视觉层具体包含以下几个层:
- Convolution Layer - convolves the input image with a set of learnable filters, each producing one feature map in the output image.
- Pooling Layer - max, average, or stochastic pooling.
- Spatial Pyramid Pooling (SPP)
- Crop - perform cropping transformation.
- Deconvolution Layer - transposed convolution.
- Im2Col - relic helper layer that is not used much anymore.
1)convolution layer
实例: as seen in caffe/models/bvlc_reference_caffenet/train_val.prototxt
layer {name: "conv1"type: "Convolution"bottom: "data"top: "conv1"# learning rate and decay multipliers for the filtersparam { lr_mult: 1 decay_mult: 1 }# learning rate and decay multipliers for the biasesparam { lr_mult: 2 decay_mult: 0 }convolution_param {num_output: 96 # learn 96 filterskernel_size: 11 # each filter is 11x11stride: 4 # step 4 pixels between each filter applicationweight_filler {type: "gaussian" # initialize the filters from a Gaussianstd: 0.01 # distribution with stdev 0.01 (default mean: 0)}bias_filler {type: "constant" # initialize the biases to zero (0)value: 0}}}输入:n * c_i * h_i * w_i
输出:n * c_o * h_o * w_o, where h_o = (h_i + 2 * pad_h - kernel_h) / stride_h + 1 and w_o likewise.
他的parameter的定义如下:
message ConvolutionParameter {optional uint32 num_output = 1; // The number of outputs for the layeroptional bool bias_term = 2 [default = true]; // whether to have bias terms// Pad, kernel size, and stride are all given as a single value for equal// dimensions in all spatial dimensions, or once per spatial dimension.repeated uint32 pad = 3; // The padding size; defaults to 0repeated uint32 kernel_size = 4; // The kernel sizerepeated uint32 stride = 6; // The stride; defaults to 1// Factor used to dilate the kernel, (implicitly) zero-filling the resulting// holes. (Kernel dilation is sometimes referred to by its use in the// algorithme à trous from Holschneider et al. 1987.)repeated uint32 dilation = 18; // The dilation; defaults to 1// For 2D convolution only, the *_h and *_w versions may also be used to// specify both spatial dimensions.optional uint32 pad_h = 9 [default = 0]; // The padding height (2D only)optional uint32 pad_w = 10 [default = 0]; // The padding width (2D only)optional uint32 kernel_h = 11; // The kernel height (2D only)optional uint32 kernel_w = 12; // The kernel width (2D only)optional uint32 stride_h = 13; // The stride height (2D only)optional uint32 stride_w = 14; // The stride width (2D only)optional uint32 group = 5 [default = 1]; // The group size for group convoptional FillerParameter weight_filler = 7; // The filler for the weightoptional FillerParameter bias_filler = 8; // The filler for the biasenum Engine { DEFAULT = 0; CAFFE = 1; CUDNN = 2;}optional Engine engine = 15 [default = DEFAULT];// The axis to interpret as "channels" when performing convolution.// Preceding dimensions are treated as independent inputs;// succeeding dimensions are treated as "spatial".// With (N, C, H, W) inputs, and axis == 1 (the default), we perform// N independent 2D convolutions, sliding C-channel (or (C/g)-channels, for// groups g>1) filters across the spatial axes (H, W) of the input.// With (N, C, D, H, W) inputs, and axis == 1, we perform// N independent 3D convolutions, sliding (C/g)-channels// filters across the spatial axes (D, H, W) of the input.optional int32 axis = 16 [default = 1];// Whether to force use of the general ND convolution, even if a specific// implementation for blobs of the appropriate number of spatial dimensions// is available. (Currently, there is only a 2D-specific convolution// implementation; for input blobs with num_axes != 2, this option is// ignored and the ND implementation will be used.)optional bool force_nd_im2col = 17 [default = false];
}具体解释:
- lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。 在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它可选参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。
扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。weight_filler: 权值初始化。
