目录
大数据简介?
Hadoop整体概念?
Hadoop 集群搭建?
分布式集群搭建?
伪分布式搭建?
大数据简介?
数据?
数据就是数值,也就是我们通过观察、实验或计算得出的结果。数据有很多种,最简单的就是数字。数据也可以是文字、图像、声音等。在计算机系统中,数据以二进制信息单元 0,1 的形式表示。
大数据?
大数据(big data),指的是在一定时间范围内不能以常规软件工具处理(存储和计算)的大而复杂的数据集。
- 数据衡量单位
- 从小到大排列:bit、Byte、KB、MB、GB、TB、PB、EB、 ZB、YB、BB、NB、DB

据国际数据公司(IDC)统计,全球数据总量预计 2020 年达到 44ZB,中国数据量将达到 8060EB, 占全球数据总量的 18%
- 大数据的特点
- 容量(Volume):数据的大小决定所考虑的数据的价值和潜在的信息
- 新浪微博,3 亿用户,每天上亿条微博
- 朋友圈,8 亿用户,每天亿级别朋友圈
- 种类(Variety):数据类型的多样性,包括文本,图片,视频,音频
- 结构化数据:可以用二维数据库表来抽象,抽取数据规律
- 半结构化数据:介于结构化和非结构化之间,主要指 XML,HTML 等,也可称非结构化
- 非结构化数据:不可用二维表抽象,比如图片,图像,音频,视频等
- 速度(Velocity):指获得数据的速度以及处理数据的速度
- 数据的产生呈指数式爆炸式增长
- 处理数据要求的延时越来越低
- 价值(Value):合理运用大数据,以低成本创造高价值
- 单条数据记录无价值,无用数据多
- 综合价值大,隐含价值大
- 容量(Volume):数据的大小决定所考虑的数据的价值和潜在的信息
一句话:容量大,种类多,速度快,价值高
Hadoop整体概念?
产生背景?
- Hadoop 是Apache Lucene 创始人 Doug Cutting 创建的,最早起源于 Apache Nutch项目。Nutch 的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题 ――如何解决数十亿网页的存储和索引问题
- 2003 年、2004 年谷歌发表的三篇论文为该问题提供了可行的解决方案
- 分布式文件系统 GFS,可用于处理海量网页的存储
- 分布式计算框架 MapReduce,可用于处理海量网页的索引计算问题
- 分布式数据库 BigTable,每一张表可以存储上 billions 行和 millions 列
- Nutch 的开发人员完成了相应的开源实现 HDFS 和 MapReduce,并从 Nutch 中剥离成为独立项目 Hadoop,到 2008 年 1 月,Hadoop 成为 Apache 顶级项目,迎来了它的快速发展期
什么是Hadoop?

Hadoop官网:https://hadoop.apache.org/
Hadoop 是 Apache 旗下的一套开源分布式软件平台,用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。你可以把 Hadoop 理解为一个分布式的操作系统。
什么是分布式程序?
- 该软件系统会划分成多个子系统或模块,各自运行在不同的机器上,子系统或模块之间通过网络通信进行协作,实现最终的整体功能,这多个机器就构成了集群。通俗的讲,分布式系统就是利用集群的多个节点共同协作完成一项或多项具体业务功能的系统。
Hadoop 的核心组件
- Common(基础功能组件:工具包,RPC 框架)
- HDFS(Hadoop Distributed File System 分布式文件系统)
- MapReduce(分布式运算编程框架)
- YARN(Yet Another Resources Negotiator 运算资源调度系统)
广义的Hadoop指一个更广泛的概念――Hadoop 生态圈 :
- HDFS:Hadoop 的分布式文件存储系统
- MapReduce:Hadoop 的分布式程序运算框架,也可以叫做一种编程模型
- YARN:Hadoop 的资源调度系统
- Hive:基于 Hadoop 的类 SQL 数据仓库工具
- HBase:基于 Hadoop 的列式分布式 NoSQL 数据库
- ZooKeeper:分布式协调服务组件
- Oozie/Azkaban:工作流调度引擎
- Sqoop:数据迁入迁出工具
- Flume:日志采集工具
- ……
Hadoop 集群搭建?
分布式集群搭建?
准备工作?
