����ƪ�ʼ��У��Ѿ���¼����ν���ͼƬ���ݸ�ʽ��ת��������txt�б��嵥�ļ�����ƪ�ʼ���Ҫ��¼��μ���ͼƬ���ݵľ�ֵ������prototxt�����ļ��и�����IJ�����
Caffe��Ҫ����������ʽ����������
ͼ��ͱ�ǩ�������ϵĴ��䣬��������Ĵ��䣬����ת�����߲�εı�ʾ�������Ե÷ֻ��߸���ֵ����ʽ�����
�ڶ�������������Ҫ������������IJ���������������weights��bias. ��Щֵ�����ŵ������ѵ�����̲��ϱ仯�ġ�
һ�������Ƹ�ʽ�ľ�ֵ����
ͼƬ��ȥ��ֵ���ٽ���ѵ���Ͳ��ԣ�������ٶȺ;��ȡ���ˣ�һ���ڸ���ģ���ж�������������������˲��費�DZ���ģ����ʹ��txt�б��嵥�ļ�������Բ�ʹ��db�ļ��;�ֵ�ļ����˲������ݻ��ں������н��⣬���˺�
��ô�����ֵ��ô�����أ�ʵ���Ͼ��Ǽ�������ѵ��������ƽ��ֵ�������������Ϊһ����ֵ�ļ������Ժ�IJ����У��Ϳ���ֱ��ʹ�������ֵ�������������Ҫ�Բ���ͼƬ���¼��㡣
��ѵ�������У�caffeʹ�õľ�ֵ���ݸ�ʽ��binaryproto������һ�������Ƹ�ʽ�ļ�������Ϊ�����ṩ��һ�������ֵ���ļ�compute_image_mean.cpp������caffe��Ŀ¼�µ�tools�ļ������档����caffe�����ɵĿ�ִ���ļ����� build/tools/ Ŀ¼�£����ǿ���ֱ����caffe��Ŀ¼��ʹ������ָ�
build/tools/compute_image_mean my-caffe-project/img_train_lmdb my-caffe-project/mean.binaryproto
- 1
������������
��һ��������my-caffe-project /img_train_lmdb �� ��ʾ��Ҫ�����ֵ�����ݣ���ʽΪlmdb��ѵ�����ݡ�
�ڶ���������my-caffe-project /mean.binaryproto�� ��������Ķ����Ƹ�ʽ�ľ�ֵ�ļ���
����prototxt�����ļ�
Ҫ����caffe����Ҫ�ȴ���һ��ģ�ͣ�model)����Ƚϳ��õ�Lenet,Alex�ȣ� ��һ��ģ���ɶ���ݣ�layer�����ɣ�ÿһ���������������ɡ����еIJ�����������caffe.proto����ļ��С�Ҫ����ʹ��caffe������Ҫ�ľ���ѧ�������ļ���prototxt���ı�д�����ǿ���ֱ��ʹ��vim��дprototxt�ļ���Ҳ����ʹ��caffe��python�ӿڱ�д��������ļ�����������Σ���Ӧ���ȶ���ģ�͵ĸ����������˽⡣
���кܶ������ͣ�����Data,Convolution,Pooling�ȣ���֮���������������Blobs�ķ�ʽ���С�
caffeһ��ʹ�õ�prototxt�����ļ������¼��֣�
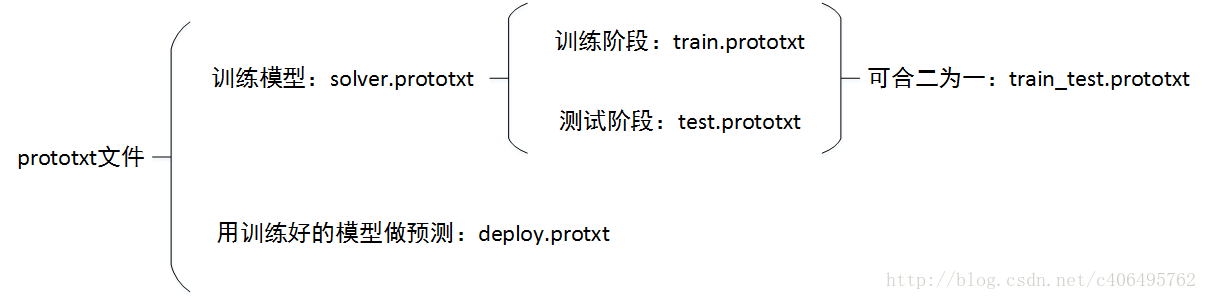
1.train_test.prototxt�ļ��������
��֮ǰ�õ���cifar10_quick_train_test.prototxt�ļ�Ϊ������ѧϰ��һ��һ����з�����
part1:
name: "CIFAR10_quick"
- 1
���ͣ�
name:��ʾ��prototxt�ļ������ƣ���������ȡ��
part2:
layer {name: "cifar" type: "Data" top: "data" top: "label" include { phase: TRAIN }transform_param {mean_file: "examples/cifar10/mean.binaryproto" }data_param {source: "examples/cifar10/cifar10_train_lmdb" batch_size: 100 backend: LMDB }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
���ͣ�
��layerΪ����ѵ�������ݲ�(Data Layers)����������������£� name: ��ʾ�ò�����ƣ�������ȡ��
type:�����ͣ������Data����ʾ������Դ��LevelDB��LMDB���������ݵ���Դ��ͬ�����ݲ������Ҳ��ͬ���������ϸ��������һ������ϰ��ʱ�����Ƕ��Dz��õ�LevelDB��LMDB���ݣ���˲���������ΪData��
top��bottom:ÿһ����bottom���������ݣ���top��������ݡ����ֻ��topû��bottom����˲�ֻ�������û�����롣��֮��Ȼ������ж��top����bottom����ʾ�ж��blobs���ݵ�����������
data �� label: �����ݲ��У�������һ������Ϊdata��top������еڶ���top��һ������Ϊlabel������(data,label)����Ƿ���ģ��������ġ�
include:һ��ѵ����ʱ��Ͳ��Ե�ʱ��ģ�͵IJ��Dz�һ���ġ��ò㣨layer��������ѵ���εIJ㣬�������ڲ��ԽεIJ㣬��Ҫ��include��ָ�������û��include���������ʾ�ò����ѵ��ģ���У����ڲ���ģ���С�
transform_param:ָ��һЩת��������mean_file����ָ�����ɵľ�ֵ�ļ���
data_param:�������ݵ���Դ��ͬ���в�ͬ�����á���cifar10_quick_train_test.prototxt�ļ���ʾ������Դ��LevelDB��LMDB����Ȼ������Ҳ������Դ���ڴ桢HDF5��ͼƬ��Windows��
����Ҫ���õIJ������£�
source: �������ݿ��Ŀ¼���ƣ�
batch_size:ÿ�δ��������ݸ�����
backend:ѡ���Dz���LevelDB����LMDB, Ĭ����LevelDB��
part3:
layer {name: "cifar" type: "Data" top: "data" top: "label" include { phase: TEST }transform_param {mean_file: "examples/cifar10/mean.binaryproto" }data_param {source: "examples/cifar10/cifar10_test_lmdb" batch_size: 100 backend: LMDB }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
���ͣ�
��layerΪ���ڲ��Ե����ݲ�(Data Layers)����������ͬpart2��
part4:
layer {name: "conv1" type: "Convolution" bottom: "data" top: "conv1" param { lr_mult: 1 }param {lr_mult: 2 }convolution_param {num_output: 32 pad: 2 kernel_size: 5 stride: 1 weight_filler { type: "gaussian" std: 0.0001 }bias_filler {type: "constant" }}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
���ͣ�
��layerΪ�Ӿ���(Vision Layers)���Ӿ������Convolution�㡢Pooling�㡢Local Response Normalization (LRN)�㡢im2col��ȡ����Ͽ�֪������Ϊ�Ӿ���ľ�����(Convolution Layer)�����Ǿ���������(CNN)�ĺ��IJ㡣��������������£�
name��type��bottom��top��������ͬ�ϣ�type��������������ΪConvolution�㡣
lr_mult:ѧϰ�ʵ�ϵ�������յ�ѧϰ�������������solver.prototxt�����ļ��е�base_lr�����������lr_mult,���һ����ʾȨֵ��ѧϰ�ʣ��ڶ�����ʾƫ�����ѧϰ�ʡ�һ��ƫ�����ѧϰ����Ȩֵѧϰ�ʵ�������
�ں����convolution_param�У����ǿ����趨����������в�����
�������õIJ�����
num_output: �����ˣ�filter)�ĸ�����
kernel_size: �����˵Ĵ�С����������˵ij��Ϳ����ȣ���Ҫ��kernel_h��kernel_w�ֱ��趨��
����������
stride: �����˵IJ�����Ĭ��Ϊ1��Ҳ������stride_h��stride_w�����ã�
pad: �����Ե��Ĭ��Ϊ0�������䡣�����ʱ�������ҡ����¶ԳƵģ���������˵Ĵ�СΪ5*5����ôpad����Ϊ2�����ĸ���Ե������2�����أ������Ⱥ߶ȶ�������4������,������������֮�������ͼ�Ͳ����С��Ҳ����ͨ��pad_h��pad_w���ֱ��趨��
weight_filler:Ȩֵ��ʼ����Ĭ��Ϊ��constant��,ֵȫΪ0���ܶ�ʱ�������á�xavier���㷨�����г�ʼ����Ҳ��������Ϊ��gaussian����
bias_filler: ƫ����ij�ʼ����һ������Ϊ��constant��,ֵȫΪ0��
bias_term:�Ƿ���ƫ���Ĭ��Ϊtrue, ������
group:���飬Ĭ��Ϊ1�顣�������1���������ƾ��������Ӳ�����һ���Ӽ��ڡ�������Ǹ���ͼ���ͨ�������飬��ô��i���������ֻ�����i���������������ӡ�
Convolution�����㷽����
���룺 n*c0*w0*h0
����� n*c1*w1*h1
���У�c1���Dz����е�num_output�����ɵ�����ͼ������
w1=(w0+2*pad-kernel_size)/stride+1;h1=(h0+2*pad-kernel_size)/stride+1;
- 1
- 2
�������strideΪ1��ǰ�����ξ������ִ����ص����������pad=(kernel_size-1)/2,��������Ⱥ߶Ȳ��䡣
part5:
layer {name: "pool1" type: "Pooling" bottom: "conv1" top: "pool1" pooling_param { pool: MAX kernel_size: 3 stride: 2 }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
���ͣ�
��layerΪ�Ӿ���(Vision Layers)�ijػ���(Pooling Layer)���ò���Ϊ�˼���������������ά�ȶ����õ�һ�ֲ㡣
name��type��bottom��top��������ͬ�ϣ�type��������������ΪPooling�㡣
�ں����pooling_param�У����ǿ����趨�ػ�������в�����
�������õIJ�����
- kernel_size: �ػ��ĺ˴�С��Ҳ������kernel_h��kernel_w�ֱ��趨��
����������
pool: �ػ�������Ĭ��ΪMAX��Ŀǰ���õķ�����MAX, AVE, ��STOCHASTIC��
pad: �;������pad��һ�������б�Ե���䡣Ĭ��Ϊ0��
stride: �ػ��IJ�����Ĭ��Ϊ1��һ����������Ϊ2�������ص���Ҳ������stride_h��stride_w�����á�
pooling������㷽�������Ǻ;�������һ���ġ�
���룺 n*c*w0*h0
����� n*c*w1*h1
�;����������������е�c���ֲ��䣺
w1=(w0+2*pad-kernel_size)/stride+1;h1=(h0+2*pad-kernel_size)/stride+1;
- 1
- 2
�������strideΪ2��ǰ�����ξ������ֲ��ص���100*100������ͼ�ػ����50*50��
part6:
layer {name: "relu1" type: "ReLU" bottom: "pool1" top: "pool1" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
���ͣ�
��layerΪ�����(Activation Layers)���ڼ�����У����������ݽ��м��������ʵ���Ͼ���һ�ֺ����任��������Ԫ�ؽ�������ġ���bottom�õ�һ��blob�������룬�����top����һ��blob���ݡ�����������У�û�иı����ݵĴ�С�����������������ݴ�С����ȵġ�
- name��type��bottom��top��������ͬ�ϣ�type��������������Ϊʹ��ReLU������ļ������㡣
��ѡ������
- negative_slope��Ĭ��Ϊ0���Ա���ReLU�������б仯��������������ֵ����ô����Ϊ����ʱ���Ͳ�������Ϊ0��������ԭʼ���ݳ���negative_slope��
������������㷽����
���룺 n*c*h*w
����� n*c*h*w
���õļ������sigmoid, tanh,relu�ȡ��ü�����ʹ��ReLU�������ReLU��֧��in-place���㣬����ζ��bottom�������������ͬ�Ա����ڴ�����ġ�
part7:
layer {name: "conv2" type: "Convolution" bottom: "pool1" top: "conv2" param { lr_mult: 1 }param {lr_mult: 2 }convolution_param {num_output: 32 pad: 2 kernel_size: 5 stride: 1 weight_filler { type: "gaussian" std: 0.01 }bias_filler {type: "constant" }}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
���ͣ�
��layerΪ�����㣬ͬpart4��
part7:
layer {name: "relu2" type: "ReLU" bottom: "conv2" top: "conv2" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
���ͣ�
��layerΪ�ػ��㣬ͬpart5��
part8:
layer {name: "conv3" type: "Convolution" bottom: "pool2" top: "conv3" param { lr_mult: 1 }param {lr_mult: 2 }convolution_param {num_output: 64 pad: 2 kernel_size: 5 stride: 1 weight_filler { type: "gaussian" std: 0.01 }bias_filler {type: "constant" }}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
