ImageNet Classification with Deep Convolutional Neural Networks
1. ТлЮФзлЪі
1.БГОА
- вЛАуЮвУЧЯыЬсЩ§бЕСЗФЃаЭЕФадФмЪБЛсЯыЕНЪЙгУДѓЕФЪ§ОнМЏЃЌЯждкКмЖрДѓаЭЪ§ОнМЏЕФГіЯжНтОіСЫЪ§ОнМЏНЯаЁЕФЮЪЬтЃЌЕЋЪЧвЊДгЪ§АйЭђЕФЭМЯёжабЇЯАЪ§ЧЇИіРрБ№ашвЊОпгаЧПДѓбЇЯАФмСІЕФФЃаЭЁЃЖјЧвЮяЬхЪЖБ№ЕФИДдгадЪЙЕУМДЪЙЪЧЪЙгУЯёImageNetетбљДѓЕФЪ§ОнМЏвВВЛФмНтОіЃЌашвЊИќЖрЕФЯШбщжЊЪЖРДУжВЙЪ§ОнМЏВЛзуЕФЮЪЬтЁЃОэЛ§ЩёОЭјТчЕФШнСППЩвдЭЈЙ§ЩюЖШКЭПэЖШРДПижЦЃЌФмЙЛЖдЭМЯёЕФаджЪзіГізМШЗЖјШЋУцЕФМйЩшЁЃ
- ЫфШЛCNNФЃаЭЕФОжВПНсЙЙЕФаЇТЪНЯИпЃЌЕЋНЋЫќУЧДѓЙцФЃгІгУгкИпЗжБцТЪЭМЯёЪБШдШЛЯдЕУЗЧГЃАКЙѓЃЌЕБЧАЕФGPUПЩвдгУгкИпЖШгХЛЏЕФЖўЮЌОэЛ§ЃЌФмЙЛМгЫйCNNЕФбЕСЗЃЌЧвзюНќЪ§ОнМЏАќКЌзуЙЛЖрЕФБъМЧбљБОРДбЕСЗДЫФЃаЭЃЌВЛЛсГіЯжбЯжиЕФЙ§ЖШФтКЯЁЃ
2.ФЃаЭЗНЗЈ
ЮЊСЫМђЛЏЪЕбщЃЌУЛгаЪЙгУШЮКЮЮоМрЖНЕФдЄбЕСЗЗНЗЈЃЌдкгІгУЪБПЩвдЪЙгУЁЃ
- НЈСЂЕФОэЛ§ЩёОЭјТчОпга6000ЭђИіВЮЪ§КЭ650000ИіЩёОдЊЃЌгаЮхВуОэЛ§ВуЃЌУПИіОэЛ§ВуКѓИњзХГиЛЏВуЃЌШ§ИіШЋСЌНгВуЃЌзюКѓга1000ИіsoftmaxЪфГіЁЃФЃаЭдкСНПщGTX 580 3GB GPUЩЯЛЈЗб5~6ЬьРДбЕСЗЁЃ
- ЮЊСЫМгПьбЕСЗЪЙгУСЫЗЧБЅКЭЩёОдЊКЭИпаЇЕФGPUЁЃ
- ЮЊСЫНтОіШЋСЌНгВужаЕФЙ§ФтКЯЪЙгУdropoutе§дђЛЏЗНЗЈЁЃ
3.ФЃаЭаЇЙћ
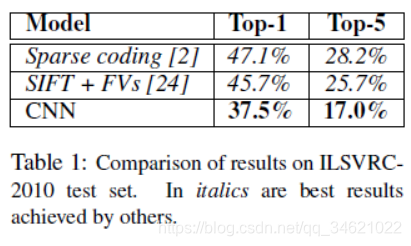
- НЋImageNet LSVRC-2010ЕФБШШќжаЕФ120ЭђеХИпЗжБцТЪЭМЯёЗжЮЊ1000ИіВЛЭЌЕФРрБ№ЃЌВтЪдЪ§ОнЩЯШЁЕУСЫ37.5%КЭ17.0%ЕФtop-1КЭtop-5ЕФДэЮѓТЪЁЃ
- дкILSVRC-2012ЕФБШШќжаЪЙгУетИіФЃЪНЕФвЛИіБфжжЃЌШЁЕУСЫ15.3%ЕФtop-5ЕФВтЪдЪЇЮѓТЪЃЌ26.2%top-1ЕФДэЮѓТЪЁЃ
- БраДСЫвЛИіИпЖШгХЛЏЕФЖўЮЌОэЛ§ЕФGPUЪЕЯжЦфЫћбЕСЗОэЛ§ЩёОЭјТчЙЬгаЕФВйзїЁЃ
ЃЈtop-5ДэЮѓТЪЪЧВтЪдЭМЯёЕФвЛВПЗжЃЌЦфжае§ШЗЕФБъЧЉВЛдкФЃаЭШЯЮЊзюПЩФмЕФЮхИіБъЧЉжаЁЃЃЉ - ШчЙћвЦГ§ШЮКЮвЛИіОэЛ§ВуЃЌЭјТчЕФадФмОЭЛсЯТНЕЁЃР§ШчЃЌЩОГ§ШЮКЮжаМфВуЕФНсЙћЛсЕМжТЭјТчадФмЕФtop-1ДэЮѓТЪЯТНЕ2%ЁЃ
