感谢您的关注 + 点赞 + 再看,对博主的肯定,会督促博主持续的输出更多的优质实战内容!!!
1.序篇-本文结构
本文从以下五个小节介绍 flink sql source\sink\format 的概念、原理。
-
背景篇-关于 sql
-
定义篇-sql source、sink
-
实战篇-sql source、sink 的用法
-
原理剖析篇-sql source、sink 是怎么跑起来的
-
总结与展望篇
2.背景篇-关于 sql
关于 flink sql 的定位。
先聊聊使用 sql 的原因,总结来说就是一切从简。
-
SQL 属于 DSL
-
SQL 易于理解
-
SQL 内置多种查询优化器
-
SQL 稳定的语言
-
SQL 易于管理
-
SQL 利于流批一体
目前 1.13 版本的 SQL 已经集成了大量高效、易用的 feature。本系列教程也是基于 1.13.1。
3.定义篇-sql source、sink
本文会简单介绍一些 flink sql 的 source、sink 的定义、使用方法,会着重切介绍其对应框架设计和实现。详细解析一下从一条 create table sql 到具体的算子层面的整个流程。
Notes:在 flink sql 中,source 有两种表,一种是数据源表,一种是数据维表。数据源表就是有源源不断的数据的表。比如 mq。数据维表就是用来给某些数据扩充维度使用的。比如 redis,mysql,一般都是做扩容维度的维表 join 使用。
本节主要介绍数据源表,数据维表的整个流程和数据源表几乎一样。下文中的 source 默认都为数据源表。
首先在介绍 sql 之前,我们先来看看 datastream 中定义一个 source 需要的最基本的内容。
-
source、sink 的 connector 连接配置信息。比如 datastream api kafka connector 的 properties,topic 名称。
-
source、sink 的序列化方式信息。比如 datastream api kafka connector 的 DeserializationSchema,SerializationSchema。
-
source、sink 的字段信息。比如 datastream api kafka connector 的序列化或者反序列化出来的 Model 所包含的字段信息。
-
source、sink 对象。比如 datastream api kafka connector source 对应的具体 java 对象。
sql 中的 source、sink 所包含的基本点其实和 datastream 都是相同的,可以将 sql 中的一些语法给映射到 datastream 中来帮助快速理解 sql:
-
sql source、sink connector\properties。可以对应到 datastream api kafka connector 的 properties,topic 名称。
-
sql source、sink format。可以对应到 datastream api kafka connector 的 DeserializationSchema,SerializationSchema。
-
sql source、sink field。可以对应到 datastream api kafka connector 的序列化或者反序列化出来的 Model 所包含的字段信息。
-
sql source、sink catalog_name、db_name、table_name。可以对应到 datastream api kafka connector source 对应的具体 java 对象。
-
sql 本身的特性。比如某些场景下需要将 sql schema 持久化,会用到 hive catalog 等,这个可以说是 sql 目前比 datastream api 多的一个特性。但是仔细想想,其实 datastream 也能够拓展这样的能力,其实就是将某个 datastream 注册到外部存储中(可以,但对 datastream 来说没必要)。
来看看官网的文档 create table schema 的描述,可以发现就是围绕着上面这五点展开的。https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/dev/table/sql/create/#create-table。
CREATE TABLE [IF NOT EXISTS] [catalog_name.][db_name.]table_name({ <physical_column_definition> | <metadata_column_definition> | <computed_column_definition> }[ , ...n][ <watermark_definition> ][ <table_constraint> ][ , ...n])[COMMENT table_comment][PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]WITH (key1=val1, key2=val2, ...)[ LIKE source_table [( <like_options> )] ]<physical_column_definition>:column_name column_type [ <column_constraint> ] [COMMENT column_comment]<column_constraint>:[CONSTRAINT constraint_name] PRIMARY KEY NOT ENFORCED<table_constraint>:[CONSTRAINT constraint_name] PRIMARY KEY (column_name, ...) NOT ENFORCED<metadata_column_definition>:column_name column_type METADATA [ FROM metadata_key ] [ VIRTUAL ]<computed_column_definition>:column_name AS computed_column_expression [COMMENT column_comment]<watermark_definition>:WATERMARK FOR rowtime_column_name AS watermark_strategy_expression<source_table>:[catalog_name.][db_name.]table_name<like_options>:
{{ INCLUDING | EXCLUDING } { ALL | CONSTRAINTS | PARTITIONS }| { INCLUDING | EXCLUDING | OVERWRITING } { GENERATED | OPTIONS | WATERMARKS }
}[, ...]结合我们刚刚说的 sql source、sink 中主要包含 5 点解释一下:
CREATE TABLE [IF NOT EXISTS] -- sql source、sink catalog_name、db_name、table_name
(-- sql source、sink field 字段信息
) WITH
( -- sql source、sink connector\properties 连接配置-- sql source、sink format
)来个 kafka source 的例子:
CREATE TABLE KafkaTable ( -- sql source、sink catalog_name、db_name、table_name`f0` STRING, -- sql source、sink 的字段信息`f1` STRING
) WITH ('connector' = 'kafka', -- sql source、sink 的 connector 连接配置'topic' = 'topic', -- sql source、sink 的 connector 连接配置'properties.bootstrap.servers' = 'localhost:9092', -- sql source、sink 的 connector 连接配置'properties.group.id' = 'testGroup', -- sql source、sink 的 connector 连接配置'format' = 'json' -- sql source、sink 的序列化方式信息
)其对应的 datastream 写法如下:
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "testGroup");DeserializationSchema<Tuple2<String, String>> d = new AbstractDeserializationSchema<Tuple2<String, String>>() {@Overridepublic Tuple2<String, String> deserialize(byte[] message) throws IOException {return json 解析为 tuple2 此处省略;}
};DataStream<Tuple2<String, String>> stream = env.addSource(new FlinkKafkaConsumer<>("topic", d, properties));将 sql source 和 datastream source 的组成部分互相映射起来可以得到下图,其中 datastream、sql 中颜色相同的属性互相对应:

2
可以看到,将所有的 sql 关系代数都映射到 datastream api 上,会有助于我们快速理解。
4.实战篇-sql source、sink 的用法
直接见官网 Table API Connectors。已经描述的非常详细了,本文侧重原理,所以此处不多赘述。
https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/connectors/table/overview/
https://www.alibabacloud.com/help/zh/faq-list/62516.htm?spm=a2c63.p38356.b99.212.3c1a1442x9AY7m
5.原理剖析篇-sql source、sink 是怎么跑起来的
关于 sql 具体工作原理可以参考 https://zhuanlan.zhihu.com/p/157265381。
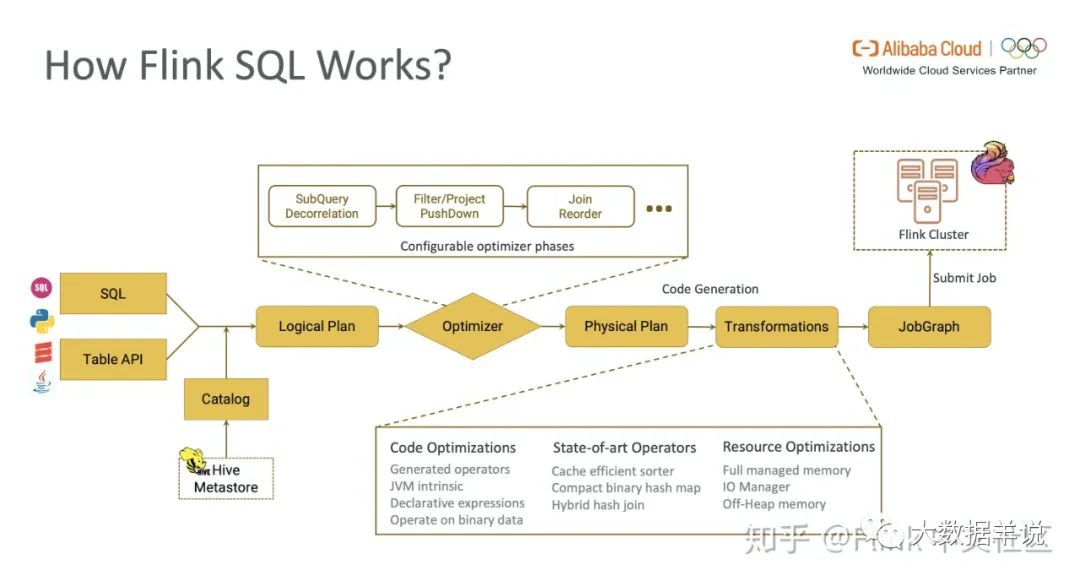
3
但是很多刚接触 flink sql 的读者看完这篇文章,会感觉到还没准备好就来了这么大一堆密集的信息。那么
-
我到底应该从哪里看起呢?
