https://zhuanlan.zhihu.com/p/28297161 ��ͼ��LSTM��GRU������
ͨ����������������LSTM��GRU
��ͳ����
��Ҫ������ƽ�����Ͽ⣬Ȼ�����ͳ�Ʒ�����ģ��
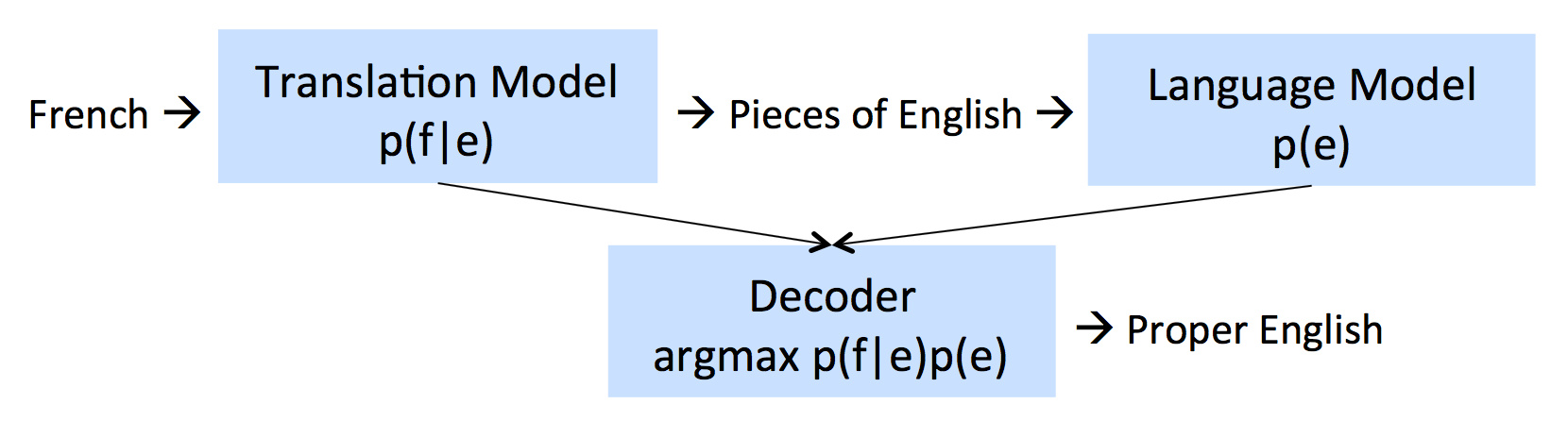
���ַ����Ǻ��ѵģ���Ϊ�漰����Զ��Լ��ܶ�ľ䷨���롣��������Ͳ����ɺ���ĸĽ��ˡ�
�����������һ��˼���Ҿ��ú���Ҫ��
end-to-end model: �ֻ�Ǵ�ͳ��������ϵͳ�ı�ɽһ�ǣ�������ϸ��û���漰��������Ҫ�����������������̣���֮�Ƿdz����ӵ�ϵͳ������ÿ�����ڶ��Ƕ�����ͬ�Ļ���ѧϰ���⡣��Щ������ģ����Ϊ����������һ��ͳһ���Ż�Ŀ��Ϊ����Ŀ�ꡣ