- 集群规划
| hadoop1 | hadoop2 | hadoop3 | |
|---|---|---|---|
| NameNode | √ | × | × |
| SecondryNameNode | × | √ | × |
| DataNode | √ | √ | √ |
| ResourceManager | × | × | √ |
| NodeManager | √ | √ | √ |
两种思路:
1) 先准备好3台空机器,再把所有需要的软件挨个安装一次,需要修改的配置挨个修改一次
2) 先准备好1台空机器,把所有需要的软件安装一次,把通用的配置改好,再来克隆它,这样我们就可以少做很多重复性工作。
这里,我们采用第二种思路:
- 上传hadoop安装包,解压到规划的安装目录
- 切换到 hadpoop 用户,并打开sftp
- pwd 查看工作目录,不满意当前目录就使用 cd 切换
- put windos上hadoop安装包路径
- tar -zxvf hadoop-2.7.5-centos-6.7.tar.gz -C ~/apps/(-C 的意思是指定解压路径,目标路径不存在则需要先创建:mkdir ~/apps)
- 配置环境变量
- vim ~/.bashrc
- 在最后面加入以下语句:
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.7.5
export PATH=$PATH:\$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后保存并退出vi编辑器 - source ~/.bashrc(使用该指令重新加载一次环境变量,使新配置的环境变量生效)
- 配置 hadoop 用户 sudoer 权限(昨天已配置好,可忽略)
- 在 root 用户下,命令行输入:vi /etc/sudoers
- 找到 root ALL=(ALL) ALL 这一行,然后在它下面添加一行:
hadoop ALL=(ALL) ALL
![]()
- wq!(保存,退出)
- 关闭防火墙(昨天已配置好,可忽略)
- service iptables status (查看)
- service iptables stop (关闭)
- chkconfig iptables off (关闭开机自启)
- 配置主机映射
- vim /etc/hosts
- 加入对应的映射

- 保存并退出vi编辑器
- 安装JDK(已安装,忽略)
注:以上操作中,如果出现 “Permission denied” 说明权限不够,需要 root 权限,可切换到 root 或者指令前添加 “sudo”
- 接下来,关机 ,克隆虚拟机
- 在 VMware Workstation 库面板里选中要克隆的虚拟机,右键→管理→克隆,下一步下一步,选中“创建克隆链接”,然后继续下一步,指定好保存的位置及名字,点击完成。重复这个过程,克隆到你规划的数量为止。
- 虚拟机克隆完毕之后,我们原始的虚拟机就可以不使用了(最好不要使用,避免被污染)。对于克隆好的虚拟机,有一些麻烦必须要解决:主机名及ip地址
- 修改主机名:sudo vi /etc/sysconfig/network ,编辑hostname的值
- ip问题:
- vi /etc/udev/rules.d/70-peresitent-net.rules,将 eth0 删除,将 eth1 修改为eth0
- sudo vi /etc/sysconfig/network-scripts/ifcfg-eth0
- 删除里面的 hwaddr 和 uuid
- 修改 bootproto 为 static
- 添加 IPADDR=192.168.25.91,DNS1=192.168.25.2,GATEWAY=192.168.25.2,PREFIX=24
注: ip 和 hostname 要修改成与主机映射文件一致
- 配置免密登录
- 在 hadoop 用户下,输入命令 ssh-keygen ,连按 3 次回车,之后你会发现,在/home/hadoop/.ssh 目录下生成了一对密钥
-
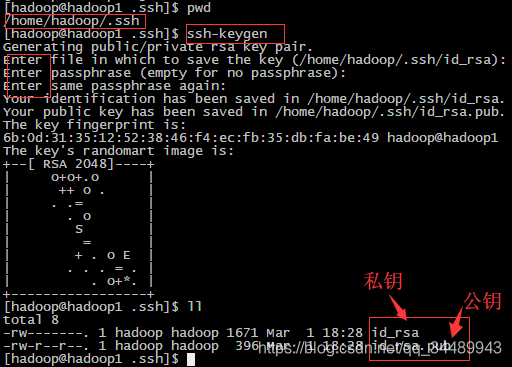
- 在 hadoop1 的 hadoop 用户家目录使用 ssh-copy-id hadoop1 ,这条指令的意思是复制 ssh公钥到 hadoop1 的 .ssh/authorized_keys 文件里,这个文件就是免密登录的关键文件
-
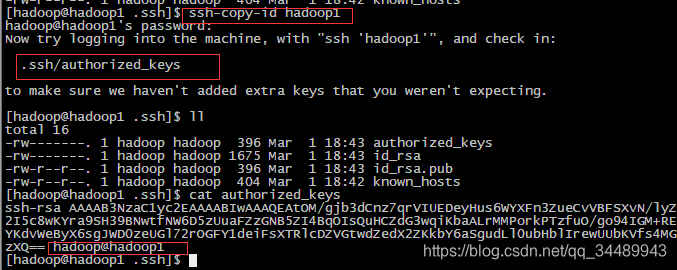
- 之后分别在 hadoop2、hadoop3 的家目录使用 ssh-copy-id hadoop1 分别将公钥复制到 hadoop1 的 authorized_keys 文件下
-
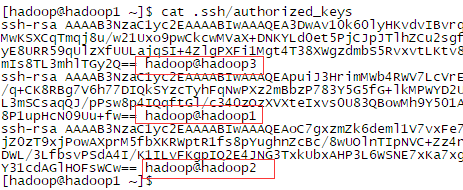
- 使用 scp ~/.ssh/authorized_keys hadoop2:~/.ssh 将 /authorized_keys 文件发送给其他机器(因为是首次连接,所以需要输入 yes 和访问密码记录在 know_hosts 文件里)
- 最后把 hadoop1 的 know_hosts 在发送给 其他主机
-
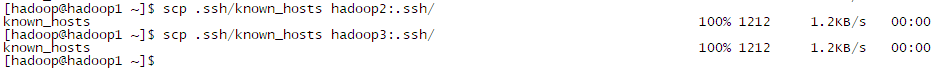
- 在任意机器上输入 ssh 主机名 验证是否成功,记得使用 exit 退出 远程连接
- 同步时间
- date(查看时间)
- ntpdate ntp1.aliyun.com
对准备工作总结一下:主机名、主机映射、静态IP、安装包、环境变量、JDK、免密登录、同步时间、防火墙
Hadoop配置文件?
