МЏГЩбЇЯА
(НиЭМРДздЁЖЮїЙЯЪщЁЗ)

Bagging
- ДгдЪМбљБОМЏжаЫцЛњВЩбљЁЃУПТжДгдЪМбљБОМЏжагаЗХЛиЕФбЁШЁnИібЕСЗбљБОЃЈдкбЕСЗМЏжаЃЌгааЉбљБОПЩФмБЛЖрДЮГщШЁЕНЃЌЖјгааЉбљБОПЩФмвЛДЮЖМУЛгаБЛГщжаЃЉЁЃЙВНјааkТжГщШЁЃЌЕУЕНkИібЕСЗМЏЁЃЃЈbootstrapЕФЙ§ГЬЃЌгЩгкЪЧгаЗХЛиГщбљЃЌЫљвдkИібЕСЗМЏжЎМфЯрЛЅЖРСЂЃЉ
- УПДЮЪЙгУвЛЗнбЕСЗМЏбЕСЗвЛИіФЃаЭЃЌk ИібЕСЗМЏЙВЕУЕН k ИіЛљФЃаЭЁЃЃЈзЂЃКетРяВЂУЛгаОпЬхЕФЗжРрЫуЗЈЛђЛиЙщЗНЗЈЃЌЮвУЧПЩвдИљОнОпЬхЮЪЬтВЩгУВЛЭЌЕФЗжРрЛђЛиЙщЗНЗЈЃЌШчОіВпЪїЁЂИажЊЦїЕШЃЉ
- РћгУетkИіЛљФЃаЭЖдВтЪдМЏНјаадЄВтЃЌНЋkИідЄВтНсЙћНјааОлКЯЁЃ(aggregatingЕФЙ§ГЬ)
- ЗжРрЮЪЬтЃКНЋЩЯВНЕУЕНЕФkИіФЃаЭВЩгУЭЖЦБЕФЗНЪНЕУЕНЗжРрНсЙћ
- ЛиЙщЮЪЬтЃКМЦЫуЩЯЪіФЃаЭЕФОљжЕзїЮЊзюКѓЕФНсЙћЁЃЃЈЫљгаФЃаЭЕФживЊадЯрЭЌЃЉ
(11ЬѕЯћЯЂ) ЛњЦїбЇЯАжЎEnsembleЃЈBaggingЁЂAdaBoostЁЂGBDTЁЂStackingЃЉ_Cyril_KIЕФВЉПЭ-CSDNВЉПЭ
ЁОЪЕеНЁП5ИіМЏГЩбЇЯАзюГЃгУЕФЗНЗЈ - ВњЦЗОРэЕФШЫЙЄжЧФмбЇЯАПт (easyai.tech)
ЫцЛњЩСж
- Sklearn Random Forest Classifiers in Python - DataCamp
ЫцЛњЩСж(Random Forest,МђГЦRF) ЪЧBaggingЕФвЛИіРЉеЙБфЬх.
RFдквдОіВпЪїЮЊЛљбЇЯАЦїЙЙНЈBaggingМЏГЩЕФЛљДЁЩЯЃЌНјвЛВНдкОіВпЪїЕФбЕСЗЙ§ГЬжав§ШыСЫЫцЛњЪєадбЁдё.
ОпЬхРДЫЕ:
- ДЋЭГОіВпЪїдкбЁдёЛЎЗжЪєадЪБЪЧдкЕБЧАНсЕуЕФЪєадМЏКЯ(МйЖЈгаdИіЪєад)жабЁдё-вЛИі зюгХЪєад;
- ЖјдкRFжаЃЌЖдЛљОіВпЪїЕФУПИіНсЕуЃЌЯШДгИУНсЕуЕФЪєадМЏКЯжаЫцЛњбЁдё-вЛИіАќКЌkИіЪєадЕФзгМЏЃЌШЛКѓдйДгетИізгМЏжабЁдёвЛИізюгХЪєадгУгкЛЎЗж.
