Residual Networks �����
����һ���������ǽ�ѧϰʹ�òв����罨�������ľ������硣�������Ͻ���Խ����������ģ��Խ���Խ�����ӵ����⣬��ʵ����������������ѵ����Residual Networks�DZ�He��������ģ��ܹ�������ѵ����������硣
����һ����������Ҫ��ɵ��ǣ�
- ʵ��ResNets�Ļ��������顣
- ����Щģ�����һ����ʵ�ֺ�ѵ��һ�����Ƚ����������ͼ����ࡣ
- ����������ǽ�����ʹ��Keras��
��Ҫʹ�õİ�:
import numpy as np
from keras import layers
from keras.layers import Input, Add, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D, AveragePooling2D, MaxPooling2D, GlobalMaxPooling2D
from keras.models import Model, load_model
from keras.preprocessing import image
from keras.utils import layer_utils
from keras.utils.data_utils import get_file
from keras.applications.imagenet_utils import preprocess_input
import pydot
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
from Week4.Second.utils.resnets_utils import *
from keras.initializers import glorot_uniform
import scipy.misc
from matplotlib.pyplot import imshowimport keras.backend as K
K.set_image_data_format('channels_last')
K.set_learning_phase(1)
1. ��������������
��Щ������������ģ�͵���Ȳ������������Ƚ�������Ӽ���(��AlexNet)��չ��һ�ٲ����ϡ�
����������Ҫ�ô��������Ա�ʾ�dz����ӵĹ��ܡ���������ѧϰ���ͬ��������ԣ��ӱ�Ե(�ڽϵ͵IJ�)���dz����ӵ�����(�ڽ���IJ�)��Ȼ����ʹ�ø����ε����粢���������õġ���Ϊѵ�����ǵ�һ�����������ݶ���ʧ:�dz��������ͨ����һ�����ٹ�����ݶ��źţ�����ݶ��½����÷dz������������˵,���ݶ��½�����,�����һ�㷴���ص���һ��,ÿһ������Ȩ�ؾ���,�ݶ�ֵ����Ѹ�ٵ�ָ��ʽ���ٵ�0�������ں����������,�ɱ�����Ѹ��,�����ݶȱ�ը��
��ѵ�������У����ǻῴ����ʼ������ݶ�Ѹ���½�����������ͼ��ʾ��
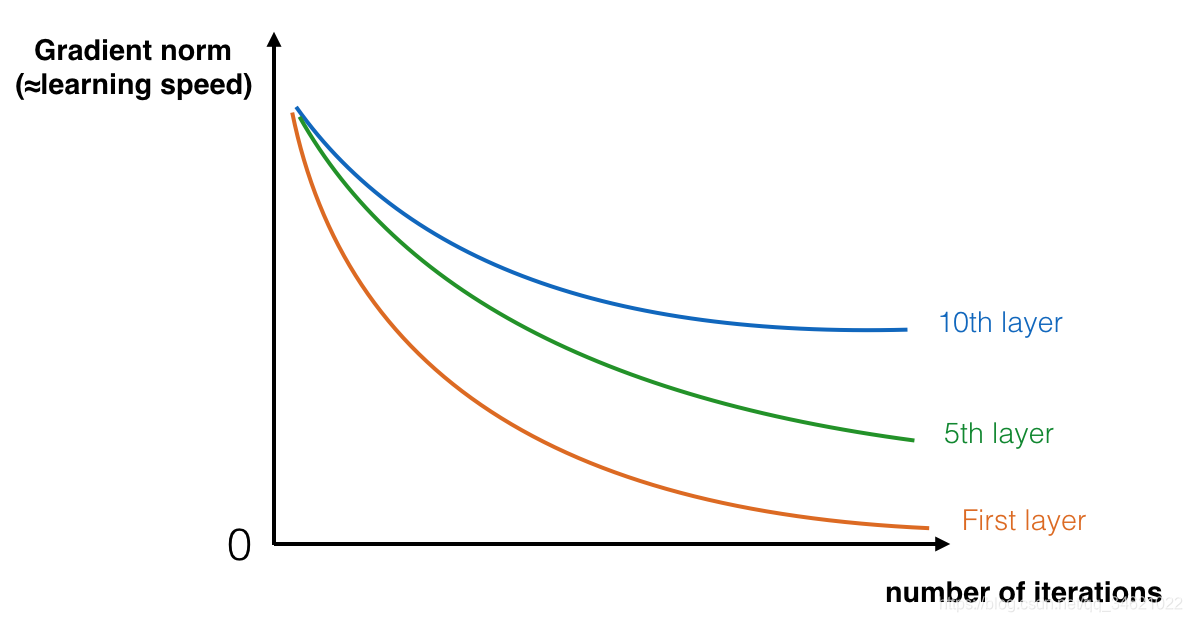
Ϊ�˽��������⣬���ǹ����в����硣
2. ����һ���в�����
�ڲв������У������ݶ�ֱ�ӷ�������dz�IJ㣬Ҳ��Ϊ����Ծ���ӡ�������ͼ��

��ߵ�ͼ����ʾ��ͨ������ġ���·�������ұߵ�ͼ������·��������һ������ݡ�·����ͨ������ЩResNet��ѵ���һ�𣬿����γ�һ���dz�������硣