默认为“constant”,值全为0,很多时候我们用”xavier”算法来进行初始化,也可以设置为”gaussian”bias_filler: 偏置项的初始化。一般设置为”constant”,值全为0。
- bias_term: 是否开启偏置项,默认为true, 开启
group: 分组,默认为1组。如果大于1,我们限制卷积的连接操作在一个子集内。如果我们根据图像的通道来分组,那么第i个输出分组只能与第i个输入分组进行连接。
2) pooling层相对来说比较简单:
实例: (as seen in caffe/models/bvlc_reference_caffenet/train_val.prototxt)
layer {name: "pool1"type: "Pooling"bottom: "conv1"top: "pool1"pooling_param {pool: MAXkernel_size: 3 # pool over a 3x3 regionstride: 2 # step two pixels (in the bottom blob) between pooling regions}
}parameter:
message PoolingParameter {enum PoolMethod { MAX = 0; AVE = 1; STOCHASTIC = 2;}optional PoolMethod pool = 1 [default = MAX]; // The pooling method// Pad, kernel size, and stride are all given as a single value for equal// dimensions in height and width or as Y, X pairs.optional uint32 pad = 4 [default = 0]; // The padding size (equal in Y, X)optional uint32 pad_h = 9 [default = 0]; // The padding heightoptional uint32 pad_w = 10 [default = 0]; // The padding widthoptional uint32 kernel_size = 2; // The kernel size (square)optional uint32 kernel_h = 5; // The kernel heightoptional uint32 kernel_w = 6; // The kernel widthoptional uint32 stride = 3 [default = 1]; // The stride (equal in Y, X)optional uint32 stride_h = 7; // The stride heightoptional uint32 stride_w = 8; // The stride widthenum Engine { DEFAULT = 0; CAFFE = 1; CUDNN = 2;}optional Engine engine = 11 [default = DEFAULT];// If global_pooling then it will pool over the size of the bottom by doing// kernel_h = bottom->height and kernel_w = bottom->widthoptional bool global_pooling = 12 [default = false];
}解释:
层类型:Pooling
必须设置的参数:
- kernel_size: 池化的核大小。也可以用kernel_h和kernel_w分别设定。
其它可选参数:
pool: 池化方法,默认为MAX。目前可用的方法有MAX, AVE, 或STOCHASTIC
pad: 和卷积层的pad的一样,进行边缘扩充。默认为0
stride: 池化的步长,默认为1。一般我们设置为2,即不重叠。也可以用stride_h和stride_w来设置
3)ssp layer 可参考paper:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
示例
layer {name: "pool5_spp"type: "SPP"bottom: "conv5"top: "pool5_spp"spp_param{pyramid_height:3pool: MAX}
}parameter:
message SPPParameter {enum PoolMethod { MAX = 0; AVE = 1; STOCHASTIC = 2;}optional uint32 pyramid_height = 1;optional PoolMethod pool = 2 [default = MAX]; // The pooling methodenum Engine { DEFAULT = 0; CAFFE = 1; CUDNN = 2;}optional Engine engine = 6 [default = DEFAULT];
}关于spp的一点解释(详细可参考paper):空间金字塔池化(spatial pyramidpooling(SPP))层来去除网络固定大小的限制,也就是说,将SPP层接到最后一个卷积层后面,SPP层池化特征并且产生固定大小的输出,它的输出然后再送到第一个全连接层。也就是说在卷积层和全连接层之前,我们导入了一个新的层,它可以接受不同大小的输入但是产生相同大小的输出;这样就可以避免在网络的输入口处就要求它们大小相同,也就实现了文章所说的可以接受任意输入尺度。
4)crop layer
parameter设置:
message CropParameter {// To crop, elements of the first bottom are selected to fit the dimensions// of the second, reference bottom. The crop is configured by// - the crop `axis` to pick the dimensions for cropping// - the crop `offset` to set the shift for all/each dimension// to align the cropped bottom with the reference bottom.// All dimensions up to but excluding `axis` are preserved, while// the dimensions including and trailing `axis` are cropped.// If only one `offset` is set, then all dimensions are offset by this amount.// Otherwise, the number of offsets must equal the number of cropped axes to// shift the crop in each dimension accordingly.// Note: standard dimensions are N,C,H,W so the default is a spatial crop,// and `axis` may be negative to index from the end (e.g., -1 for the last// axis).optional int32 axis = 1 [default = 2];repeated uint32 offset = 2;
}下面是引用别人给的解释,觉得解释的很好哦.
According to the Crop layer documentation, it takes two bottom blobs and outputs one top blob. Let’s call the bottom blobs as A and B, the top blob as T.
A -> 32 x 3 x 224 x 224
B -> 32 x m x n x p
Then,
T -> 32 x m x n x p
Regarding axis parameter, from docs:
Takes a Blob and crop it, to the shape specified by the second input Blob, across all dimensions after the specified axis.
which means, if we set axis = 1, then it will crop dimensions 1, 2, 3. If axis = 2, then T would have been of the size 32 x 3 x n x p. You can also set axis to a negative value, such as -1, which would mean the last dimension, i.e. 3 in this case.
