�����Deep Learning�����ҵ Course1-����������ѧϰ-��������ҵ
Planar data classification with one hidden layer����һ�����ز��ƽ�����ݷ���
���Ŀ�ģ�
- ʹ�ô��з����Լ����������tanh������ʵ��һ�����е����ز�Ķ����������硣
- ���㽻���ش��ۡ�
- ʵ��ǰ���ͷ�����
1.��Ҫʹ�õİ�
1.numpy����Python���ڿ�ѧ����Ļ�������
2.matplotlib��python���ڻ�ͼ�Ŀ⡣
3.sklearn��Ϊ�����ھ�����ݷ����ṩ����Ч�Ĺ��ߡ�
4.planar_utils���ṩ�������������ʹ�õĸ������õĺ��������������ʦ��ҵ���ṩ��
5.testCases���ṩ��һЩ����ʾ����������������ȷ��
2.���ݼ�
���α��ʹ�õ����ݼ�Ϊ"flower"�����ճ��棬�������ȼ������ݼ����鿴�������ݼ�����Ϣ��
���룺
import numpy as np
import matplotlib.pyplot as plt
from Utils import planar_utils, sigmoidif __name__ == "__main__":X, Y = planar_utils.load_planar_dataset()print(X.shape)print(Y.shape)plt.scatter(X[0, :], X[1, :], c=np.squeeze(Y), s=40, cmap=plt.cm.Spectral)
������
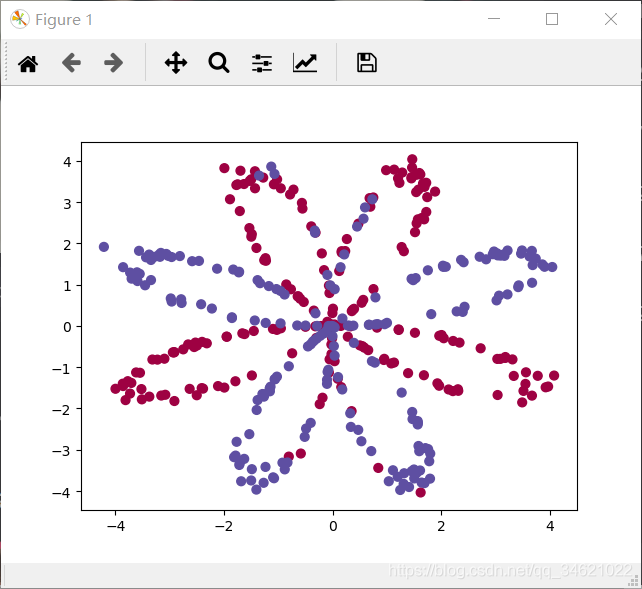
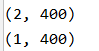
�����н�����Կ���X��ά���ǣ�2��400����Y��ά���ǣ�1��400����Ҳ����˵X��400��������ÿ������������������
��ͼ���к�ɫ��������ı�ǩ��Y=0����ɫ��������ı�ǩ��Y=1��
3.�����ع�
�ڹ���������������֮ǰ���������ȿ������ع�����������ϵı��֡�����ʹ��sklearn�����ú�����ʵ����һ�㡣��������Ĵ�����ѵ�����ݼ��ϵ����ع��������
clf = sklearn.linear_model.LogisticRegressionCV()clf.fit(X.T, Y.T)
���н�������ӡ���������棬������ʱ����������warning��
D:\programfile\Anaconda3\lib\site-packages\sklearn\utils\validation.py:724: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
D:\programfile\Anaconda3\lib\site-packages\sklearn\model_selection_split.py:1978: FutureWarning: The default value of cv will change from 3 to 5 in version 0.22. Specify it explicitly to silence this warning.
