先放上pyspark.sql.DataFrame的函数汇总
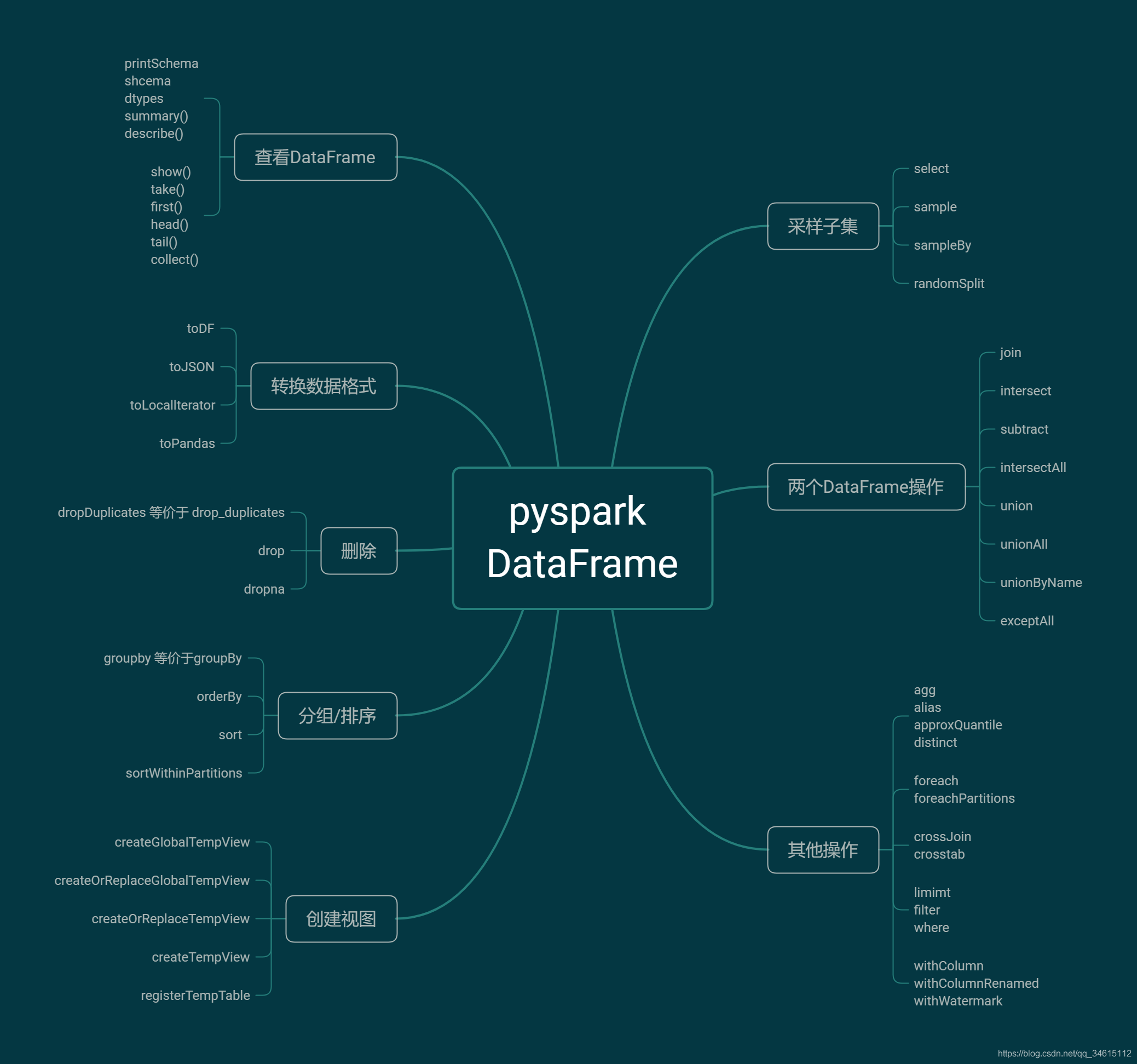
本节来学习pyspark.sql.DataFrame函数。博客中代码基于spark 2.4.4版本。不同版本函数会有不同,详细请参考官方文档。博客案例中用到的数据可以点击此处下载(提取码:2bd5)
from pyspark.sql import SparkSession
spark = SparkSession.Builder().master('local').appName('learnDataFrame').getOrCreate()
从文件中读取数据,创建DataFrame
df = spark.read.csv('../data/data.csv', header='True')
# 查看各个列的数据类型
df.printSchema()
root|-- _c0: string (nullable = true)|-- 对手: string (nullable = true)|-- 胜负: string (nullable = true)|-- 主客场: string (nullable = true)|-- 命中: string (nullable = true)|-- 投篮数: string (nullable = true)|-- 投篮命中率: string (nullable = true)|-- 3分命中率: string (nullable = true)|-- 篮板: string (nullable = true)|-- 助攻: string (nullable = true)|-- 得分: string (nullable = true)
?