- етРяЕФВЮЪ§kПижЦСЫЫцЛњадЕФв§ШыГЬЖШ:ШєСюk:=d,дђЛљОіВпЪїЕФЙЙНЈгыДЋЭГОіВпЪїЯрЭЌ; ШєСюk:=1,дђЪЧЫцЛњбЁдё-вЛИіЪєадгУгкЛЎЗж;-АуЧщПіЯТЃЌЭЦМіжЕk:=log2dЁЃ
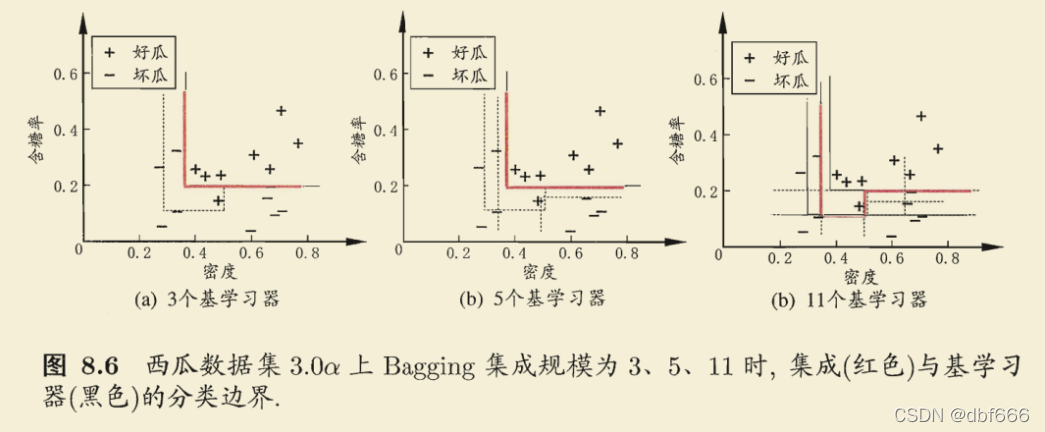
ЬиЕуЃКМђЕЅЁЂвзЪЕЯжЁЂПЊЯњаЁЃЌБЛгўЮЊДњБэМЏГЩбЇЯАММЪѕЕФЗНЗЈ
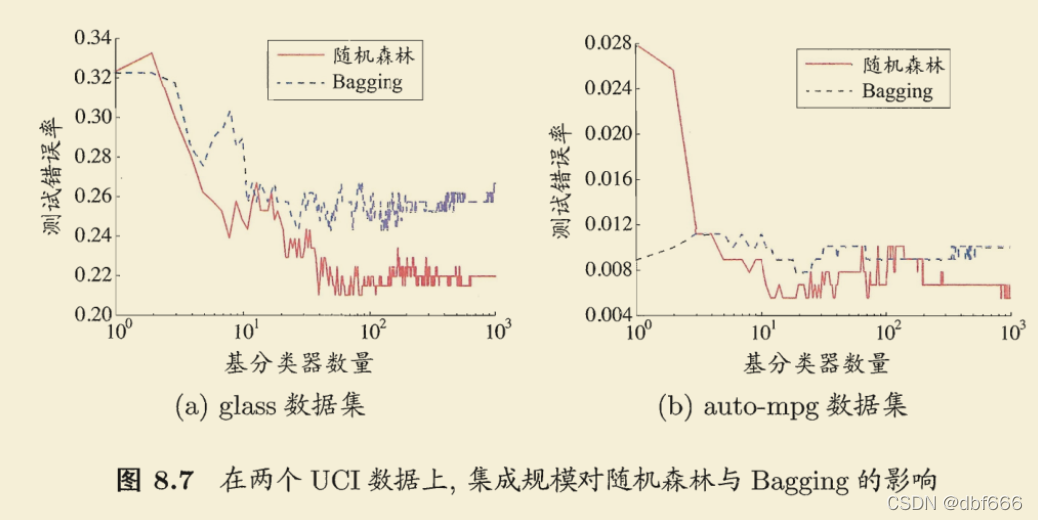
ЫцЛњЩСжЕФЪеСВадгыBaggingЯрЫЦ:
- ЫцЛњЩСжЕФ
Ц№ЪМадФмЭљЭљЯрЖдНЯВюЃЌЬиБ№ЪЧдкМЏГЩжажЛАќКЌ-вЛИіЛљбЇЯАЦїЪБ;(вђЮЊЭЈЙ§в§ШыЪєадШХЖЏЃЌЫцЛњЩСжжаИіЬхбЇЯАЦїЕФадФмЭљЭљгаЫљНЕЕЭ) - ШЛЖјЃЌЫцзХ
ИіЬхбЇЯАЦїЪ§ФПЕФдіМгЃЌЫцЛњЩСжЭЈГЃЛсЪеСВЕНИќЕЭЕФЗКЛЏЮѓВюЁЃ - жЕЕУвЛЬсЕФЪЧЃЌЫцЛњЩСжЕФ
бЕСЗаЇТЪГЃгХгкBagging,вђЮЊдкИіЬхОіВпЪїЕФЙЙНЈЙ§ГЬжаЃЌBaggingЪЙгУЕФЪЧЁАШЗЖЈаЭЁБОіВпЪїЃЌдкбЁдёЛЎЗжЪєадЪБвЊЖдНсЕуЕФЫљгаЪєадНјааПМВьЃЌЖјЫцЛњЩСжЪЙгУЕФЁАЫцЛњаЭЁБОіВпЪїдђжЛашПМВьвЛИіЪєадзгМЏЁЃ