warnings.warn(CV_WARNING, FutureWarning)
�����ع���������Ƴ�����
���룺
clf = sklearn.linear_model.LogisticRegressionCV()clf.fit(X.T, Y.T)# ���ƾ��߽߱�plot_decision_boundary(lambda x: clf.predict(x), X, Y)plt.title("Logistic Regression")#��ӡȷ��LR_predictions = clf.predict(X.T)print('���ع�ģ����ȷ���ȷ�ʣ�%d' %float((np.dot(Y, LR_predictions) + np.dot(1 - Y, 1 - LR_predictions)) / float(Y.size) * 100) + '%')
������
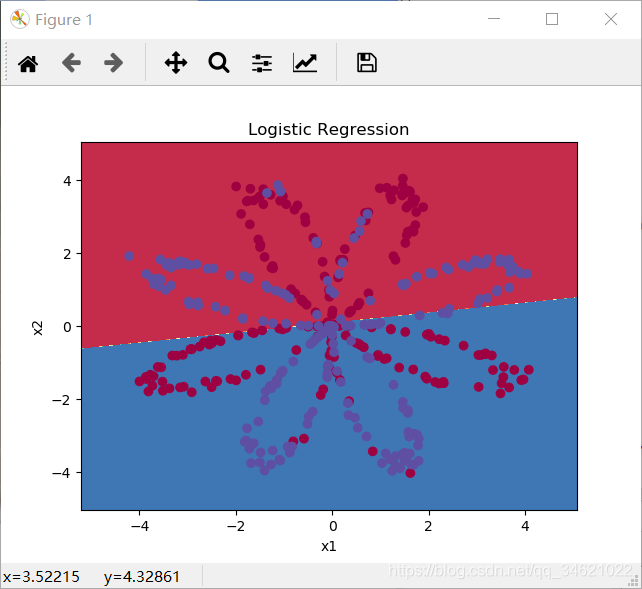

���������н������Ҳ���Կ���sklearn���Դ������ع�ģ�Ͳ����ܺܺõĶ����ݼ��е����ݽ��з��࣬��ȷ�ʻ�����50%�����ǵ�Ŀ�ľ��ǵõ����õķ���ģ�ͣ�����������һ��ʵ�����������ģ�͡�
4.������ģ�͡�
�������dz�����ѵ��һ��ֻ��һ�����ز�������硣
ģ����ͼ��ʾ��
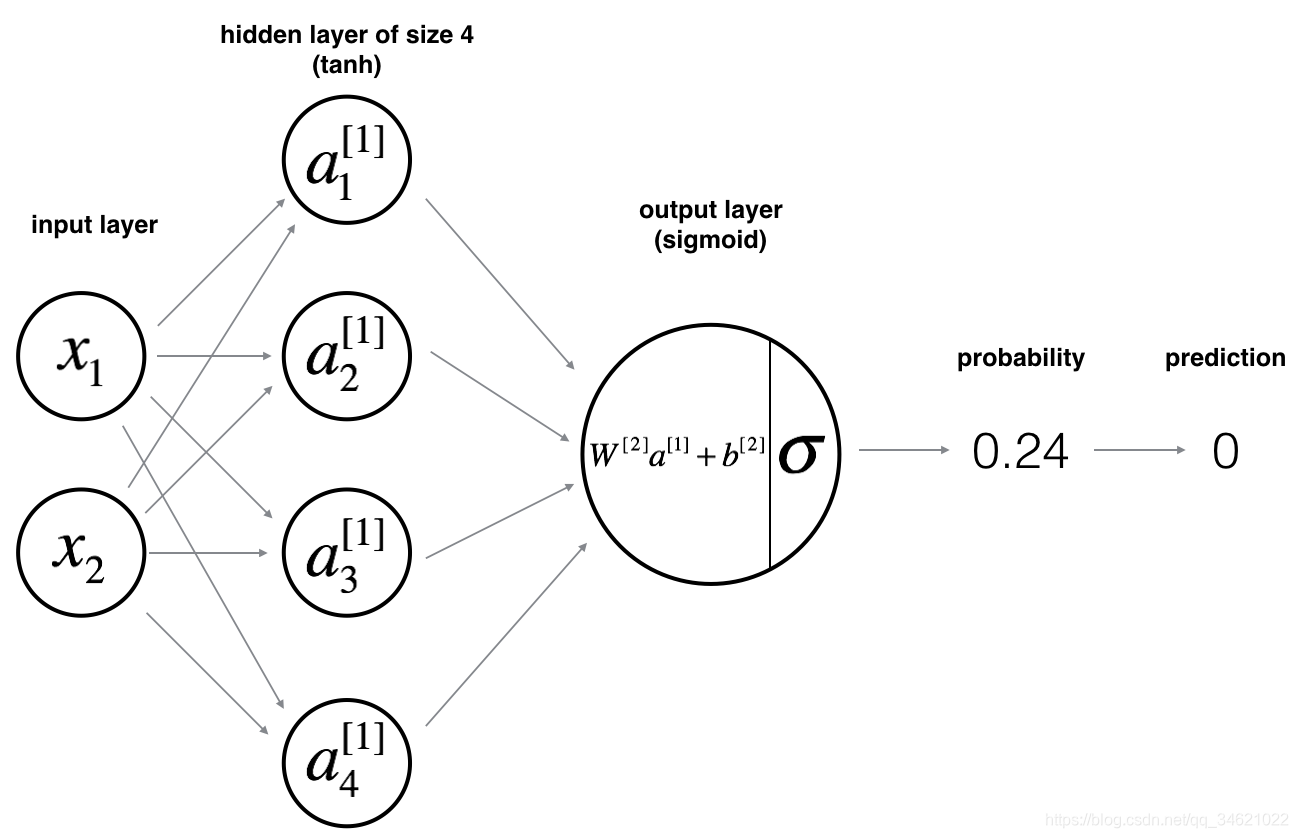
��ѧ��ʽ�������⣺
��һ������x(i)x^(i)x(i)Ϊ����
z[1](i)z^{[1](i)}z[1](i) = W[1]x(1)W^{[1]}x^{(1)}W[1]x(1) + b[1](i)b^{[1](i)}b[1](i)
a[1](i)a^{[1](i)}a[1](i) = tanh?(z[1](i))\tanh(z^{[1](i)})tanh(z[1](i))
z[2](i)z^{[2](i)}z[2](i) = W[2]a[1](i)W^{[2]}a^{[1](i)}W[2]a[1](i) + b[2](i)b^{[2](i)}b[2](i)
y^(i)\hat y^{(i)}y^?(i) = a[1](i)a^{[1](i)}a[1](i) = ��(z[2](i))\sigma(z^{[2](i)})��(z[2](i))
yprediction(i)y^{(i)}_{prediction}yprediction(i)? = {0,a[2](i)>0.51\begin{cases}0, a^{[2](i)} > 0.5 \\ 1 \end{cases}{
0,a[2](i)>0.51?
����������Ԥ���������ǿ��Լ�����ۣ�����Ϊ���ۺ�����ʽ��
J=?1m��i=0m(y(i)log?(a[2](i))+(1?y(i))log?(1?a[2](i)))J = - \frac{1}{m} \sum\limits_{i = 0}^{m} \large\left(\small y^{(i)}\log\left(a^{[2] (i)}\right) + (1-y^{(i)})\log\left(1- a^{[2] (i)}\right) \large \right) \small J=?m1?i=0��m?(y(i)log(a[2](i))+(1?y(i))log(1?a[2](i)))
4.1ģ�����
����һ��������ģ�͵ķ�����
1.����������ṹ��
2.��ʼ��ģ�Ͳ�����
3.ѭ����
- ʵ��ǰ��
- ������ʧ
- ��������ݶ�
- ���²���
4.2 ����������ṹ
��������������
- n_x:�����Ĵ�С
- n_h:���ز�Ĵ�С(����Ϊ4)
- n_y:�����Ĵ�С
�ȶ��庯��layer_sizes_test_cases����Ҫ�����Զ�����ѵ���������������£�
def layer_sizes_test_case():#������ɲ�ͬ��ѵ����X�ͱ�ǩ��Y#ʹ��random.randrange()����X_feature_num = random.randrange(1, 9)Y_feature_num = random.randrange(1, 3)number = random.randrange(10, 100)#(������������������X_assess = np.zeros(shape=(X_feature_num, number))Y_assess = np.zeros(shape=(Y_feature_num, number))return X_assess, Y_assess
����layer_sizes����������ѵ�����ͱ�ǩ���������㡢���ز㡢������С��
def layer_sizes(X, Y):n_x = X.shape[0]n_h = 4n_y = Y.shape[0]return n_x, n_h, n_y
���ԣ�
X_assess, Y_assess = layer_sizes_test_case()n_x, n_h, n_y = layer_sizes(X_assess, Y_assess)print("������С��n_x = %d"%n_x)print("���ز��С��n_h = %d"%n_h)print("������С��n_y = %d"%n_y)
������

4.3 ��ʼ��ģ�Ͳ���
ʹ��np.random.randn(a,b) * 0.01�����ʼ����״����(a,b)����ƫ��������ʼ��Ϊ�㣨����0.01��ԭ���ǣ�Ȩ�ع����ʹ�����뼤�����ֵ����������ݶ��½�ͣ�ͣ�randn����������ķ�Χ��[0, 1)����
ʹ��np.zeros((a,b))��ʼ��һ����0����״����(a,b)��
���룺
def initiallize_parameters(n_x, n_h, n_y):np.random.seed(2)W1 = np.random.randn(n_h, n_x) * 0.01b1 = np.zeros(shape = (n_h, 1))W2 = np.random.randn(n_y, n_h) * 0.01b2 = np.zeros(shape=(n_y, 1))assert (W1.shape == (n_h, n_x))assert (b1.shape == (n_h, 1))assert (W2.shape == (n_y, n_h))assert (b2.shape == (n_y, 1))parameters = {
"W1": W1,"b1": b1,"W2": W2,"b2": b2}return parameters
���ԣ�
X_assess, Y_assess = layer_sizes_test_case()n_x, n_h, n_y = layer_sizes(X_assess, Y_assess)print("������С��n_x = %d"%n_x)print("���ز��С��n_h = %d"%n_h)print("������С��n_y = %d"%n_y)parameters = initiallize_parameters(n_x, n_h, n_y)print("W1 = " + str(parameters["W1"]))print("b1 = " + str(parameters["b1"]))print("W2 = " + str(parameters["W2"]))print("b2 = " + str(parameters["b2"]))