from pyspark.sql.types import IntegerType, FloatType# withColumns: 为DataFrame增加新的列,如果列名存在,则替换已存在的列
df = df.withColumn('命中', df['命中'].cast(IntegerType()))
df = df.withColumn('投篮数', df['投篮数'].cast(IntegerType()))
df = df.withColumn('投篮命中率', df['投篮命中率'].cast(FloatType()))
df = df.withColumn('3分命中率', df['3分命中率'].cast(FloatType()))
df = df.withColumn('篮板', df['篮板'].cast(IntegerType()))
df = df.withColumn('助攻', df['助攻'].cast(IntegerType()))
df = df.withColumn('得分', df['得分'].cast(IntegerType()))df.printSchema()
root|-- _c0: string (nullable = true)|-- 对手: string (nullable = true)|-- 胜负: string (nullable = true)|-- 主客场: string (nullable = true)|-- 命中: integer (nullable = true)|-- 投篮数: integer (nullable = true)|-- 投篮命中率: float (nullable = true)|-- 3分命中率: float (nullable = true)|-- 篮板: integer (nullable = true)|-- 助攻: integer (nullable = true)|-- 得分: integer (nullable = true)
?
# 打印数据的2行
df.show(2)
+---+----+----+------+----+------+----------+---------+----+----+----+
|_c0|对手|胜负|主客场|命中|投篮数|投篮命中率|3分命中率|篮板|助攻|得分|
+---+----+----+------+----+------+----------+---------+----+----+----+
| 0|勇士| 胜| 客| 10| 23| 0.435| 0.444| 6| 11| 27|
| 1|国王| 胜| 客| 8| 21| 0.381| 0.286| 3| 9| 27|
+---+----+----+------+----+------+----------+---------+----+----+----+
only showing top 2 rows?
df.explain<bound method DataFrame.explain of DataFrame[_c0: string, 对手: string, 胜负: string, 主客场: string, 命中: int, 投篮数: int, 投篮命中率: float, 3分命中率: float, 篮板: int, 助攻: int, 得分: int]>agg
聚合函数,等价于pandas中的df.groupby().agg()
# 求得分的均值
ans = df.agg({
'得分': 'mean'}).collect()
ans[Row(avg(得分)=32.04)]alias
返回带有别名集的新DataFrame。
df2 = df.alias('df1')approxQuantile
计算DataFrame的数字列的近似分位数
quantile_25 = df.approxQuantile('得分', (0.25, ), 0.01)
quantile_25[27.0]df.coalesce(numPartitions=1)DataFrame[_c0: string, 对手: string, 胜负: string, 主客场: string, 命中: int, 投篮数: int, 投篮命中率: float, 3分命中率: float, 篮板: int, 助攻: int, 得分: int]# 查看DataFrame所有的列名
df.columns['_c0', '对手', '胜负', '主客场', '命中', '投篮数', '投篮命中率', '3分命中率', '篮板', '助攻', '得分']corr(col1, col2, method=None)
计算两个数值型列的相关性,目前仅支持persion相关系数。
# 计算3分命中率 和 得分的相关性
df.corr('3分命中率', '得分')0.776918459184134count()
返回DataFrame的行数
df.count()25cov(col1, col2)
计算两个指定列的协方差,与DataFrameStatFunctions.cov()相同
df.cov('3分命中率', '得分')1.0428483147422474createGlobalTempView(name)
创建全局临时视图,此临时视图的生命周期与此Spark应用程序相关,如果已经存在同名的视图,则抛出 TempTableAlreadyExistsException
df.createGlobalTempView('df')createOrReplaceGlobalTempView(name)
