
ָ������
�Ӵ洢���������еļ��ָ�궼����ͬ�ģ������ڲ�ͬ�ij�������Щָ������һЩϸ�IJ��졣
���磬�� Node Exporter ���ص�������ָ�� node_load1 ��Ӧ������ǰϵͳ�ĸ���״̬������ʱ��ı仯���ָ�귵�ص������������ڲ��ϱ仯������ָ�� node_cpu_seconds_total ����ȡ������������ȴ��ͬ������һ�����������ֵ����Ϊ�䷴Ӧ���� CPU ���ۼ�ʹ��ʱ�����������Ͻ�ֻҪϵͳ���ػ������ֵ�ǻ�һֱ���
Ϊ���ܹ������û������������Щ��ͬ���ָ��֮��IJ��죬Prometheus ������ 4 �ֲ�ͬ��ָ�����ͣ�Counter������������Gauge���DZ��̣���Histogram��ֱ��ͼ����Summary��ժҪ����
�� node-exporter���������ϸ���⣩���ص����������У���ע����Ҳ�����˸����������͡����磺
# HELP node_cpu_seconds_total Seconds the cpus spent in each mode.
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="cpu0",mode="idle"} 362812.7890625Counter ֻ�������ļ�����
Counter (ֻ�������ļ�����) ���͵�ָ���乤����ʽ�ͼ�����һ����ֻ�����������������ڴ洢�������� HTTP ����������ʹ�õ� CPU ʱ��֮�����Ϣ�dz�������
�����ļ��ָ�꣬�� http_requests_total��node_cpu_seconds_total ���� Counter ���͵ļ��ָ�ꡣ
