Python 正则表达式学习―-flags 编译标志位
关于正则表达式更多的内容,推荐https://blog.csdn.net/longerzone/article/details/24303161博客,更推荐书籍《python核心编码》,当然其他叙述正则表达式的书籍都可以,博主此处简介了正则表达式后,主要介绍re模块的flags 编译标志位 re.I、re,S和re.M
1、正则表达式简介
正则表达式(简称为regex)是一些由字符和特殊符号组成的字符串,他们描述了模式的重复或者表述多个字符,于是正则表达式能按照某种模式匹配一些列由相似特征的字符串。正则表达式本身是一种小型的、高度专业化的编程语言,而在python中,通过内嵌集成re模块,程序员可以直接调用来实现正则匹配。正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎执行。
2、正则表达式工作流程
正则表达式工作流程如下图1:
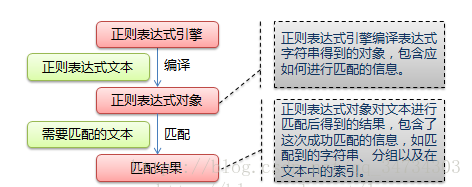
首先语言中的正则表达式引擎会将用户使用的正则表达式文本编程成正则表达式对象,然后依次拿出表达式对象和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,将会有相关语法的解决办法,在后期学习中慢慢摸索,都容易理解。
3、正则表达式re模块之flags 编译标志位
Python中flags 编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,对多行数据进行匹配等。常用的flags如下:
| 标志 | 含义 |
|---|---|
| re.S(DOTALL) | 匹配包括换行在内的所有字符 |
| re.I(IGNORECASE) | 使匹配对大小写不敏感 |
| re.L(LOCALE) | 做本地化识别(locale-aware)匹配,法语等 |
| re.M(MULTILINE) | 多行匹配,影响^和$ |
| re.X(VERBOSE) | 该标志通过给予更灵活的格式以便将正则表达式写得更易于理解 |
| re.U | 根据Unicode字符集解析字符,这个标志影响\w,\W,\b,\B |
(1)re.I 使匹配对大小写不敏感,如下:
# re.I 的学习,忽略大小写
S1 = 'CoN' #定义字符串i1
S2 = 'www.xiao.con' #定义字符串i2
#print(re.search('CoN','www.xiao.con').group()) #区分大小写的子组输出,报有错
print(re.search(S1,S2,re.I).group()) #不区分大小写的子组输出结果: 输出 con
备注:输出字符的大小以被匹配的字符串的大小写为主,如S2为’www.xiao.CON’,则输出的为:

(2)re.M 使用^ 和 $ 符号,实现多行多行匹配。如将所有行的末尾字符串输出得:
# re.M 的学习,将所有行的尾字母或者首部输出
S3 = '''I am girlyou are boywe are friends''' #定义初始字符串
print(re.findall(r"\w+$",S3,re.M)) #输出S3的每行最后一个字符串输出为:
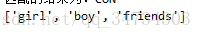
(3)re.S匹配包括换行在内的所有字符。如下:
s1 = '''jduedhhelloworld: 11630passgrthgdg''' #初始字符串,有换行所以用三引号
b = re.findall('hello(.*?)pass',s1) #findal返回字符串中某个正则表达式模式全部的非重复出现的情况,不包含换行,返回列表
c = re.findall('hello(.*?)pass',s1,re.S) #包含换行
print('b is',b) #输出B匹配的结果
print('c is',c) #输出C,包行匹配输出的结果结果输出对比为:

总结
flags 编译标志位就相当于一些特殊的指令,就如上面提的比如是否忽略大小写。并不是必须使用,不用的时候定义flags=0即可。上面短短三个小代码的学习还涉及了search(),findall() 方法,简单但是重要,博主会在以后的博客中会涉及,当然大家也可以通过推荐的网站书籍进行学习,查阅资料解决遇到的问题,对自己的成长会更有帮助。
源代码:
链接:https://pan.baidu.com/s/1giUdK9PgAcoBskn2sbj4yQ 密码:dxmh