创建全局临时视图,如果存在同名视图,则替换同名视图,视图生命周期与Spark应用程序相关
df.createOrReplaceGlobalTempView('df')createOrReplaceTempView(name)
创建局部临时视图,该临时表的生命周期与SparkSession绑定在一起
df.createOrReplaceTempView('df')createTempView(name)
创建局部临时视图,该临时表的生命周期与SparkSession绑定在一起,如果已经存在同名的视图,则抛出 TempTableAlreadyExistsException
df.createTempView('df')crossJoin()
返回两个DataFrame的笛卡尔积
df.columns['_c0', '对手', '胜负', '主客场', '命中', '投篮数', '投篮命中率', '3分命中率', '篮板', '助攻', '得分']df1 = df.select('_c0', '对手')
df2 = df.select('_c0', '胜负')
df_crossjoin = df1.crossJoin(df2)
df_crossjoin.show(10)+---+----+---+----+
|_c0|对手|_c0|胜负|
+---+----+---+----+
| 0|勇士| 0| 胜|
| 0|勇士| 1| 胜|
| 0|勇士| 2| 胜|
| 0|勇士| 3| 负|
| 0|勇士| 4| 胜|
| 0|勇士| 5| 胜|
| 0|勇士| 6| 负|
| 0|勇士| 7| 负|
| 0|勇士| 8| 胜|
| 0|勇士| 9| 胜|
+---+----+---+----+
only showing top 10 rows?
crosstab(col1, col2)
计算给定列的成对频率表
cube(*cols)
使用指定的列为当前DataFrame创建多维多维数据集,因此我们可以在它们上运行聚合
describe(*cols)
计算数字和字符串列的统计信息
df.describe(['对手', '命中', '投篮数']).show()+-------+----+------------------+------------------+
|summary|对手| 命中| 投篮数|
+-------+----+------------------+------------------+
| count| 25| 25| 25|
| mean|null| 9.8| 21.16|
| stddev|null|3.0138568866708537|3.3501243758005956|
| min|76人| 6| 15|
| max|黄蜂| 19| 29|
+-------+----+------------------+------------------+?
distinct()
按行去重,返回去重后的DataFrame
tmp_df = df.select(['主客场', '命中']).distinct()
tmp_df.show()+------+----+
|主客场|命中|
+------+----+
| 客| 16|
| 客| 10|
| 主| 10|
| 客| 12|
| 主| 8|
| 客| 9|
| 客| 6|
| 主| 11|
| 主| 6|
| 客| 13|
| 客| 8|
| 主| 13|
| 主| 12|
| 主| 19|
+------+----+?
drop(*cols)
删除指定的行,返回删除后的DataFrame
df1 = df.alias('df1')
df1 = df1.drop('命中', '得分')df1.show(2)+---+----+----+------+------+----------+-------------------+----+----+
|_c0|对手|胜负|主客场|投篮数|投篮命中率| 3分命中率|篮板|助攻|
+---+----+----+------+------+----------+-------------------+----+----+
| 0|勇士| 胜| 客| 23| 0.435| 0.444| 6| 11|
| 1|国王| 胜| 客| 21| 0.381|0.28600000000000003| 3| 9|
+---+----+----+------+------+----------+-------------------+----+----+
only showing top 2 rows?
df.show(2)+---+----+----+------+----+------+----------+-------------------+----+----+----+
|_c0|对手|胜负|主客场|命中|投篮数|投篮命中率| 3分命中率|篮板|助攻|得分|
+---+----+----+------+----+------+----------+-------------------+----+----+----+
| 0|勇士| 胜| 客| 10| 23| 0.435| 0.444| 6| 11| 27|
| 1|国王| 胜| 客| 8| 21| 0.381|0.28600000000000003| 3| 9| 27|
+---+----+----+------+----+------+----------+-------------------+----+----+----+
only showing top 2 rows?