Counter��һ������ǿ��Ĺ��ߣ���������������Ӧ�ó����м�¼ijЩ�¼������Ĵ�����ͨ����ʱ�����ʽ�洢��Щ���ݣ����ǿ������ɵ��˽���¼��������ʵı仯�� PromQL���õľۺϲ����ͺ����������û�����Щ���ݽ��н�һ���ķ�����
���磬ͨ��rate()������ȡHTTP�������������ʣ�
rate(http_requests_total[5m])��ѯ��ǰϵͳ�У�������ǰ10��HTTP��ַ��
topk(10, http_requests_total)
����������һֱ���ӵ�����ûʲô�ô����˽����ӿ�ʼ�ж���������ʲô��ֵ�𣿵�����Ҫ��ס��ÿ��ָ�궼�洢��ʱ�������������� HTTP ���������ڿ����� 1000 ���� Prometheus Ҳ���¼֮ǰij��ʱ����ֵ�����ǿ���ȥ��ѯ��ȥһ��Сʱ�ڵ�����������Ȼ�����ʱ��������Ҫ�����������������ӻ���ٵ��ٶ��ж�죬���ͨ��������� Counter ָ�����Ƕ���ȥ�鿴�仯�ʶ����DZ��������֡�PromQL ���õľۺϲ����ͺ����������û�����Щ���ݽ��н�һ���ķ��������磬ͨ�� rate() ������ȡ HTTP ����������ʣ�
rate(http_requests_total[5m])��ȡ���ǵ�ǰ����ӵ��������ݣ�����������һ�����䣬Ҳ����һ��ʱ�䷶Χ��
counter�ڻ���ͼ�ε�ʱ��ʹ��rate����ȥ����һ�±仯�ʣ������ʡ�
Gauge �����ɼ����DZ���
�� Counter ��ͬ��Gauge�������ɼ����DZ��̣����͵�ָ�������ڷ�Ӧϵͳ�ĵ�ǰ״̬���������ָ����������ݿ����ɼ�������counter��һֱ�����ġ�
����ָ���� node_memory_MemFree_bytes����ǰ�������е��ڴ��С����node_memory_MemAvailable_bytes�������ڴ��С������ Gauge ���͵ļ��ָ�ꡣ
���� Gauge ָ����Ȼ����ʱ����洢���������ǿ��Կ�����ʱ��仯��ֵ��ͨ������ֱ�Ӱ����ǻ��Ƴ����������Ϳ��Կ���ֵ���������DZ仯������ͨ�� Gauge ָ�꣬�û�����ֱ�Ӳ鿴ϵͳ�ĵ�ǰ״̬��
�ڻ���ͼ�в鿴״̬��ʱ��ֱ��ʹ��ָ��ֵ�Ϳ��Ի��Ƴ�������Ϊ�����ͱ�ʾ��ǰ��״̬��
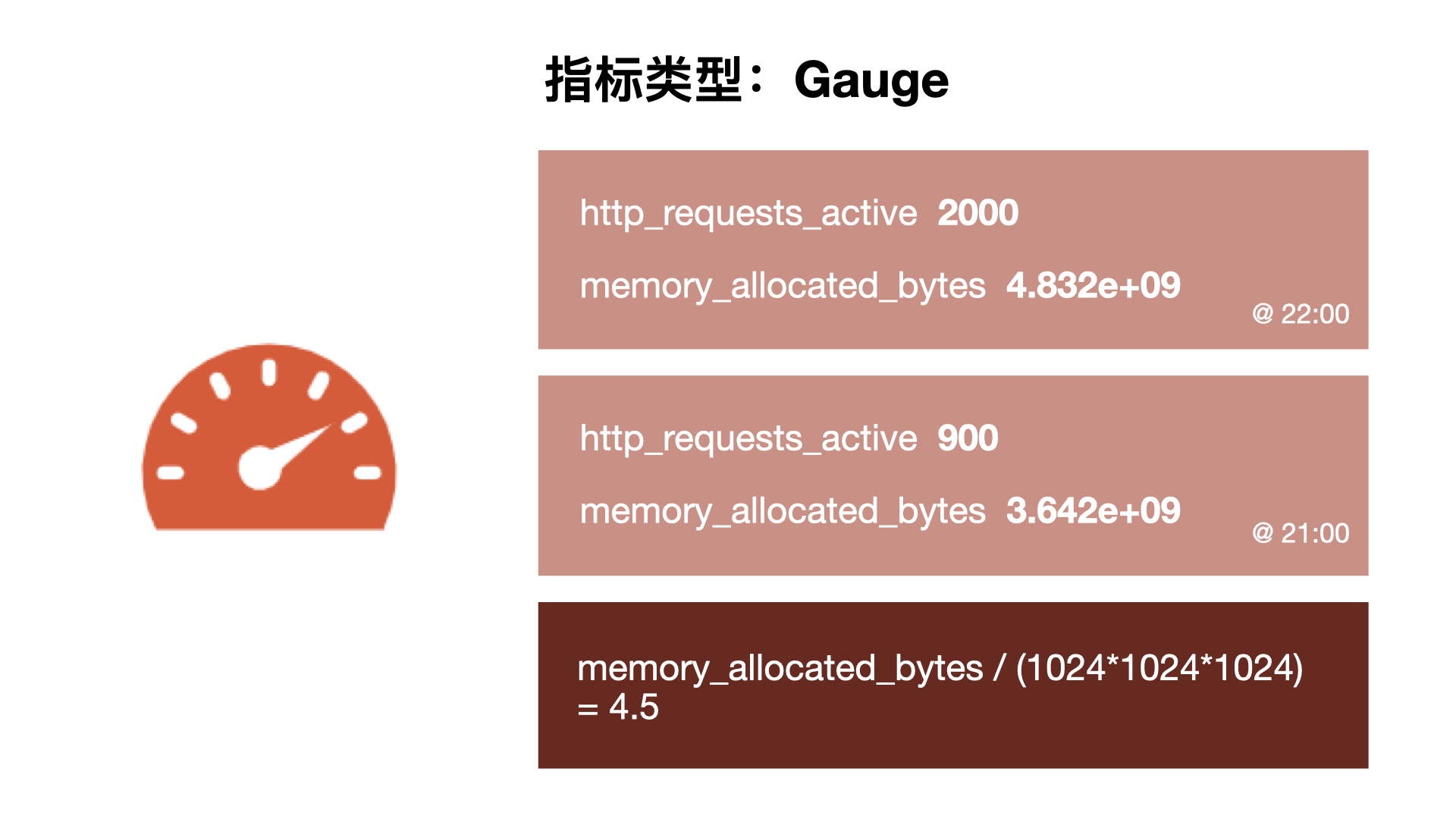
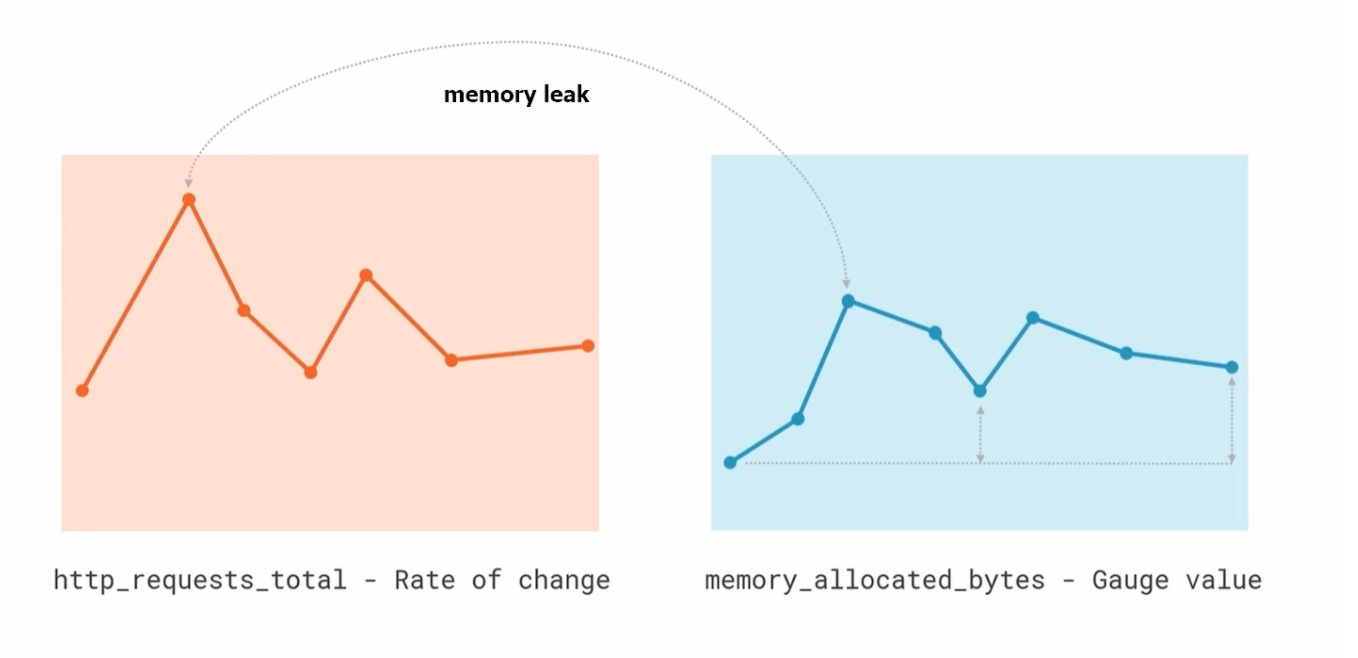
��Щ��ָ�����Ͷ�ֻ��Ϊÿ��������ȡһ���������� Prometheus ��ǿ��֮�������������������ǣ��������ǻ���������ͼ��һ���� HTTP ����ı仯�ʣ���һ���Ƿ���� gauge ���͵�ʵ���ڴ棬ֱ�Ӵ�ͼ�ϾͿ��Կ���������֮����һ�ֹ����ԣ���������ַ�ֵ��ʱ���ڴ��ʹ��Ҳ����ַ�ֵ������������ϸ�۲�Ҳ�ᷢ���ڷ�ֵ�����ڴ�ʹ������û�лָ�����ֵǰ��ˮƽ�����������������ӣ�������ܿ���Ӧ�ó����д����ڴ�й¶�����⣬ͨ����Щ��ָ��Ϳ����������ҵ���Щ���ܴ��ڵ����⡣
���� Gauge ���͵ļ��ָ�꣬ͨ�� PromQL ���ú��� delta() ���Ի�ȡ������һ��ʱ�䷶Χ�ڵı仯��������磬���� CPU �¶�������Сʱ�ڵIJ��죺
delta(cpu_temp_celsius{host="zeus"}[2h])