�����ѧϰ���ṩ��һ��ͳһ��ģ�ͣ�һ��ͳһ������Ŀ�꺯�������Ż�Ŀ�꺯���Ĺ����У��õ�һ��end to end��������jointģ�͡���ͳ��������ϵͳ�����ѧϰ�ǽ�Ȼ�෴�ģ�����ģ�͡�����ģ�͡�����ģ�͡���һ�Ѷ�����ģ��������ѵ����
RNN
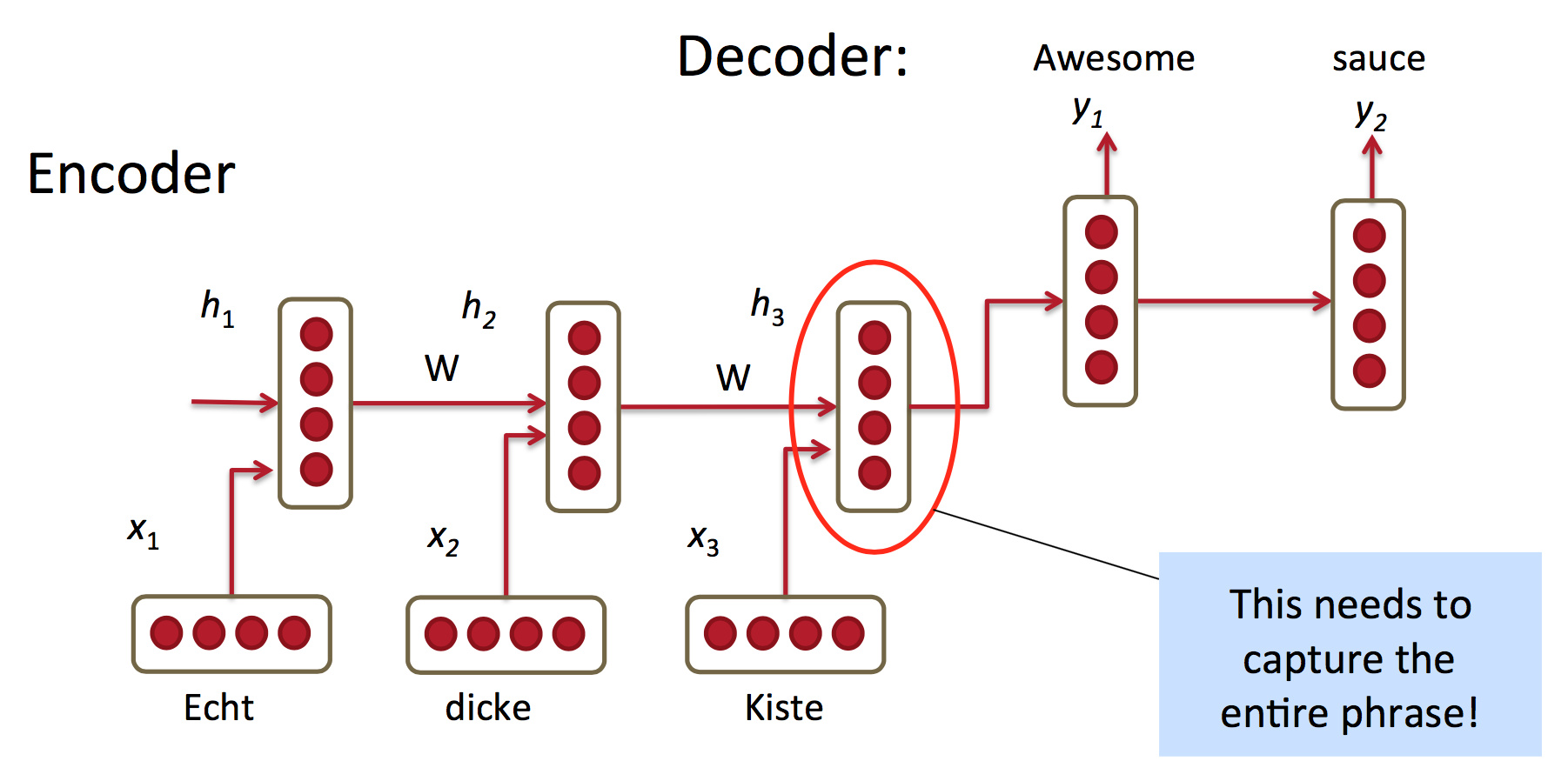
��Ȧ��ʾ������ʾ�����ܲ�����ԭ�Ķ�������壬����RNN����ס̫��֮ǰ�����飬������������ʾ͵������ˡ������ⲻ�Ǹ�ʵ�õ�ģ�͡�(��Ϊ�ݶ���ɢ)
��ͼ�У�
Encoder�ǣ�
ht=?(ht?1,xt)=f(W(hh)ht?1+W(hx)xt)h_t = \phi (h_{t-1}, x_t) = f (W^{(hh)} h_{t-1} + W^{(hx)} x_t)ht?=?(ht?1?,xt?)=f(W(hh)ht?1?+W(hx)xt?)