dropDuplicates(subset=None)
返回删除重复行的DataFrame,可以考虑只根据某些行去重。与drop_Duplicates()功能相同
df1 = df.dropDuplicates(subset=['胜负', '主客场'])
df1.show()+---+----+----+------+----+------+----------+---------+----+----+----+
|_c0|对手|胜负|主客场|命中|投篮数|投篮命中率|3分命中率|篮板|助攻|得分|
+---+----+----+------+----+------+----------+---------+----+----+----+
| 0|勇士| 胜| 客| 10| 23| 0.435| 0.444| 6| 11| 27|
| 6|灰熊| 负| 客| 6| 19| 0.316| 0.222| 4| 8| 20|
| 3|灰熊| 负| 主| 8| 20| 0.4| 0.25| 5| 8| 22|
| 2|小牛| 胜| 主| 10| 19| 0.526| 0.462| 3| 7| 29|
+---+----+----+------+----+------+----------+---------+----+----+----+?
dropna(how=‘any’, thresh=None, subset=None)
返回删除含有空值的行,别名DataFrameNaFunctions.drop()
how: any, 删除包含空的行
all, 删除全部为空的行、
thresh: 默认为空,如果指定的话,删除小阈值且非空的行
import numpy as np
import pandas as pd
tmp_df = spark.createDataFrame(pd.DataFrame({
'a': [1, 2, np.nan], 'b': [2, np.nan, 5]}))
tmp_df.show()+---+---+
| a| b|
+---+---+
|1.0|2.0|
|2.0|NaN|
|NaN|5.0|
+---+---+?
tmp_df.dropna(how='any').show()+---+---+
| a| b|
+---+---+
|1.0|2.0|
+---+---+?
dtypes
返回列表类型,包含所有列的列名和他们的数据类型
df.dtypes[('_c0', 'string'),('对手', 'string'),('胜负', 'string'),('主客场', 'string'),('命中', 'string'),('投篮数', 'string'),('投篮命中率', 'string'),('3分命中率', 'string'),('篮板', 'string'),('助攻', 'string'),('得分', 'string')]explain(extended=False)
将(逻辑和物理)计划打印到控制台以进行调试
df.explain(extended=False)== Physical Plan ==
*(1) FileScan csv [_c0#2232,对手#2233,胜负#2234,主客场#2235,命中#2236,投篮数#2237,投篮命中率#2238,3分命中率#2239,篮板#2240,助攻#2241,得分#2242] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/D:/demo/studyProj/spark/data/data.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<_c0:string,对手:string,胜负:string,主客场:string,命中:string,投篮数:string,投篮命中率:string,3分命中率:string,篮...fillna(value, subset=None)
填充缺失值,别名na.fill().DataFrame.fillna()和DataFrameNaFunctions.fill()。
value: int,long, float, string. or dict, 如果为字典类型,则key为列名,value为对应列的填充值
subset:可选的列名
tmp_df = spark.createDataFrame(pd.DataFrame({
'a': [1, 2, np.nan], 'b': [2, np.nan, 5]}))
tmp_df.fillna({
'a': 100, 'b': 200}).show()+-----+-----+
| a| b|
+-----+-----+
| 1.0| 2.0|
| 2.0|200.0|
|100.0| 5.0|
+-----+-----+?
filter(condition)
根据给定的条件过滤行,与where()功能相同
df.filter(df['命中'] > 15).show()+---+------+----+------+----+------+----------+------------------+----+----+----+
|_c0| 对手|胜负|主客场|命中|投篮数|投篮命中率| 3分命中率|篮板|助攻|得分|
+---+------+----+------+----+------+----------+------------------+----+----+----+
| 10| 爵士| 胜| 主| 19| 25| 0.76| 0.875| 2| 13| 56|
| 23|开拓者| 胜| 客| 16| 29| 0.552|0.5710000000000001| 8| 3| 48|
+---+------+----+------+----+------+----------+------------------+----+----+----+?