������ֱ��ʹ�� predict_linear() �����ݵı仯���ƽ���Ԥ�⡣���磬Ԥ��ϵͳ���̿ռ��� 4 ��Сʱ֮���ʣ����������������������Ԥ��ģ�predict_linear() ����������ڴ��̿ռ���˵�Ļ��Ƿdz����õģ���Ϊ������ʵ��ʹ�õĹ��̵���һ���Ӿ����������ˣ�����һ�������Ĺ��̣����Կ��Ը�������������ж�4��Сʱ֮�����ʣ�������������������Ϳ�����ǰȥ�����̿ռ������������ݡ�
predict_linear(node_filesystem_free_bytes[1h], 4 * 3600)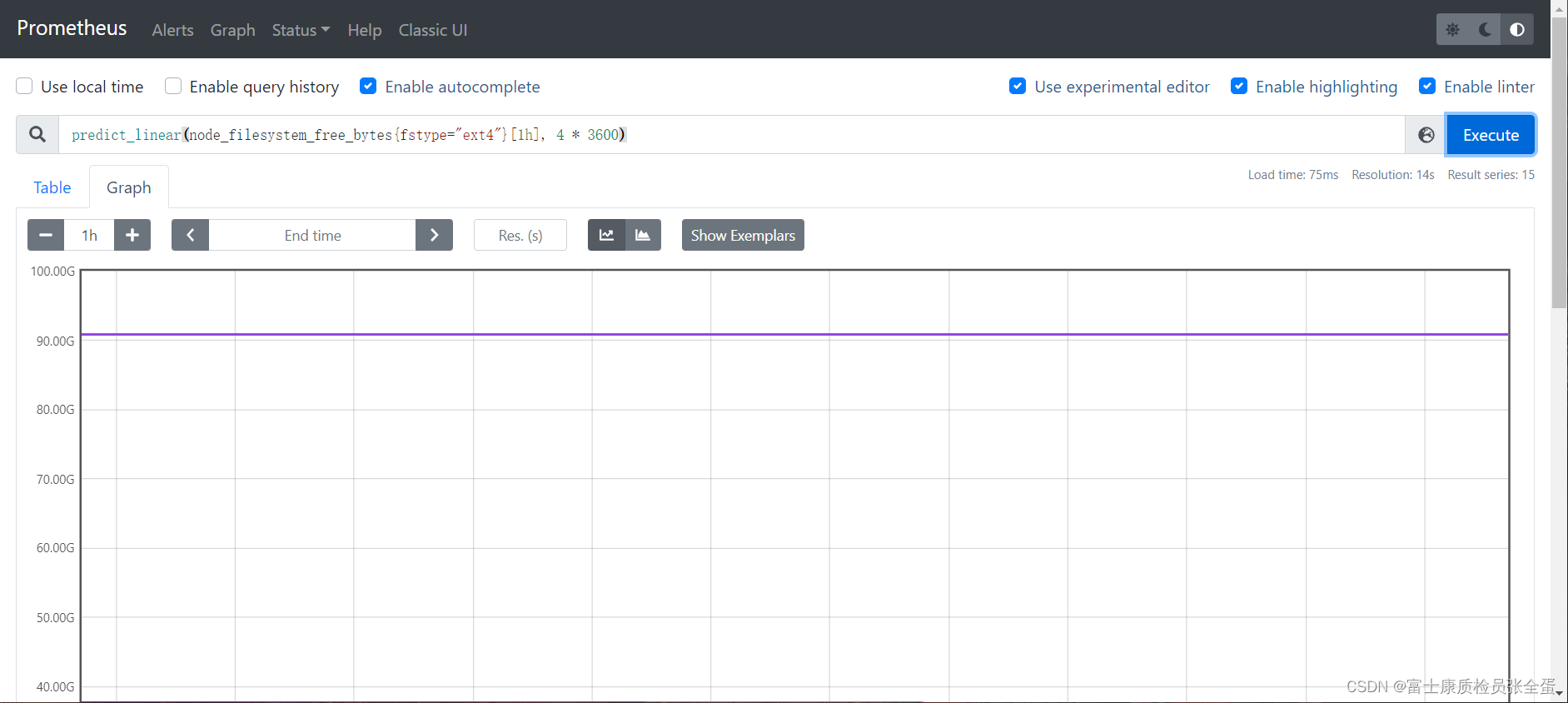
???Histogram ֱ��ͼ �� Summary ժҪ ʹ��Histogram��Summary�������ݷֲ����
���� Counter �� Gauge ���͵ļ��ָ�����⣬Prometheus �������� Histogram �� Summary ��ָ�����͡�Histogram �� Summary ��������ͳ�ƺͷ��������ķֲ������
�ڴ������������Ƕ�������ʹ��ijЩ����ָ���ƽ��ֵ������ CPU ��ƽ��ʹ���ʡ�ҳ���ƽ����Ӧʱ�䣬���ַ�ʽҲ�к����Ե����⣬��ϵͳ API ���õ�ƽ����Ӧʱ��Ϊ������������ API ����ά���� 100ms ����Ӧʱ�䷶Χ�ڣ��������������Ӧʱ����Ҫ 5s����ô�ͻᵼ��ijЩ WEB ҳ�����Ӧʱ���䵽��λ���ϣ�����������Ϊ��β������
Ϊ��������ƽ���������dz�β��������ķ�ʽ���ǰ��������ӳٵķ�Χ���з��������磬ͳ���ӳ��� 0~10ms ֮����������ж��ٶ� 10~20ms ֮������������ж��١�ͨ�����ַ�ʽ���Կ��ٷ���ϵͳ����ԭ��
Histogram �� Summary ����Ϊ���ܹ����������������ڵģ�ͨ�� Histogram ��Summary ���͵ļ��ָ�꣬���ǿ��Կ����˽����������ֲ������
Summary
ժҪ������¼ijЩ������ƽ����С�������Ǽ��������ʱ��������ļ���С��ժҪ��ʾ������ص���Ϣ��count���¼������Ĵ������� sum�������¼����ܴ�С��������ͼ����ժҪָ����Է��ش���Ϊ 3 ���ܺ� 15��Ҳ����ζ�� 3 �μ����ܹ���Ҫ 15s ��������ƽ��ÿ�μ�����Ҫ���� 5s����һ�������Ĵ���Ϊ 10���ܺ�Ϊ 113����ôƽ��ֵΪ 11.3����Ϊ����ָ�궼��¼��ʱ������������ǿ���ʹ��ժҪ������һ��ͼ������ʾƽ��ֵ�ı仯�ʣ�����ͼ�ϵ�����ʾ���� 5 ����ʱ����ڵ�ƽ�����ʡ�

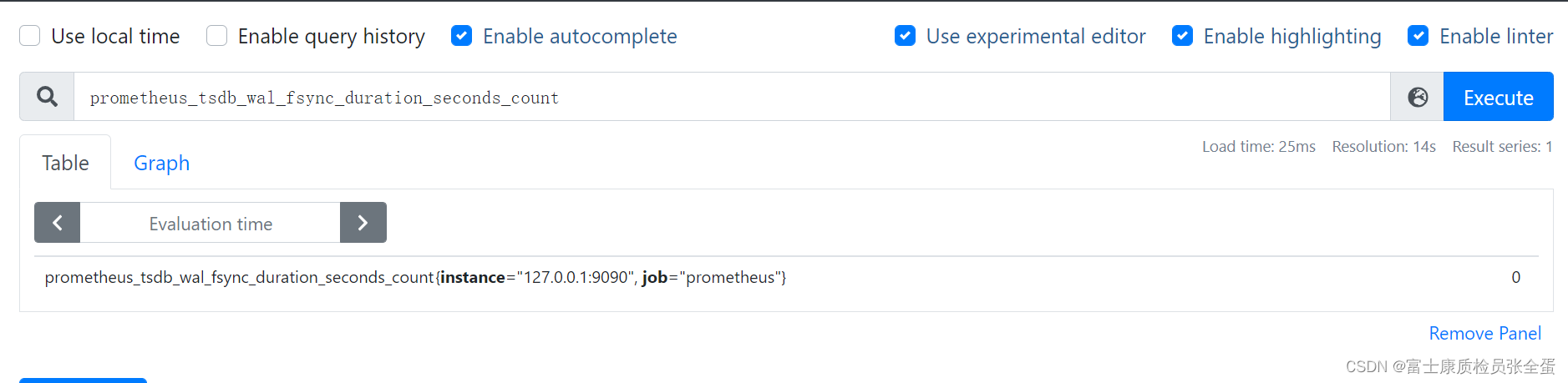
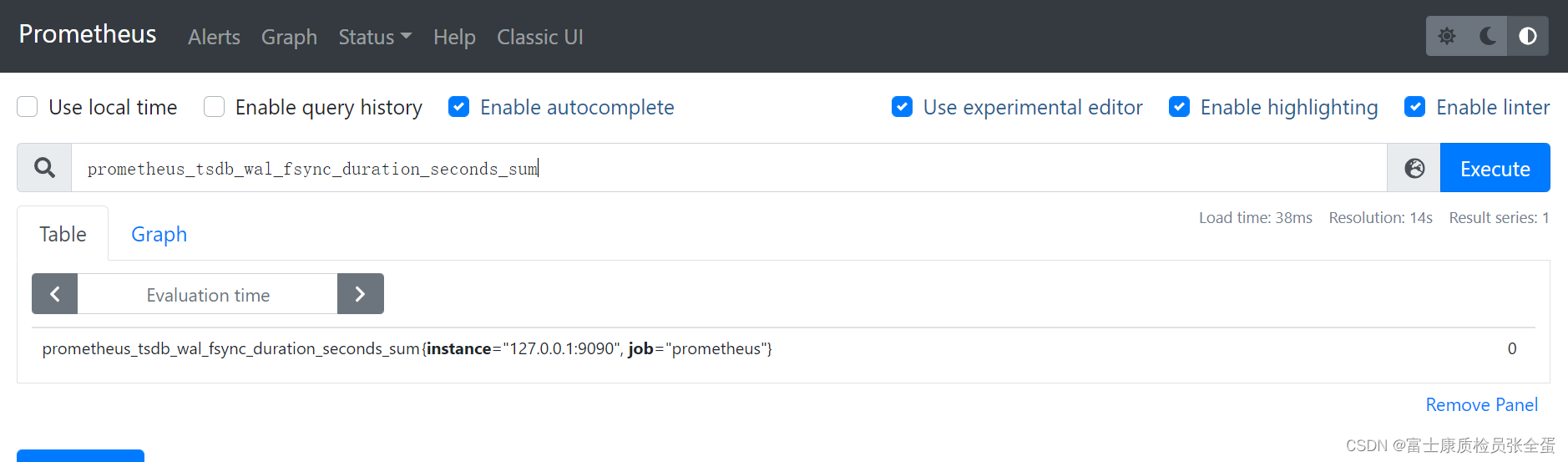
���磬ָ�� prometheus_tsdb_wal_fsync_duration_seconds ��ָ������Ϊ Summary������¼�� Prometheus Server �� wal_fsync �Ĵ���ʱ�䣬ͨ������ Prometheus Server �� /metrics ��ַ�����Ի�ȡ�����¼���������ݣ�
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.
# TYPE prometheus_tsdb_wal_fsync_duration_seconds summary
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
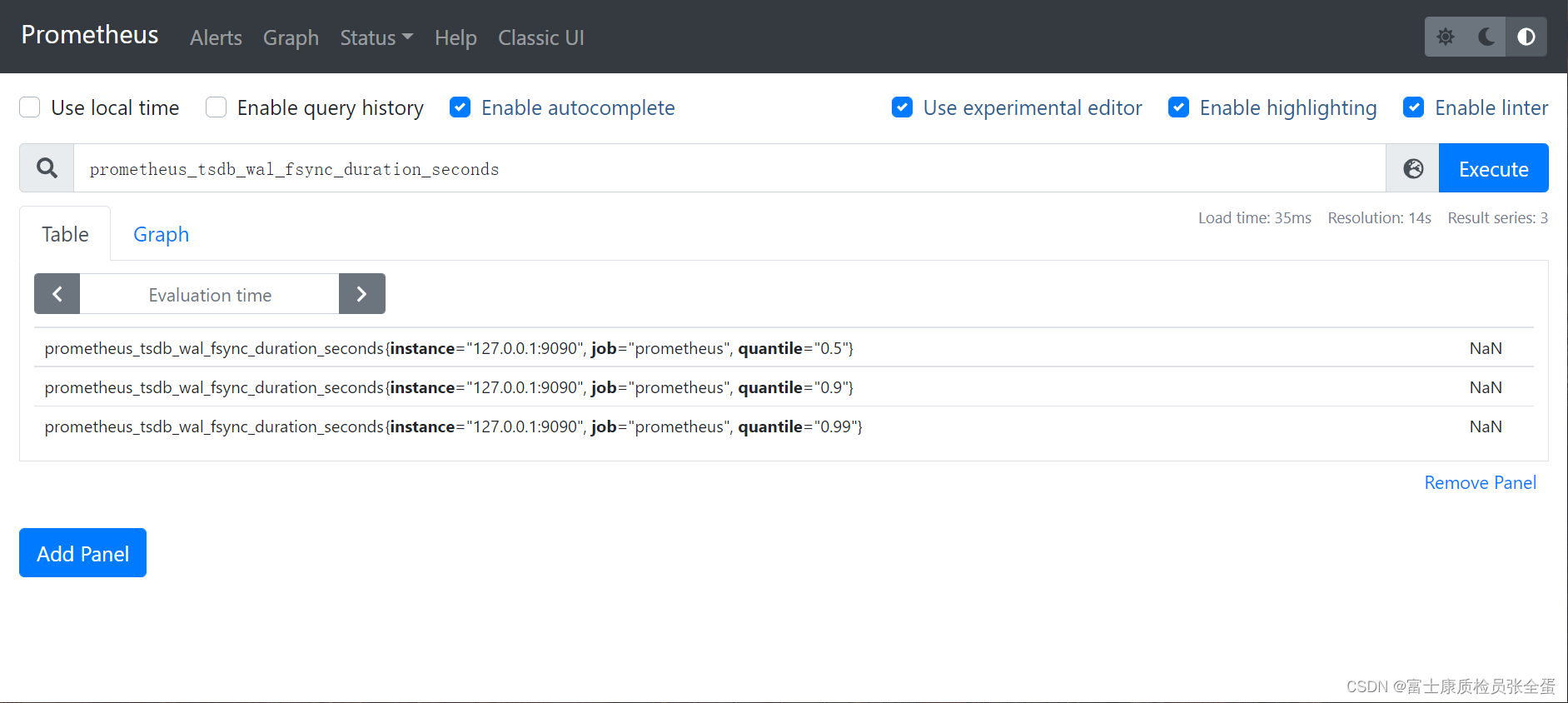