4.ЯТвЛВНМЦЛЎ
ДђЫуЖдЪгЦЕађСаЪЙгУЗЧГЃДѓЕФЩюЖШОэЛ§ЩёОЭјТчЃЌЦфжаЪБМфНсЙЙЬсЙЉСЫЗЧГЃгагУЕФаХЯЂЃЌетаЉаХЯЂЭљЭљдкОВЬЌЭМЯёжаЖЊЪЇСЫЃЌЛђепЫЕВЛЬЋУїЯдЁЃ
2. ЪЕбщЗНЗЈ
2.1 Ъ§ОнМЏ
ImageNetжаЭМЯёЕФЗжБцТЪЪЧВЛвЛбљЕФЃЌЕЋЪЧФЃаЭашвЊЪфШыЙЬЖЈЕФГпДчЃЌВЩгУЯТВЩбљЗНЗЈНЋЪфШыГпДчБфЮЊСЫ256*256ЁЃГ§СЫНЋУПИіЯёЫиМѕШЅбЕСЗМЏЕФЯёЫиЦНОљжЕЭтЃЌУЛгазіЦфЫћДІРэЁЃ
2.2 ФЃаЭНсЙЙ
ЮхИіОэЛ§ВуЁЂШ§ИіШЋСЌНгВуЁЃ
2.2.1 ReluЗЧЯпадКЏЪ§
дкТлЮФжаНЋsigmoidКЏЪ§КЭtanhКЏЪ§ГЦЮЊsaturating nonlinearitiesЃЌНЋreluГЦЮЊnon-saturating nonlinearityКЏЪ§ЃЌЮФеТЬсЕНЪЙгУsaturating nonlinearitiesКЏЪ§БШЪЙгУnon-saturating nonlinearityКЏЪ§ЬнЖШЯТНЕЫйЖШвЊТ§ЁЃNairКЭHintonНЋnonlinearityГЦЮЊRectified Linear Units(Relu)ЁЃ
ДгЭМжаПЩвдПДГіЪЙгУreluМЄЛюКЏЪ§БШЪЙгУtanhМЄЛюКЏЪ§вЊПь6БЖЁЃ

2.2.2 дкЖрGPUЩЯбЕСЗ
ЮФеТЬсЕНБОЮФбЕСЗЕФЭјТчЪЧЗХдкСНИіGPUЩЯдЫааЕФЃЌвЛИіGPUЩЯЗХжУвЛАыЕФЩёОдЊЃЌЛЙгавЛИіММЧЩЪЧЃКЪЙGPUжЛдкЬиЖЈЕФВужаЭЈаХЃЌБШШчЕк3ВуЕФФкКЫДгЕк2ВуЕФЫљгаФкКЫгГЩфжаЛёШЁЪфШыЁЃШЛЖјЃЌЕк4ВуЕФФкКЫжЛНгЪмЮЛгкЭЌвЛGPUЩЯЕФЕк3ВуФкКЫгГЩфЕФЪфШыЁЃвђДЫбЁдёСЌНгФЃЪНЖдгкНЛВцбщжЄБШНЯживЊЁЃ
етжжЗНЪННЋtop-1КЭtop-5ЕФДэЮѓТЪЗжБ№МѕЩйСЫ1.7%КЭ1.2%ЁЃВЂдквЛЖЈГЬЖШЩЯМѕЩйСЫдЫааЪБМфЁЃ
2.2.3 ОжВПЯьгІЙщвЛЛЏ Local Response Normalization
ЫфШЛreluКЏЪ§ВЛашвЊЖдЪфШыЪ§ОнНјааБъзМЛЏВйзїЃЌЕЋЪЧОжВПе§ЙцЛЏЗНАИгажњгкЗКЛЏЁЃ
МЦЫуЙЋЪНЃК
bx,yi=ax,yi(k+aЁЦj=max(0,i?n/2)min(N?1,i+n/2)(ax,yj)2)ІТb_{x,y}^i = \frac{a_{x,y}^i}{(k + a\sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)}(a_{x,y}^j)^2)^{\beta}}bx,yi?=(k+aЁЦj=max(0,i?n/2)min(N?1,i+n/2)?(ax,yj?)2)ІТax,yi??