-
能理解 sql 会映射到具体的算子执行。但是它具体是怎么对应到具体的算子上的呢?
博主会从以下两个角度去帮大家理清楚整个流程。
- 先抛开 flink sql、datastream 提供的能力来说,如果你在自己的一个程序中去接入一个数据源,你最关心的是哪些组件?
答:消费一个数据源最重要的就是 connector(负责链接外部组件,消费数据) + serde(负责序列化成 flink 认识的变量形式)。
- 结合第一个问题 + 一段简单的 flink sql 代码来看看 flink 是怎么去做这件事情的。
代码(基于 1.13.1):
public class KafkaSourceTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());env.setParallelism(1);EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);tEnv.executeSql("CREATE TABLE KafkaSourceTable (\n"+ " `f0` STRING,\n"+ " `f1` STRING\n"+ ") WITH (\n"+ " 'connector' = 'kafka',\n"+ " 'topic' = 'topic',\n"+ " 'properties.bootstrap.servers' = 'localhost:9092',\n"+ " 'properties.group.id' = 'testGroup',\n"+ " 'format' = 'json'\n"+ ")");Table t = tEnv.sqlQuery("SELECT * FROM KafkaSourceTable");tEnv.toAppendStream(t, Row.class).print();env.execute();}
}可以看到这段代码很简单,就是创建一个数据源表之后 select 数据 print。
通过上面这段 sql 映射出的 transformations 中发现,其实 flink 中最关键变量的也就是我们刚刚提出的第一个问题中的那两点:
-
sql source connector 是
FlinkKafkaConsumer -
sql source format 是
JsonRowDataDeserializationSchema

19
所以我们就可以从下面这三个方向(多出来的一个是配置信息)的问题去了解具体是怎么对应到具体的算子上的。
-
sql source connector:用户指定了
connector = kafka,flink 是怎么自动映射到FlinkKafkaConsumer的? -
sql source format:用户指定了
format = json,字段信息,flink 是怎么自动映射到JsonRowDataDeserializationSchema,以及字段解析的? -
sql source properties:flink 是怎么自动将配置加载到
FlinkKafkaConsumer中的?
5.1.connector 怎样映射到具体算子?
引用官网图:

22
Notes:其中
LookupTableSource为数据维表。
先说下结论,再跟一遍源码。
结论:
-
MetaData:将 sql create source table 转化为实际的
CatalogTable、翻译为 RelNode -
Planning:创建 RelNode 的过程中使用 SPI 将所有的 source(
DynamicTableSourceFactory)\sink(DynamicTableSinkFactory) 工厂动态加载,获取到 connector = kafka,然后从所有 source 工厂中过滤出名称为 kafka + 继承自DynamicTableSourceFactory.class的工厂类KafkaDynamicTableFactory,使用KafkaDynamicTableFactory创建出KafkaDynamicSource -
Runtime:
KafkaDynamicSource创建出FlinkKafkaConsumer,负责 flink 程序实际运行。
源码:
debug 代码,既然创建的是 FlinkKafkaConsumer,那我们就将断点打在 FlinkKafkaConsumer 的构造函数中。
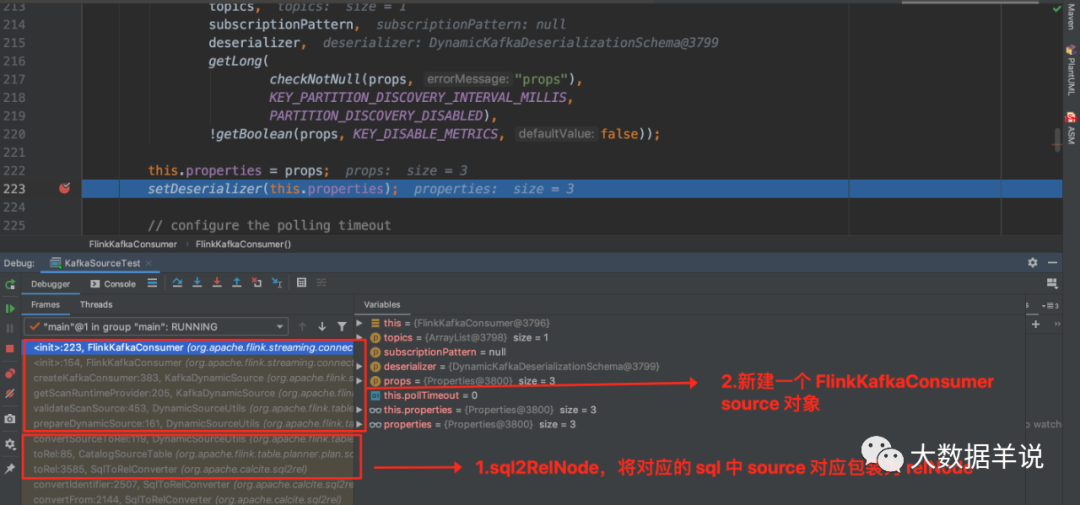
5
如图可以发现当 debug 到当前断点时,已经进入 FlinkKafkaConsumer source 的创建阶段了,执行到这里的时候已经是完成了 sql connector 和具体实际 connector 的映射了。那么 connector 怎样映射到具体算子的过程呢?