df.where(df['命中'] > 15).show()+---+------+----+------+----+------+----------+------------------+----+----+----+
|_c0| 对手|胜负|主客场|命中|投篮数|投篮命中率| 3分命中率|篮板|助攻|得分|
+---+------+----+------+----+------+----------+------------------+----+----+----+
| 10| 爵士| 胜| 主| 19| 25| 0.76| 0.875| 2| 13| 56|
| 23|开拓者| 胜| 客| 16| 29| 0.552|0.5710000000000001| 8| 3| 48|
+---+------+----+------+----+------+----------+------------------+----+----+----+?
first()
返回第一行作为一个Row
t = df.first()
type(t)pyspark.sql.types.Rowforeach(f)
对DataFrame的所有行执行函数操作,等价于df.rdd.foreach()
foreachPartition(f)
将f函数应用于此DataFrame的每个分区。
freqItems(cols, support=None)
查找列的频繁项
cols: 要计算重复项的列名,为字符串类型的列表或者元祖。
support: 要计算频率项的频率值。默认是1%。参数必须大于1e-4.
df.freqItems(cols=['命中', '主客场'], support=0.9).show()+--------------+----------------+
|命中_freqItems|主客场_freqItems|
+--------------+----------------+
| [8]| [客]|
+--------------+----------------+?
groupBy(*cols)
按指定列分组,后面可以执行aggregation函数,等价于groupby()
df.groupBy(['主客场', '胜负']).agg({
'得分': 'sum', '对手': 'count'}).show()+------+----+---------+-----------+
|主客场|胜负|sum(得分)|count(对手)|
+------+----+---------+-----------+
| 主| 负| 89.0| 3|
| 客| 胜| 384.0| 12|
| 主| 胜| 308.0| 9|
| 客| 负| 20.0| 1|
+------+----+---------+-----------+?
head(n=None)
返回DataFrame的前n行
df.head(3)[Row(_c0='0', 对手='勇士', 胜负='胜', 主客场='客', 命中='10', 投篮数='23', 投篮命中率='0.435', 3分命中率='0.444', 篮板='6', 助攻='11', 得分='27'),Row(_c0='1', 对手='国王', 胜负='胜', 主客场='客', 命中='8', 投篮数='21', 投篮命中率='0.381', 3分命中率='0.28600000000000003', 篮板='3', 助攻='9', 得分='27'),Row(_c0='2', 对手='小牛', 胜负='胜', 主客场='主', 命中='10', 投篮数='19', 投篮命中率='0.526', 3分命中率='0.462', 篮板='3', 助攻='7', 得分='29')]intersect(other)
返回两个DataFrame交集组成的DataFrame
join(other, on=None, how=None)
根据指定列,用指定方法连接两个DataFrame
limit(num)
将结果计数限制为指定的数量
df.limit(3).show()+---+----+----+------+----+------+----------+-------------------+----+----+----+
|_c0|对手|胜负|主客场|命中|投篮数|投篮命中率| 3分命中率|篮板|助攻|得分|
+---+----+----+------+----+------+----------+-------------------+----+----+----+
| 0|勇士| 胜| 客| 10| 23| 0.435| 0.444| 6| 11| 27|
| 1|国王| 胜| 客| 8| 21| 0.381|0.28600000000000003| 3| 9| 27|
| 2|小牛| 胜| 主| 10| 19| 0.526| 0.462| 3| 7| 29|
+---+----+----+------+----+------+----------+-------------------+----+----+----+?