�ڿγ�������ѧϰ�����нݾ���ResNetģ�������ѧϰ��һ����Ⱥ���������ζ�����ǿ����ڲ���ѵ�������ܣ����սϵ͵�����¶�������ResNet�顣��һЩ֤�ݱ���ѧϰһ����Ⱥ������������������ݶ���ʧ�����Ӹ���Ч��
��ResNet����Ҫʹ���������͵Ŀ飬��Ҫȡ��������/���ά������ͬ�Ļ��Dz�ͬ�ģ����������Ƕ�Ҫʵ�֡�
2.1 ��ȿ�(The identity block)
��ȿ����ڲв�������ʹ�õı��飬��Ӧ�����뼤��(a[l]a^{[l]}a[l])���������(a[l+2]a^{[l+2]}a[l+2])����ͬ��ά����Ϊ�˾��в������б���IJ�ͬ���裬������һ��ͼ��չʾ��
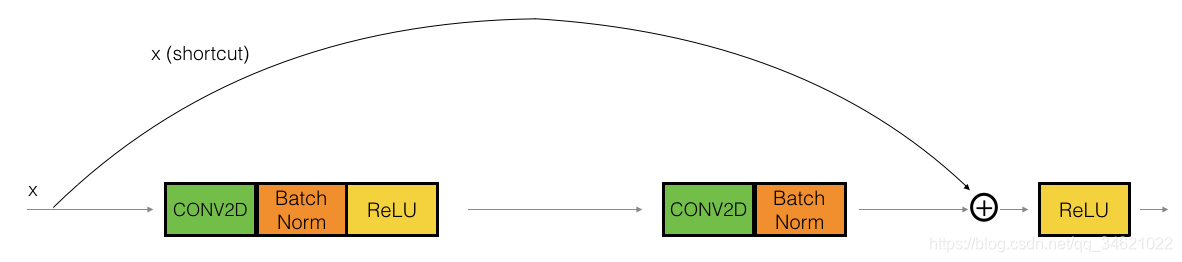
ͼƬ�������·�����dz�Ϊ�����·�����������·����Ϊ��·���������ͼ������Ҳ��ȷ��ÿ����CONV2D��RELU�IJ��衣Ϊ�˼ӿ�ѵ���ٶȣ����ǻ�������һ��BatchNorm���衣BatchNorm��Keras��ֻ��һ�д���Ϳ���ʵ�֡�
�������ϰ�У��㽫ʵ��һ�����Ǹ�ǿ��İ汾��ֱ��Խ���������ز㣬����ͼ��ʾ��
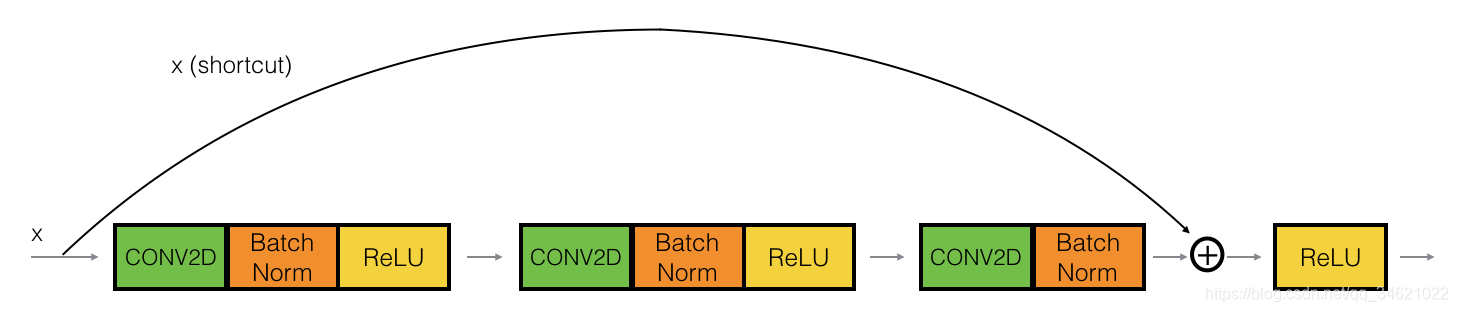
��·����һ����ɲ��֣�
- ��һ��Conv2D:������F1��ά��Ϊ(1��1)������Ϊ(1��1)��padding��valid����������Ӧ����conv_name_base+��2a����ʹ��0��Ϊ�����ʼ�������ӡ�
- ��һ��BatchNorm�Ƕ�ͨ������й�һ������������Ӧ����bn_name_base + ��2a����
- Ȼ��ʹ��ReLU���������û�����ƣ�Ҳû�г�������
��·���ڶ�����ɲ��֣�
- �ڶ���Conv2D��������F2��ά��Ϊ(f��f)������Ϊ(1��1)��paddingΪ����same������������Ӧ����conv_name_base+��2b����ʹ��0��Ϊ�����ʼ�������ӡ�
- �ڶ���BatchNorm�Ƕ�ͨ������й�һ������������Ӧ����bn_name_base + ��2b��
- Ȼ��ʹ��ReLU���������û�����ƣ�Ҳû�г�������
��·���ĵ�������ɲ��֣�
- ������Conv2D:������F1��ά��Ϊ(1��1)������Ϊ(1��1)��padding��valid����������Ӧ����conv_name_base+��2c����ʹ��0��Ϊ�����ʼ�������ӡ�
- ������BatchNorm�Ƕ�ͨ������й�һ������������Ӧ����bn_name_base + ��2c����ʹ��0��Ϊ�����ʼ�������ӡ�
���һ����
- ���·�����������һ��
- ʹ��ReLU���������û������Ҳû�г�������
��ϰ��ʵ��ResNet��ȿ顣�����Ѿ�ʵ������·���ĵ�һ�������
- ʵ��Conv2D���ο��ĵ�
- ʵ��BatchNorm���ο��ĵ�
- ʵ�ּ��ʹ��
Activation('relu')(X) - ���ӡ����·�������ݵ�ֵ���ο��ĵ�
def identity_block(X, f, filters, stage, block):"""ʵ�ֺ�ȿ�:param X:����������ά��(m, n_H_prev, n_W_prev, n_C_prev):param f:������ָ����·�����м�CONV���ڵ�ά��:param filters:�����б���������·��ÿ�������Ĺ���������:param stage:����������ÿ���λ�ø�ÿ����������block����һ��ʹ��:param block:�ַ�������ÿ���λ��������ÿһ�㣬��stage����һ��ʹ��:return:X-������������tensor���ͣ�ά��Ϊ(n_H, n_W, n_C)"""#������������conv_name_base = "res" + str(stage) + block + "_branch"bn_name_base = "bn" + str(stage) + block + '_branch'#��ȡ����������F1, F2, F3 = filters#�������������X_shortcut = X#��·����һ����ɲ���X = Conv2D(filters=F1, kernel_size=(1, 1), strides=(1, 1), padding='valid', name=conv_name_base + '2a', kernel_initializer=glorot_uniform(seed=0))(X)X = BatchNormalization(axis=3, name=bn_name_base + '2a')(X)X = Activation('relu')(X)#��·���ڶ�����ɲ���X = Conv2D(filters=F2, kernel_size=(f, f), strides=(1, 1), padding='same', name=conv_name_base + '2b', kernel_initializer=glorot_uniform(seed=0))(X)X = BatchNormalization(axis=3, name=bn_name_base + '2b')(X)X = Activation('relu')(X)#��·����������ɲ���X = Conv2D(filters=F3, kernel_size=(1, 1), strides=(1, 1), padding='valid', name=conv_name_base + '2c', kernel_initializer=glorot_uniform(seed=0))(X)X = BatchNormalization(axis=3, name=bn_name_base + '2c')(X)#���һ������shortcut��ֵ������·���У�ͨ��relu���������X = Add()([X, X_shortcut])X = Activation('relu')(X)return X
���ã�
if __name__ == "__main__":tf.reset_default_graph()with tf.Session() as test:np.random.seed(1)A_prev = tf.placeholder("float", [3,4,4,6])X = np.random.randn(3, 4, 4, 6)A = identity_block(A_prev, f=2, filters=[2, 4, 6], stage=1, block='a')test.run(tf.global_variables_initializer())#K.learning_phase()��������Ǯģʽ����ѵ��ģʽ�»��Dz���ģʽ�£�ѵ��ģʽΪ0������ģʽΪ1out = test.run([A], feed_dict={
A_prev:X, K.learning_phase():0})print("out = " + str(out[0][1][1][0]))
������

2.2 ������
�����Ѿ�ʵ���˲в�����ĺ�ȿ飬������������Ҫʵ�ֲв�����ľ����飬���ǿ����һ����ʽ�����������ά�Ȳ�ƥ��ʱ�������ʹ��������ʽ�����ȿ鲻ͬ���ǽݾ�����һ��Conv2D�㣬����ͼ��ʾ��
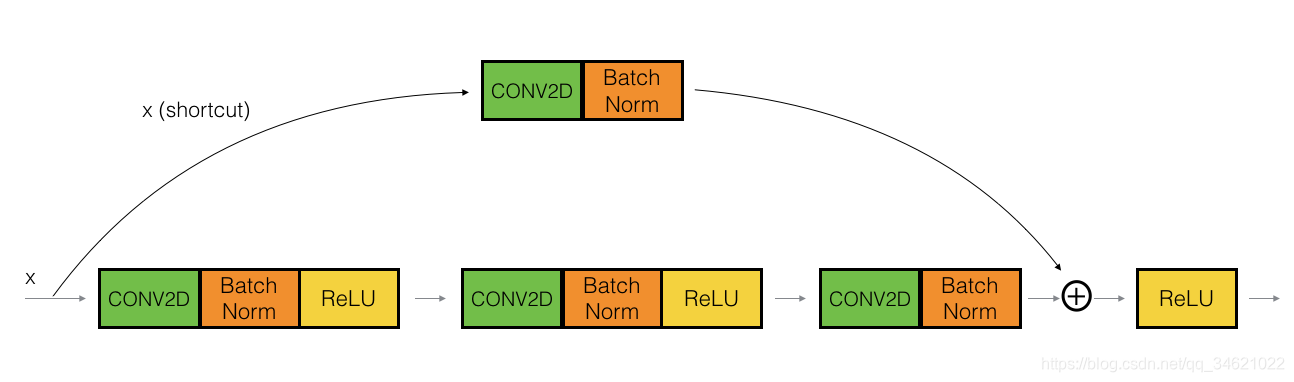
�ݾ��е�Conv2D��������������x���µ���ά���ģ����������������У�ά�Ⱦͻ�ƥ���������Ա㽫��ݼ�ֵ���ӻ���·����(���ú��������ᵽ��WsW_sWs?��������)�����磺������ֵ�Ŀ��Ⱥ߶ȼ���һ�룬���ǿ���ʹ��һ��1*1�ģ�����Ϊ2�ľ�����ʵ�֡��ڽݾ��ֵ�Conv2D��û��ʹ���κη����Լ������������Ҫ������Ӧ��һ��(��ѧϰ��)���Ժ��������������ά�����Ӷ�ʹά�������ļӷ�������ƥ�䡣
�������ʵ�ֲ���������ʾ��
��·����һ������:
- ��һ��Conv2D��������F1��ά��Ϊ(1��1)������Ϊ(s��s)��paddingΪvalid����������Ϊ
conv_name_base + '2a'�� - ��һ��BatchNorm�Ƕ�ͨ������й�һ��������Ϊ
bn_name_base + '2a'�� - ʹ��Relu�������
��·���ĵڶ���������
- �ڶ���Conv2D��������F2��ά��Ϊ(f��f)������Ϊ(1��1)��paddingΪvalid����������Ϊ
conv_name_base + '2b'�� - �ڶ���BatchNorm�Ƕ�ͨ������й�һ��������Ϊ
bn_name_base + '2b'�� - ʹ��Relu�������
��·���ĵ�����������
- ������Conv2D��������F3��ά��Ϊ(1��1)������Ϊ(1��1)��paddingΪvalid������Ϊ
conv_name_base + '2b'�� - ������BatchNorm�Ƕ�ͨ������й�һ������������Ϊ
bn_name_base + '2c'�� - û�м������
�ݾ���
- �ݾ��ֵ�Conv2D��������F3��ά��Ϊ(1��1)������Ϊ(s��s)��paddingΪvalid������Ϊ
bn_name_base + '1'��
���һ����
- ���ݾ�����·����ֵ����һ��
- Ӧ��Relu�������
��ϰ��ʵ�־����飬�Ѿ�ʵ������·���ĵ�һ������;������Ӧ��ʵ�����ಿ�֡�����ǰһ��������ʹ��0��Ϊ�����ʼ�������ӣ���ȷ�������Ƿּ�����һ���ԡ�
- ʵ��Conv2D���ο��ĵ�
- ʵ��BatchNorm���ο��ĵ�
- ʵ�ּ��ʹ��
Activation('relu')(X) - ���ӡ����·�������ݵ�ֵ���ο��ĵ�
���룺
def convolutional_block(X, f, filters, stage, block, s=2):"""ʵ�־�����:param X:���룬ά��Ϊ( m, n_H_prev, n_W_prev, n_C_prev):param f:��������·���д���ά��:param filters:�����б���������·��ÿ������Ĺ���������:param stage:������ÿ���λ��������ÿһ��:param block:�ַ���������ÿһ���λ������:param s:����������:return:�����������X��ά��Ϊ(n_H, n_W, n_C)"""#��������conv_name_base = 'res' + str(stage) + block + '_branch'bn_name_base = 'bn' + str(stage) + block + '_branch'F1, F2, F3 = filtersX_shortcut = X#��·����һ����X = Conv2D(filters=F1, kernel_size=(1, 1), strides=(s, s), padding='valid', name=conv_name_base + '2a', kernel_initializer=glorot_uniform(seed=0))(X)X = BatchNormalization(axis=3, name=bn_name_base + '2a')(X)X = Activation('relu')(X)#��·���ĵڶ�����X = Conv2D(filters=F2, kernel_size=(f, f), strides=(1, 1), padding='same', name=conv_name_base + '2b', kernel_initializer=glorot_uniform(seed=0))(X)X = BatchNormalization(axis=3, name=bn_name_base + '2b')(X)X = Activation('relu')(X)#��·���ĵ�������X = Conv2D(filters=F3, kernel_size=(1, 1), strides=(1, 1), padding='valid', name=conv_name_base + '2c', kernel_initializer=glorot_uniform(seed=0))(X)X = BatchNormalization(axis=3, name=bn_name_base + '2c')(X)#�ݾ�X_shortcut = Conv2D(filters=F3, kernel_size=(1, 1), strides=(s, s), padding='valid', name=conv_name_base + '1', kernel_initializer=glorot_uniform(seed=0))(X_shortcut)X_shortcut = BatchNormalization(axis=3, name=bn_name_base + '1')(X_shortcut)X = Add()([X, X_shortcut])X = Activation('relu')(X)return X
���ã�
tf.reset_default_graph()with tf.Session() as test:np.random.seed(1)A_prev = tf.placeholder("float", [3, 4, 4, 6])X = np.random.randn(3, 4, 4, 6)A = convolutional_block(A_prev, f=2, filters=[2, 4, 6], stage=1, block='a')test.run(tf.global_variables_initializer())out = test.run([A], feed_dict={
A_prev: X, K.learning_phase(): 0})print("out = " + str(out[0][1][1][0]))
������

3. ����һ��50��IJв�����ģ��
�˽����˲в�����Ľṹ���������Ǿ�һ��ʵ��һ�����IJв����磬��ṹ����ͼ��ʾ������ID Block��ʾ���ݿ飬��ID Block x3����ζ����Ӧ�ð�3�����ݿ����һ��
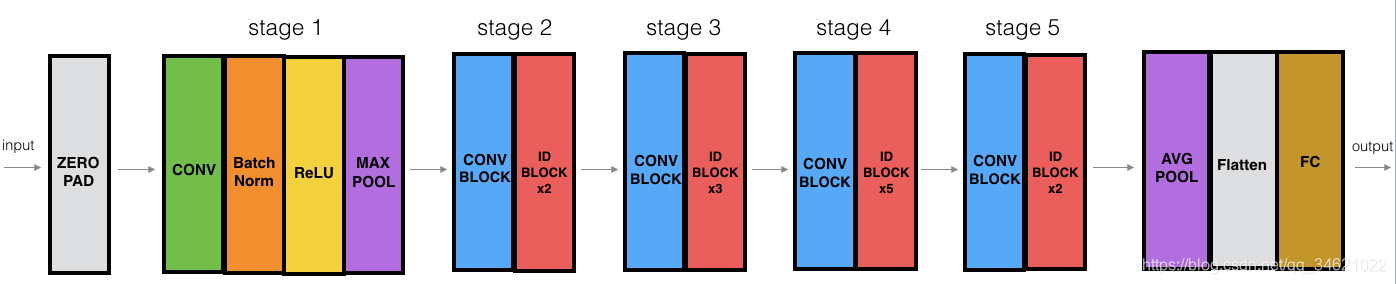
50��в��������ɣ�
- ���������ݽ���0��䣬padding =��3,3����
- stage1��
- ��������64����������������7��7����������2��2����������conv1����
- BatchNorm���������ݽ��й�һ����
- ���ֵ�ػ��㴰��Ϊ��(3��3)������Ϊ(2��2).
