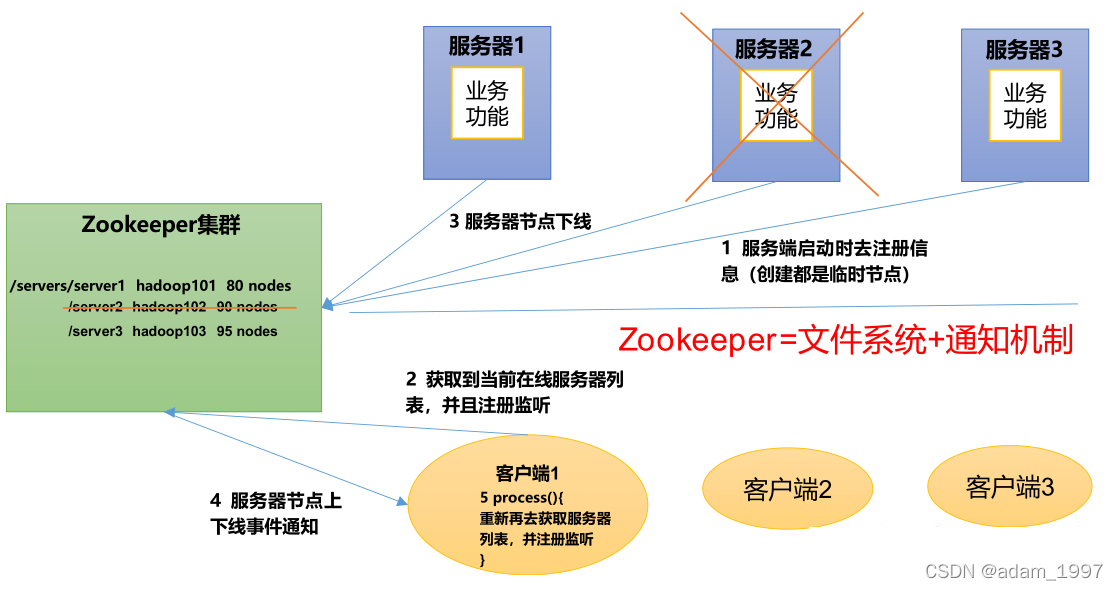
��һ�� �˽�zookeeper
1. ʲô��Zookeeper��
�ٷ��ĵ�����ô����zookeeper������һ���ֲ�ʽЭ����ܣ���Apache Hadoop ��һ������
Ŀ������Ҫ����������ֲ�ʽӦ���о���������һЩ���ݹ������⣬�磺ͳһ��������״̬ͬ
������Ⱥ�������ֲ�ʽӦ��������Ĺ����ȡ�
Zookeeper�����ģʽ�Ƕ������⣺��һ�����ڹ۲���ģʽ��Ƶķֲ�ʽ���������ܣ�������洢������Ҷ����ĵ����ݣ�Ȼ����ܹ۲��ߵ�ע�ᣬһ����Щ���ݵ�״̬�����仯��Zookeeper�ͽ�����֪ͨ�Ѿ���Zookeeper��ע�����Щ�۲�
��������Ӧ�ķ�Ӧ��
ZooKeeper = ���� Unix �ļ�ϵͳ + ֪ͨ���� + Znode �ڵ�
���ã�����ע��+�ֲ�ʽϵͳ��һ����֪ͨЭ��
������ַ��https://zookeeper.apache.org/
���ص�ַ��https://zookeeper.apache.org/releases.html#download
1.2 �ص�
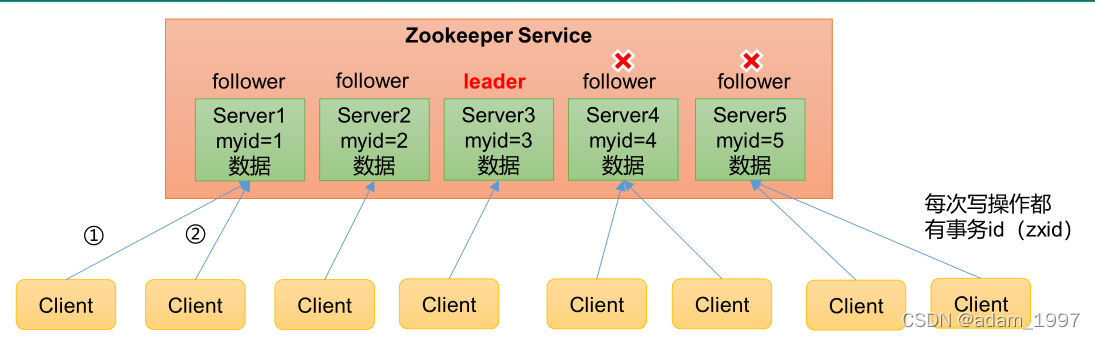
1��Zookeeper��һ���쵼�ߣ�Leader������������ߣ�Follower����ɵļ�Ⱥ��
2��Leader�������ͶƱ�ķ���;��飬����ϵͳ״̬��
3�� Follower���ڽ��տͻ�������ͻ��˷��ؽ������ѡ��Leader�����в���ͶƱ
4����Ⱥ��ֻҪ�� �������Ͻڵ��Zookeeper��Ⱥ����������������Zookeeper�ʺϰ�װ����̨��������
5��ȫ������һ�£�ÿ��Server����һ����ͬ�����ݸ�����Client�������ӵ��ĸ�Server�����ݶ���һ�µġ�
6����������˳��ִ�У�����ͬһ��Client�ĸ��������䷢��˳������ִ�С�
7�����ݸ���ԭ���ԣ�һ�����ݸ���Ҫô�ɹ���Ҫôʧ�ܡ�
8��ʵʱ�ԣ���һ��ʱ�䷶Χ�ڣ�Client�ܶ����������ݡ�
1.3 ���ݽṹ
ZooKeeper ����ģ�͵Ľṹ�� Unix �ļ�ϵͳ�����ƣ������Ͽ��Կ�����һ������ÿ���ڵ����һ�� ZNode��ÿһ�� ZNode Ĭ���ܹ��洢 1MB �����ݣ�ÿ�� ZNode ������ͨ����·��Ψһ��ʶ�������ܹ����ɵ����ӡ�ɾ��znode ��
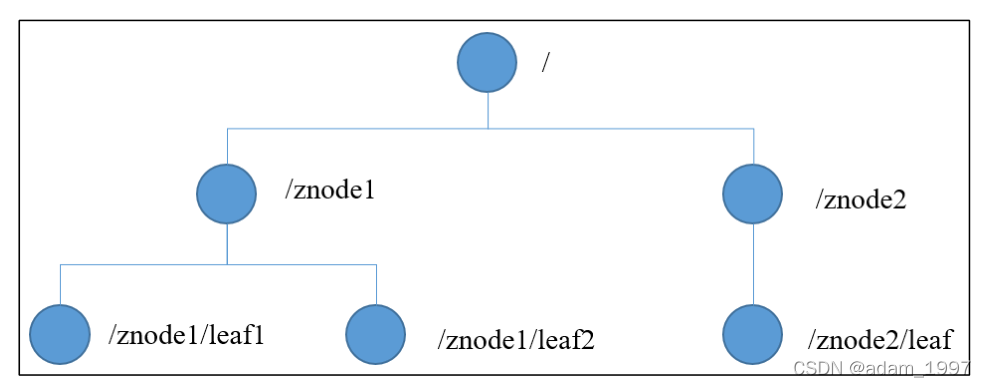
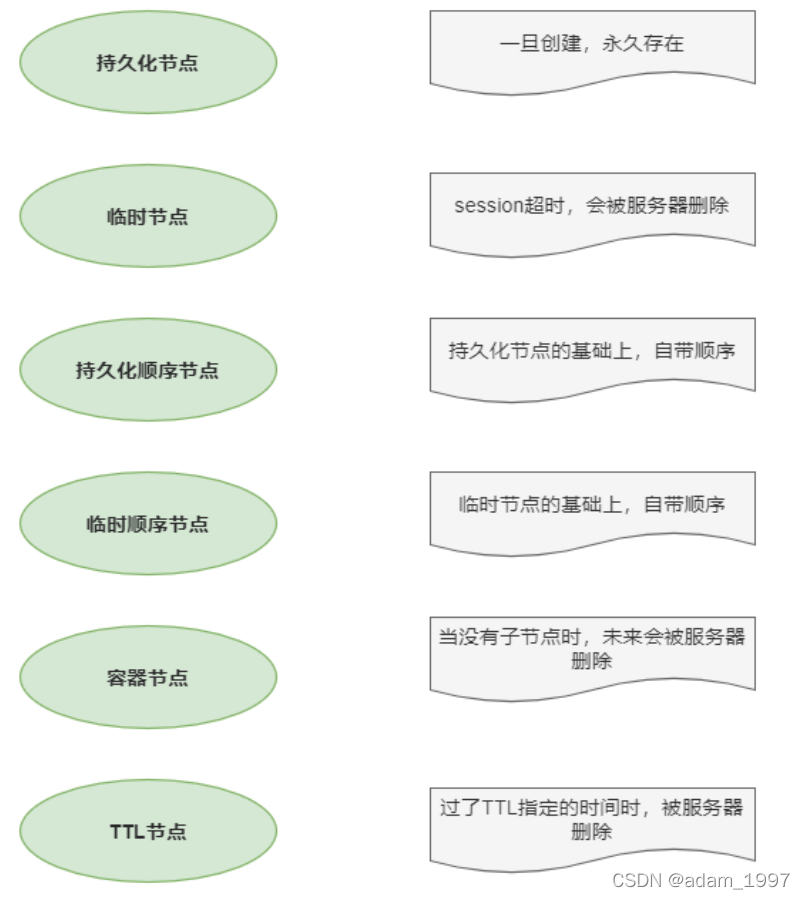
���������͵�znode��
1��PERSISTENT?�־û�Ŀ¼�ڵ�
�ͻ�����zookeeper�Ͽ����Ӻýڵ����ɴ��ڣ�ֻҪ���ֶ�ɾ���ýڵ㣬������Զ����
2�� PERSISTENT_SEQUENTIAL?�־û�˳����Ŀ¼�ڵ�
�ͻ�����zookeeper�Ͽ����Ӻýڵ����ɴ��ڣ�ֻ��Zookeeper���ýڵ����ƽ���˳����
3��EPHEMERAL?��ʱĿ¼�ڵ�
�ͻ�����zookeeper�Ͽ����Ӻýڵ㱻ɾ��
4��EPHEMERAL_SEQUENTIAL?��ʱ˳����Ŀ¼�ڵ�
�ͻ�����zookeeper�Ͽ����Ӻýڵ㱻ɾ����ֻ��Zookeeper���ýڵ����ƽ���˳����
5. Container �ڵ㣨3.5.3 �汾���������Container�ڵ�����û���ӽڵ㣬��Container�ڵ���δ���ᱻZookeeper�Զ����,��ʱ����Ĭ��60s ���һ�Σ�
6. TTL �ڵ�( Ĭ�Ͻ��ã�ֻ��ͨ��ϵͳ���� zookeeper.extendedTypesEnabled=true ���������ȶ�)
1.4������֪ͨ����
�ͻ���ע����������ĵ�����ڵ㣬����Ŀ¼�ڵ㼰�ݹ���Ŀ¼�ڵ�
- ���ע����Ƕ�ij���ڵ�ļ�����������ڵ㱻ɾ�������߱���ʱ����Ӧ�Ŀͻ��˽���֪ͨ
- ���ע����Ƕ�ij��Ŀ¼�ļ����������Ŀ¼���ӽڵ㱻�������������ӽڵ㱻ɾ������Ӧ�Ŀͻ��˽���֪ͨ
- ���ע����Ƕ�ij��Ŀ¼�ĵݹ��ӽڵ���м����������Ŀ¼����������ӽڵ���Ŀ¼�ṹ�ı仯�����ӽڵ㱻��������ɾ�������߸��ڵ������ݱ仯ʱ����Ӧ�Ŀͻ��˽���֪ͨ��
ע�⣺���е�֪ͨ����һ���Եģ��������ǶԽڵ㻹�Ƕ�Ŀ¼���еļ�����һ����������Ӧ�ļ��������Ƴ����ݹ��ӽڵ㣬�����Ƕ������ӽڵ�ģ����ԣ�ÿ���ӽڵ�������¼�ͬ��ֻ�ᱻ����һ�Ρ�
1.5 Ӧ�ó���
�ṩ�ķ��������ͳһ��������ͳһ���ù�����ͳһ��Ⱥ�������������ڵ㶯̬�����ߡ������ؾ���ȡ�
ͳһ�������� ���ڷֲ�ʽ�����£�������Ҫ��Ӧ��/�������ͳһ����������ʶ�����磺IP������ס������������ס��
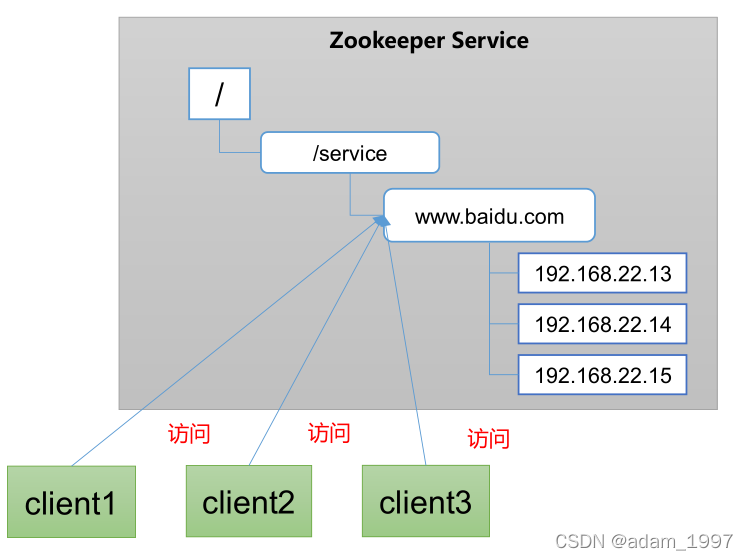
ͳһ���ù���
1���ֲ�ʽ�����£������ļ�ͬ���dz�������
��1��һ��Ҫ��һ����Ⱥ�У����нڵ��������Ϣ��һ�µģ����� Kafka ��Ⱥ��
��2���������ļ��ĺ�ϣ���ܹ�����ͬ���������ڵ��ϡ�
2�����ù����ɽ���ZooKeeperʵ�֡�
��1���ɽ�������Ϣд��ZooKeeper�ϵ�һ��Znode��
��2�������ͻ��˷������������Znode��
��3��һ��Znode�е����ݱ��ģ�ZooKeeper��֪ͨ�����ͻ��˷�������

ͳһ��Ⱥ����
1���ֲ�ʽ�����У�ʵʱ����ÿ���ڵ��״̬�DZ�Ҫ�ġ�
��1���ɸ��ݽڵ�ʵʱ״̬����һЩ������
2��ZooKeeper����ʵ��ʵʱ��ؽڵ�״̬�仯
��1���ɽ��ڵ���Ϣд��ZooKeeper�ϵ�һ��ZNode��
��2���������ZNode�ɻ�ȡ����ʵʱ״̬�仯
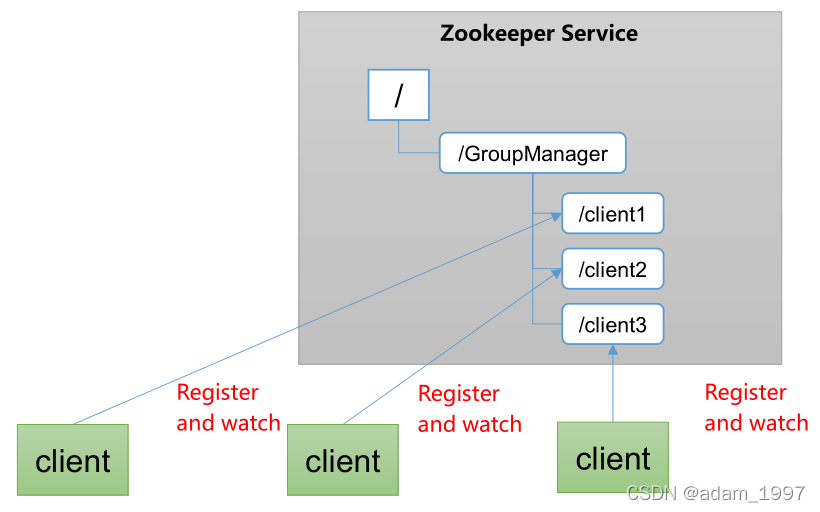
����̬������
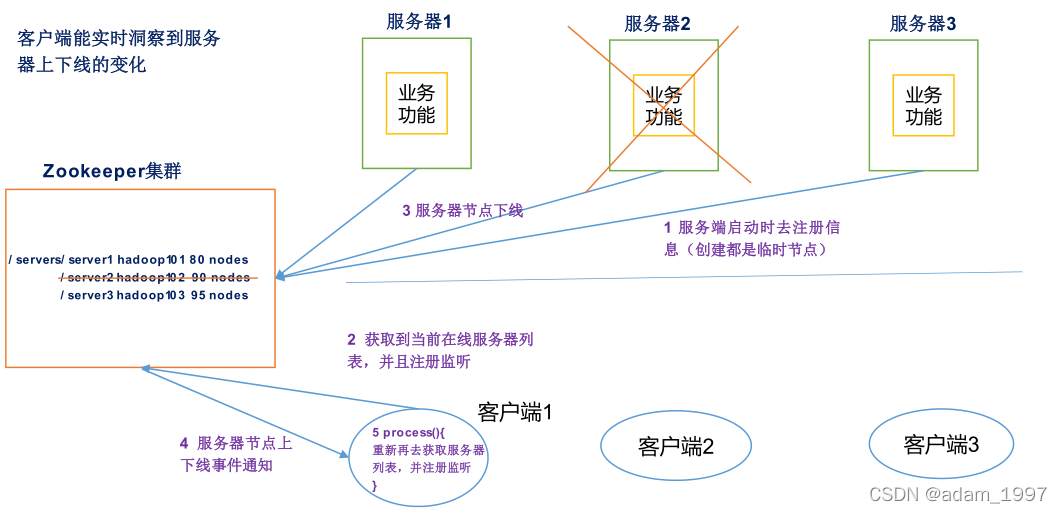
�����ؾ���
��Zookeeper�м�¼ÿ̨�������ķ��������÷��������ٵķ�����ȥ�������µĿͻ�������
�ڶ��� zookeeperʵս
1�����ذ�װ
step 1 ��װjdk ����java���� �C ʡ�ԣ��ٶ�һ���
step 2 ���أ���ѹzookeeper
wget https://mirror.bit.edu.cn/apache/zookeeper/zookeeper�\3.5.7/apache�\zookeeper�\3.5.7�\bin.tar.gztar �\zxvf apache�\zookeeper�\3.5.7�\bin.tar.gzcd apache�\zookeeper�\3.5.7�\bin
step 3 �������ļ� zoo_sample.cfg ��Ϊ zoo.cfg��
�� dataDir ·�������ڰ�װĿ¼�´�����Ŀ¼
cp zoo_sample.cfg zoo.cfgdataDir=/opt/module/zookeeper-3.5.7/zkData[atguigu@hadoop102 zookeeper-3.5.7]$ mkdir zkData
step 4 ����zookeeper
��1������ Zookeeper
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
��2���鿴�����Ƿ�����
[atguigu@hadoop102 zookeeper-3.5.7]$ jps
4020 Jps
4001 QuorumPeerMain
��3���鿴״̬
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: standalone
��4�������ͻ���
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh
��5���˳��ͻ��ˣ�
[zk: localhost:2181(CONNECTED) 0] quit
��6��ֹͣ Zookeeper
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh stop
�����ļ����
tickTime��ͨ��������,ZooKeeper����������ʱ�䣬��λ����
ZooKeeperʹ�õĻ���ʱ�䣬������֮���ͻ����������֮��ά��������ʱ������Ҳ����ÿ��tickTimeʱ��ͻᷢ��һ��������ʱ�䵥λΪ���롣
�����������ƣ�����������С��session��ʱʱ��Ϊ��������ʱ��(session����С��ʱʱ����2*tickTime)��
initLimit��LF��ʼͨ��ʱ��
��Ⱥ�е�Follower�����߷�����(F)��Leader�쵼�߷�����(L)֮���ʼ����ʱ�����̵������������tickTime����������
ͶƱѡ����Leader�ij�ʼ��ʱ�䣬Follower�����������У����Leaderͬ�������������ݣ�Ȼ��ȷ���Լ��ܹ�����������ʼ״̬��
Leader����Follower��initLimitʱ����������������
syncLimit��LFͬ��ͨ��ʱ��
��Ⱥ��Leader��Follower֮��������Ӧʱ�䵥λ��������Ӧ����syncLimit * tickTime��Leader��ΪFollwer�������ӷ������б���ɾ��Follwer��
�����й����У�Leader������ZooKeeper��Ⱥ�����л�������ͨ�ţ�����ͨ��һЩ���������ƣ����������Ĵ��״̬��
���L������������syncLimit֮��û�д�F���յ���Ӧ����ô����Ϊ���F�Ѿ��������ˡ�
dataDir�������ļ�Ŀ¼+���ݳ־û�·��
�����ڴ����ݿ������Ϣ��λ�ã����û������˵�������µ�������־Ҳ���浽���ݿ⡣
clientPort=2181���ͻ������Ӷ˿�
2����Ⱥ��װ
step1 - step3 �뱾�ذ�װģʽ��ͬ����/opt/module/zookeeper-3.5.7/zkData Ŀ¼�´���һ�� myid ���ļ������ļ��������� server ��Ӧ�ı�ţ�ע�⣺���²�Ҫ�п��У����Ҳ�Ҫ�пո�
[atguigu@hadoop102 zkData]$ vi myid
2
# ÿ̨��������myid ��һ��
step4 ��zoo.cfg �����ļ���������������
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
# hadoop102-hadoop104 ��Ҫ��host �ļ�
step5 �������úõ� zookeeper ������������
[atguigu@hadoop102 module ]$ xsync zookeeper-3.5.7
# xsync Ϊ�Լ���д��ͬ���ű�
���ֱ��� hadoop103��hadoop104 ���� myid �ļ�������Ϊ 3��4
�������
server.A=B:C:D��
A ��һ�����֣���ʾ����ǵڼ��ŷ�������
��Ⱥģʽ������һ���ļ� myid������ļ��� dataDir Ŀ¼�£�����ļ�������һ�����ݾ��� A ��ֵ��Zookeeper ����ʱ��ȡ���ļ����õ������������ zoo.cfg �����������Ϣ�ȽϴӶ��жϵ������ĸ� server��
B ������������ĵ�ַ��
C ����������� Follower �뼯Ⱥ�е� Leader ������������Ϣ�Ķ˿ڣ�
D ����һ��Ⱥ�е� Leader ���������ˣ���Ҫһ���˿������½���ѡ�٣�ѡ��һ���µ�Leader��������˿ھ�������ִ��ѡ��ʱ�������ͨ�ŵĶ˿ڡ�
��Ⱥ����
��1���ֱ����� Zookeeper
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
[atguigu@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start
[atguigu@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start
��2���鿴״̬
[atguigu@hadoop102 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: follower
[atguigu@hadoop103 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: leader
[atguigu@hadoop104 zookeeper-3.4.5]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: follower
3 �������zookeeper
| �������� | �������� |
|---|---|
| help | ��ʾ�������� |
| ls path | ʹ��ls ����鿴��ǰznode ���ӽڵ� ���ɼ����� -w �����ӽڵ�仯 -s ���Ӵμ���Ϣ |
| create | ��ͨ���� -s �������� -e ��ʱ��������ʱ����ʧ�� |
| get path | ��ȡ�ڵ��ֵ���ɼ�����-w �����ӽڵ�仯 -s ���Ӵμ���Ϣ |
| set | ���ýڵ�ľ���ֵ |
| stat | �鿴�ڵ�״̬ |
| delete | ɾ���ڵ� |
| deleteall | �ݹ�ɾ���ڵ� |
| rmr | rmr��������ڴ���delete���rmr��һ���ݹ�ɾ������������ָ���ڵ�ӵ���ӽڵ�ʱ��rmr���������ɾ���ӽڵ㡣 |
1�� �� �����ͻ���
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh -server
hadoop102:2181
2�� �� ��ʾ���в�������
[zk: hadoop102:2181(CONNECTED) 1] help
�鿴��ǰznode �ڵ�������������
1�� �� �鿴��ǰznode ��������������
[zk: hadoop102:2181(CONNECTED) 0] ls /
[zookeeper]
2�� �� �鿴��ǰ�ڵ���ϸ ����
[zk: hadoop102:2181(CONNECTED) 5] ls -s /
[zookeeper]cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = -1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
��1��czxid�������ڵ������id zxid
ÿ���� ZooKeeper ״̬�������һ�� ZooKeeper ���� ID������ ID �� ZooKeeper ���������ܵĴ���ÿ���Ķ���Ψһ�� zxid����� zxid1 С�� zxid2����ô zxid1 �� zxid2 ֮ǰ������
��2��ctime��znode �������ĺ��������� 1970 �꿪ʼ��
��3��mzxid��znode �����µ����� zxid
��4��mtime��znode ����ĵĺ��������� 1970 �꿪ʼ��
��5��pZxid��������ӻ�ɾ���ӽڵ������ID���ӽڵ��б������仯�Żᷢ���ı䣩
��6��cversion��znode���ӽڵ������汾��һ���ڵ���ӽڵ����ӡ�ɾ������Ӱ������汾��
��7��dataversion��znode ���ݱ仯��
��8��aclVersion��znode ���ʿ����б��ı仯��
��9��ephemeralOwner���������ʱ�ڵ㣬����� znode ӵ���ߵ� session id�����������ʱ�ڵ����� 0��
��10��dataLength��znode �����ݳ���
��11��numChildren��znode �ӽڵ�����
Ӧ��demo
����״̬�����еİ汾���в���������ʵ���ֹ����Ĺ���
���磺 �ͻ������Ȼ�ȡ�汾��Ϣ�� get -s /node-test
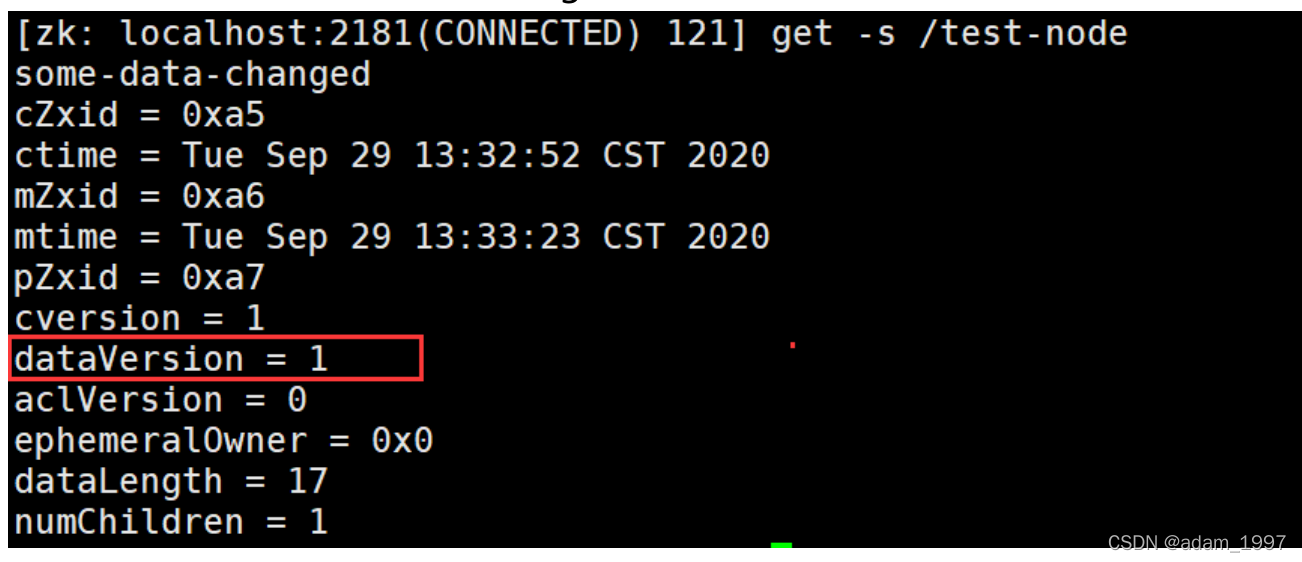
/test-node ��ǰ�����ݰ汾�� 1 �� ��ʱ�ͻ��� �� set ���������ݵ�ʱ����Ѱ汾�Ŵ���

�����ִ������ set����ǰ�� �����������ݣ�zookeeper ������汾�ţ� ���ʱ���������
��ǰ�İ汾��ȥ�ģ����ᵼ����ʧ�ܣ������´���

4 �ڵ����� ���־�/ ����/ �����/ ����ţ�
�־ã�Persistent�����ͻ��˺ͷ������˶Ͽ����Ӻ����Ľڵ㲻ɾ��
���ݣ�Ephemeral�����ͻ��˺ͷ������˶Ͽ����Ӻ����Ľڵ��Լ�ɾ��
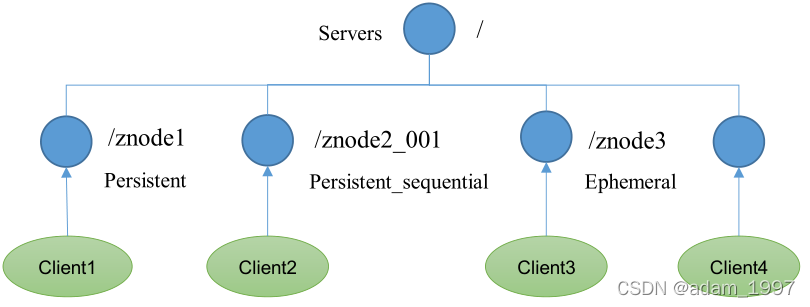
��1���־û�Ŀ¼�ڵ�
�ͻ�����Zookeeper�Ͽ����Ӻýڵ����ɴ���
��2���־û�˳����Ŀ¼�ڵ�
�ͻ�����Zookeeper�Ͽ����Ӻýڵ����ɴ��ڣ�ֻ��Zookeeper���ýڵ����ƽ���˳����
��3����ʱĿ¼�ڵ�
�ͻ�����Zookeeper�Ͽ����Ӻýڵ㱻ɾ��
��4����ʱ˳����Ŀ¼�ڵ�
�ͻ�����Zookeeper �Ͽ����Ӻýڵ㱻ɾ�� ��ֻ��Zookeeper���ýڵ����ƽ���˳���š�
˵��������znodeʱ����˳���ʶ��znode���ƺ�ḽ��һ��ֵ��˳�����һ�����������ļ��������ɸ��ڵ�ά��
ע�⣺�ڷֲ�ʽϵͳ�У�˳��ſ��Ա�����Ϊ���е��¼�����ȫ�����������ͻ��˿���ͨ��˳����ƶ��¼���˳��
1 �� �ֱ�2 ����ͨ�ڵ� �����ýڵ� + ������ţ�
[zk: localhost:2181(CONNECTED) 3] create /sanguo "diaochan"
Created /sanguo
[zk: localhost:2181(CONNECTED) 4] create /sanguo/shuguo
"liubei"
Created /sanguo/shuguo
ע�⣺�����ڵ�ʱ��Ҫ��ֵ
2�� �� ��ýڵ��ֵ
[zk: localhost:2181(CONNECTED) 5] get -s /sanguo
diaochan
cZxid = 0x100000003
ctime = Wed Aug 29 00:03:23 CST 2018
mZxid = 0x100000003
mtime = Wed Aug 29 00:03:23 CST 2018
pZxid = 0x100000004
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 7
numChildren = 1[zk: localhost:2181(CONNECTED) 6] get -s /sanguo/shuguo
liubei
cZxid = 0x100000004
ctime = Wed Aug 29 00:04:35 CST 2018