Цфжаax,yia_{x,y}^iax,yi?БэЪОЕкiiiИіФкКЫМЦЫуЮЛжУ(x,y)(x,y)(x,y)ДІЕФReluЗЧЯпадЕЅдЊЕФЪфГіЃЌbx,yib_{x,y}^ibx,yi?БэЪОЯьгІЙщвЛЛЏКѓЕФЪфГіжЕЁЃ
nnnБэЪОЭЌвЛЮЛжУЯТгыИУЮЛжУЯрСкЕФФкКЫгГЩфЕФЪ§СПЁЃNNNБэЪОетвЛВужаФкКЫЕФзмЪ§СПЁЃетжжЯьгІЙщвЛЛЏЪЕЯжСЫвдвЛжжФЃЗТецЪЧЩёОдЊЕФКсЯђвЛжТЃЌДгЖјдкЪЙгУВЛЭЌФкКЫМЦЫуЕФЩёОдЊЪфГіжЎМфВњЩњНЯДѓЕФОКељЁЃГЃЪ§kЁЂnЁЂaКЭІТkЁЂnЁЂaКЭ\betakЁЂnЁЂaКЭІТЖМЪєгкГЌВЮЪ§ЃЌЫќУЧЕФжЕШЁОігкЪЙгУЕФбщжЄЛњЃЛЮвУЧЪЙгУЕФЩшжУЪЧЃКk=2,n=5,a=10?4,ІТ=0.75k=2,n=5,a=10^{-4},\beta = 0.75k=2,n=5,a=10?4,ІТ=0.75ЁЃдкФГаЉВужагІгУReluКѓдйЪЙгУетжжЙщвЛЛЏЗНЗЈЁЃ
ЮФеТЬсЕНвђЮЊУЛгаМѕШЅОљжЕЃЌвђДЫетИіЗНЗЈГЦЮЊЁАССЖШЙщвЛЛЏЁБ(brightness normalization)ЁЃ
ЯьгІЙщвЛЛЏНЋtop-1КЭtop-5ЕФДэЮѓТЪНЕЕЭСЫ1.4%КЭ1.2%ЁЃ
2.2.4 жиЕўГиЛЏ Overlapping Pooling
ДЋЭГЗНЗЈжаЯрСкЕЅдЊжЎМфЛЅВЛжиЕўЁЃГиЛЏВуБЛШЯЮЊЪЧгЩвЛаЉМфИєЮЊsИіЯёЫиЕФГиЛЏЕЅдЊзщГЩЕФЭјТчЃЌЃЌУПИіЖМБэЪОвЛИівдГиЛЏЕЅдЊЮЛжУЮЊжааФЕФДѓаЁЮЊz?zz*zz?zЕФЧјгђЁЃ
- ЕБs<zs<zs<zЪБЃЌЕУЕНЕФЪЧжиЕўГиЛЏЁЃ
- ЕБs=zs=zs=zЪБЃЌЕУЕНЕФЪЧДЋЭГГиЛЏВуЁЃ
ЮФеТжаФЃаЭЪЙгУЕФЪЧжиЕўГиЛЏ(s=2,z=3s=2,z=3s=2,z=3)ЃЌНЋДэЮѓТЪtop-1КЭtop-5ЗжБ№МѕаЁСЫ0.4%КЭ0.3%ЁЃ