 �͵�һ��counter��gauge��ͬ���ǣ�summary�����ж��ָ�ꡣ���¼��������������¼��������ܴ�С���Լ��¼��ķֲ������
�͵�һ��counter��gauge��ͬ���ǣ�summary�����ж��ָ�ꡣ���¼��������������¼��������ܴ�С���Լ��¼��ķֲ������
- �¼��������¼��ܴ�С��������������п��Ե�֪��ǰ Prometheus Server ����
wal_fsync�������ܴ���Ϊ 216 �Σ���ʱ 2.888716127000002s�� - �ֲ������������λ����quantile=0.5 �ٷ�֮50�IJ�����ʱ���ĺ�ʱΪ 0.012352463��9 ��λ����quantile=0.9 �ٷ�֮90�IJ������ĺ�ʱΪ 0.014458005s���ٷ�֮99�IJ�����ʱ0.017316173��
Histogram
ժҪ�dz����ã�����ƽ��ֵ������һЩϸ�ڣ���ͼ�� 10 �� 113 ���ܺͰ����dz���ķ�Χ�����������鿴ʱ�仨��ʲô�ط��ˣ���ô���Ǿ���Ҫֱ��ͼ����
ֱ��ͼ�� bucket Ͱ����ʽ��¼�������������ǿ�����һ��Ͱ������Ҫ 1s ����ٵļ��㣬��һ��Ͱ���� 5 �����١�10 �����١�20 �����١�60 �����١���ָ�귵��ÿ���洢Ͱ�ļ��������� 3 ���� 5 �����̵�ʱ������ɣ�6 ���� 10 �����̵�ʱ������ɡ�
Prometheus �е�ֱ��ͼ���ۻ������������ 10 �μ��㶼���� 60 �����ٵ�ʱ��Σ������� 10 ���У��� 9 �εĴ���ʱ��Ϊ 20 �����٣�����ʾ�����ݵķֲ������Կ��Կ������ǵĴּ��㶼�� 10 �����£�ֻ��һ������ 20 �룬����ڼ���ٷ�λ�������á�
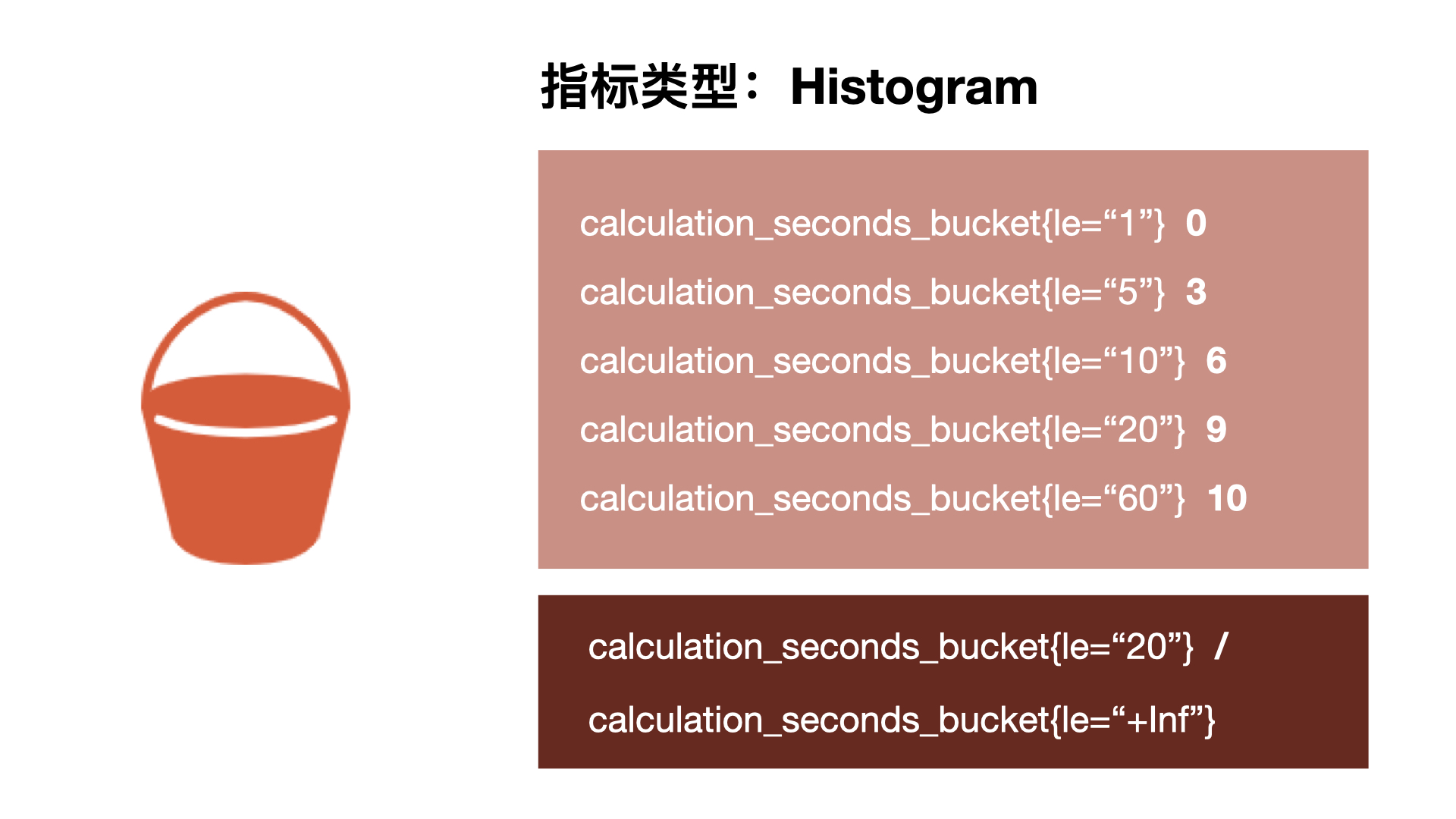
�� Prometheus Server �������ص����������У�����Ҳ���ҵ�����Ϊ Histogram �ļ��ָ��prometheus_tsdb_compaction_chunk_range_seconds_bucket�����Կ������ֵ��һֱ���ӵģ���Ϊ���ۼ����ӵģ���Ϊ1600�ǰ���ǰ��400��100�ġ�
# HELP prometheus_tsdb_compaction_chunk_range_seconds Final time range of chunks on their first compaction
# TYPE prometheus_tsdb_compaction_chunk_range_seconds histogram
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="100"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="400"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="1600"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="6400"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="25600"} 405
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="102400"} 25690
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="409600"} 71863
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="1.6384e+06"} 115928