Boosting
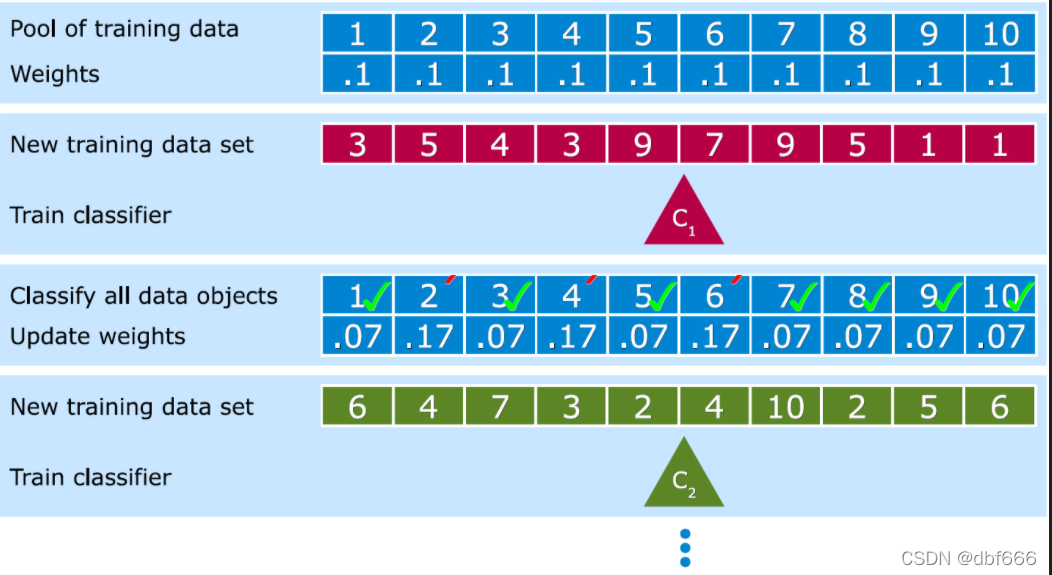
BoostingЕФКЫаФЫМЯыЪЧНЋЖрИіШѕЗжРрЦїзщзАГЩвЛИіЧПЗжРрЦї ЁЃ
ЙигкBoostingЕФСНИіКЫаФЮЪЬтЃК
1ЃЉдкУПвЛТжШчКЮИФБфбЕСЗЪ§ОнЕФШЈжЕЛђИХТЪЗжВМЃП
ЭЈЙ§ЬсИпФЧаЉдкЧАвЛТжБЛШѕЗжРрЦїЗжДэбљР§ЕФШЈжЕЃЌМѕаЁЧАвЛТжЗжЖдбљР§ЕФШЈжЕЃЌРДЪЙЕУЗжРрЦїЖдЮѓЗжЕФЪ§ОнгаНЯКУЕФаЇЙћЁЃ
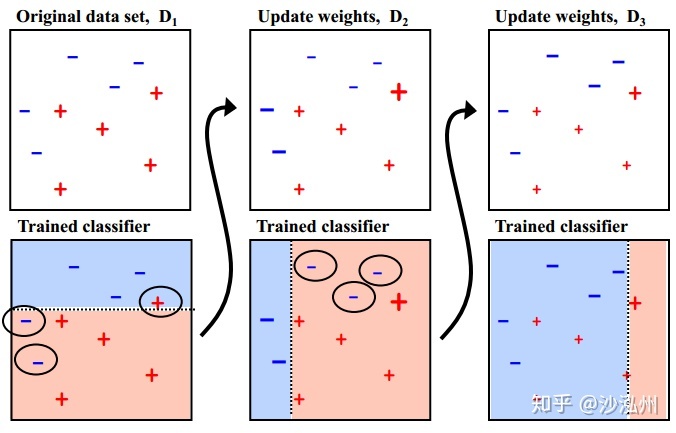
2ЃЉЭЈЙ§ЪВУДЗНЪНРДзщКЯШѕЗжРрЦїЃП
ЭЈЙ§МгЗЈФЃаЭНЋШѕЗжРрЦїНјааЯпадзщКЯЃЌБШШчAdaBoostЭЈЙ§МгШЈЖрЪ§БэОіЕФЗНЪНЃЌМДдіДѓДэЮѓТЪаЁЕФЗжРрЦїЕФШЈжЕЃЌЭЌЪБМѕаЁДэЮѓТЪНЯДѓЕФЗжРрЦїЕФШЈжЕЁЃ
ЖјЬсЩ§ЪїЭЈЙ§ФтКЯВаВюЕФЗНЪНж№ВНМѕаЁВаВюЃЌНЋУПвЛВНЩњГЩЕФФЃаЭЕўМгЕУЕНзюжеФЃаЭЁЃ
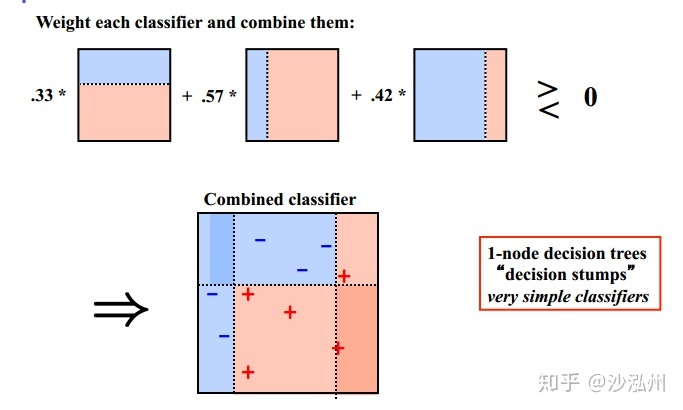
BoostingЫуЗЈЬиЕуЃК
1ЁЂађЙсЪНМЏГЩЗНЗЈЃЈSequential EnsembleЃЉЁЃУПТжЕќДњЩњГЩЕФЛљФЃаЭЃЌжївЊЬсЩ§ЧАвЛДњЛљФЃаЭБэЯжВЛКУЕФЕиЗНЁЃ