ЮФеТЬсГіЃЌдкбЕСЗФЃаЭЪБЙлВьЕНЪЙгУжиЕўГиФЃаЭЛсНЕЕЭЙ§ФтКЯЕФИХТЪЁЃ
2.2.5 ећЬхНсЙЙ
CNNећЬхЛњМмЙЙЭМЃК
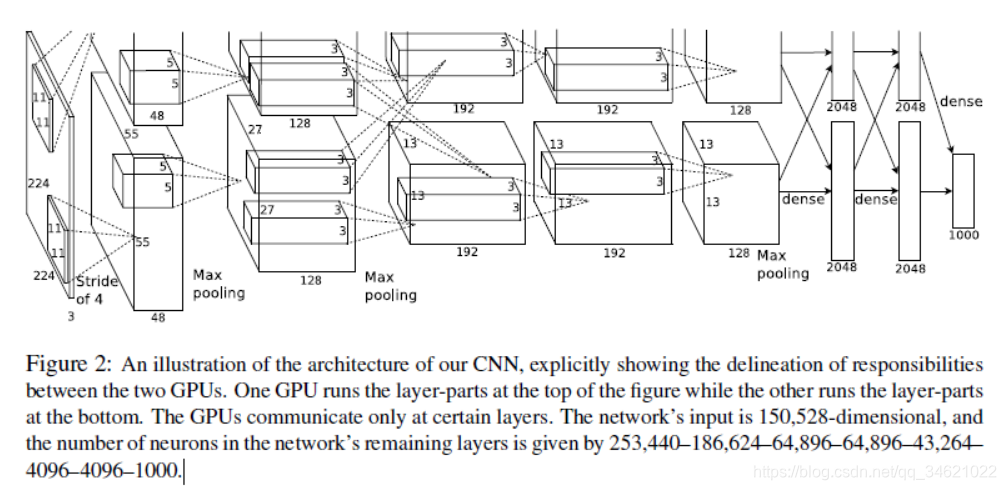
ИУЭјТчАќКЌ8ИіДјШЈжиЕФжЕЃЌЧА5ИіЪЧОэЛ§ЕФЃЌЦфгрШ§ИіЪЧЭъШЋСЌНгЕФЁЃзюКѓвЛИіШЋСЌНгВуЕФЪфГіБЛЗДРЁЕНвЛИіsoftmaxВуЃЌВњЩњГЌЙ§1000жаЗжРрБъЧЉЁЃ
ЮФеТЬсЕНЦфЭјТчзюДѓЛЏСЫЖрЯюЪНТпМЛиЙщФПБъЃЌетЯрЕБгкзюДѓЛЏСЫдЄВтЗжВМЯТе§ШЗБъЧЉЕФЖдЪ§ИХТЪЕФбЕСЗЧщаЮЕФЦНОљжЕЁЃ(ЮвРэНтЕФЪЧЪЙгУСЫзюДѓГиЛЏВуЃЌзюКѓЕУЕНЕФдЄВтНсЙћЛсДѓвЛаЉЁЃ)
ЕкЖўВуЁЂЕкЫФВуКЭЕкЮхВуОэЛ§ВуЕФФкКЫжЛСЌНгЕНЩЯвЛВузЄСєдкЭЌвЛGPUЩЯЕФФкКЫгГЩф(МћЭМ2)ЃЌЕкШ§ВуОэЛ§ВуЕФФкКЫСЌНгЕНЕкЖўВуЕФЫљгаФкКЫгГЩфЁЃШЋСЌНгВуЕФЩёОдЊгыЧАвЛВуЕФЫљгаЩёОдЊЯрСЌЁЃЯьгІЙцЗЖЛЏВудкЕквЛКЭЕкЖўОэЛ§ВужЎКѓЁЃ
ЕквЛИіОэЛ§ВуЕФЪфШыЮЊ224ЁС224ЁС3ЕФЭМЯёЃЌЖдЦфЪЙгУ96ИіДѓаЁЮЊ11ЁС11ЁС3ЁЂВНГЄЮЊ4ЃЈВНГЄБэЪОФкКЫгГЩфжаЯрСкЩёОдЊИаЪмвАжааФжЎМфЕФОрРыЃЉЕФФкКЫРДДІРэЪфШыЭМЯёЁЃЕкЖўИіОэЛ§ВуНЋЕквЛИіОэЛ§ВуЕФЪфГіЃЈЯьгІЙщвЛЛЏвдМАГиЛЏЃЉзїЮЊЪфШыЃЌВЂЪЙгУ256ИіФкКЫДІРэЭМЯёЃЌУПИіФкКЫДѓаЁЮЊ5ЁС5ЁС48ЁЃЕкШ§ИіЁЂЕкЫФИіКЭЕкЮхИіОэЛ§ВуБЫДЫСЌНгЖјжаМфУЛгаШЮКЮГиЛЏЛђЙщвЛЛЏВуЁЃЕкШ§ИіОэЛ§Вуга384