Decoder�ǣ�
equationht=?(ht?1)=f(W(hh)ht?1){equation} h_t = \phi (h_{t-1}) = f (W^{(hh)} h_{t-1}) equationht?=?(ht?1?)=f(W(hh)ht?1?)
yt=softmax(W(S)ht)y_t = softmax (W^{(S)}h_t)yt?=softmax(W(S)ht?)
��С������ѵ��ʵ���ϵĽ�������
max?��1N��n=1Nlog?p��(y(n)�Ox(n))\max_{\theta} \dfrac {1}{N} \sum_{n=1}^{N} \log p_{\theta} (y^{(n)}|x^{(n)})��max?N1?n=1��N?logp��?(y(n)�Ox(n))
�����ֹdecoder��softmax�����������и�����������ֹ���ࡣ
��չ
- train different weights for encoding and decoding
- compute every hidden state in decoder from:
- ǰһ��ʱ�̵����ز�
- encoder�����һ�����ز�(c=hT)
- ǰһ��Ԥ���� yt?1y_{t?1}yt?1?(Ϊ�˱��ⲻҪ�����ظ��Ĵ�)
3��ʹ�����RNN
4��ʹ�� bi-directional encoder(�������ѵ������˼���)
�ŵ㣺
end-to-end
���Dz���Ҫ�����������������ģ��ȥcapture grammar
ȱ�㣺
��û�а취���µ�������Ҳû�а취����encoder�е�ǰ��Ĵʡ�
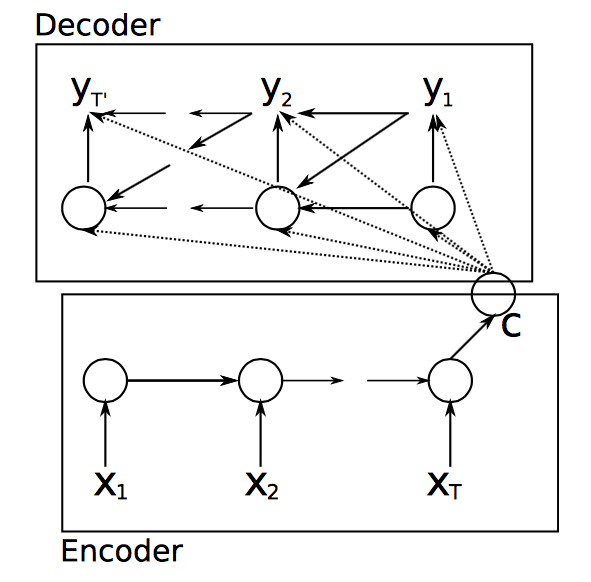
���е�2���ʾ��ͼ��
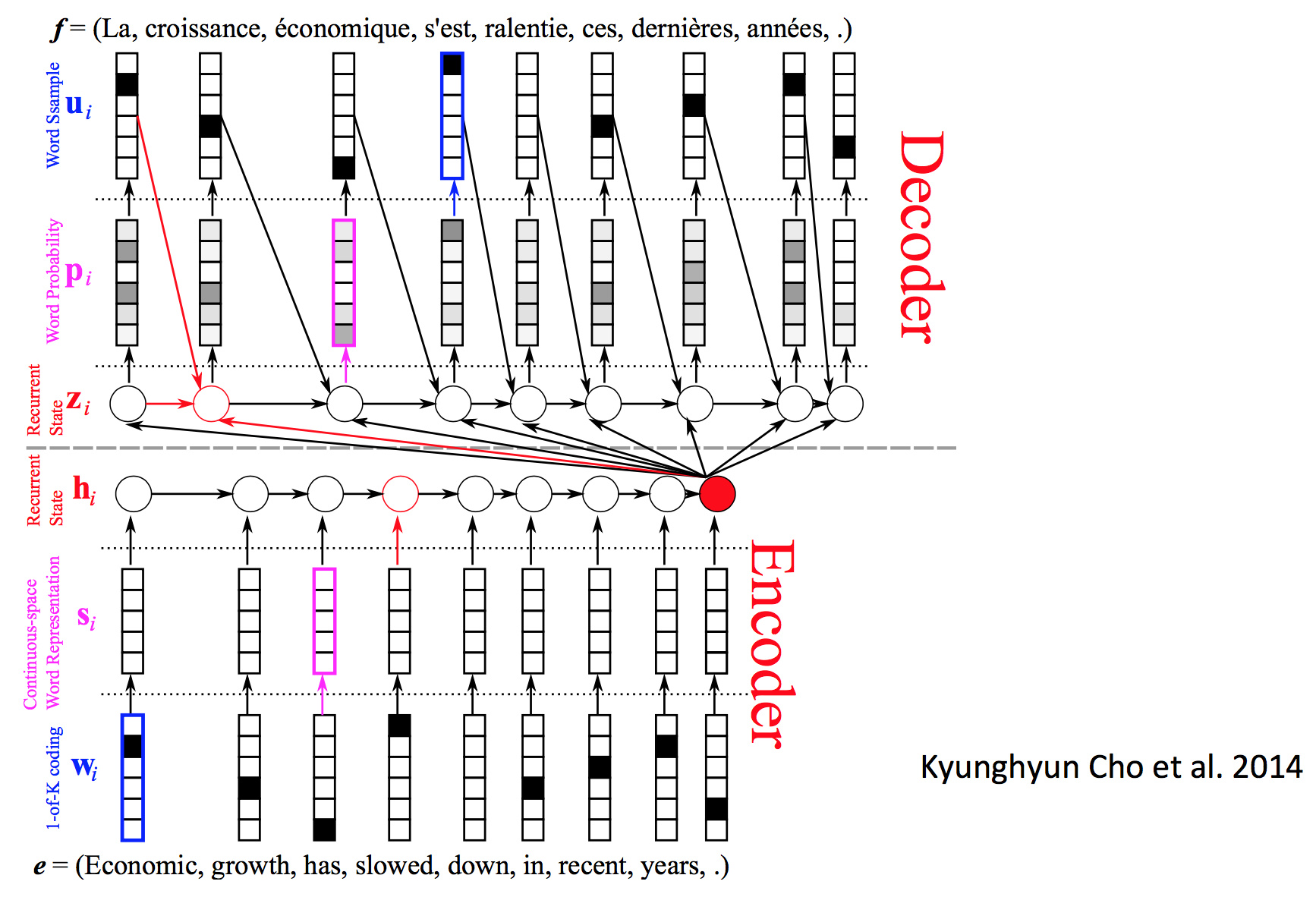
��3���ʾ��ͼ��
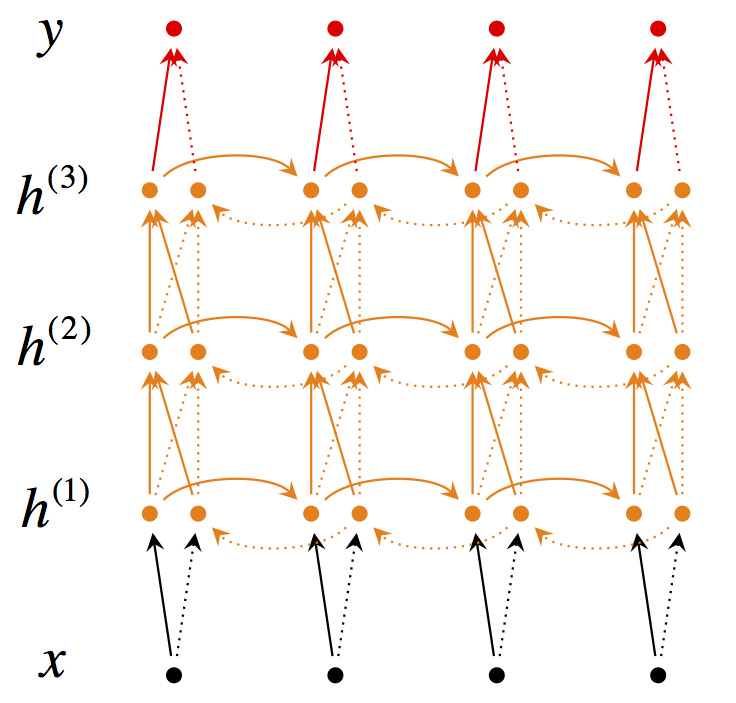
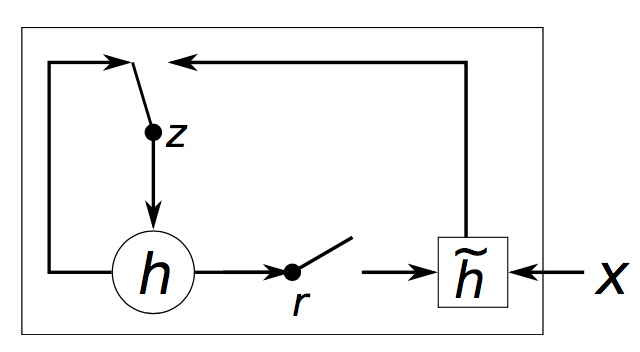
GRU(Gated Recurrent Units)
����Ҫ�ص㣺