���ͣ�
��layerΪ�����㣬ͬpart4��
part9:
layer {name: "relu3" type: "ReLU" bottom: "conv3" top: "conv3" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
���ͣ�
��layerΪ����㣬ͬpart6��
part10:
layer {name: "pool3" type: "Pooling" bottom: "conv3" top: "pool3" pooling_param { pool: AVE kernel_size: 3 stride: 2 }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
���ͣ�
��layerΪ�ػ��㣬ͬpart5��
part11:
layer {name: "ip1" type: "InnerProduct" bottom: "pool3" top: "ip1" param { lr_mult: 1 }param {lr_mult: 2 }inner_product_param {num_output: 64 weight_filler { type: "gaussian" std: 0.1 }bias_filler {type: "constant" }}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
���ͣ�
��layerΪȫ����(Inner Product)��ȫ���Ӳ㣬�����뵱����һ�����������Ҳ��һ��������������������blobs��width��heightȫ��Ϊ1����
name��type��bottom��top��������ͬ�ϣ�type��������������Ϊȫ���㡣
�ں����inner_product_param�У����ǿ����趨����������в�����
�������õIJ�����
- num_output: ��������filfter)�ĸ���
����������
weight_filler: Ȩֵ��ʼ����Ĭ��Ϊ��constant��,ֵȫΪ0���ܶ�ʱ�������á�xavier���㷨�����г�ʼ����Ҳ��������Ϊ��gaussian����
bias_filler: ƫ����ij�ʼ����һ������Ϊ��constant��,ֵȫΪ0��
bias_term: �Ƿ���ƫ���Ĭ��Ϊtrue, ������
ȫ����ļ��㷽����
���룺 n*c0*h*w
����� n*c1*1*1
ȫ���Ӳ�ʵ����Ҳ��һ�־����㣬ֻ�����ľ����˴�С��ԭ���ݴ�Сһ�¡�������IJ��������;�����IJ���һ����
part12:
layer {name: "ip2" type: "InnerProduct" bottom: "ip1" top: "ip2" param { lr_mult: 1 }param {lr_mult: 2 }inner_product_param {num_output: 10 weight_filler { type: "gaussian" std: 0.1 }bias_filler {type: "constant" }}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
���ͣ�
��layerΪȫ���㣬ͬpart11��
part13:
layer {name: "accuracy" type: "Accuracy" bottom: "ip2" bottom: "label" top: "accuracy" include { phase: TEST }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
���ͣ�
��layerΪ���������(Accuracy Layer)���ò�������ࣨԤ�⣩��ȷ�ȣ�ֻ��test�β��У�include�������Ͳ��Խ�ʹ�á�
part14:
layer {name: "loss" type: "SoftmaxWithLoss" bottom: "ip2" bottom: "label" top: "loss" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
���ͣ�
��layerΪsoftmax-loss�㣬sotfmax-loss���㹫ʽΪ��
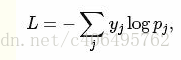
�о��������ھ��������õ�����ũ�صļ��㡣
- name��type��bottom��top��������ͬ�ϣ�type��������������Ϊsoftmax-loss�㡣
2.��β
��Caffe�У�������Щ�㣬���кܶ�㣬�����ڳ��������У����ﲻ�ڼ������⡣
��Ϊ��ϸ�����ݣ��ɲ鿴������
URL��http://caffe.berkeleyvision.org/tutorial/layers.html
��ƪ�ʼǽ���¼���ʹ��caffe�ṩ��python�ӿڱ�дtrain.protxt��test.prototxt�ļ���