ИіФкКЫЃЌУПИіЕФДѓаЁЮЊ3ЁС3ЁС256ЃЌЦфЪфШыЮЊЕкЖўИіОэЛ§ВуЕФЪфГіЁЃЕкЫФИіОэЛ§Вуга384ИіФкКЫЃЌУПИіФкКЫДѓаЁЮЊ3ЁС3ЁС192ЁЃЕкЮхИіОэЛ§Вуга256ИіФкКЫЃЌУПИіФкКЫДѓаЁЮЊ3ЁС3ЁС192ЁЃШЋСЌНгВуИїга4096ИіЩёОдЊЁЃ
2.3 МѕЩйЙ§ФтКЯ
2.3.1 РЉдіЪ§Он Data Augmentation
ЮФеТЬсЕНЦфЪЙгУЕФСНжжЪ§ОнРЉГфЗНЗЈЖМЪЙгУКмаЁЕФМЦЫуДњМлОЭПЩвдЪЙдЪМЭМЯёЩњГЩзЊЛЛКѓЕФЭМЯёЃЌзЊЛЛКѓЕФЭМЯёВЛашвЊДцдкДХХЬЩЯЃЌвђЮЊПЩвдвЛБпЪЙгУpythonдкCPUЩЯзЊЛЛЃЌвЛБпдкGPUЩЯЖдЭМЯёНјаабЕСЗЁЃ
- аЮЪНвЛЃКЭМЯёЦНвЦКЭЫЎЦНЗзЊЃКОЁЙметбљВњЩњЕФбЕСЗЪ§ОнЪЙИпЖШЯрЙиЕФЃЌЕЋЪЧдкКмДѓГЬЖШЩЯНтОіСЫбЯжиЕФЙ§ФтКЯЮЪЬтЁЃ
- аЮЪНЖўЃКЕкЖўжжаЮЪНЕФЪ§ОндіЧПИФБфбЕСЗЭМЯёжаRGBЭЈЕРЕФЧПЖШЃЌОЭЪЧдкећИіImageNetбЕСЗМЏЕФЭМЯёЕФRGBЯёЫижЕЩЯЪЙгУPCAЁЃЖдгкУПИібЕСЗЭМЯёЃЌЮвУЧНЋевЕНЕФжїГЩЗжЕФБЖЪ§ЯрМгЃЌгыЯргІЕФЬиеїжЕГЩБШР§ЕФФЃСПГЫвдвЛИіЫцЛњБфСПЃЌИУЫцЛњБфСПРДздвЛИіОљжЕЮЊ0ЁЂБъзМВюЮЊ0.1ЕФИпЫЙЗжВМЁЃЖдгкУПИіRGBЭМЯёЯёЫи[IxyR,IxyG,IxyB]T[I_{xy}^R,I_{xy}^G,I_{xy}^B]^T[IxyR?,IxyG?,IxyB?]TЃЌЮвУЧЬэМгЯТУцЕШЪНЕФжЕЃК
[p1,p2,p3][a1ІЫ1,a2ІЫ2,a3ІЫ3][p_1,p_2,p_3][a_1\lambda_1,a_2\lambda_2,a_3\lambda_3][p1?,p2?,p3?][a1?ІЫ1?,a2?ІЫ2?,a3?ІЫ3?]