- stage2��
- ������ʹ��������СΪ[64��64��256]�Ĺ�������f=3��s=1,block=��a��
- 2����ȿ�ʹ��������СΪ[64��64��256]�Ĺ�������f=3��block=��b������c��
- stages3��
- ������ʹ��3����СΪ[128,128,512]�Ĺ�������f=3��s=2,block=��a��
- 3����ȿ�ʹ��������СΪ[128,128,512]�Ĺ�������f=3��block=��b������c������d��
- stage4��
- ������ʹ��3����СΪ[256,256,1024]�Ĺ�������f=3��s=2,block=��a����
- 5����ȿ�ʹ��������СΪ[256,256,1024]�Ĺ�������f=3��block=��b������c������d������e������f����
- stage5��
- ������ʹ��f=3����СΪ[512,512,2048]�Ĺ�������f=3��s=2,block=��a��
- 2����ȿ�ʹ��������СΪ[256,256,2048]�Ĺ�������f=3��block=��b������c����
- ��ֵ�ػ���ʹ��ά��Ϊ��2,2���Ĵ��ڣ�����Ϊ��avg_pool��
- չ������
- ȫ���Ӳ㣨�ܼ����ӣ�ʹ��softmax�����������Ϊ
"fc" + str(classes)
�����ֲ
- ��ֵ�ػ��㣺��ַ
- Conv2D����ַ
- BatchNorm����ַ
- zero ��䣺��ַ
- ���ֵ�ػ��㣺��ַ
- ȫ���Ӳ㣺��ַ
- ���ӿ�ݷ�ʽ���ݵ�ֵ����ַ
���룺
def ResNet50(input_shape=(64, 64, 3), classes=6):"""50��в�����Ľṹ��CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK*2 -> CONVBLOCK -> IDBLOCK*3-> CONVBLOCK -> IDBLOCK*5 -> CONVBLOCK -> IDBLOCK*2 -> AVGPOOL -> TOPLAYER:param input_shape:ͼ�����ݼ�ά��:param classes:������:return:model - ģ��"""#��������X_input = Input(input_shape)#0���X = ZeroPadding2D((3, 3))(X_input)#stage1X = Conv2D(64, (7, 7), strides=(2, 2), name='conv1', kernel_initializer=glorot_uniform(seed=0))(X)X = BatchNormalization(axis=3, name='bn_conv1')(X)X = Activation('relu')(X)X = MaxPooling2D((3, 3), strides=(2, 2))(X)#stage2X = convolutional_block(X, f=3, filters=[64, 64, 256], stage=2, block='a', s=1)X = identity_block(X, 3, [64, 64, 256], stage=2, block='b')X = identity_block(X, 3, [64, 64, 256], stage=2, block='c')#stage3X = convolutional_block(X, f=3, filters=[128, 128, 512], stage=3, block='a', s=2)X = identity_block(X, 3, [128, 128, 512], stage=3, block='b')X = identity_block(X, 3, [128, 128, 512], stage=3, block='c')X = identity_block(X, 3, [128, 128, 512], stage=3, block='d')#stage4X = convolutional_block(X, f=3, filters=[256, 256, 1024], stage=4, block='a', s=2)X = identity_block(X, 3, [256, 256, 1024], stage=4, block='b')X = identity_block(X, 3, [256, 256, 1024], stage=4, block='c')X = identity_block(X, 3, [256, 256, 1024], stage=4, block='d')X = identity_block(X, 3, [256, 256, 1024], stage=4, block='e')X = identity_block(X, 3, [256, 256, 1024], stage=4, block='f')#stage5X = X = convolutional_block(X, f=3, filters=[512, 512, 2048], stage=5, block='a', s=2)X = identity_block(X, 3, [512, 512, 2048], stage=5, block='b')X = identity_block(X, 3, [512, 512, 2048], stage=5, block='c')#��ֵ�ػ�X = AveragePooling2D(pool_size=(2, 2), padding='same')(X)#�����X = Flatten()(X)X = Dense(classes, activation='softmax', name='fc' + str(classes), kernel_initializer=glorot_uniform(seed=0))(X)model = Model(inputs=X_input, outputs=X, name='ResNet50')return modelʵ��ģ�ͣ�
model = ResNet50(input_shape=(64, 64, 3), classes=6)
����ģ�ͣ�
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
ʹ�õ����ݼ���

���룺
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()# Normalize image vectors
X_train = X_train_orig / 255.