我们往前回溯一下,定位到 CatalogSourceTable 中的 82 行(源码基于 1.13.1),发现 tableSource 已经是 KafkaDynamicSource,因此可以确定就是这一行代码将 connector = kafka 映射到 FlinkKafkaConsumer 的。
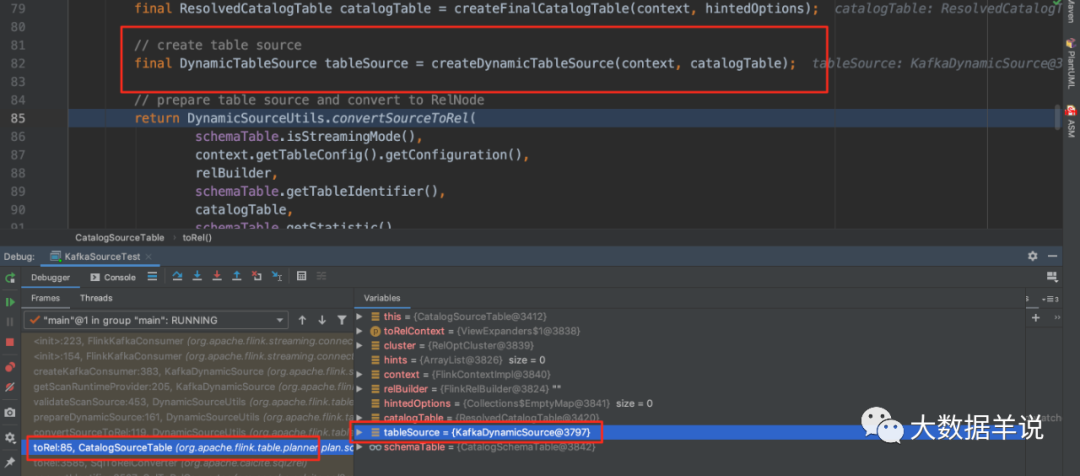
6
可以发现这段代码将包含了所有 sql create source table 中信息的 catalogTable 变量传入了。
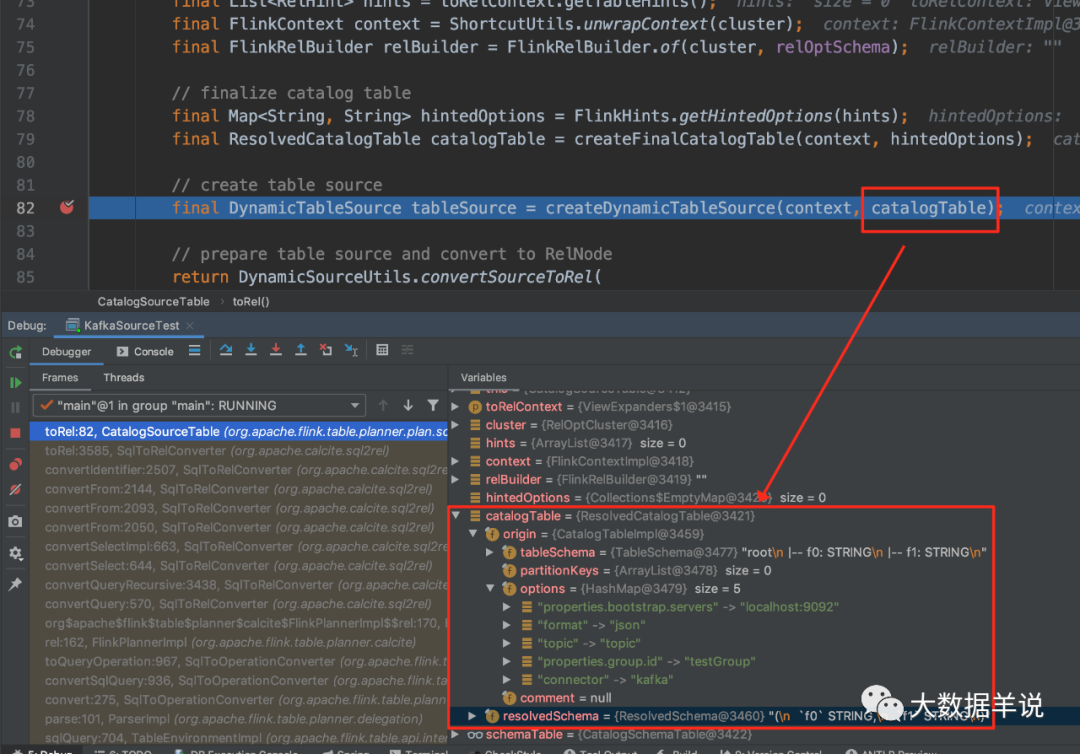
7
进入这个方法后,可以看到是使用了 FactoryUtil 创建了 DynamicTableSource。
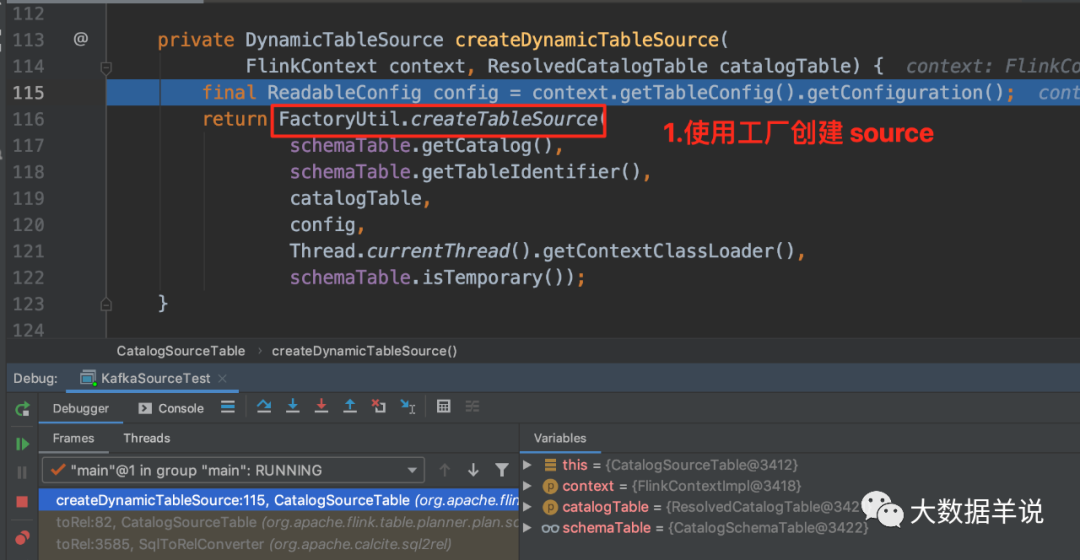
8
