YOLO系列–YOLO V1
YOLO V1:
- 论文:You only look once: unified, real time object detection(2016 CVPR)
- 效果:448 ×\times× 448, 达到45FPS,63.4mAP(Pascal VOC 2017测试集)
- 论文思想:
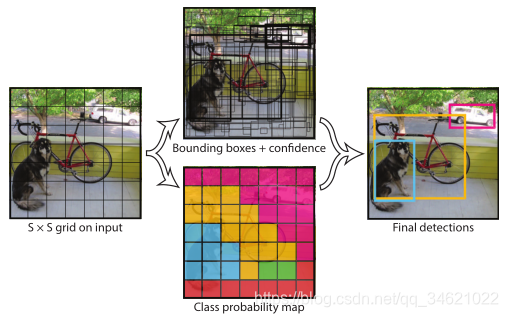
(1) 将一副图像分成S ×\times× S个网格,如果某个object的中心落在这个网格里,这个网格就负责预测这个object。
(2) 每个网格都要预测B个Bounding Box,每个Bounding Box由5个预测值组成(x, y, w, h, confidence–C个类别,x,y为box 的中心坐标,x,y,w,h都在0~1之间是一个相对值)。(论文使用PASCAL VOC,共20个类别,C=20,S=7,B=2).
网络结构图: prediction result 是一个长度为 S ×\times× S ×\times× (B ×\times× 5 + C)的向量。

注意:
-
在YOLO V1中没有anchor,预测的x, y, w, h都是直接预测bounding box 的位置。
-
confidence 计算方式:Pr(Object) * IOUpredtruthIOU^{truth}_{pred}IOUpredtruth?
其中Pr(Object)表示grid cell中存在object的概率,有就是1,没有就是0。IOU表示预测框占真实框的比例。
这里的IOU与有anchor的检测模型计算方式不同。有anchor的模型IOU计算方式为:预测框与真实框的交集比上两个框的并集。 -

(3) 损失函数:

- 计算bonding box损失,作者首先用坐标真实值减预测值开方,再加上高和宽的真实值的开方减去预测值的开方。
- 计算confidence损失:预测值减去真实值。前部分计算正样本,后部分计算负样本,正样本时CiC_{i}Ci?为1,负样本时CiC_{i}Ci?为0。
- Classes损失:预测值减去真实值。
为什么计算边界框的高和宽的处理时要进行开根号处理?
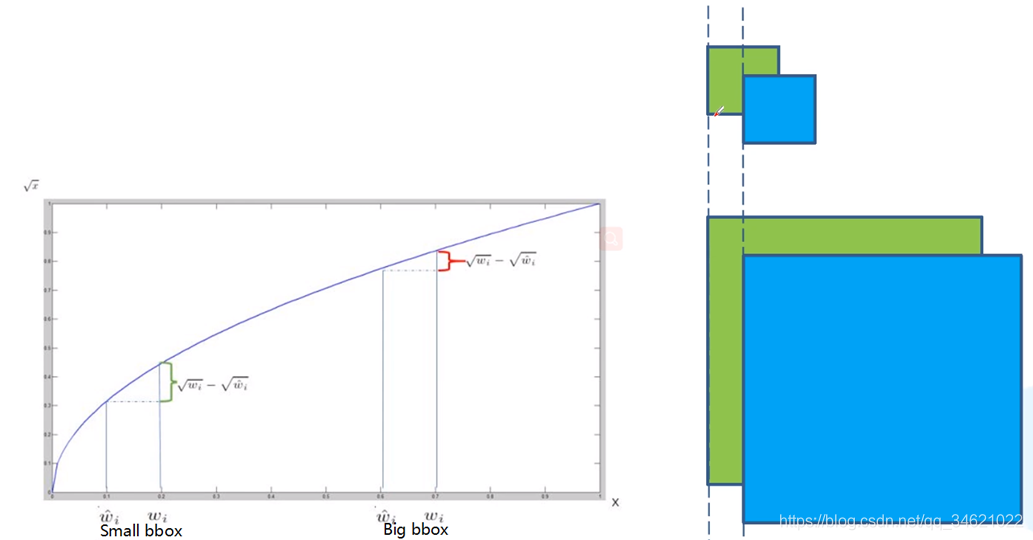
-
绿色表示真实目标边界框,蓝色代表预测的目标边界框,上面是小目标,下面是大目标。
我们假设大目标和小目标的预测边界框都相对真实边界框偏移了相同的一段距离,可以从图中看出小目标偏移一段距离以后效果变得较差,而大目标则没什么太大影响。 -
也就是说对于不同尺度目标而言IOU是不同的,因此我们不能直接使用预测的宽度减去真实的宽度,因此作者使用开根号的方法来做减法。
-
从上图我们可以看出用了开根号以后在移动相同的距离时,小目标的占比要比大目标的占比要大,也就是会值得损失函数更关注小目标。
YOLO V1 缺点:
- YOLO V1对于小目标检测效果较差,在前面我们可以看到YOLO V1在每个grid cell上只预测两个Bounding box,且都属于同一类别,所以当小目标聚集在一起时效果较差。
- 目标出现新的尺寸或配置时效果也较差。
- 作者发现主要误差来源是定位不准确,这主要是因为作者使用了直接预测目标的坐标信息,不像Faster RCNN和SSD一样使用基于anchor的回归预测。