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="6.5536e+06"} 2.5687892e+07
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="2.62144e+07"} 2.5687896e+07
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="+Inf"} 2.5687896e+07
prometheus_tsdb_compaction_chunk_range_seconds_sum 4.7728699529576e+13
prometheus_tsdb_compaction_chunk_range_seconds_count 2.5687896e+07
�� Summary ���͵�ָ������֮������ Histogram ���͵�����ͬ���ᷴӦ��ǰָ��ļ�¼������(�� _count ��Ϊ��)�Լ���ֵ���������� _sum ��Ϊ������
��ͬ���� Histogram ָ��ֱ�ӷ�Ӧ���ڲ�ͬ�����������ĸ���������ͨ����ǩ le ���ж��塣histogram��ר�ŵĺ���ȥ���㣬������ܡ�
ͬʱ����Histogram��ָ�꣬���ǻ�����ͨ��histogram_quantile()�����������ֵ�ķ�λ������ͬ����Histogramͨ��histogram_quantile�������ڷ������˼���ķ�λ���� ��Sumamry�ķ�λ������ֱ���ڿͻ��˼�����ɡ���˶��ڷ�λ���ļ�����ԣ�Summary��ͨ��PromQL���в�ѯʱ�и��õ����ܱ��֣���Histogram������ĸ������Դ����֮���ڿͻ��˶���Histogram���ĵ���Դ���١���ѡ�������ַ�ʽʱ�û�Ӧ�ð����Լ���ʵ�ʳ�������ѡ��