������

4.3 �������������ʵ��
1.ǰ��
���룺
def forward_propagation(X, parameters):print(X.shape)W1 = parameters['W1']b1 = parameters['b1']W2 = parameters['W2']b2 = parameters['b2']Z1 = np.dot(W1, X) + b1 #4,2 2,1 = 4,1A1 = np.tanh(Z1) #4, 1Z2 = np.dot(W2, A1) + b2 #1, 4 4,1 = 1,1A2 = sigmoid.sigmoid(Z2) #1, 1print(A2.shape)assert(A2.shape == (1, X.shape[1]))cache = {
"Z1" : Z1,"A1" : A1,"Z2" : Z2,"A2" : A2}return A2, cache
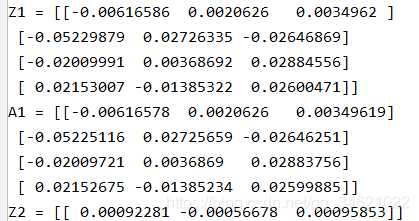
���ԣ����õ��ĺ��������ĵ���β����
X_assess, parameters = forward_propagation_test_case()A2, cache = forward_propagation(X_assess, parameters)print("Z1 = " + str(cache['Z1']))print("A1 = " + str(cache['A1']))print("Z2 = " + str(cache['Z2']))
������
2.���ۺ���
������ǰ������һ�����Ǿ�Ҫ������ۣ����㹫ʽ���£�
J=?1m��i=0m(y(i)log?(a[2](i))+(1?y(i))log?(1?a[2](i)))J = - \frac{1}{m} \sum\limits_{i = 0}^{m} \large{(} \small y^{(i)}\log\left(a^{[2] (i)}\right) + (1-y^{(i)})\log\left(1- a^{[2] (i)}\right) \large{)} \smallJ=?m1?i=0��m?(y(i)log(a[2](i))+(1?y(i))log(1?a[2](i)))
���룺
def compute_cost(A2,Y,parameters):m = Y.shape[1]W1 = parameters['W1']W2 = parameters['W2']#��ӦԪ�����logprobs = np.multiply(np.log(A2), Y) + np.multiply(np.log(1 - A2), (1 - Y))cost = -np.sum(logprobs)/mcost = np.squeeze(cost)assert (isinstance(cost, float))return cost
����:
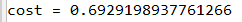
3.���㷴��
����ǰ���õ���cache��������ݽ��м��㡣
������������һ�·����ļ��㹫ʽ��

��ǰ��������ʹ�õĵ�һ���������sigmoid���䵼������д��
g��g^{'}g��(z) = g(z)(1?g(z))g(z)(1-g(z))g(z)(1?g(z))���ڶ����������tanh���䵼��Ϊg��g^{'}g��(z) = (1?g(z)2)(1-g(z)^{2})(1?g(z)2)��
ʵ�ִ��룺
