1.序篇
源码公众号后台回复1.13.2 sql hive udf获取。
废话不多说,咱们先直接上本文的目录和结论,小伙伴可以先看结论快速了解博主期望本文能给小伙伴们带来什么帮助:
-
背景及应用场景介绍:博主期望你能了解到,其实很多场景下实时数仓的建设都是随着离线数仓而建设的(相同的逻辑在实时数仓中重新实现一遍),因此能够在 flink sql 中复用 hive udf 是能够大大提高人效的。
-
flink 扩展支持 hive 内置 udf:flink sql 提供了扩展 udf 的能力,即 module,并且 flink sql 也内置了 HiveModule(需要你主动加载进环境),来支持一些 hive 内置的 udf (比如 get_json_object)给小伙伴们使用。
-
flink 扩展支持用户自定义的 hive udf:主要介绍 flink sql 流任务中,不能使用 create temporary function 去引入一个用户自定义的 hive udf。因此博主只能通过 flink sql 提供的 module 插件能力,自定义了 module,来支持引入用户自定义的 hive udf。
2.背景及应用场景介绍
其实大多数公司都是从离线数仓开始建设的。相信大家必然在自己的生产环境中开发了非常多的 hive udf。随着需求对于时效性要求的增高,越来越多的公司也开始建设起实时数仓。很多场景下实时数仓的建设都是随着离线数仓而建设的。实时数据使用 flink 产出,离线数据使用 hive\spark 产出。
那么回到我们文章标题的问题:为什么需要 flink 支持 hive udf 呢?
博主分析了下,结论如下:
站在数据需求的角度来说,一般会有以下两种情况:
-
以前已经有了离线数据链路,需求方也想要实时数据。如果直接能用已经开发好的 hive udf,则不用将相同的逻辑迁移到 flink udf 中,并且后续无需费时费力维护两个 udf 的逻辑一致性。
-
实时和离线的需求都是新的,需要新开发。如果只开发一套 udf,则事半功倍。