orderBy(*cols, **kwargs)
根据指定列排序,返回排好序的DataFrame
cols:用来排序的列或列名称的列表。
ascending:布尔值或布尔值列表(默认 True). 升序排序与降序排序。指定多个排序顺序的列表。如果指定列表, 列表的长度必须等于列的长度
# 按得分降序,投篮数升序排列
df.orderBy(['得分', '投篮数'], ascending=[False, True]).show(5)+---+------+----+------+----+------+----------+------------------+----+----+----+
|_c0| 对手|胜负|主客场|命中|投篮数|投篮命中率| 3分命中率|篮板|助攻|得分|
+---+------+----+------+----+------+----------+------------------+----+----+----+
| 10| 爵士| 胜| 主| 19| 25| 0.76| 0.875| 2| 13| 56|
| 15| 太阳| 胜| 客| 12| 22| 0.545| 0.545| 2| 7| 48|
| 23|开拓者| 胜| 客| 16| 29| 0.552|0.5710000000000001| 8| 3| 48|
| 12| 灰熊| 胜| 主| 11| 25| 0.44| 0.429| 4| 8| 38|
| 14| 猛龙| 负| 主| 8| 25| 0.32| 0.273| 6| 11| 38|
+---+------+----+------+----+------+----------+------------------+----+----+----+
only showing top 5 rows?
persist(storageLevel=StorageLevel(True, True, False, False, 1))
设置存储级别以在第一次操作运行完成后保存其值,默认为(memory_only_ser)
randomSplit(weights, seed=None)
根据给定的权重随机划分DataFrame
splits = df.randomSplit(weights=[0.2, 0.8], seed=7)
for s in splits:print(s.count())3
22rdd
以Row的pyspark.RDD形式返回内容。
rdd = df.rdd
type(rdd)pyspark.rdd.RDDregisterTempTable(name)
使用给定名称将此RDD注册为临时表
此临时表的生存期与用于创建此DataFrame的SQLContext绑定在一起
df.registerTempTable('table')
df1 = spark.sql("select '对手','胜负' from table") #
df1.show(5)+----+----+
|对手|胜负|
+----+----+
|对手|胜负|
|对手|胜负|
|对手|胜负|
|对手|胜负|
|对手|胜负|
+----+----+
only showing top 5 rows?
repartition(numPartitions, *cols)
按照给定的分区表达式分区,返回新的DataFrame。
产生的DataFrame是哈希分区。
numPartitions参数可以是一个整数来指定分区数,或者是一个列。如果是一个列,这个列会作为第一个分区列。如果没有指定,将使用默认的分区数。
replace(to_replace, value=None, subset=None)
返回用另外一个值替换了一个值的新的DataFrame。DataFrame.replace() 和 DataFrameNaFunctions.replace() 类似
rollup(*cols)
使用指定的列为当前的DataFrame创建一个多维汇总,这样可以聚合这些数据。
sample(withReplacement, fraction, seed=None)
返回DataFrame的子集采样
df.sample(withReplacement=False, fraction=0.4, seed=4).show()+---+----+----+------+----+------+------------------+-------------------+----+----+----+
|_c0|对手|胜负|主客场|命中|投篮数| 投篮命中率| 3分命中率|篮板|助攻|得分|
+---+----+----+------+----+------+------------------+-------------------+----+----+----+
| 4|76人| 胜| 客| 10| 20| 0.5| 0.25| 3| 13| 27|
| 5|黄蜂| 胜| 客| 8| 18| 0.444| 0.4| 10| 11| 27|
| 9|老鹰| 胜| 客| 8| 15|0.5329999999999999| 0.545| 3| 11| 29|
| 10|爵士| 胜| 主| 19| 25| 0.76| 0.875| 2| 13| 56|
| 15|太阳| 胜| 客| 12| 22| 0.545| 0.545| 2| 7| 48|
| 16|灰熊| 胜| 客| 9| 20| 0.45| 0.5| 5| 7| 29|
| 17|掘金| 胜| 主| 6| 16| 0.375|0.14300000000000002| 8| 9| 21|
| 19|篮网| 胜| 主| 13| 20| 0.65| 0.615| 10| 8| 37|
| 24|鹈鹕| 胜| 主| 8| 16| 0.5| 0.4| 1| 17| 26|
+---+----+----+------+----+------+------------------+-------------------+----+----+----+?