def backward_propagation(parameters, cache, X, Y):m = X.shape[1]W1 = parameters['W1']W2 = parameters['W2']A1 = cache['A1']A2 = cache['A2']dZ2 = A2 - YdW2 = np.dot(dZ2, A1.T)#����֮��db2 = np.sum(dZ2, axis=1, keepdims=True)/mdZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2))dW1 = np.dot(dZ1, X.T)/mdb1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)grads = {
"dW1": dW1,"db1": db1,"dW2": dW2,"db2": db2}return grads
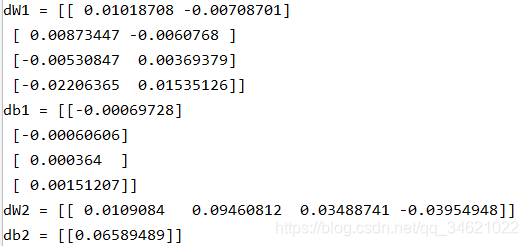
���ô��룺
parameters, cache, X_assess, Y_assess = backward_propagation_test_case()grads = backward_propagation(parameters, cache, X_assess, Y_assess)print("dW1 = " + str(grads["dW1"]))print("db1 = " + str(grads["db1"]))print("dW2 = " + str(grads["dW2"]))print("db2 = " + str(grads["db2"]))
������
4.���²���
���������Ѿ��õ���dW1,dW2,db1,db2��ֵ�����ǿ���ʹ����Щ�����ݶ��½������в������¡�
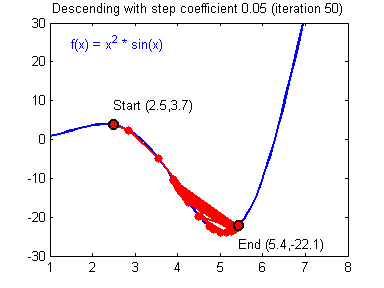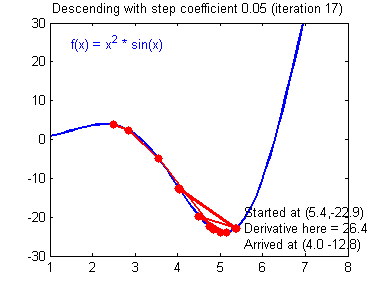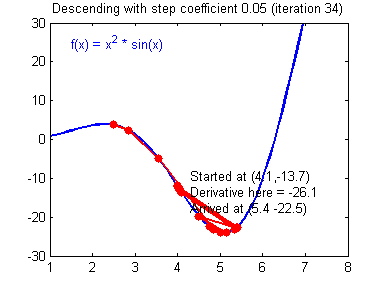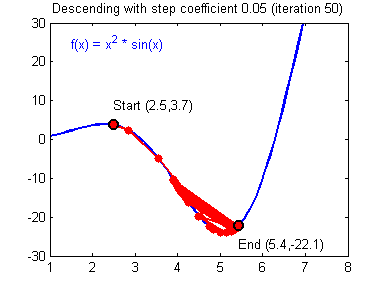
һ������ݶȸ��µĹ�ʽ:��=��?����J����\theta =\theta -\alpha{\alpha J\over\alpha\theta}��=��?��������J?��������\alpha����ѧϰ�ʣ���\theta���Dz�����
�ݶ��½��㷨�������õ�ѧϰ����(����)�ͽϲ��ѧϰ����(��ɢ)��ͼƬ��Adam Harley�ṩ��
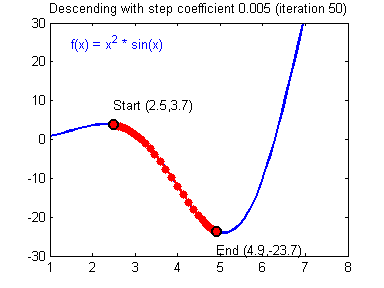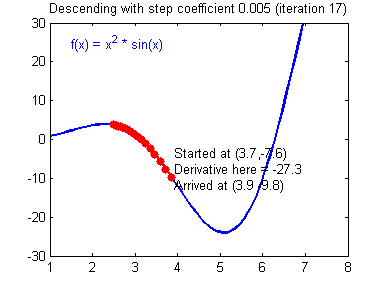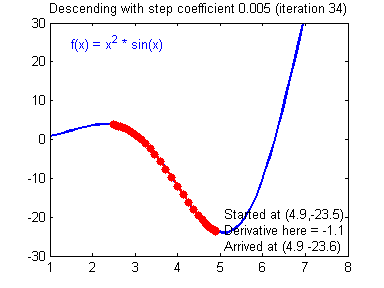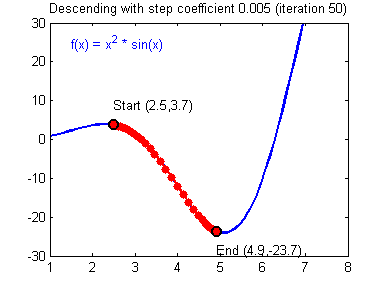
����ʵ�֣�
def update_parameters(parameters, grads, learning_rate = 1.2):W1 = parameters['W1']b1 = parameters['b1']W2 = parameters['W2']b2 = parameters['b2']dW1 = grads['dW1']db1 = grads['db1']dW2 = grads['dW2']db2 = grads['db2']W1 = W1 - learning_rate * dW1b1 = b1 - learning_rate * db1W2 = W2 - learning_rate * dW2b2 = b2 - learning_rate * db2parameters = {