因此在 flink 中支持 hive udf 这件事对开发人员提效来说是非常有好处的。
3.在扩展前,你需要知道一些基本概念
flink 支持 hive udf 这件事分为两个部分。
-
flink 扩展支持 hive 内置 udf
-
flink 扩展支持用户自定义 hive udf
第一部分:flink 扩展支持 hive 内置 udf,比如 get_json_object,rlike 等等。
有同学问了,这么基本的 udf,flink 都没有吗?
确实没有。关于 flink sql 内置的 udf 见如下链接,大家可以看看 flink 支持了哪些 udf:https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/functions/systemfunctions/
那么如果我如果强行使用 get_json_object 这个 udf,会发生啥呢?结果如下图。
直接报错找不到 udf。
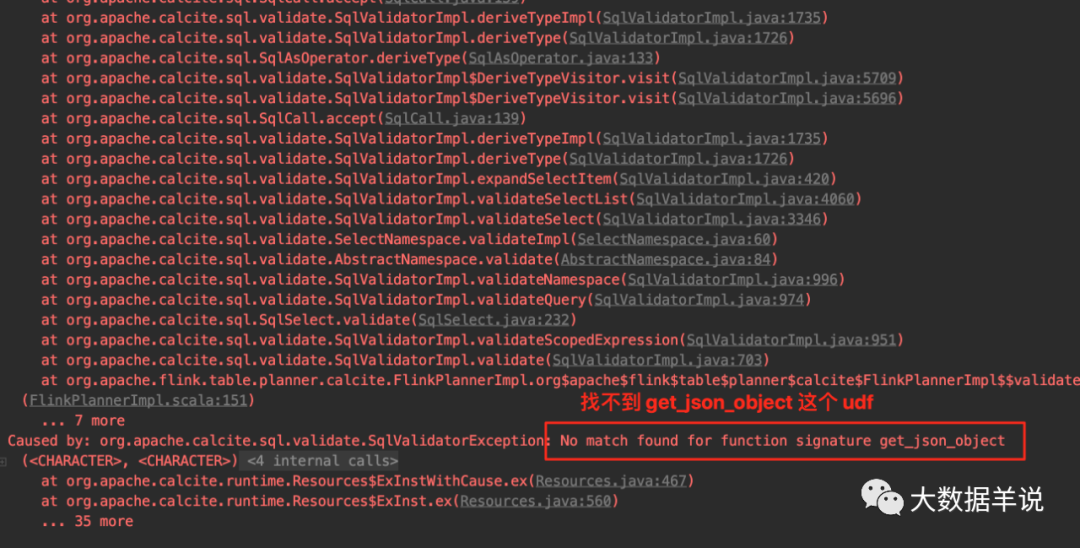
error
第二部分:flink 扩展支持用户自定义 hive udf。
内置函数解决不了用户的复杂需求,用户就需要自己写 hive udf,并且这部分自定义 udf 也想在 flink sql 中使用。
下面看看怎么在 flink sql 中进行这两种扩展。
4.hive udf 扩展支持
4.1.flink sql module
涉及到扩展 udf 就不得不提到 flink 提供的 module。见官网下图。
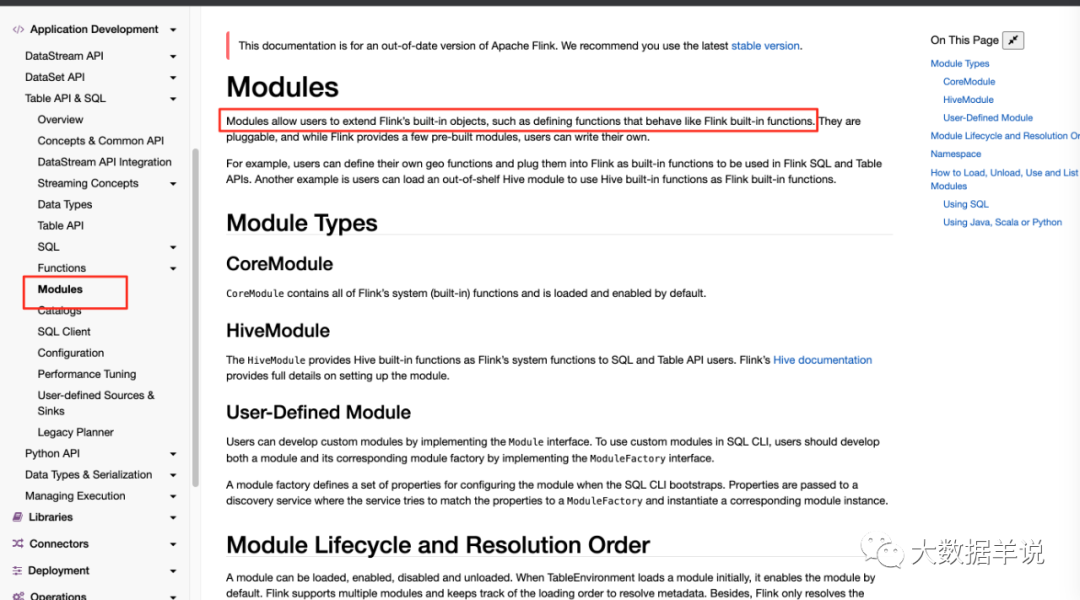
module
从第一句话就可以看到,module 的作用就是让用户去扩展 udf 的。
flink 本身已经内置了一个 module,名字叫 CoreModule,其中已经包含了一些 udf。
那我们要怎么使用 module 这玩意去扩展我们的 hive udf 呢?