进入 FactoryUtil.createTableSource 后可以看到,就是最重要的两步操作。
-
先获取 kafka 工厂对象。
-
使用 kafka 工厂对象创建出 kafka source。
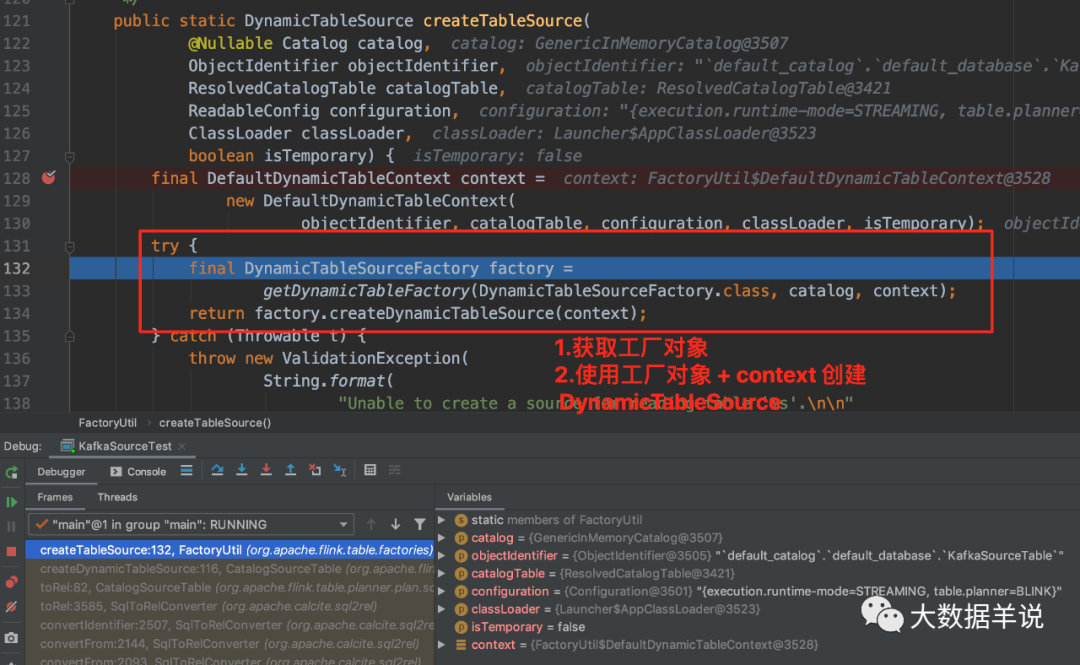
9
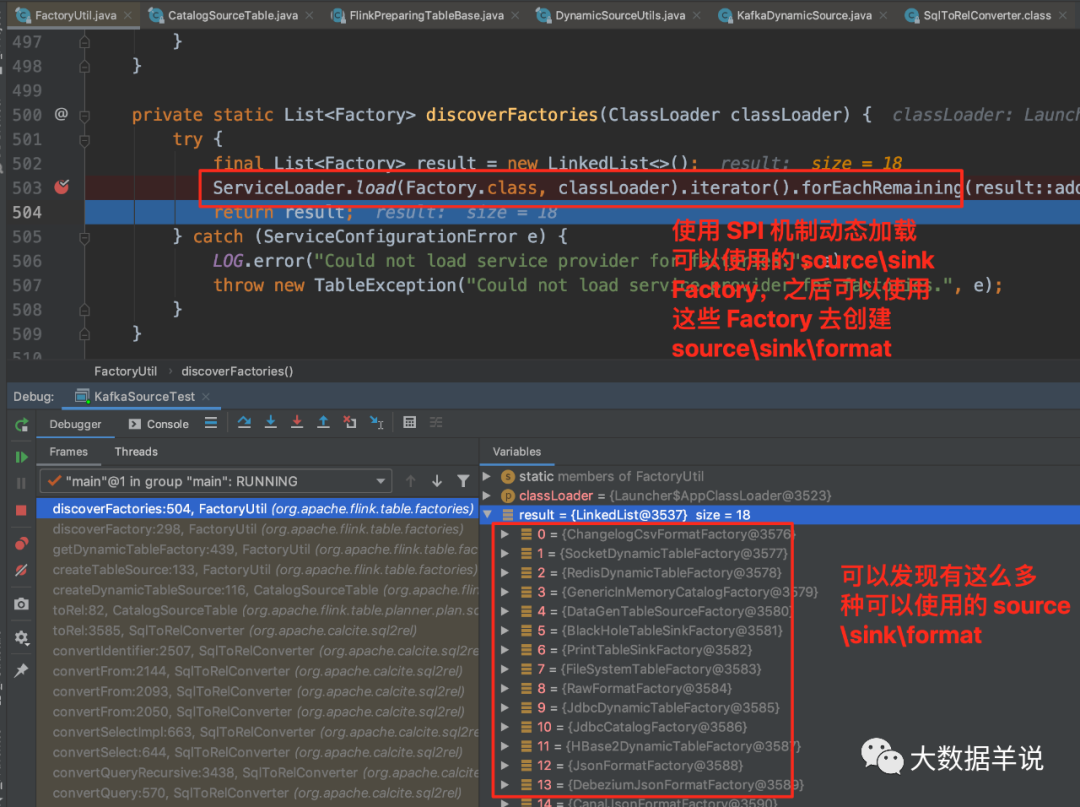
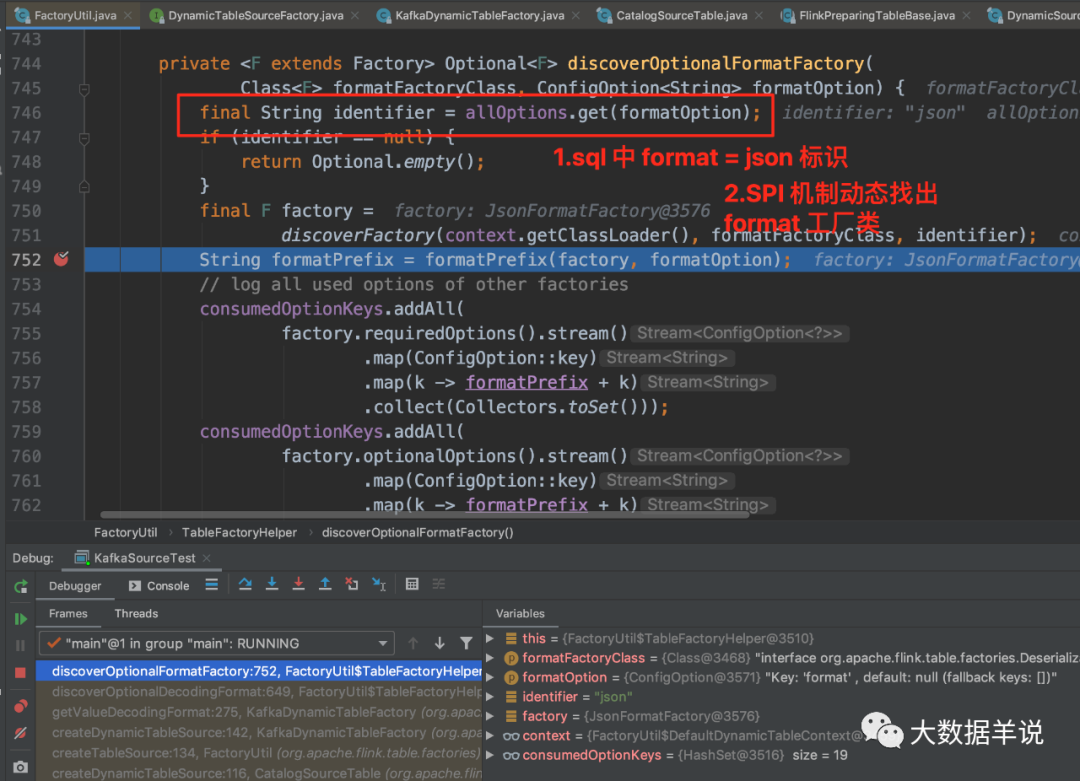
进入 FactoryUtil.getDynamicTableFactory 后:
-
flink 是使用了 SPI 机制动态(SPI 机制天然插件化)的加载到了所有继承了
Factory的工厂实例。通过截图可以看到有好多 source\sink\format Factory。关于 SPI 可以参考 https://www.jianshu.com/p/3a3edbcd8f24 -