Regarding offset parameter, I checked out $CAFFE_ROOT/src/caffe/proto/caffe.proto (on line 630), I did not find any default value for offset parameter, so I assume that you have to provide that parameter, otherwise it will result in an error. However, I may be wrong.
Now, Caffe knows that you need a blob of size m on the first axis. We still need to tell Caffe from where to crop. That’s where offset comes in. If offset is 10, then your blob of size m will be cropped starting from 10 and end at 10+m-1 (for a total of size m). Set one value for offset to crop by that amount in all the dimensions (which are determined by axis, remember? In this case 1, 2, 3). Otherwise, if you want to crop each dimension differently, you have to specify number of offsets equal to the number of dimensions being cropped (in this case 3). So to sum up all,
If you have a blob of size 32 x 3 x 224 x 224 and you want to crop a center part of size 32 x 3 x 32 x 64, then you would write the crop layer as follows:
layer {name: "T"type: "Crop"bottom: "A"bottom: "B"top: "T"crop_param {axis: 2offset: 96offset: 80}
}FCN使用了crop layer,有兴趣的可以研究一下。。
5)img2clo
官方文档就一句话。我再补充点:
它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。如下图: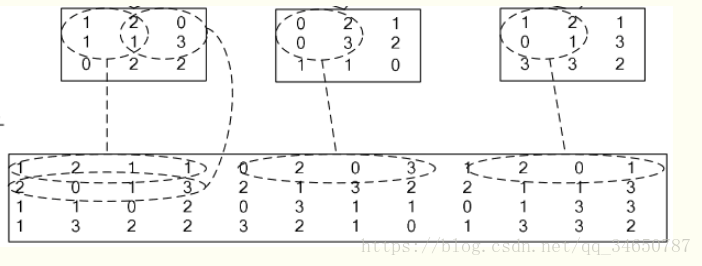
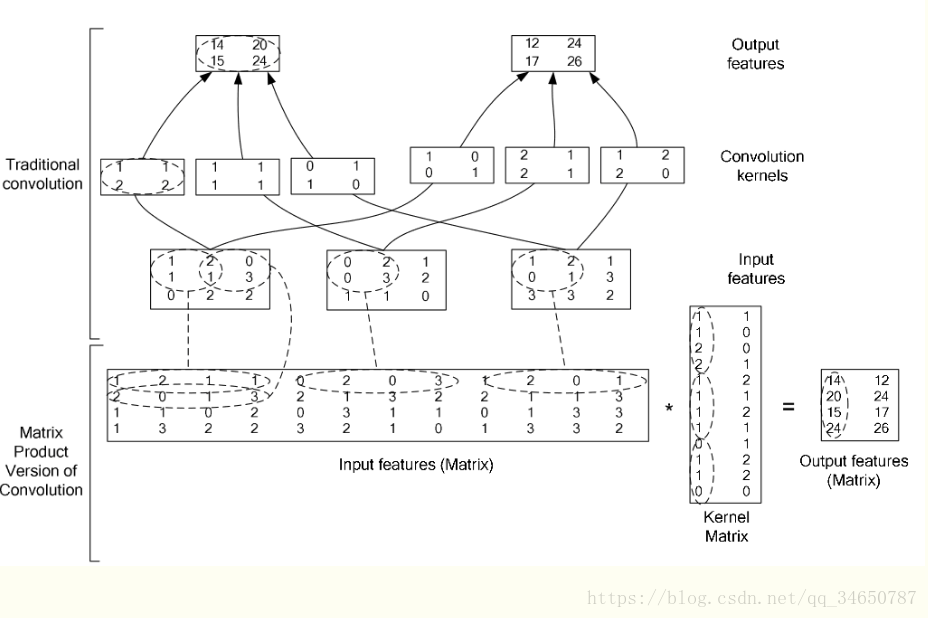
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
细心的同学可能发现我漏了一个deconvolution layer,没错,这个层官方没有给出文档,我就举个例子在下面好了:
layer {name: "upscore2"type: "Deconvolution"bottom: "score_fr"top: "upscore2"param {lr_mult: 0}convolution_param {num_output: 21bias_term: falsekernel_size: 4stride: 2}
}这个是fcn里的一段代码,参考一下。