mZxid = 0x100000004
mtime = Wed Aug 29 00:04:35 CST 2018
pZxid = 0x100000004
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 6
numChildren = 0
3�� �� ��������ŵĽڵ� �����ýڵ� + ����ţ�
��1���ȴ���һ����ͨ�ĸ��ڵ�/sanguo/weiguo
[zk: localhost:2181(CONNECTED) 1] create /sanguo/weiguo
"caocao"
Created /sanguo/weiguo
��2����������ŵĽڵ�
[zk: localhost:2181(CONNECTED) 2] create -s /sanguo/weiguo/zhangliao "zhangliao"
Created /sanguo/weiguo/zhangliao0000000000
[zk: localhost:2181(CONNECTED) 3] create -s /sanguo/weiguo/zhangliao "zhangliao"
Created /sanguo/weiguo/zhangliao0000000001
[zk: localhost:2181(CONNECTED) 4] create -s /sanguo/weiguo/xuchu "xuchu"
Created /sanguo/weiguo/xuchu0000000002
���ԭ��û����Žڵ㣬��Ŵ� 0 ��ʼ���ε��������ԭ�ڵ������� 2 ���ڵ㣬��������ʱ�� 2 ��ʼ���Դ����ơ�
4�� �� �������ݽڵ� �����ݽڵ� + ������� or ����ţ� ��
��1���������ݵIJ�����ŵĽڵ�
[zk: localhost:2181(CONNECTED) 7] create -e /sanguo/wuguo "zhouyu"
Created /sanguo/wuguo
��2���������ݵĴ���ŵĽڵ�
[zk: localhost:2181(CONNECTED) 2] create -e -s /sanguo/wuguo "zhouyu"
Created /sanguo/wuguo0000000001
��3���ڵ�ǰ�ͻ������ܲ鿴����
[zk: localhost:2181(CONNECTED) 3] ls /sanguo
[wuguo, wuguo0000000001, shuguo]
��4���˳���ǰ�ͻ���Ȼ���������ͻ���
[zk: localhost:2181(CONNECTED) 12] quit
[atguigu@hadoop104 zookeeper-3.5.7]$ bin/zkCli.sh
��5���ٴβ鿴��Ŀ¼�¶��ݽڵ��Ѿ�ɾ��
[zk: localhost:2181(CONNECTED) 0] ls /sanguo
[shuguo]
5�� �Ľڵ�����ֵ
[zk: localhost:2181(CONNECTED) 6] set /sanguo/weiguo "simayi"
6���ڵ�ɾ����鿴 ��
1�� �� ɾ���ڵ�
[zk: localhost:2181(CONNECTED) 4] delete /sanguo/jin
2�� �� �ݹ�ɾ���ڵ�
[zk: localhost:2181(CONNECTED) 15] deleteall /sanguo/shuguo
3�� �� �鿴�ڵ�״̬
[zk: localhost:2181(CONNECTED) 17] stat /sanguo
cZxid = 0x100000003
ctime = Wed Aug 29 00:03:23 CST 2018
mZxid = 0x100000011
mtime = Wed Aug 29 00:21:23 CST 2018
pZxid = 0x100000014
cversion = 9
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 4
numChildren = 1
5 ������ԭ��
�ͻ���ע����������ĵ�Ŀ¼�ڵ㣬��Ŀ¼�ڵ㷢���仯�����ݸı䡢�ڵ�ɾ������Ŀ¼�ڵ�����ɾ����ʱ��ZooKeeper ��֪ͨ�ͻ��ˡ��������Ʊ�֤ ZooKeeper ������κε����ݵ��κθı䶼�ܿ��ٵ���Ӧ�������˸ýڵ��Ӧ�ó���
1������ԭ�����
1������Ҫ��һ��main()�߳�
2����main�߳��д���Zookeeper�ͻ��ˣ���ʱ�ͻᴴ�������̣߳�һ��������������ͨ�ţ�connet����һ�����������listener����
3��ͨ��connect�߳̽�ע��ļ����¼�����Zookeeper��
4����Zookeeper��ע��������б��н�ע��ļ����¼����ӵ��б��С�
5��Zookeeper�����������ݻ�·���仯���ͻὫ�����Ϣ����listener�̡߳�
6��listener�߳��ڲ�������process()������

2�������ļ���
1�������ڵ����ݵı仯
get path [watch] // ע�������ͬʱ��ȡ����
2�������ӽڵ������ı仯
ls �\w /path �� �\R ���ִ�Сд��һ���ô�д
1�� �� �ڵ��ֵ�仯����
��1���� hadoop104 ������ע�����/sanguo �ڵ����ݱ仯
[zk: localhost:2181(CONNECTED) 26] get -w /sanguo
��2���� hadoop103 ��������/sanguo �ڵ������
[zk: localhost:2181(CONNECTED) 1] set /sanguo "xisi"
��3���۲� hadoop104 �����յ����ݱ仯�ļ���
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged
path:/sanguo
ע�⣺��hadoop103�ٶ����/sanguo��ֵ��hadoop104�ϲ������յ���������Ϊע��һ�Σ�ֻ�ܼ���һ�Ρ����ٴμ�������Ҫ�ٴ�ע�ᡣ
2�� �� �ڵ���ӽڵ�仯������·���仯��
��1���� hadoop104 ������ע�����/sanguo �ڵ���ӽڵ�仯
[zk: localhost:2181(CONNECTED) 1] ls -w /sanguo
[shuguo, weiguo]
��2���� hadoop103 ����/sanguo �ڵ��ϴ����ӽڵ�
[zk: localhost:2181(CONNECTED) 2] create /sanguo/jin "simayi"
Created /sanguo/jin
��3���۲� hadoop104 �����յ��ӽڵ�仯�ļ���
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged
path:/sanguo
ע�⣺�ڵ��·���仯��Ҳ��ע��һ�Σ���Чһ�Ρ�������Ч������Ҫ���ע�ᡣ
��Եݹ���Ŀ¼�ļ���
ls �\R �\w /path �� �\R ���ִ�Сд��һ���ô�д
���¶�/test �ڵ���еݹ����������ÿ��Ŀ¼�µ�Ŀ¼����Ҳ��һ���Եģ����һ����/test Ŀ¼�´����ڵ�ʱ�����������¼����ڶ�����û�У�ͬ������Ϊʱ�ݹ��Ŀ¼������������/test/sub0�½��нڵ㴴��ʱ�������¼��������ٴν�/test/sub0/subsub1�ڵ�ʱ��û�д����¼���
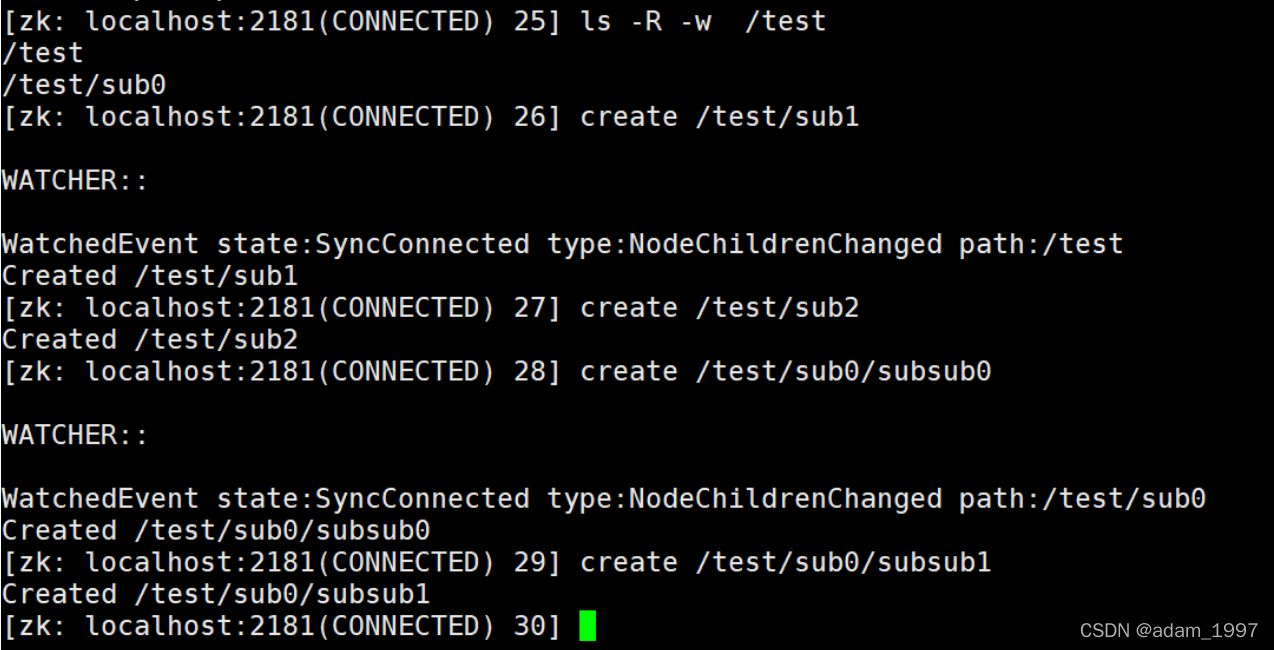
Zookeeper�¼����ͣ�
None: ���ӽ����¼�
NodeCreated�� �ڵ㴴��
NodeDeleted�� �ڵ�ɾ��
NodeDataChanged���ڵ����ݱ仯
NodeChildrenChanged���ӽڵ��б��仯
DataWatchRemoved���ڵ�������Ƴ�
ChildWatchRemoved���ӽڵ�������Ƴ�
7 Zookeeper �� ACL Ȩ����( Access Control List )
Zookeeper ��ACL Ȩ����,���Կ��ƽڵ�Ķ�д����,��֤���ݵİ�ȫ�ԣ�Zookeeper ACL Ȩ�����÷�Ϊ 3 ������ɣ��ֱ��ǣ�Ȩ��ģʽ��Scheme������Ȩ����ID����Ȩ����Ϣ��Permission�����������һ������ scheme:id:permission��ʽ�� ACL ������Ϣ��
�������Ǿ��忴һ���� 3 ���ִ���ʲô��˼��
Ȩ��ģʽ��Scheme��
�������� ZooKeeper ����������Ȩ����֤�ķ�ʽ��ZooKeeper ��Ȩ����֤��ʽ�����Ϊ�������ͣ�
һ���Ƿ�Χ��֤����ν�ķ�Χ��֤����˵ ZooKeeper �������һ�� IP ����һ�� IP ��ַ����ij��Ȩ�ޡ��������ǿ�����һ�� IP ��ַΪ��ip��192.168.0.110���Ļ����Է������ϵ�ij�����ݽڵ����д���Ȩ�ޡ�����Ҳ����ͨ����ip:192.168.0.1/24����һ�� IP ��ַ�Ļ�����Ȩ��
��һ��Ȩ��ģʽ���ǿ�����֤��Ҳ��������Ϊ�û�������ķ�ʽ���� ZooKeeper ��������֤��ʽ�� Digest ��֤���� Digest ������֤��ʽ�����ڿͻ��˴��͡�username:password��������ʽ��Ȩ�ޱ�ʾ����ZooKeeper ����˻������ ����ʹ�� SHA-1 �� BASE64 �㷨���м��ܣ��Ա�֤��ȫ�ԡ�
����һ��SuperȨ��ģʽ, Super������Ϊ��һ������� Digest ��֤������ Super Ȩ�Ŀͻ��˿��Զ� ZooKeeper �ϵ��������ݽڵ�������������
��Ȩ����ID��
��Ȩ�������˵����Ҫ��Ȩ����˭������Ӧ�� 4 �ֲ�ͬ��Ȩ��ģʽ��˵���������ѡ����� IP��ʽ��ʹ�õ���Ȩ���������һ�� IP ��ַ�� IP ��ַ�Σ������ʹ�� Digest �� Super ��ʽ�����Ӧ��һ���û���������� World ģʽ������Ȩϵͳ�����е��û���
Ȩ����Ϣ��Permission��
Ȩ����ָ���ǿ��������ݽڵ���ִ�еIJ������࣬������ʾ���� ZooKeeper ���Ѿ�����õ�
Ȩ���� 5 �֣�
���ݽڵ㣨c: create������Ȩ�ޣ�����Ȩ�Ķ�����������ݽڵ��´����ӽڵ㣻
���ݽڵ㣨w: wirte������Ȩ�ޣ�����Ȩ�Ķ�����Ը��¸����ݽڵ㣻
���ݽڵ㣨r: read����ȡȨ�ޣ�����Ȩ�Ķ�����Զ�ȡ�ýڵ�������Լ��ӽڵ���б���Ϣ��
���ݽڵ㣨d: delete��ɾ��Ȩ�ޣ�����Ȩ�Ķ������ɾ�������ݽڵ���ӽڵ㣻
���ݽڵ㣨a: admin��������Ȩ�ޣ�����Ȩ�Ķ�����ԶԸ����ݽڵ������ ACL Ȩ�����á�
���
getAcl����ȡij���ڵ��aclȨ����Ϣ
setAcl������ij���ڵ��aclȨ����Ϣ
addauth: ������֤��Ȩ��Ϣ���൱��ע���û���Ϣ��ע��ʱ�����������룬zk�������ĵ���ʽ�洢
����ͨ��ϵͳ����zookeeper.skipACL=yes�������ã�Ĭ����no,��������Ϊtrue, �����ù���echoACL�����ٽ���Ȩ���
������ȨID�����ַ�ʽ:
a.��������ID:
@Test
public void generateSuperDigest() throws NoSuchAlgorithmException {
String sId = DigestAuthenticationProvider.generateDigest("gj:test"); System.out.println(sId);// gj:X/NSthOB0fD/OT6iilJ55WJVado=}b.��xshell ������
echo �\n <user>:<password> | openssl dgst �\binary �\sha1 | openssl base64
����ACL�����ַ�ʽ
a:�ڵ㴴����ͬʱ����ACL
create [-s] [-e] [-c] path [data] [acl]
ag: create /zk�\node datatest digest:gj:X/NSthOB0fD/OT6iilJ55WJVado=:cdrwab:��setAcl ����
setAcl /zk�\node digest:gj:X/NSthOB0fD/OT6iilJ55WJVado=:cdrwa������Ȩ��Ϣ����ֱ�ӷ��ʣ�ֱ�ӷ��ʽ��������쳣
get /zk�\node
[zk: localhost:2181(CONNECTED) 23] get /zk-node
Insufficient permission : /zk-node
�쳣��Ϣ:
org.apache.zookeeper.KeeperException$NoAuthException: KeeperErrorCode = NoAuth
for /zk�\node����ǰ��Ҫ������Ȩ��Ϣaddauth digest gj:testget /zk�\nodedatatest
��һ����Ȩģʽ�� auth ������Ȩ
ʹ��֮ǰ��Ҫ�� addauth digest username:password ע���û���Ϣ����������ֱ����������Ȩ
�磺
1 addauth digest u100:p100
2 create /node�\1 node1data auth:u100:p100:cdwra
3 ����u100�û���Ȩ��Ϣ�ᱻzk���棬������Ϊ��ǰ����Ȩ�û�Ϊu100
4 get /node�\1
5 node1data
IP��Ȩģʽ��
setAcl /node�\ip ip:192.168.109.128:cdwra
create /node�\ip data ip:192.168.109.128:cdwra
���ָ��IP����ͨ�����ŷָ��� �� setAcl /node-ip ip:IP1:rw,ip:IP2:a
Super ��������Աģʽ��
����һ�������Digestģʽ�� ��Superģʽ�³�������Ա�û����Զ�Zookeeper�ϵĽڵ�����κεIJ�����
��Ҫ����������ͨ��JVM ϵͳ����������
DigestAuthenticationProvider���
Dzookeeper.DigestAuthenticationProvider.superDigest=super:base64encoded(SHA1(password))
������Բο�zookeeper��aclȨ����
8 ZooKeeper �ڴ����ݺͳ־û�
Zookeeper���ݵ���֯��ʽΪһ�������ļ�ϵͳ�����ݽṹ������Щ���ݶ��Ǵ洢���ڴ��еģ��������ǿ�����Ϊ��Zookeeper��һ�������ڴ��С�����ݿ⡣
�ڴ��е�����
public class DataTree {
private final ConcurrentHashMap<String, DataNode> nodes = new ConcurrentHashMap<String, DataNode>();private final WatchManager dataWatches = new WatchManager();private final WatchManager childWatches = new WatchManager();
DataNode ��Zookeeper�洢�ڵ����ݵ���С��λ
public class DataNode implements Record {
byte data[];Long acl;public StatPersisted stat;private Set<String> children = null;
9 ������־
���ÿһ�οͻ��˵����������Zookeeper���Ὣ���Ǽ�¼��������־�У���Ȼ��ZookeeperҲ�Ὣ���ݱ��Ӧ�õ��ڴ����ݿ��С����ǿ�����zookeeper���������ļ�zoo.cfg �������ڴ��е����ݳ־û�Ŀ¼��Ҳ����������־�Ĵ洢·�� dataLogDir. ���û������dataLogDir���DZ��, ������־���洢��dataDir �������Ŀ¼��zookeeper�ṩ�˸�ʽ�����߿��Խ������ݲ鿴������־���� org.apache.zookeeper.server.LogFormatter ��������ʾ��
java �\classpath .:slf4j�\api�\1.7.25.jar:zookeeper�\3.5.8.jar:zookeeper�\jute�\3.5.8.jar org.apache.zookeeper.server.LogFormatter /usr/local/zookeeper/apache�\zookeeper�\3.5.8�\bin/data/version�\2/log.1
�����ҷֱ��¼�˲���ʱ�䣬�ͻ��˻ỰID��CXID,ZXID,�������ͣ��ڵ�·�����ڵ����ݣ���#+ascii ���ʾ�����ڵ�汾��

Zookeeper����������־�ļ�������ʱ���Ƶ�����д���IO������������־�IJ�����д�����ᴥ���ײ����IOΪ�ļ������µĴ��̿飬������Seek����ˣ�Ϊ����������IO��Ч�ʣ�Zookeeper�ڴ���������־�ļ���ʱ��ͽ����ļ��ռ��Ԥ����- ���ڴ����ļ���ʱ�������ϵͳ����һ���һ��Ĵ��̿顣���Ԥ����Ĵ��̴�С����ͨ��ϵͳ���� zookeeper.preAllocSize �������á�
������־�ļ���Ϊ�� log.<��ʱ�������ID>��ӦΪ��־�ļ�ʱ˳��д��ģ���������������IDҲ��������������־�ļ��У���С������ID����־���˼�������һ��������־�ļ��Ĵ���
���ݿ���
���ݿ������ڼ�¼Zookeeper��������ijһʱ�̵�ȫ�����ݣ�������д�뵽ָ���Ĵ����ļ��С�����ͨ������snapCount����ÿ�������������������ɿ��գ����ݴ洢��dataDir ָ����Ŀ¼�У�����ͨ�����·�ʽ���в鿴�������ݣ� Ϊ�˱��⼯Ⱥ�����л�����ͬһʱ����п��գ�ʵ�ʵĿ�������ʱ��Ϊ�������ﵽ [snapCount/2 + �����(�������ΧΪ1 ~ snapCount/2 )] ����ʱ��
ʼ���գ�
java �\classpath .:slf4j�\api�\1.7.25.jar:zookeeper�\3.5.8.jar:zookeeper�\jute�\3.5.8.jar org.apache.zookeeper.server.SnapshotFormatter /usr/local/zookeeper/apache�\zookeeper�\3.5.8�\bin/data�\dir/version�\2/snapshot.0
����������־�ļ���Ϊ�� snapshot.<��ʱ�������ID>����־���˼�������һ��������־�ļ��Ĵ���
����������־��Ϊɶ��Ҫ�������ݡ�
����������ҪʱΪ�˿��ٻָ��� ������־�ļ���ÿ��������������ӵIJ������������Ǵﵽij���趨�����µ��ڴ�ȫ�����ݡ�����ͨ�����������Ƿ�Ӧ��ʱ�ڴ����ݵ�״̬��������־�Ǹ�ȫ������ݣ����Իָ����ݵ�ʱ�����Ȼָ��������ݣ���ͨ�������ָ�������־�е����ݼ��ɡ