pip_ipi?КЭІЫi\lambda_iІЫi?ЗжБ№ЪЧ3x3ЕФRGBаЗНВюОиеѓЕФЕкiiiИіЬиеїЯђСПКЭЕкiiiИіЕФЬиеїжЕЃЌЖјaia_iai?ЪЧЧАУцЫљЫЕЕФЫцЛњжЕЁЃЖдгквЛеХЬиЖЈЭМЯёжаЕФЫљгаЯёЫиЃЌУПИіaia_iai?жЛЛсБЛГщШЁвЛДЮЃЌжЊЕРетеХЭМЦЌдйДЮгУгкбЕСЗЪБЃЌВХЛсжиаТЬсШЁЫцЛњБфСПЁЃетИіЗНАИНќЫЦЕиВЖзНдЪМЭМЯёЕФвЛаЉживЊЪєадЃЌЖдЯѓЕФЩэЗнВЛЪмЙтееЕФЧПЖШКЭбеЩЋБфЛЏгАЯьЁЃ етИіЗНАИНЋtop-1ДэЮѓТЪНЕЕЭСЫ1ЃЅвдЩЯЁЃ
2.3.2 Dropout
НЋУПИіЩёОдЊЖЊЦњЕФИХТЪЩшжУЮЊ0.5ЃЌвдетжжЗНЪНЖЊЦњЕФЩёОдЊВЛВЮгые§ЯђДЋЕнЃЌвВВЛВЮгыЗДЯђДЋВЅЁЃУПДЮгаЪфШыЪБЩёОЭјТчЖМЛсгаВЛЭЌЕФНсЙЙЃЌЕЋЪЧетаЉНсЙЙЖМШЈжиЙВЯэЁЃдкВтЪдЪБЪЙгУЫљгаЩёОдЊВЂНЋЫќУЧЕФЪфГіЖМГЫвд0.5.ЁЃЃЈЮвМЧЕУЪЧдкбЕСЗЪБНЋМЄЛюжЕГ§вд0.5ЃЌетОфЛАвтЫМЪЧВЛЪЧКЭетИівЛбљЃЌЛЙЪЧЮвЕФМЧвфгаЮѓЃЉ
2.4 бЇЯАЯИНк
ЮвУЧЪЙгУЫцЛњЬнЖШЯТНЕбЕСЗЮвУЧЕФФЃаЭЃЌХњСПДѓаЁЮЊ128ИібљБОЃЌЖЏСПЮЊ0.9ЃЌжиСПЫЅМѕЮЊ0.0005ЁЃЮвУЧЗЂЯжетвЛаЁВПЗжЕФжиСПЫЅМѕЖдФЃаЭЕФбЇЯАКмживЊЁЃЛЛОфЛАЫЕЃЌетРяЕФжиСПЫЅМѕВЛНіНіЪЧвЛИіе§дђЛЏЦї:ЫќМѕЩйСЫФЃаЭЕФбЕСЗЮѓВюЁЃШЈжЕwЕФИќаТЙцдђЪЧЃК
vi+1:=0.9?vi?0.0005???wi???(ІСLІСw)Div_{i+1} := 0.9 \cdot v_i - 0.0005\cdot\epsilon\cdot w_i - \epsilon\cdot(\frac{\alpha L}{\alpha w})_{D_i}vi+1?:=0.9?vi??0.0005???wi????(ІСwІСL?)Di??wi+1:=wi+vi+1w_{i+1}:=w_i + v_{i+1}wi+1?:=wi?+vi+1?
ЦфжаiiiБэЪОЕБЧАЕќДњДЮЪ§ЃЌvvvБэЪОЖЏСП(momentum)ЃЌ?\epsilon?БэЪОбЇЯАТЪЃЌ(ІСLІСw)Di(\frac{\alpha L}{\alpha w})_{D_i}(ІСwІСL?)Di??БэЪОЕкiiiХњДЮDiD_iDi?ЕФФПБъКЏЪ§ЙигкwwwЕФЕМЪ§ЕФЦНОљжЕЁЃ
ГѕЪМЛЏУПвЛВуШЈжЕЃЌГѕЪМЛЏКѓЕФШЋжАЮЊСуОљжЕИпЫЙЗжВМЃЌБъзМВюЮЊ0.01ЁЃЕкЖўВуЁЂЕкЫФВуКЭЕкЮхВуОэЛ§ВувдМАШЋСЌЭЈвўВиВужаГѕЪМЛЏЩёОдЊЦЋВюЮЊГЃЪ§1ЃЌгУГЃЪ§0ГѕЪМЛЏЪЃгрВужаЕФЩёОдЊЦЋВюЁЃЖдЫљгаВуЪЙгУЯрЭЌЕФбЇЯАТЪЃЌВЂдкећИіХрбЕЙ§ГЬжаЪжЖЏЕїећЁЃВЩгУЕФЦєЗЂЪНЗНЗЈЪЧЃЌЕБбщжЄДэЮѓТЪВЛдйЫцзХЕБЧАЕФбЇЯАТЪЬсИпЪБЃЌНЋбЇЯАТЪГ§вд10ЁЃГѕЪМЛЏбЇЯАТЪЮЊ0.01ЃЌжежЙЧАНЕЕЭ3ДЮЁЃЪЕбщепдкСНЬЈNVIDIA GTX 580 3GB gpuЩЯгУСЫ5ЕН6ЬьЕФЪБМфЃЌЭЈЙ§120ЭђеХЭМЯёЕФбЕСЗМЏЃЌЖдЭјТчНјааСЫДѓдМ90ИіжмЦкЕФбЕСЗЁЃ
2.5 НсЙћ
2.
