市场使用情况(背景)
-
中小型软件公司,建议选RabbitMQ。一方面,erlang语言天生具备高并发的特性,而且他的管理界面用起来十分方便。不考虑rocketmq和kafka的原因是,一方面中小型软件公司不如互联网公司,数据量没那么大,选消息中间件,应首选功能比较完备的,所以kafka排除。RocketMQ也很不错,只是没有RabbitMQ出来的早,文档和网上的资料没有RabbitMQ多,但也是很不错,RocketMQ是阿里出品,现在阿里已经把RocketMQ捐赠给Apache了,维护和更新不是问题 。
-
大型软件公司,根据具体使用在rocketMq和kafka之间二选一。一方面,大型软件公司,具备足够的资金搭建分布式环境,也具备足够大的数据量。针对rocketMQ,大型软件公司也可以抽出人手对rocketMQ进行定制化开发,毕竟国内有能力改JAVA源码的人,还是相当多的。至于kafka,根据业务场景选择,如果有日志采集功能,肯定是首选kafka了。具体该选哪个,看使用场景
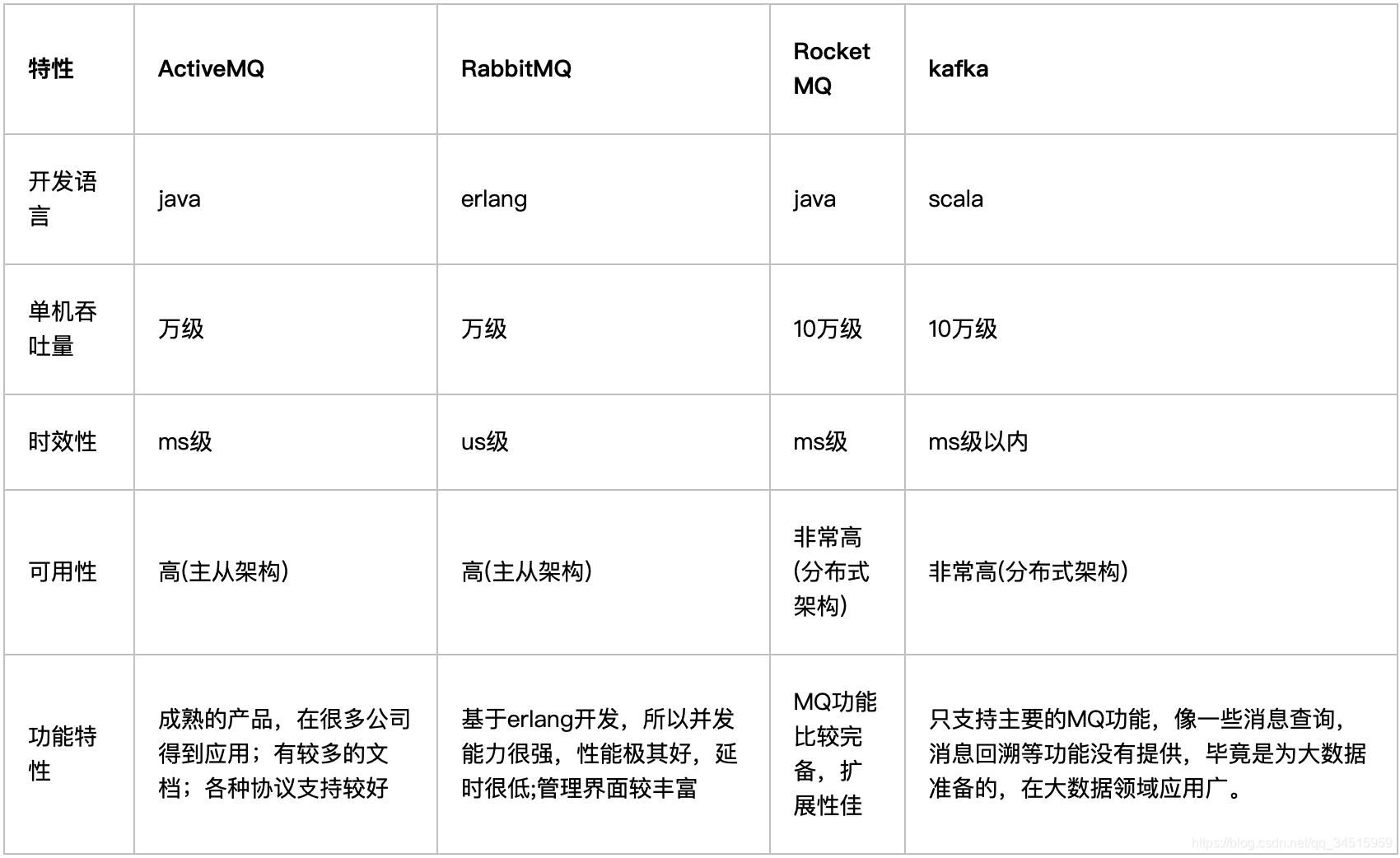
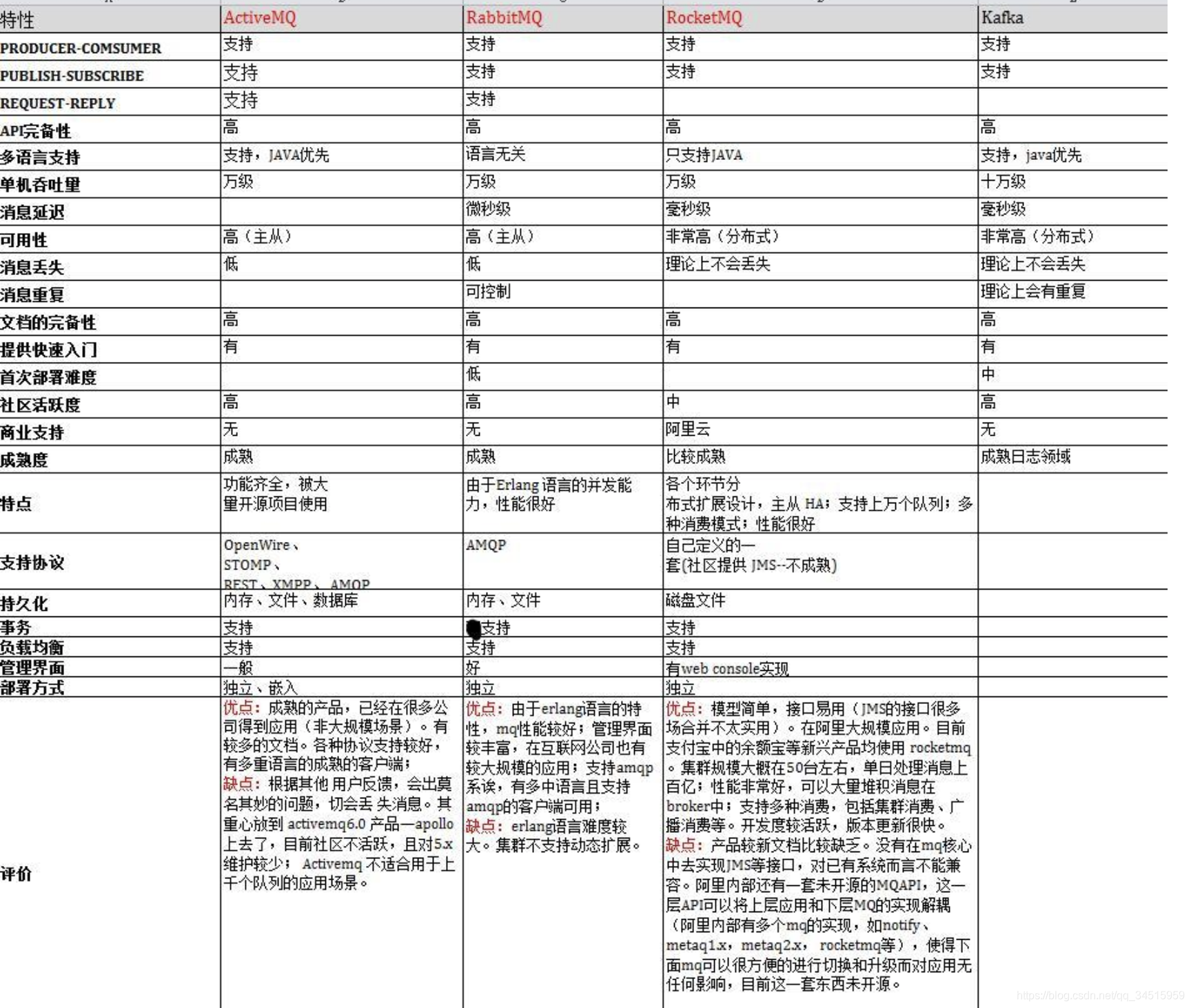
横纵对比
- ActiveMQ
优点
单机吞吐量:万级
topic数量都吞吐量的影响:
时效性:ms级
可用性:高,基于主从架构实现高可用性
消息可靠性:有较低的概率丢失数据
功能支持:MQ领域的功能极其完备
缺点:
官方社区现在对ActiveMQ 5.x维护越来越少,较少在大规模吞吐的场景中使用。