通过 connector = kafka +
DynamicTableSourceFactory.class的标识去过滤出KafkaDynamicTableFactory。
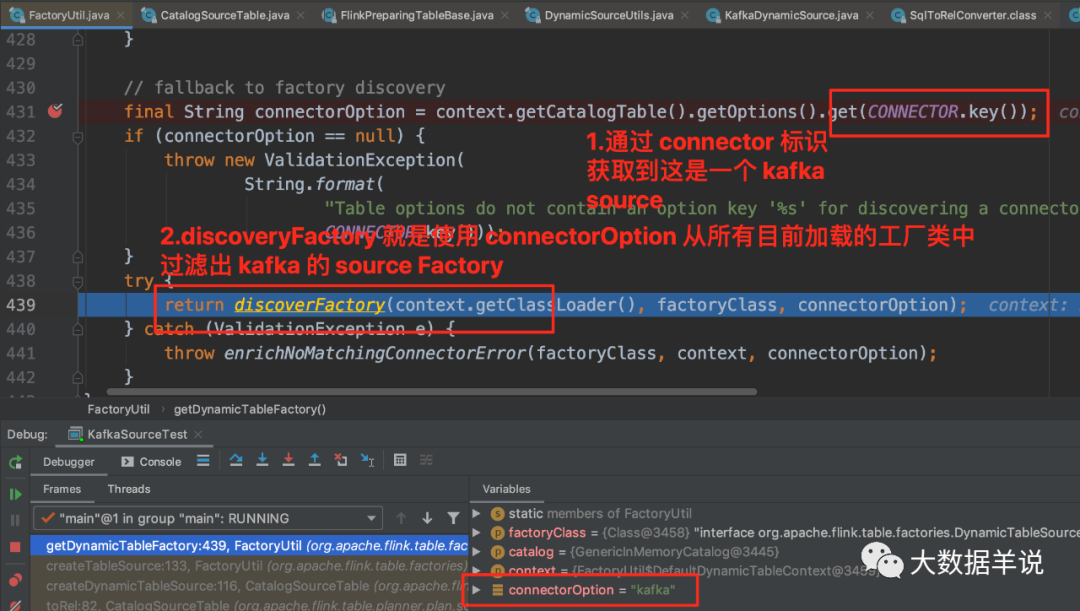
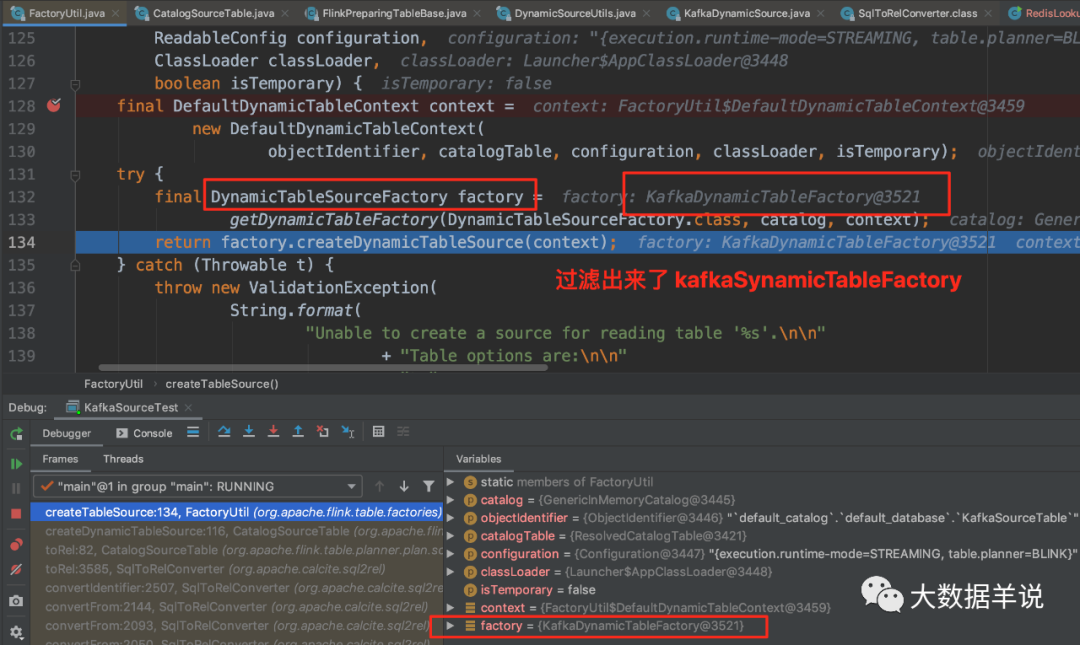
然后 KafkaDynamicTableFactory.createDynamicTableSource 去创建对应的 source。
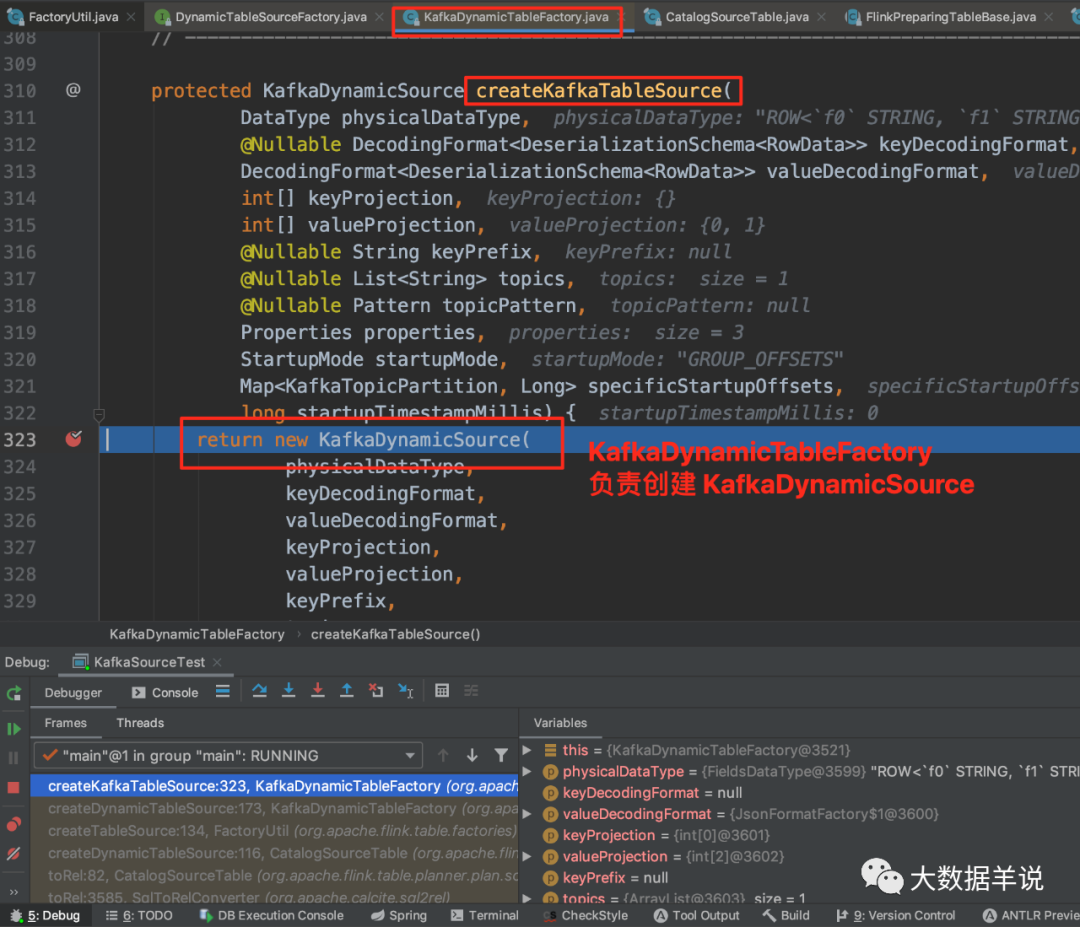
13
可以看到 KafkaDynamicTableFactory.createDynamicTableSource 中调用 KafkaDynamicTableFactory.createKafkaTableSource 来创建 KafkaDynamicSource。