X_test = X_test_orig / 255.# Convert training and test labels to one hot matrices
Y_train = convert_to_one_hot(Y_train_orig, 6).T
Y_test = convert_to_one_hot(Y_test_orig, 6).Tprint("number of training examples = " + str(X_train.shape[0]))
print("number of test examples = " + str(X_test.shape[0]))
print("X_train shape: " + str(X_train.shape))
print("Y_train shape: " + str(Y_train.shape))
print("X_test shape: " + str(X_test.shape))
print("Y_test shape: " + str(Y_test.shape))
������

ѵ�����룺
model.fit(X_train, Y_train, epochs=2, batch_size=32)
���ֽ�ͼ��
epoch1��

epoch2��

����ģ�ͱ��֣�
preds = model.evaluate(X_test, Y_test)print("Loss = " + str(preds[0]))print("Test Accuracy = " + str(preds[1]))

��ҵֻҪ���������ѵ�������������Щ�����Լ�����������Σ����ѵ��20�ξͿ��Ի�ñȽϺõĽ����������CPU�Ͽ�����Ҫ1��Сʱ��ʱ�䡣
���������Ǿ�ֱ��ʹ����ҵ�ṩ���Ѿ�ѵ���õIJ������������ؽ���ʹ�á�
û���ҵ�������ļ���ֻ���ϴ��룬��ҿ�һ���ɡ�
model = load_model('ResNet50.h5')preds = model.evaluate(X_test, Y_test)
print("Loss = " + str(preds[0]))
print("Test Accuracy = " + str(preds[1]))
4. ����ģ��
���룺
img_path = 'datasets//my_image.jpg'img = image.load_img(img_path, target_size=(64, 64))x = image.img_to_array(img)x = np.expand_dims(x, axis=0)x = preprocess_input(x)print('Input image shape:', x.shape)my_image = scipy.misc.imread(img_path)imshow(my_image)print("class prediction vector [p(0), p(1), p(2), p(3), p(4), p(5)] = ")print(model.predict(x))
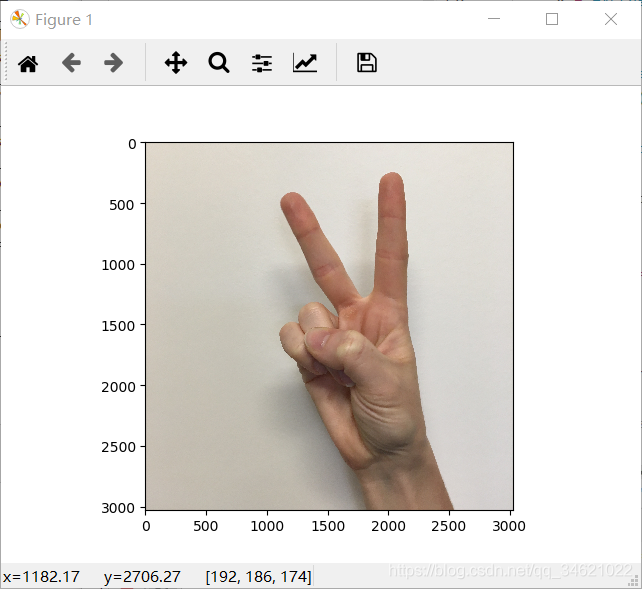
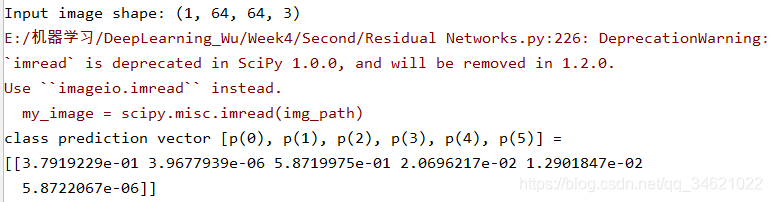
�ҵĽ�����д���ģ�ʹ�ø����IJ���Ӧ�����[[1,0,0,0,0,0]].