- ģ��ѧϰ��ʱ�����Ӷ������䱣�ֺܾ�
- ��������������IJ�ͬ����ͬ��
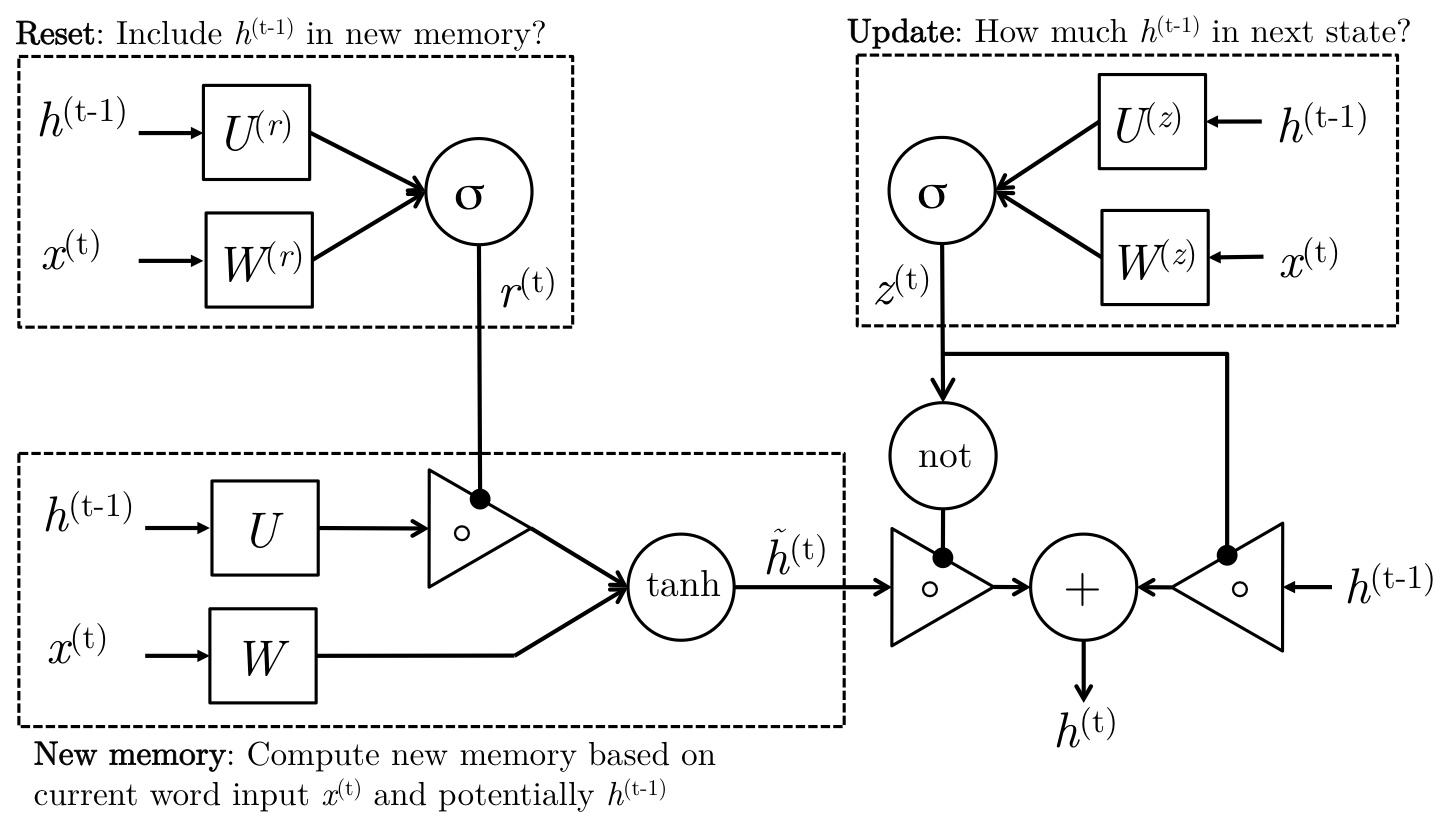
����Ҫ��ʽ����
update gate:
zt=��(W(z)xt+U(z)ht?1)z_t=\sigma\left(W^{(z)}x_t+U^{(z)}h_{t-1}\right)zt?=��(W(z)xt?+U(z)ht?1?)
reset gate:
rt=��(W(r)xt+U(r)ht?1)r_t=\sigma\left(W^{(r)}x_t+U^{(r)}h_{t-1}\right)rt?=��(W(r)xt?+U(r)ht?1?)
new memory content:
h~t=tanh?(rt?Uht?1+Wxt)\tilde{h}_{t} = \operatorname{tanh}(r_{t}\circ Uh_{t-1} + Wx_{t} )h~t?=tanh(rt??Uht?1?+Wxt?)
finale content:
ht=(1?zt)?h~t+zt?ht?1h_{t} = (1 - z_{t}) \circ \tilde{h}_{t} + z_{t} \circ h_{t-1}ht?=(1?zt?)?h~t?+zt??ht?1?
�������˼�ǣ�֮ǰ�ļ�����reset gate���ƣ����reset gateԪ�ض���0��������֮ǰ�����顣�����Ӱ���۵���з��������и����յ����а�����һ��ƽ������Ů�����ƽ������ŮҲ�������Ǹ����յ����У��������˾��������������������Ǹ����ĵĵ�Ӱ��������ǰ��˵�˶��ٻ�������������õĿ��ܾ��ǡ����ġ�����ʡ���ôһЩGRU���ܻ�˵����������һ�����ǿ�ҵĴ���Ҳ���������֮ǰ�ļ���嵭����ͣ��������Ұ�reset gate��Ϊ0��֮ǰ�ļ��䲻�����ã��������дʻ�д���µļ��䡣
��update gate�������ǵ������ĸ��£�����ʱ��t�ļ����������֮ǰ���������Ե�ǰ��
��һ��ʼ��Ϊ���ͼ���͵ĺ����������ԭ��gate�������������IJ���0/1�ġ�
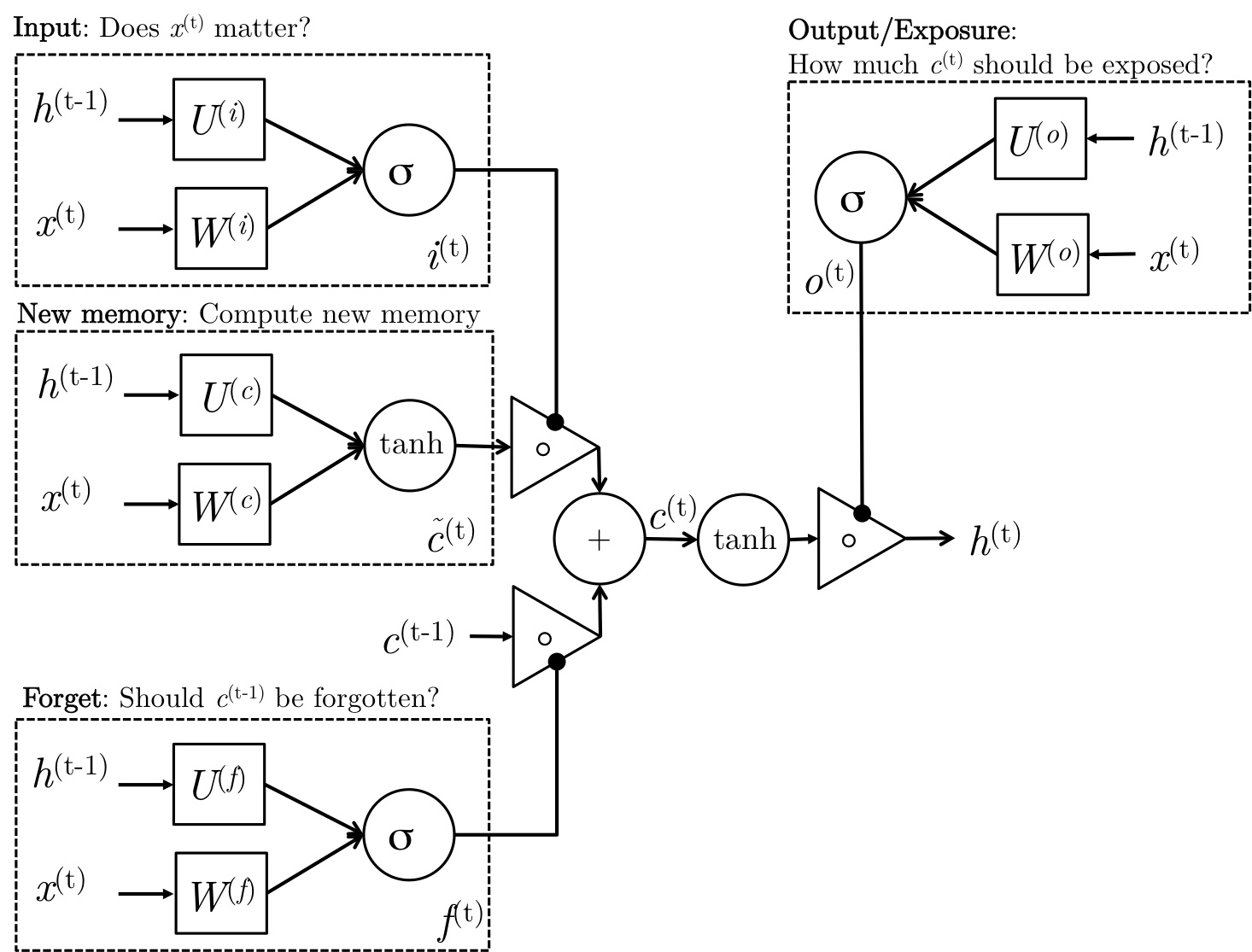
LSTM��Long-Short-Term-Memories��
LSTM��GRU�������ƣ�ֻ������Ԫ�ṹ�е㲻ͬ��GRU�ĵ�Ԫ�ṹ����:
LSTM��Ԫ�ṹ���£�

�Լ������⣺
| GRU | LSTM | |
|---|---|---|
| update gate | ������һ������뵱ǰ�������Ȩ�أ�������Ե���Ҫ�̶� | |
| reset gate | ������һ������ڵ�ǰ�ʵ�Ȩ�أ�ע�����ʵ����� | |
| input gate | ���ڵ�ǰ�ʵ�Ȩ�� | |
| forget gate | ������ƣ�������һ�������Ȩ�� | |
| output gate | ����gate�����tanh����ֵ��ʵ���ϸ�updategateһ�� | |
| new memory generation | ������RNN���� |