原题链接
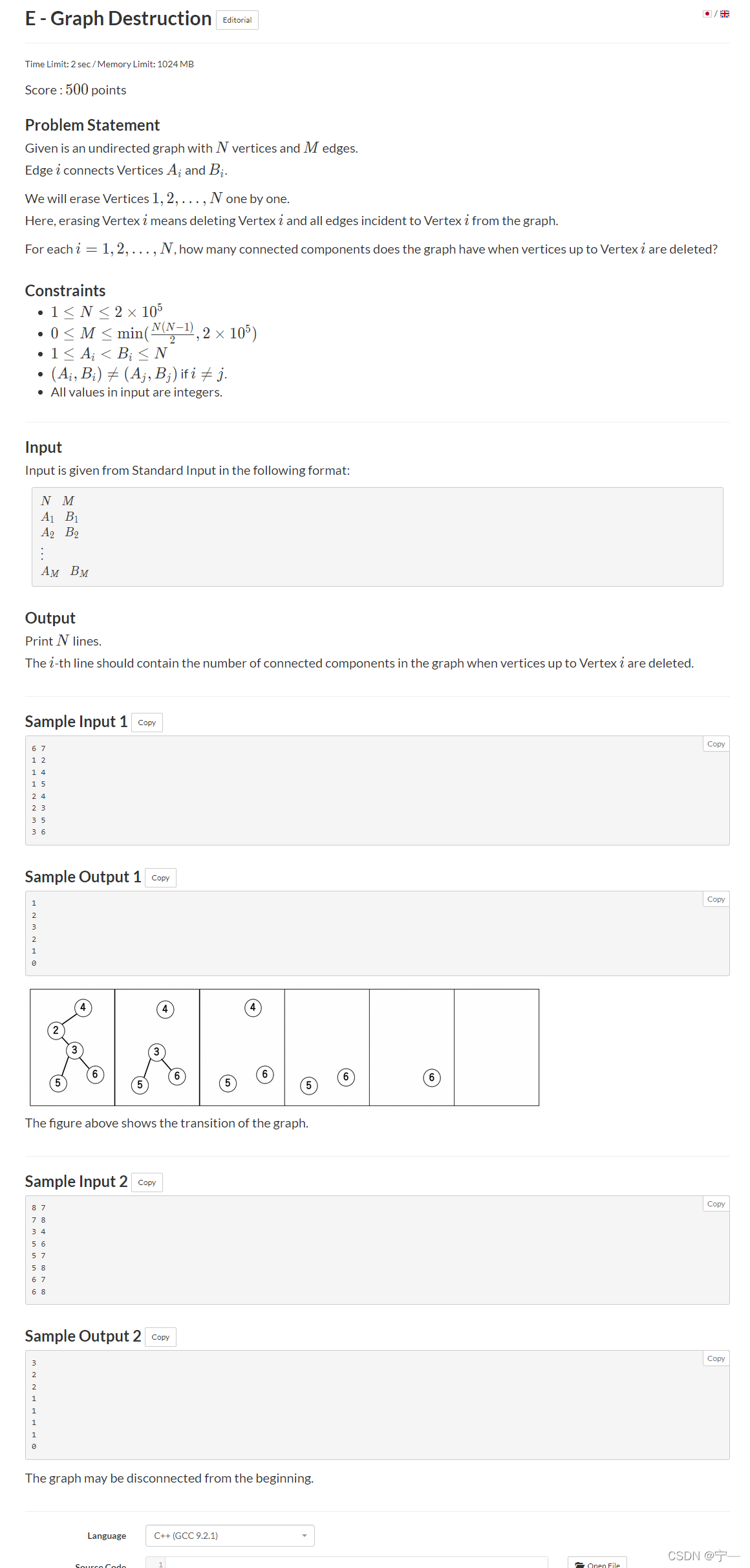
题意
给一个n个点,m条边的图,问依次删去点1 - n,剩余的部分可以组成几个连通块。
思路
自己的思路
一开始不会写,大概看了一眼题解后自己想的是存一个无向图,然后从后往前恢复点,用并查集,然后把比当前点大的且与当前点相连的点合并,合并完以后从最后一个点到当前这个点遍历一遍找有几个不同的部分,然后加入答案数组,可惜这种做法虽然能过大半的样例但是却超时了。
正解思路
也是用并查集,从后往前恢复点,每恢复一个点答案都+1(假设都不连通),然后去枚举所有和它相连的点,只要有一个点相连但它们并不在同一个集合里,那就说明这两个点(块)被合二为一了,那也就说明,连通块的个数要-1。最后得到的就是加上这个点后所有的连通块个数,也是删去上一个点后所剩下的块数
那么为什么要遍历的是所有和当前点相连的点呢,因为通过看数据范围可以发现a < b,所以说和当前点相连的一定都是比它大的点,所以遍历这个也不用去特判什么的。
所以说做题看清数据范围真的很重要,一开始自己写就还去判了大于当前点的点。
最后因为还有删去最后一个点的个数0,所以手动添加一个0.
代码
超时代码
#include<bits/stdc++.h>
using namespace std;int n, m;
const int N = 2e5 + 10;int p[N]; //存储每个点的祖宗节点// 返回x的祖宗节点
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);return p[x];
}vector<int> g[N];int main()
{
cin >> n >> m;for (int i = 1; i <= n; i ++ ) p[i] = i;for (int i = 1; i <= m; i ++ ){
int a, b; scanf("%d%d", &a, &b);g[a].push_back(b);}vector<int> ans;ans.push_back(0);for (int i = n; i >= 1; i -- ){
for (int j = 0; j < g[i].size(); j ++ ){
int v = g[i][j];if (v > i) p[find(v)] = find(i);}int f[N]={
0};int x = 0;for (int j = n; j >= i; j -- ){
if (f[find(j)] == 0) {
x ++;f[find(j)] = 1;}}ans.push_back(x);}for (int i = ans.size() - 2; i >= 0; i -- ){
printf("%d\n", ans[i]);}return 0;
}
正确代码
#include<bits/stdc++.h>
using namespace std;int n, m;
const int N = 2e5 + 10;int p[N]; //存储每个点的祖宗节点// 返回x的祖宗节点
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);return p[x];
}vector<int> g[N];int main()
{
cin >> n >> m;for (int i = 1; i <= n; i ++ ) p[i] = i;for (int i = 1; i <= m; i ++ ){
int a, b; scanf("%d%d", &a, &b);g[a].push_back(b);}vector<int> ans;ans.push_back(0);int res = 0; for (int i = n; i >= 1; i -- ){
res++;for (int j = 0; j < g[i].size(); j ++ ){
int v = g[i][j];if (p[find(v)] != find(i)) {
p[find(v)] = find(i);res --;}}ans.push_back(res);}for (int i = ans.size() - 2; i >= 0; i -- ){
printf("%d\n", ans[i]);}return 0;
}
总结(一个大发现)
看了官方题解,我发现atcoder还有自带的函数库了,比如说并查集也可以直接用函数写了,太强了太强了。
点击了解详情