�鿴����ϸ�ڣ�
model.summary()
��������ֽ�ͼ����

���ƽṹͼ��
���룺
plot_model(model, to_file='model.png')SVG(model_to_dot(model).create(prog='dot', format='svg'))
����ͼ����������

5. ���ߴ���
resnets_utils.py
import os
import numpy as np
import tensorflow as tf
import h5py
import mathdef load_dataset():train_dataset = h5py.File('datasets/train_signs.h5', "r")train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set featurestrain_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labelstest_dataset = h5py.File('datasets/test_signs.h5', "r")test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set featurestest_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labelsclasses = np.array(test_dataset["list_classes"][:]) # the list of classestrain_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classesdef random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):"""Creates a list of random minibatches from (X, Y)Arguments:X -- input data, of shape (input size, number of examples) (m, Hi, Wi, Ci)Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples) (m, n_y)mini_batch_size - size of the mini-batches, integerseed -- this is only for the purpose of grading, so that you're "random minibatches are the same as ours.Returns:mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y)"""m = X.shape[0] # number of training examplesmini_batches = []np.random.seed(seed)# Step 1: Shuffle (X, Y)permutation = list(np.random.permutation(m))shuffled_X = X[permutation,:,:,:]shuffled_Y = Y[permutation,:]# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.num_complete_minibatches = math.floor(m/mini_batch_size) # number of mini batches of size mini_batch_size in your partitionningfor k in range(0, num_complete_minibatches):mini_batch_X = shuffled_X[k * mini_batch_size : k * mini_batch_size + mini_batch_size,:,:,:]mini_batch_Y = shuffled_Y[k * mini_batch_size : k * mini_batch_size + mini_batch_size,:]mini_batch = (mini_batch_X, mini_batch_Y)mini_batches.append(mini_batch)# Handling the end case (last mini-batch < mini_batch_size)if m % mini_batch_size != 0:mini_batch_X = shuffled_X[num_complete_minibatches * mini_batch_size : m,:,:,:]mini_batch_Y = shuffled_Y[num_complete_minibatches * mini_batch_size : m,:]mini_batch = (mini_batch_X, mini_batch_Y)mini_batches.append(mini_batch)return mini_batchesdef convert_to_one_hot(Y, C):Y = np.eye(C)[Y.reshape(-1)].Treturn Ydef forward_propagation_for_predict(X, parameters):"""Implements the forward propagation for the model: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SOFTMAXArguments:X -- input dataset placeholder, of shape (input size, number of examples)parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3"the shapes are given in initialize_parametersReturns:Z3 -- the output of the last LINEAR unit"""# Retrieve the parameters from the dictionary "parameters" W1 = parameters['W1']b1 = parameters['b1']W2 = parameters['W2']b2 = parameters['b2']W3 = parameters['W3']b3 = parameters['b3'] # Numpy Equivalents:Z1 = tf.add(tf.matmul(W1, X), b1) # Z1 = np.dot(W1, X) + b1A1 = tf.nn.relu(Z1) # A1 = relu(Z1)Z2 = tf.add(tf.matmul(W2, A1), b2) # Z2 = np.dot(W2, a1) + b2A2 = tf.nn.relu(Z2) # A2 = relu(Z2)Z3 = tf.add(tf.matmul(W3, A2), b3) # Z3 = np.dot(W3,Z2) + b3return Z3def predict(X, parameters):W1 = tf.convert_to_tensor(parameters["W1"])b1 = tf.convert_to_tensor(parameters["b1"])W2 = tf.convert_to_tensor(parameters["W2"])b2 = tf.convert_to_tensor(parameters["b2"])W3 = tf.convert_to_tensor(parameters["W3"])b3 = tf.convert_to_tensor(parameters["b3"])params = {
"W1": W1,"b1": b1,"W2": W2,"b2": b2,"W3": W3,"b3": b3}x = tf.placeholder("float", [12288, 1])z3 = forward_propagation_for_predict(x, params)p = tf.argmax(z3)sess = tf.Session()prediction = sess.run(p, feed_dict = {
x: X})return prediction