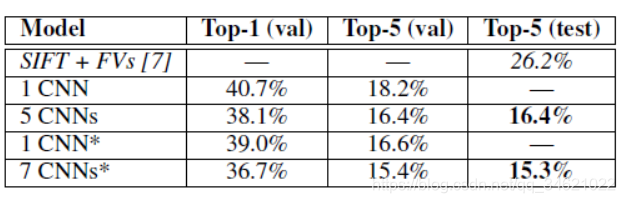
ЮФеТУшЪіЕФCNNЕФtop-5ДэЮѓТЪДяЕНСЫ18.2ЃЅЁЃ
ЖдЮхИіЯрЫЦCNNЕФдЄВтНсЙћМЦЫуОљжЕЃЌЕУЕНЕФДэЮѓТЪЮЊ16.4ЃЅЁЃ
БэИёЕкЫФааЃЌЖдЕЅЖРЕФвЛИіCNNЃЌдкзюКѓвЛИіГиЛЏВужЎКѓЃЌЖюЭтЬэМгЕкСљИіОэЛ§ВуЃЌЖдећИіImageNet Fall 2011 release(15M images, 22K categories)НјааЗжРрЃЌШЛКѓдкILSVRC-2012ЩЯЁАЮЂЕїЁБЃЈfine-tuningЃЉЭјТчЃЌЕУЕНЕФДэЮѓТЪЮЊ16.6ЃЅЁЃ
ЖдећИіImageNet Fall 2011АцБОЕФЪ§ОнМЏЯТдЄбЕСЗЕФСНИіCNNЃЌЧѓЫћУЧЪфГіЕФдЄВтжЕгыЧАУцЬсЕНЕФ5ИіВЛЭЌЕФCNNЪфГіЕФдЄВтжЕЕФОљжЕЃЌЕУЕНЕФДэЮѓТЪЮЊ15.3ЃЅЁЃ
БШШќЕФЕкЖўУћДяЕНСЫ26.2ЃЅЕФtop-5ДэЮѓТЪЃЌЫћУЧЕФЗНЗЈЪЧЃКЖдМИИідкЬиеїШЁбљУмЖШВЛЭЌЕФFisherЯђСПЩЯбЕСЗЕФЗжРрЦїЕФдЄВтНсЙћШЁЦНОљЕФЗНЗЈ
2.5.1 ЖЈадЦРЙР Qualitative Evaluations

ЭМ3ЯдЪОСЫгЩЭјТчЕФСНИіЪ§ОнСЌНгВубЇЯАЕУЕНЕФОэЛ§ФкКЫЁЃИУЭјТчвбОбЇЯАЕНаэЖрЦЕТЪКЭЗНЯђЬсШЁЕФФкКЫЃЌвдМАИїжжЩЋПщЁЃЧызЂвтСНИіGPUЫљеЙЯжЕФВЛЭЌЬиадЃЌетвВЩЯУцНщЩмЕФЯожЦЛЅСЌЕФНсЙћЁЃGPU1ЩЯЕФФкКЫдкКмДѓГЬЖШЩЯгыбеЩЋЮоЙиЃЌШЛЖјGPU2ЩЯЕФФкКЫдкКмДѓГЬЖШЩЯЖМгкбеЩЋгаЙиЁЃетжжЬивьаддкУПДЮЕќДњЦкМфЖМЛсЗЂЩњЃЌВЂЧвЖРСЂгкШЮКЮЬиЖЈЕФЫцЛњШЈжиГѕЪМЛЏЙ§ГЬЃЈвдGPUЕФжиаТБрКХЮЊФЃЃЉЁЃ