4.2.flink 扩展支持 hive 内置 udf
步骤如下:
- 引入 hive 的 connector。其中包含了 flink 官方提供的一个
HiveModule。在HiveModule中包含了 hive 内置的 udf。
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-hive_${scala.binary.version}</artifactId><version>${flink.version}</version>
</dependency>- 在
StreamTableEnvironment中加载HiveModule。
String name = "default";
String version = "3.1.2";
tEnv.loadModule(name, new HiveModule(version));然后在控制台打印一下目前有的 module。
String[] modules = tEnv.listModules();
Arrays.stream(modules).forEach(System.out::println);然后可以看到除了 core module,还有我们刚刚加载进去的 default module。
default
core- 查看所有 module 的所有 udf。在控制台打印一下。
String[] functions = tEnv.listFunctions();
Arrays.stream(functions).forEach(System.out::println);就会将 default 和 core module 中的所有包含的 udf 给列举出来,当然也就包含了 hive module 中的 get_json_object。
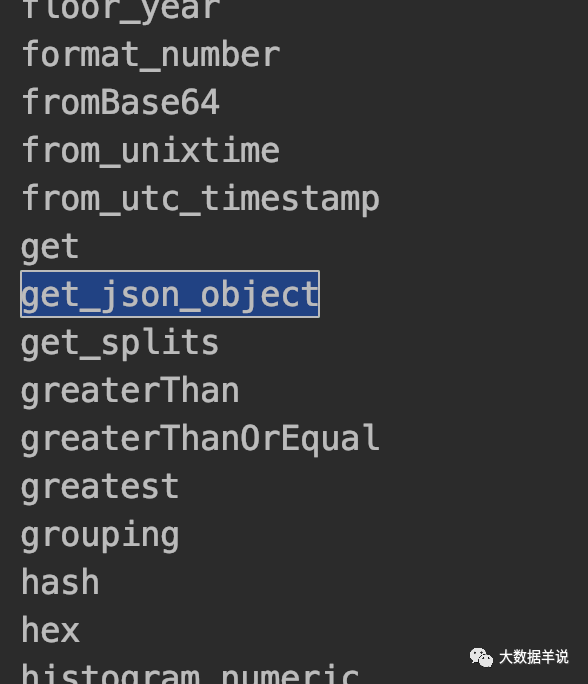
get_json_object
然后我们再去在 flink sql 中使用 get_json_object 这个 udf,就没有报错,能正常输出结果了。
使用 flink hive connector 自带的 HiveModule,已经能够解决很大一部分常见 udf 使用的问题了。
4.2.flink 扩展支持用户自定义 hive udf
原本博主是直接想要使用 flink sql 中的 create temporary function 去执行引入自定义 hive udf 的。
举例如下:
CREATE TEMPORARY FUNCTION test_hive_udf as 'flink.examples.sql._09.udf._02_stream_hive_udf.TestGenericUDF';发现在执行这句 sql 时,是可以执行成功,将 udf 注册进去的。
但是在后续 udf 初始化时就报错了。具体错误如下图。直接报错 ClassCastException。
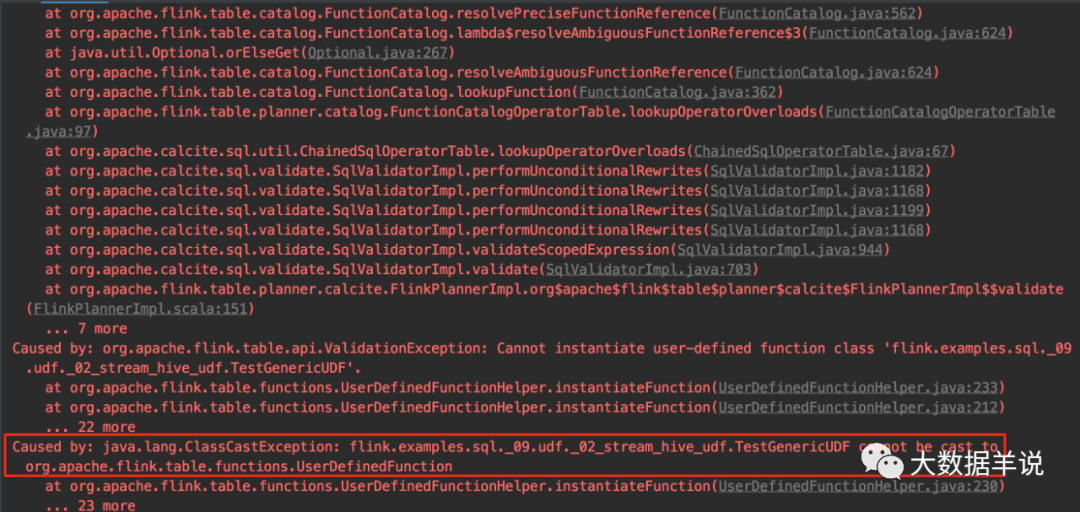
ddl hive udf error
看了下源码,flink 流环境下(未连接 hive catalog 时)在创建 udf 时会认为这个 udf 是 flink 生态体系中的 udf。
所以在初始化我们引入的 TestGenericUDF 时,默认会按照 flink 的 UserDefinedFunction 强转,因此才会报强转错误。
那么我们就不能使用 hive udf 了吗?