"W1": W1,"b1": b1,"W2": W2,"b2": b2}return parameters
���ԣ�
parameters, grads = update_parameters_test_case()parameters = update_parameters(parameters, grads)print("W1 = " + str(parameters["W1"]))print("b1 = " + str(parameters["b1"]))print("W2 = " + str(parameters["W2"]))print("b2 = " + str(parameters["b2"]))
������
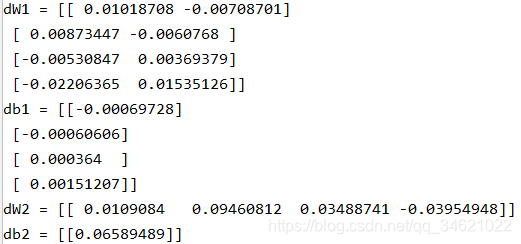
���������Ѹ������˲�����ʵ�������Ǹ�����IJ������ܲ��������Ų�����������Ҫ��ε�����ָ������һ�������������������������Եĵõ����Ų��������������Ǿͽ�������������������
5.������������
ʵ�ִ��룺
def nn_model(X, Y, n_h, num_iterations = 10000, print_cost = False):#1.��ø��㵥Ԫ����np.random.seed(3)n_x, nh, n_y = layer_sizes(X, Y)#2.��ʼ������parameters = initiallize_parameters(n_x, n_h, n_y)W1 = parameters['W1']b1 = parameters['b1']W2 = parameters['W2']b2 = parameters['b2']#3.ѭ��ʵ�������������i = 0while i < num_iterations:i+=1print(i)#1.ǰ��A2, cache = forward_propagation(X, parameters)#2.�������cost = compute_cost(A2, Y, parameters)#3.����grads = backward_propagation(parameters, cache, X, Y)#4.���²���parameters = update_parameters(parameters, grads)if print_cost and i % 1000 == 0:print("��%i�μ���õ��Ĵ���Ϊ��%f." %(i, cost))return parameters
���ԣ�
X_assess, Y_assess = nn_model_test_case()parameters = nn_model(X_assess, Y_assess, 4, num_iterations = 10000, print_cost=False)print("W1 = " + str(parameters["W1"]))print("b1 = " + str(parameters["b1"]))print("W2 = " + str(parameters["W2"]))print("b2 = " + str(parameters["b2"]))
������

6.Ԥ��
���������ǾͿ��Թ�������������ģ�͵�Ԥ���ˡ�
yprediction(i)y^{(i)}_{prediction}yprediction(i)? = {0,a[2](i)>0.51\begin{cases}0, a^{[2](i)} > 0.5 \\ 1 \end{cases}{
0,a[2](i)>0.51?
