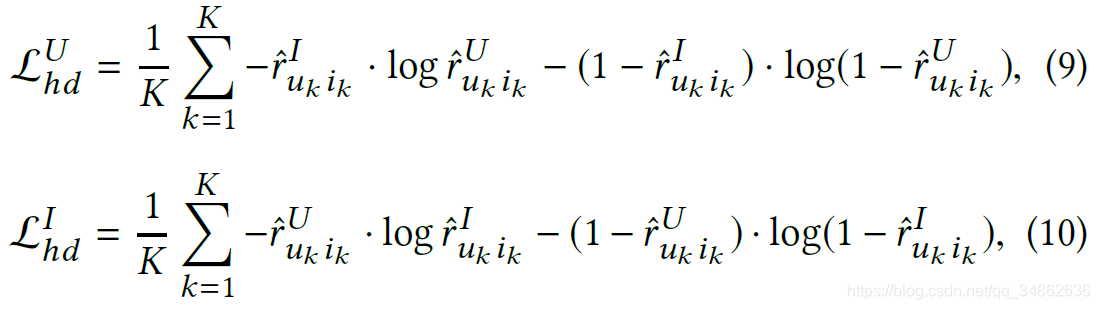
然后将监督损失和对冲损失与正则化项线性组合:
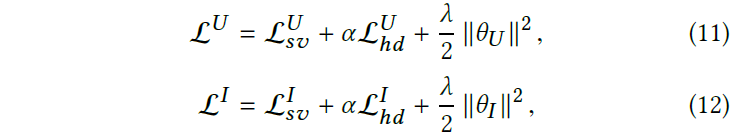
对偶序列模型的训练可以交替进行。首先,游戏一开始就用一个采样用户u并从用户u的未观测项目里采样生成一组项目集合ik (k = 1,···,K)。然后以用户为中心的模型计算预测分数![]() 并生成监督损失的梯度
并生成监督损失的梯度![]() 。然后,我们让以项目为中心的模型输出其预测分数
。然后,我们让以项目为中心的模型输出其预测分数![]() ,用作“标签”,计算对冲损失的梯度
,用作“标签”,计算对冲损失的梯度![]() 。最后,我们把它们加在一起,使用合成梯度值
。最后,我们把它们加在一起,使用合成梯度值![]() 以更新用户为中心的模式。第一轮游戏到此结束。在第二轮中,游戏将以一个抽样项目i开始,两个模型的角色将互换。这样的过程将重复,直到收敛或在一些时代之后。我们在Alg. 1中给出了算法(附录A)。
以更新用户为中心的模式。第一轮游戏到此结束。在第二轮中,游戏将以一个抽样项目i开始,两个模型的角色将互换。这样的过程将重复,直到收敛或在一些时代之后。我们在Alg. 1中给出了算法(附录A)。