sampleBy(col, fractions, seed=None)
根据每个层次上给出的分数,返回没有替换的分层样本。
schema
返回DataFrame的schema
df.schemaStructType(List(StructField(_c0,StringType,true),StructField(对手,StringType,true),StructField(胜负,StringType,true),StructField(主客场,StringType,true),StructField(命中,StringType,true),StructField(投篮数,StringType,true),StructField(投篮命中率,StringType,true),StructField(3分命中率,StringType,true),StructField(篮板,StringType,true),StructField(助攻,StringType,true),StructField(得分,StringType,true)))select(*cols)
根据指定列名返回对应列构成的DataFrame
selectExpr(*expr)
投影一组SQL表达式并返回一个新的DataFrame。
tmp_df.selectExpr("a * 2", "abs(a)").show()+-------+------+
|(a * 2)|abs(a)|
+-------+------+
| 2.0| 1.0|
| 4.0| 2.0|
| NaN| NaN|
+-------+------+?
sort(*cols,**kwargs)
根据指定的列排序
df.sort(['得分'], ascending=False).show(10)+---+------+----+------+----+------+----------+---------+----+----+----+
|_c0| 对手|胜负|主客场|命中|投篮数|投篮命中率|3分命中率|篮板|助攻|得分|
+---+------+----+------+----+------+----------+---------+----+----+----+
| 10| 爵士| 胜| 主| 19| 25| 0.76| 0.875| 2| 13| 56|
| 23|开拓者| 胜| 客| 16| 29| 0.552| 0.571| 8| 3| 48|
| 15| 太阳| 胜| 客| 12| 22| 0.545| 0.545| 2| 7| 48|
| 12| 灰熊| 胜| 主| 11| 25| 0.44| 0.429| 4| 8| 38|
| 14| 猛龙| 负| 主| 8| 25| 0.32| 0.273| 6| 11| 38|
| 19| 篮网| 胜| 主| 13| 20| 0.65| 0.615| 10| 8| 37|
| 18|尼克斯| 胜| 主| 12| 27| 0.444| 0.385| 2| 10| 37|
| 21| 湖人| 胜| 客| 13| 22| 0.591| 0.444| 4| 9| 36|
| 11| 骑士| 胜| 主| 8| 21| 0.381| 0.429| 11| 13| 35|
| 8|尼克斯| 胜| 客| 9| 23| 0.391| 0.353| 5| 9| 31|
+---+------+----+------+----+------+----------+---------+----+----+----+
only showing top 10 rows?
sortWithinPartitions(*cols, **kwargs)
每个分区按指定的列排序
stat
返回一个DataFrameStatFunctoins
subtract(other)
subtract(other):返回一个新的DataFrame,这个DataFrame中包含的行不在另一个DataFrame中。这相当于SQL中的EXCEPT
take(num)
返回DataFrame的前num行
sortWithinPartitions(*cols, **kwargs)
返回一个新的DataFrame,每个分区按指定的列排序
summary()
df.select('胜负', '命中', '投篮数').summary('min', 'max', 'count').show()+-------+----+----+------+
|summary|胜负|命中|投篮数|
+-------+----+----+------+
| min| 胜| 6| 15|
| max| 负| 19| 29|
| count| 25| 25| 25|
+-------+----+----+------+?
toDF(*cols)
返回包含指定列的新的DataFrame
ndf = df.select("胜负", "命中", "投篮数").filter(df['投篮数'] == 21).toDF("胜负_", "命中_", "投篮数_")
ndf.show()+-----+-----+-------+
|胜负_|命中_|投篮数_|
+-----+-----+-------+
| 胜| 8| 21|
| 负| 8| 21|
| 胜| 8| 21|
| 胜| 9| 21|
+-----+-----+-------+?