基本上整个创建 Source 的流程就结束了。
5.2.format 怎样映射到具体 serde?
结论:
-
MetaData:和 connector 都一样
-
Planning:format 是在创建 RelNode 的过程中,使用
KafkaDynamicTableFactory创建出KafkaDynamicSource时,通过 SPI 去动态过滤出 format = json 并且继承自DeserializationFormatFactory.class的 format 工厂类JsonFormatFactory。 -
Runtime:
KafkaDynamicSource创建出FlinkKafkaConsumer时,实例化 serde 即JsonRowDataDeserializationSchema,负责 flink 程序实际运行时的反序列化。
源码:
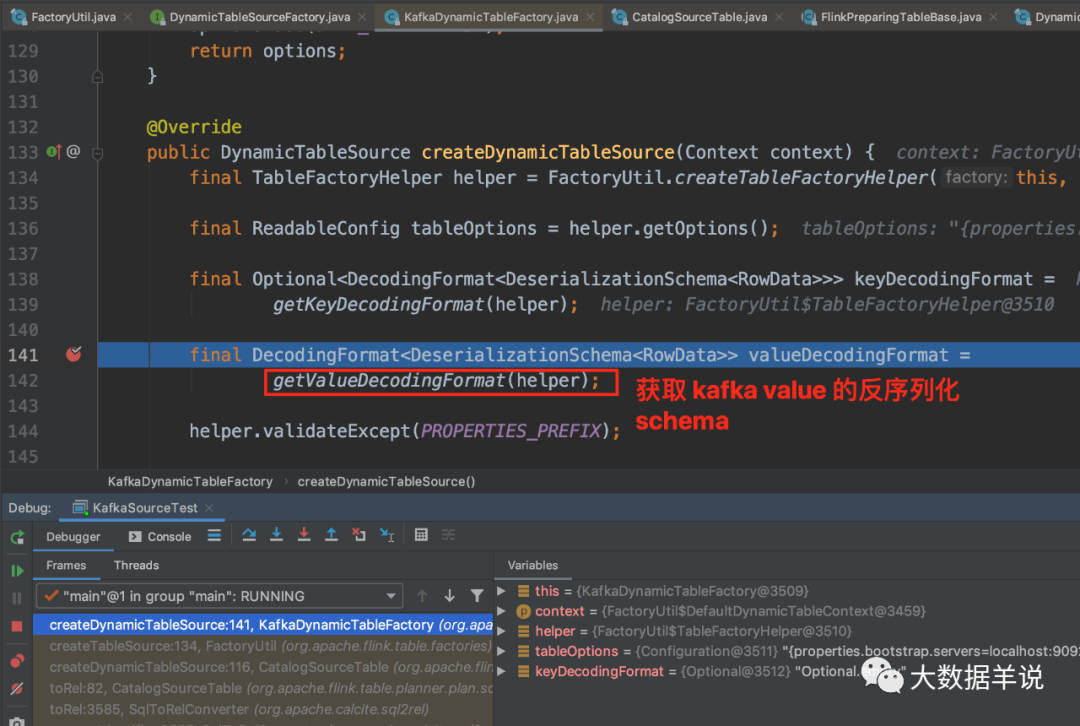
15
KafkaDynamicTableFactory.createDynamicTableSource 中获取反序列化 schema 定义。
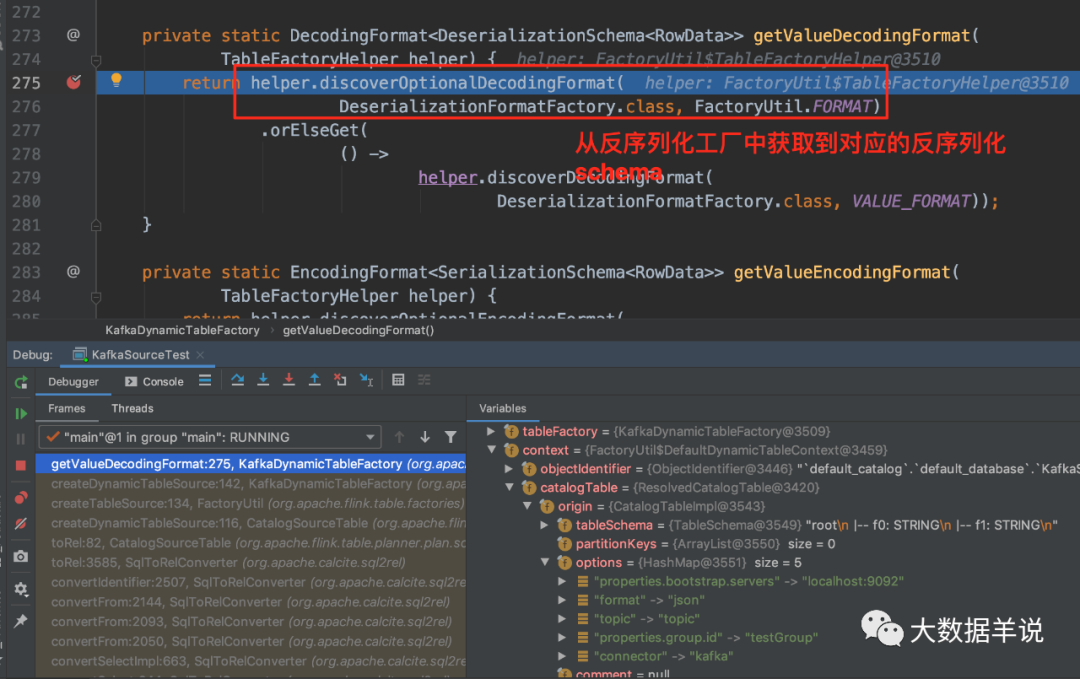
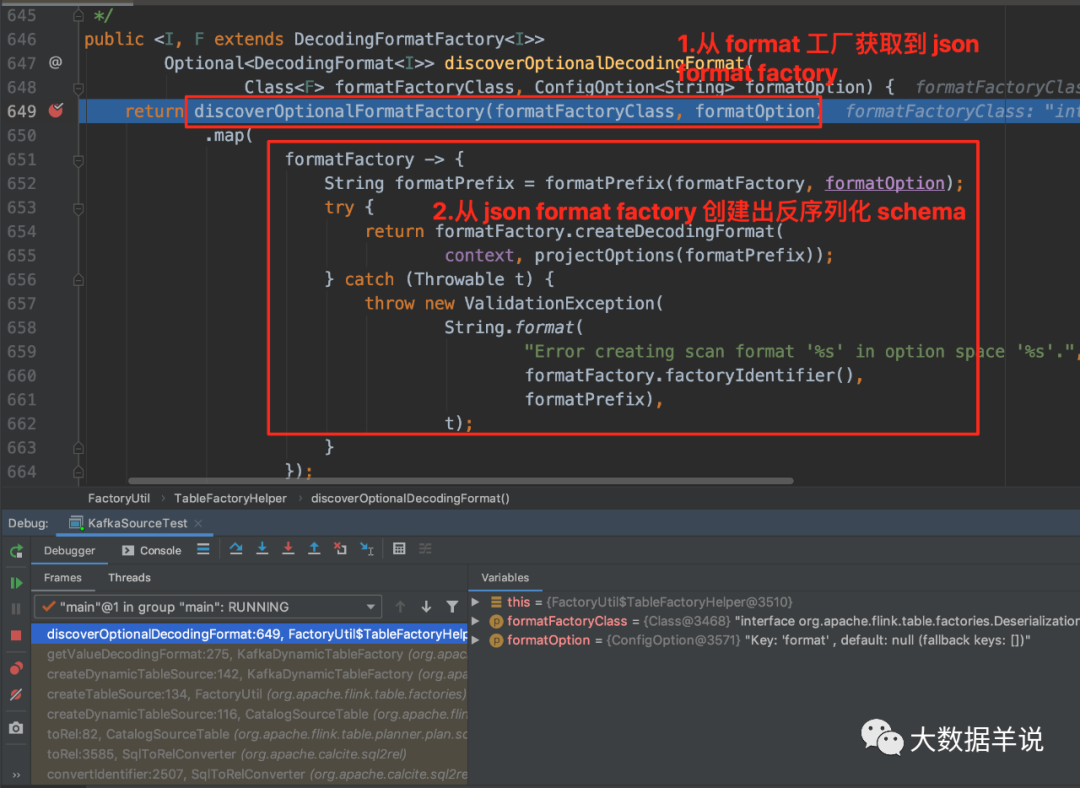
18
-
flink 是使用了 SPI 机制动态(SPI 机制天然插件化)的加载到了所有继承了
Factory的 format 工厂实例。 -
通过 format = json 的标识并且继承自
DeserializationFormatFactory.class去过滤出JsonFormatFactory。
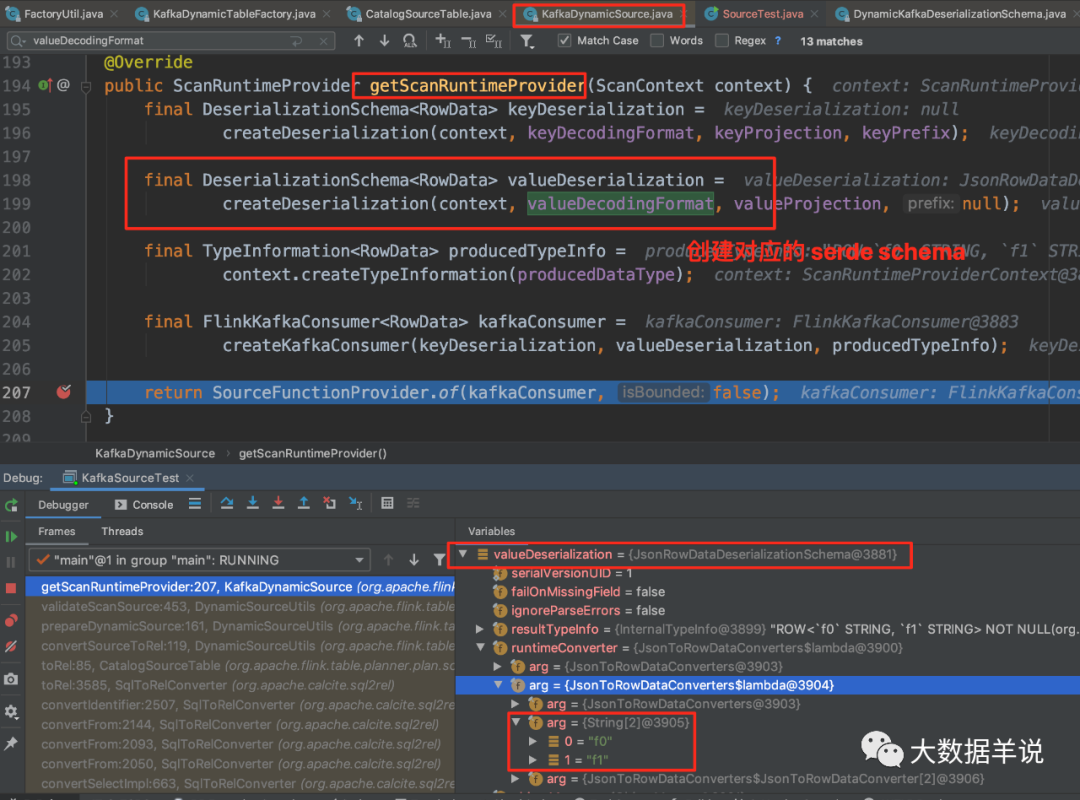
20
5.3.其他配置属性怎么加载?