���룺
def predict(parameters, X):A2, cache = forward_propagation(X, parameters)#���ظ�����x����������ֵ��>0.5Ϊ1 <=0.5Ϊ0predict_result = np.round(A2)return predict_result���ԣ�
parameters, X_assess = predict_test_case()predictions = predict(parameters, X_assess)print("predictions mean = " + str(np.mean(predictions)))
������

7. ��������ģ�Ͳ鿴�����
���룺
X, Y = planar_utils.load_planar_dataset()parameters = nn_model(X, Y, 4, 1000, print_cost=True)plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)plt.title("Decision Boundary for hidden layer size " + str(4))
������
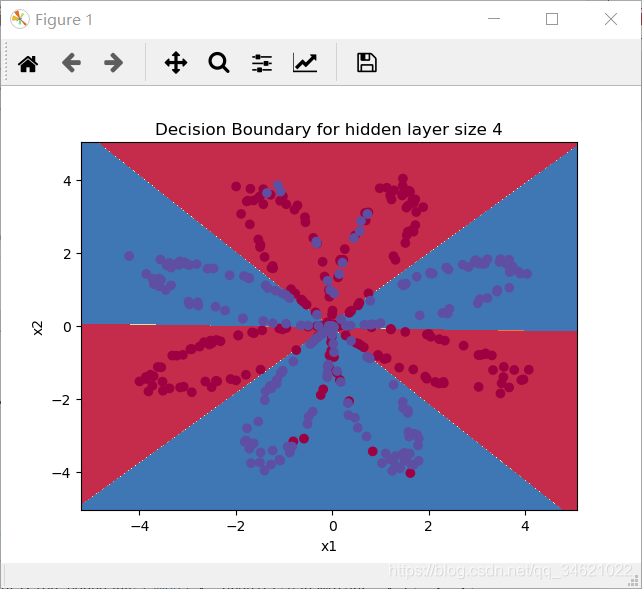
�Ա�һ��ʼ����ʹ�����ع�ģ�ͽ��л��֣����ڵĽ�������������ع�ģ�͵ķ�������
7. ���㾫��
���룺
predictions = predict(parameters, X)print('Accuracy: %d' % float((np.dot(Y, predictions.T) + np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100) + '%')
������

8. ���Բ�ͬ���ز㵥Ԫ���µ�Ԥ�⾫��
���룺
������

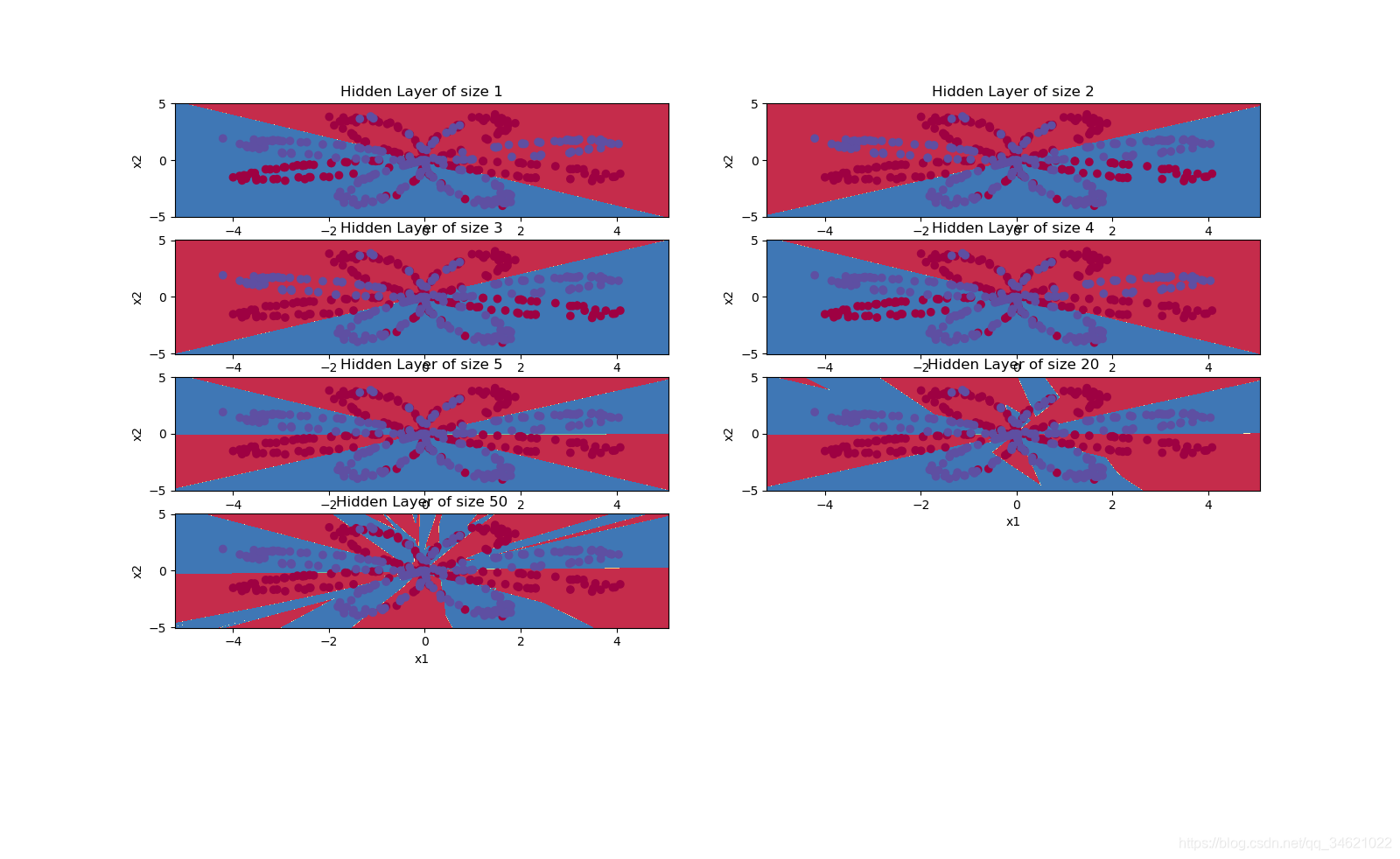
�ӽ����������������������ز�����Ϊ5��õ���ߵ�Ԥ���ʡ�
ͬʱ����Ҳ���Ըı�ѧϰ�ʣ��������յĽ����
7. �����������ݼ�
���룺
noisy_circles, noisy_moons, blobs, gaussian_quantiles, no_structure = load_extra_datasets()datasets = {
"noisy_circles": noisy_circles,"noisy_moons": noisy_moons,"blobs": blobs,"gaussian_quantiles": gaussian_quantiles}dataset = "noisy_moons"X, Y = datasets[dataset]print(X.shape)print(Y.shape)X, Y = X.T, Y.reshape(1, Y.shape[0])if dataset == "blobs":Y = Y % 2plt.scatter(X[0, :], X[1, :], c=np.squeeze(Y), s=40, cmap=plt.cm.Spectral)parameters = nn_model(X, Y, n_h=5, num_iterations=5000)plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)predictions = predict(parameters, X)print('Accuracy: %d' % float((np.dot(Y, predictions.T) + np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100) + '%')
������

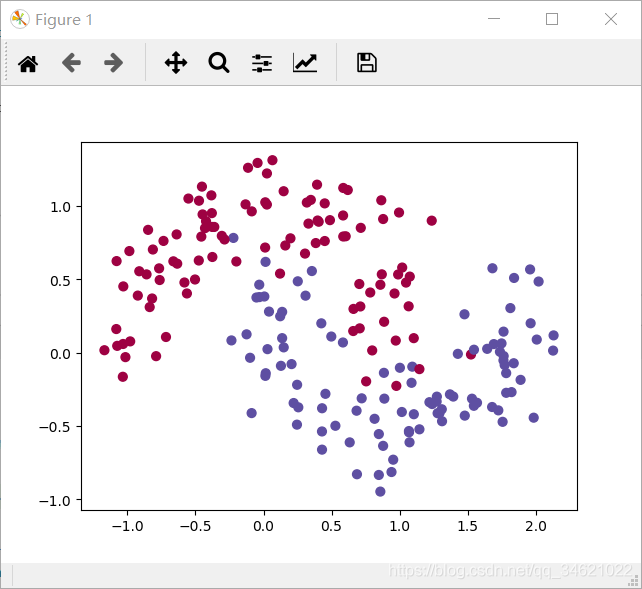
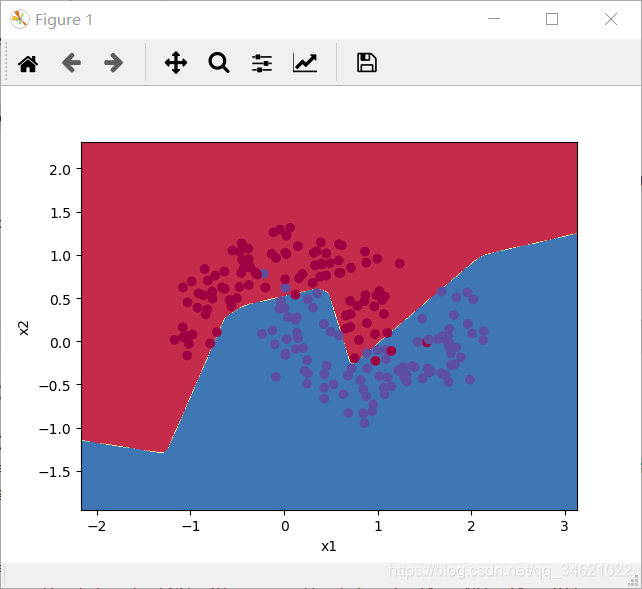
��ҿ����Լ��ٽ���ѧϰ�ʻ����ز㵥Ԫ������ز����ĵ�����
Reference��https://github.com/Kulbear/deep-learning-coursera/blob