toJSON(use_unicode=True)
将DataFrame转换为字符串类型的rdd
df_json = df.select("胜负", "命中", "投篮数").filter(df['投篮数'] == 21).toJSON()
df_json.collect()
['{"胜负":"胜","命中":8,"投篮数":21}','{"胜负":"负","命中":8,"投篮数":21}','{"胜负":"胜","命中":8,"投篮数":21}','{"胜负":"胜","命中":9,"投篮数":21}']
toLocalIterator(prefetchPartitions=False)
返回一个迭代器,该迭代器包含此DataFrame中的所有行
ndf = df.select("胜负", "命中", "投篮数").filter(df['投篮数'] == 21).toLocalIterator()
for row in ndf:print(row)
Row(胜负='胜', 命中=8, 投篮数=21)
Row(胜负='负', 命中=8, 投篮数=21)
Row(胜负='胜', 命中=8, 投篮数=21)
Row(胜负='胜', 命中=9, 投篮数=21)
toPandas()
将pyspark DataFrame转换为pandas DataFrame
ndf = df.toPandas()
type(ndf)
pandas.core.frame.DataFrame
union(other)
两个DataFrame的并集
df1 = df.select(["胜负", "命中", "投篮数"]).filter(df['投篮数'] > 25)
df2 = df.select(["胜负", "命中", "投篮数"]).filter(df['投篮数'] < 20)
print(df1.count(), df2.count())ndf = df1.union(df2)
ndf.show()
2 7
+----+----+------+
|胜负|命中|投篮数|
+----+----+------+
| 胜| 12| 27|
| 胜| 16| 29|
| 胜| 10| 19|
| 胜| 8| 18|
| 负| 6| 19|
| 胜| 8| 15|
| 胜| 6| 16|
| 胜| 8| 19|
| 胜| 8| 16|
+----+----+------+
?
unionByName(other)
根据列名进行union
ndf.union(df2).distinct().show()
+----+----+------+
|胜负|命中|投篮数|
+----+----+------+
| 胜| 8| 18|
| 胜| 6| 16|
| 负| 6| 19|
| 胜| 8| 19|
| 胜| 12| 27|
| 胜| 16| 29|
| 胜| 8| 15|
| 胜| 10| 19|
| 胜| 8| 16|
+----+----+------+
?
withColumn(colName, col)
为DataFrame增加一个列,如果DataFrame中已存在列名,则替换该列
# 增加一列,胜标记为1 负标记为0
from pyspark.sql import functions as Fdf.withColumn('胜负_flag', F.when(df['胜负'] == '胜', 1).when(df['胜负'] == '负', 0)).show(5)
+---+----+----+------+----+------+----------+---------+----+----+----+---------+
|_c0|对手|胜负|主客场|命中|投篮数|投篮命中率|3分命中率|篮板|助攻|得分|胜负_flag|
+---+----+----+------+----+------+----------+---------+----+----+----+---------+
| 0|勇士| 胜| 客| 10| 23| 0.435| 0.444| 6| 11| 27| 1|
| 1|国王| 胜| 客| 8| 21| 0.381| 0.286| 3| 9| 27| 1|
| 2|小牛| 胜| 主| 10| 19| 0.526| 0.462| 3| 7| 29| 1|
| 3|灰熊| 负| 主| 8| 20| 0.4| 0.25| 5| 8| 22| 0|
| 4|76人| 胜| 客| 10| 20| 0.5| 0.25| 3| 13| 27| 1|
+---+----+----+------+----+------+----------+---------+----+----+----+---------+
only showing top 5 rows
?
withColumnRenamed(exciting, new)
通过重命名现有列来返回新的DataFrame
df.withColumnRenamed(existing='对手', new='比赛对手').show(3)
+---+--------+----+------+----+------+----------+---------+----+----+----+
|_c0|比赛对手|胜负|主客场|命中|投篮数|投篮命中率|3分命中率|篮板|助攻|得分|
+---+--------+----+------+----+------+----------+---------+----+----+----+
| 0| 勇士| 胜| 客| 10| 23| 0.435| 0.444| 6| 11| 27|
| 1| 国王| 胜| 客| 8| 21| 0.381| 0.286| 3| 9| 27|
| 2| 小牛| 胜| 主| 10| 19| 0.526| 0.462| 3| 7| 29|
+---+--------+----+------+----+------+----------+---------+----+----+----+
only showing top 3 rows
文末致敬官方文档:http://spark.apache.org/docs/latest/api/python/pyspark.sql.html#pyspark.sql.DataFrame