2ЁЂДгЦЋВюЗНВюЗжНт[[е§дђЛЏгыЦЋВю-ЗНВюЗжНт bias-variance]]ЕФНЧЖШПДЃЌжївЊЙизЂНЕЕЭЦЋВюЃЌМДВЛЖЯЕќДњШѕЗжРрЦїЃЌДгЖјНЕЕЭ BiasЁЃвђДЫЃЌЪЪгУгк Low Variance & High Bias ЕФФЃаЭЁЃФмЛљгкЗКЛЏадФмЯрЕБШѕЕФбЇЯАЦїЙЙНЈГіКмЧПЕФМЏГЩЁЃ
ЛљгкBoostingЫуЗЈЕфаЭДњБэ
ШчAdaBoostЁЂGBDTЁЂXGBoostЕШЁЃ
Adaboost


ЁОЮхЗжжгЛњЦїбЇЯАЁПAdaboostЃКЧАШЫддЪїКѓШЫГЫСЙ_пйСЈпйСЈ_bilibili
3ИіЙигкAdaBoostЕФИХФю_пйСЈпйСЈ_bilibili
ЛњЦїбЇЯАжЎЪ§бЇжЎТУ-ДгСуЭЦЕМadaboostгы3DПЩЪгЛЏ-ЬиеїбЁдё-МЏЬхжЧФм-МЏГЩбЇЯА-boosting_пйСЈпйСЈ_bilibili
BaggingЃЌBoostingЖўепжЎМфЕФЧјБ№
1ЃЉбљБОбЁдёЩЯЃК
BaggingЃКбЕСЗМЏЪЧдкдЪММЏжагаЗХЛибЁШЁЕФЃЌДгдЪММЏжабЁГіЕФИїТжбЕСЗМЏжЎМфЪЧЖРСЂЕФЁЃ
BoostingЃКУПвЛТжЕФбЕСЗМЏВЛБфЃЌжЛЪЧбЕСЗМЏжаУПИібљР§дкЗжРрЦїжаЕФШЈжиЗЂЩњБфЛЏЁЃЖјШЈжЕЪЧИљОнЩЯвЛТжЕФЗжРрНсЙћНјааЕїећЁЃ