дкЭМ4ЕФзѓВрУцАхжаЃЌЭЈЙ§МЦЫу8еХВтЪдЭМЯёЕФtop-5дЄВтРДЖЈадЦРЙРЭјТчЕФбЕСЗНсЙћЁЃЧызЂвтЃЌМДЪЙЪЧЦЋРыжааФЕФЖдЯѓЃЌШчзѓЩЯНЧЕФђ§ГцЃЌвВПЩвдБЛЭјТчЪЖБ№ЁЃЧА5УћжаЕФДѓЖрЪ§ЫЦКѕЖМЪЧКЯРэЕФЁЃР§ШчЃЌжЛгаЦфЫћРраЭЕФУЈБЛШЯЮЊЪЧБЊЕФКЯРэБъЧЉЁЃдкФГаЉЧщПіЯТЭМЦЌжагаЖрИіЮяЬхЃЌБШШчгЃЬвКЭЙЗЃЌЪЙЕУЭМЦЌНЙЕуВЛУїШЗЃЌЛсЕМжТдЄВтДэЮѓЁЃ
СэвЛжжЬНЫїЭјТчЪгОѕжЊЪЖЕФЗНЗЈЪЧПМТЧзюКѓвЛИі4096ЮЌвўВуЭМЯёЕФЬиеїМЄЛюЁЃШчЙћСНЗљЭМЯёВњЩњЕФЬиеїМЄЛюЯђСПОпгааЁЕФХЗЪЯЗжРыЃЌЮвУЧПЩвдЫЕЩёОЭјТчЕФИпВуШЯЮЊЫќУЧЪЧЯрЫЦЕФЁЃ
ЭМ4гвВрЯдЪОСЫРДздВтЪдМЏЕФ5еХЭМЯё(ЕквЛСа)ЃЌвдМАРДздбЕСЗМЏЕФСаЭМЯёЃЌИљОнетИіЖШСПЃЌЫќУЧЪЧзюЯрЫЦЕФЁЃзЂвтЃЌдкЯёЫиМЖБ№ЃЌдкЯёЫиВуДЮЩЯЃЌД§МьВтЕФбЕСЗЭМЯёЭЈГЃВЛЛсгыЕквЛСажаЕФВщбЏЭМЯёгаНЯаЁЕФL2ОрРыЁЃР§ШчЃЌМьЫїЕНЕФЙЗКЭДѓЯѓвдИїжжзЫЪЦГіЯжЁЃЮвУЧдкВЙГфВФСЯжаеЙЪОСЫИќЖрВтЪдЭМЯёЕФНсЙћЁЃЭЈЙ§ЪЙгУХЗЪНОрРыРДМЦЫуСНИі4096ЮЌЪЕжЕЯђСПЕФЯрЫЦадЃЌаЇТЪВЛИпЃЌЕЋЪЧЭЈЙ§бЕСЗздБрТыЦїПЩвдНЋетаЉЯђСПбЙЫѕЮЊНЯЖЬЕФЖўНјжЦТыЃЌФмЙЛЪЙЦфИќИпаЇЁЃгыгІгУздБрТыЦїЕНдЪМЯёЫиЯрБШЃЌетгІИУЪЧИќКУЕФЭМЯёМьЫїЗНЗЈЁЃЫќВЛЪЙгУЭМЯёБъЧЉЃЌвђДЫИќЧуЯђгкМьЫїОпгаЯрЫЦЭМАИБпдЕЕФЭМЯёЃЌВЛЙмЫќУЧЕФЭМЯёгявхЪЧЗёЯрЫЦЁЃ
жЊЪЖЕу
1.ДѓаЭЪ§ОнМЏLabelMe,АќКЌЪ§ЪЎЭђИіЭъШЋЗжИюЕФЭМЯёЃЌImageNetАќКЌГЌЙ§15000ЭђИіГЌЙ§22000ИіРрБ№ЕФИпЗжБцТЪЕФЭМЯёЁЃ
2.ImageNetзмЙВКЌга120еХбЕСЗЭМЯёЃЌЦфжа50000еХбщжЄЭМЯёЃЌ150,000еХВтЪдЭМЯёЁЃ
3.ЪЙгУreluВЛашвЊЮЊСЫЗРжЙЪфШыЪ§ОнБЅКЭЖјЖдЪфШыНјааБъзМЛЏЁЃ
гаЕФЕиЗНТлЮФаДЕФКмКУЃЌЕЃаФздМКБэЪігаЮѓОЭжБНгЗвыСЫЁЃ