- Kafka
号称大数据的杀手锏,谈到大数据领域内的消息传输,则绕不开Kafka,这款为大数据而生的消息中间件,以其百万级TPS的吞吐量名声大噪,迅速成为大数据领域的宠儿,在数据采集、传输、存储的过程中发挥着举足轻重的作用。
Apache Kafka它最初由LinkedIn公司基于独特的设计实现为一个分布式的提交日志系统( a distributed commit log),之后成为Apache项目的一部分。
目前已经被LinkedIn,Uber, Twitter, Netflix等大公司所采纳。
优点
性能卓越,单机写入TPS约在百万条/秒,最大的优点,就是吞吐量高。
时效性:ms级
可用性:非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用
消费者采用Pull方式获取消息, 消息有序, 通过控制能够保证所有消息被消费且仅被消费一次;
有优秀的第三方Kafka Web管理界面Kafka-Manager;
在日志领域比较成熟,被多家公司和多个开源项目使用;
功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用
缺点:
Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长
使用短轮询方式,实时性取决于轮询间隔时间;
消费失败不支持重试;
支持消息顺序,但是一台代理宕机后,就会产生消息乱序;
社区更新较慢;
- RabbitMQ
RabbitMQ 2007年发布,是一个在AMQP(高级消息队列协议)基础上完成的,可复用的企业消息系统,是当前最主流的消息中间件之一。
RabbitMQ优点:
由于erlang语言的特性,mq 性能较好,高并发;
吞吐量到万级,MQ功能比较完备
健壮、稳定、易用、跨平台、支持多种语言、文档齐全;
开源提供的管理界面非常棒,用起来很好用
社区活跃度高;
RabbitMQ缺点:
erlang开发,很难去看懂源码,基本职能依赖于开源社区的快速维护和修复bug,不利于做二次开发和维护。
RabbitMQ确实吞吐量会低一些,这是因为他做的实现机制比较重。
需要学习比较复杂的接口和协议,学习和维护成本较高。
- RocketMQ
RocketMQ出自 阿里公司的开源产品,用 Java 语言实现,在设计时参考了 Kafka,并做出了自己的一些改进。
RocketMQ在阿里集团被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景。
RocketMQ优点:
单机吞吐量:十万级
可用性:非常高,分布式架构
消息可靠性:经过参数优化配置,消息可以做到0丢失
功能支持:MQ功能较为完善,还是分布式的,扩展性好
支持10亿级别的消息堆积,不会因为堆积导致性能下降
源码是java,我们可以自己阅读源码,定制自己公司的MQ,可以掌控
RocketMQ缺点:
支持的客户端语言不多,目前是java及c++,其中c++不成熟;
社区活跃度一般
没有在 mq 核心中去实现JMS等接口,有些系统要迁移需要修改大量代码