错误,小伙伴萌岂敢有这种想法。博主都把这个标题列出来了(牛逼都吹出去了),还能给不出解决方案嘛。
思路见下一章节。
4.3.flink 扩展支持用户自定义 hive udf 的增强 module
其实思路很简单。
使用 flink sql 中的 create temporary function 虽然不能执行,但是 flink 提供了插件化的自定义 module。
我们可以扩展一个支持用户自定义 hive udf 的 module,使用这个 module 来支持自定义的 hive udf。
实现的代码也非常简单。简单的把 flink hive connector 提供的 HiveModule 做一个增强即可,即下图中的 HiveModuleV2。
使用方式如下图所示:
源码公众号后台回复1.13.2 sql hive udf获取。
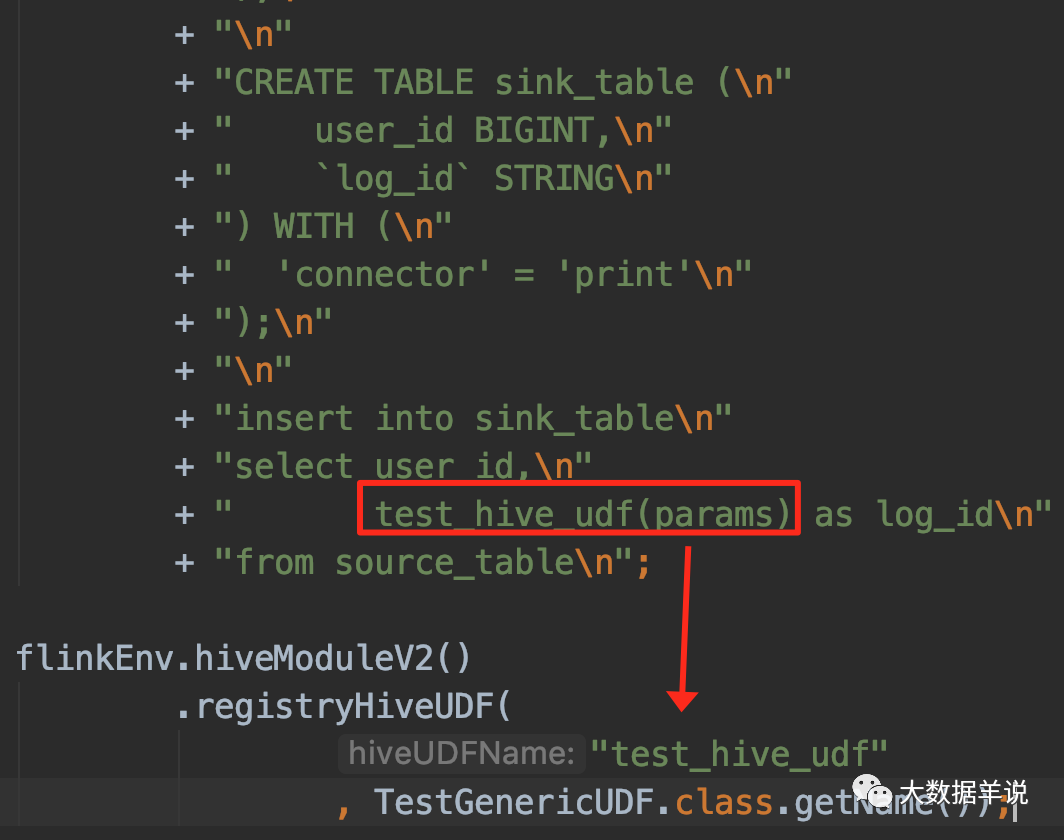
hive module enhance
然后程序就正常跑起来了。
肥肠滴好用!
5.总结与展望
源码公众号后台回复1.13.2 sql hive udf获取。
本文主要介绍了如果在 flink sql 使用 hive 内置 udf 及用户自定义 hive udf,总结如下:
-
背景及应用场景介绍:博主期望你能了解到,其实很多场景下实时数仓的建设都是随着离线数仓而建设的(相同的逻辑在实时数仓中重新实现一遍),因此能够在 flink sql 中复用 hive udf 是能够大大提高人效的。
-
flink 扩展支持 hive 内置 udf:flink sql 提供了扩展 udf 的能力,即 module,并且 flink sql 也内置了 HiveModule(需要你主动加载进环境),来支持一些 hive 内置的 udf (比如 get_json_object)给小伙伴们使用。
-
flink 扩展支持用户自定义的 hive udf:主要介绍 flink sql 流任务中,不能使用 create temporary function 去引入一个用户自定义的 hive udf。因此博主只能通过 flink sql 提供的 module 插件能力,自定义了 module,来支持引入用户自定义的 hive udf。