Linux 上面安装软件其实就两点:一是配置,二是环境变量。环境变量已提前配置完毕,现在我们只要修改好 Hadoop 的配置文件就大功告成。
Hadoop 的配置文件位于 ~/apps/hadoop-2.7.5/etc/hadoop/ 文件夹中,需要修改的配置共有 6 个:
- hadoop-env.sh
- 里面指定 jdk 安装路径
- core-site.xml
- 里面指定 namenode 及缓存目录等
- hdfs-site.xml
- 里面指定 HDFS 相关参数,比如数据保存目录、文件备份数、及 Secondary NameNode
- mapred-site.xml
- 里面指定 MR 相关参数
- yarn-site.xml
- 里面指定一些资源调度的参数
- slaves
- 里面指定 datanode 有哪些
鉴于同学们是初次接触,我已经配置好了一个模板,大家只需要上传配置模板到 ~/apps/hadoop-2.7.5/etc/hadoop/ :
- 在 SecureCRT 里按下 alt+p ,建立sftp连接
- cd ~/apps/hadoop-2.7.5/etc/hadoop/
- put d:\Documents\hadoopconfig\*(红色部分为配置模板在windows上的路径,注意修改为自己的,里面不能带空格)
上传并修改为你自己机器上对应的值后,一点节点的所有配置就搞定了,现在把整个 ~/apps/hadoop-2.7.5/etc/hadoop/ 下的配置发送给其他节点
- scp -r ~/hadoop-2.7.5/etc/hadoop hadoop2:~/hadoop-2.7.5/etc
- scp -r ~/hadoop-2.7.5/etc/hadoop hadoop3:~/hadoop-2.7.5/etc
初始化namenode?
在 HDFS 主节点上执行命令进行初始化 namenode(初始化只搭建时执行一次,可以理解为建立一个新的档案库)
- hadoop namenode -format
-

启动HDFS?
- start-dfs.sh (在集群任意节点执行 )
启动YARN?
- start-yarn.sh(只能在YARN的主节点启动,否则ResourceManager进程无法启动 )
验证集群是否安装成功?
- 使用 jps 指令查看进程
- WebUI
- http://192.168.25.91:50070
- http://192.168.25.93:8088
- 上传一个文件到HDFS:hadoop fs -put xxxxx /(前面xxxxx代表要上传的文件在本地的路径,/ 表示上传到hdfs的路径)
- 运行一个MapReduce任务:hadoop jar ~/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /testwc.txt /result(wordcount 后面第一个参数是在hdfs里的源文件路径, 后面的/result 表示保存结果在hdfs上面的路径 )
伪分布式搭建?
考虑到部分同学可能硬件支持不了搭建分布式集群,这里再介绍一下伪分布式集群:
- Hadoop 可以在单节点上以伪分布式的方式运行, 进程以分离的 Java 进程来运行, 所有 Hadoop 进程都在一个机器上 ,同时,读取的是 HDFS 中的文件而非本地文件
- 伪分布式只需要修改 2 个配置文件 core-site.xml 和 hadoop-env.sh( hdfs-site.xml 主要用来配置数据块的副本数的,对于伪分布式来说,不管你配置几个副本,它始终都只有一个副本,所以就不用管了)
- 其他步骤和搭建分布式集群一致