结论:
在 KafkaDynamicTableFactory 创建 KafkaDynamicTable 的过程中初始化。
源码:
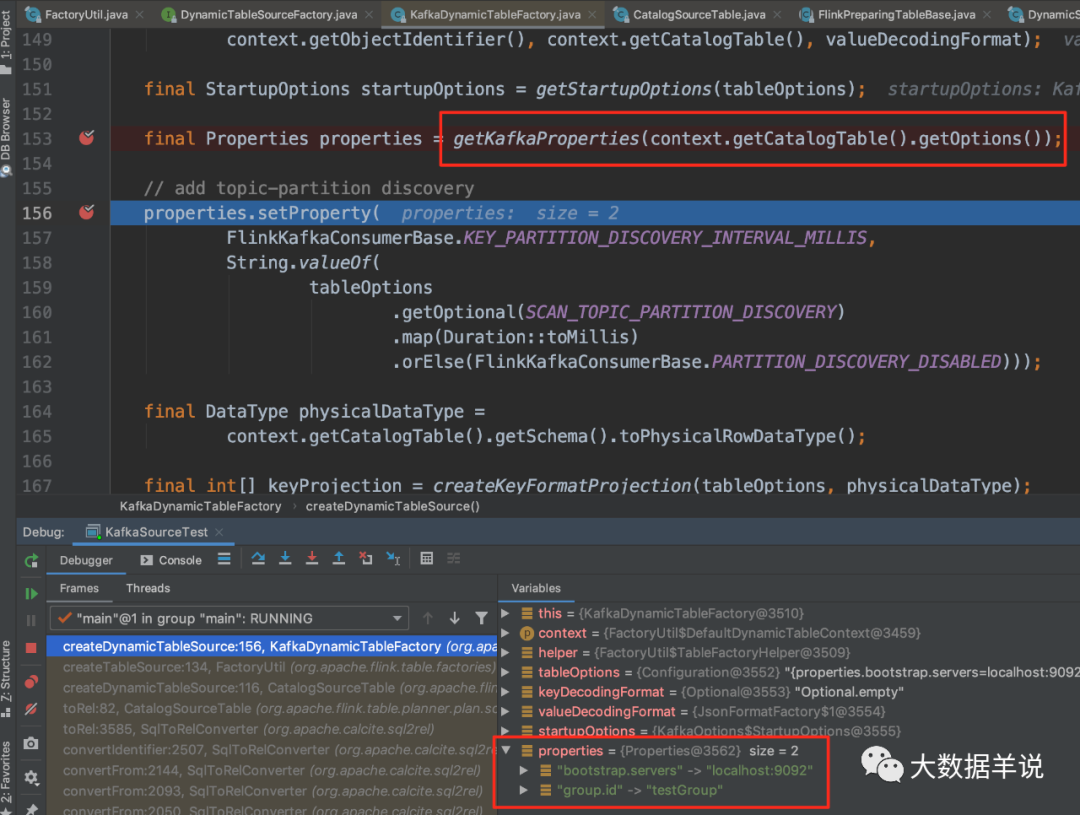
14
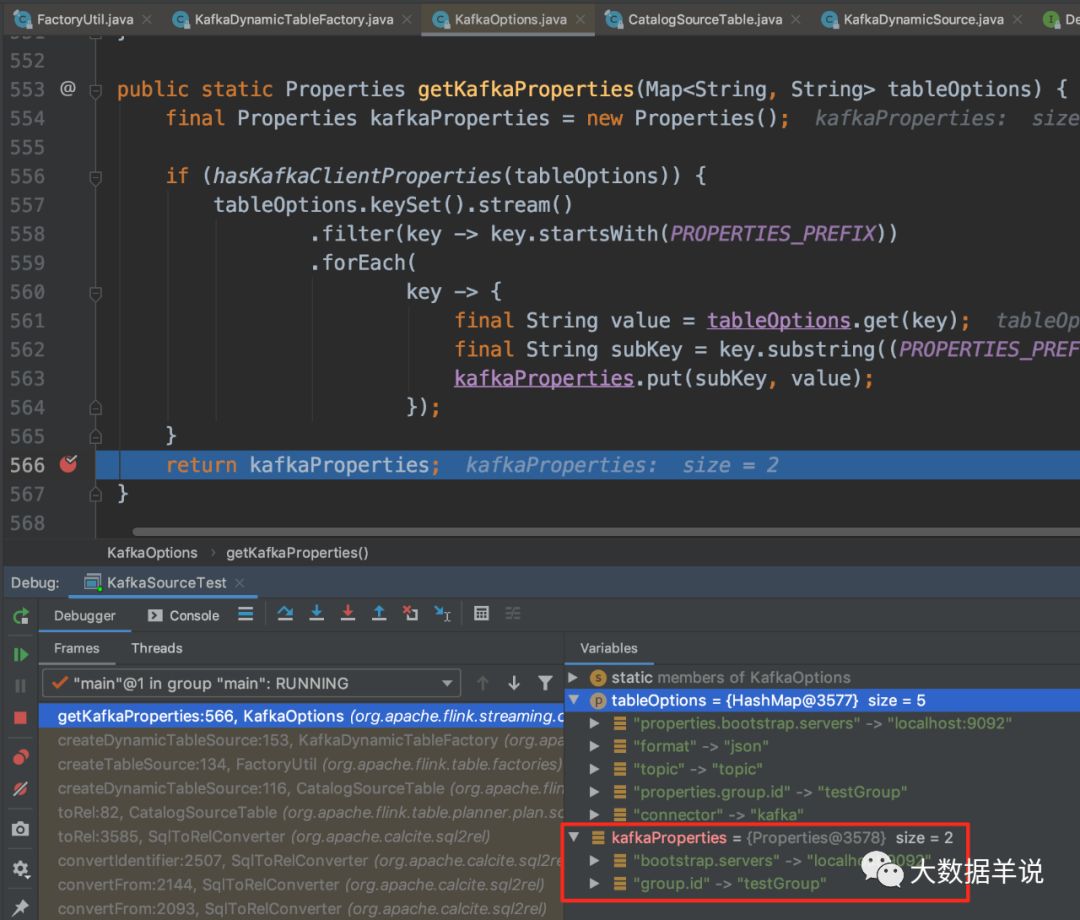
21
6.总结与展望篇
本文作为 flink sql 知其然系列的第一节,基于 1.13.1 版本 flink 介绍了 flink sql 的 source\sink\format 从 sql 变为可执行代码的原理。带大家过了一下源码。希望可以喜欢。
下节预告:flink sql 自定义 source\sink。