2ЃЉбљР§ШЈжиЃК
BaggingЃКЪЙгУОљдШШЁбљЃЌУПИібљР§ЕФШЈжиЯрЕШ
BoostingЃКИљОнДэЮѓТЪВЛЖЯЕїећбљР§ЕФШЈжЕЃЌДэЮѓТЪдНДѓдђШЈжидНДѓЁЃ
3ЃЉдЄВтКЏЪ§ЃК
BaggingЃКЫљгадЄВтКЏЪ§ЕФШЈжиЯрЕШЁЃ
BoostingЃКУПИіШѕЗжРрЦїЖМгаЯргІЕФШЈжиЃЌЖдгкЗжРрЮѓВюаЁЕФЗжРрЦїЛсгаИќДѓЕФШЈжиЁЃ
4ЃЉВЂааМЦЫуЃК
BaggingЃКИїИідЄВтКЏЪ§ПЩвдВЂааЩњГЩ
BoostingЃКИїИідЄВтКЏЪ§жЛФмЫГађЩњГЩЃЌвђЮЊКѓвЛИіФЃаЭВЮЪ§ашвЊЧАвЛТжФЃаЭЕФНсЙћЁЃ
змНс
етСНжжЗНЗЈЖМЪЧАбШєИЩИіЗжРрЦїећКЯЮЊвЛИіЗжРрЦїЕФЗНЗЈЃЌжЛЪЧећКЯЕФЗНЪНВЛвЛбљЃЌзюжеЕУЕНВЛвЛбљЕФаЇЙћЃЌНЋВЛЭЌЕФЗжРрЫуЗЈЬзШыЕНДЫРрЫуЗЈПђМмжавЛЖЈГЬЖШЩЯЛсЬсИпСЫдЕЅвЛЗжРрЦїЕФЗжРраЇЙћЃЌЕЋЪЧвВдіДѓСЫМЦЫуСПЁЃ
ЯТУцЪЧНЋОіВпЪїгыетаЉЫуЗЈПђМмНјааНсКЯЫљЕУЕНЕФаТЕФЫуЗЈЃК
- Bagging + ОіВпЪї = ЫцЛњЩСж
- AdaBoost + ОіВпЪї = ЬсЩ§Ъї
- Gradient Boosting + ОіВпЪї = GBDT