背景:前端时间,测试的时候发现数据库所在的服务器磁盘占用量疯狂的增加。就去查看了是什么原因。足够定位到是数据库表的问题。问题来了,以前只知道数据库的表是以文件的形式存在的。其他都不知道,所以花了很多时间来初步了解。
initdb 的时候会指定一个 PGDATA 目录,这就是 PostgresQL 存储数据的地方。典型的位置是在 /postgres/data a 。PGDATA 下面各项存储的内容大概是:
| 文件或目录名 | 存储内容 |
|---|---|
| PG_VERSION | PostgresQL 实例的版本号如 9.3 之类的 |
| base | 每个 database 会在 base 目录下有一个子目录 |
| global | Postgres 自己的 meta 数据库存放的地方(全局 DB) |
| pg_xlog | WAL(Write Ahead Log 预写式日志)存放的地方 |
| 其他 | 其他不知道干啥的目录还有好多 |
base 目录是最重要的一个目录,放的是每一个 database 的数据。base 目录里的每一个数字目录对于一个 database 的 oid, 可以通过 查看 pg_database 这张表查看每一个 数据库的 oid 。
select oid, datname from pg_database ;
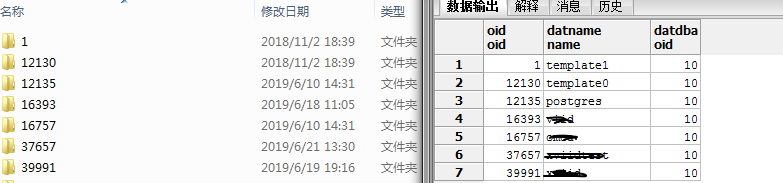
可以看到 oid和文件夹的名称是对应的。
每一张表的数据(大部分)又是放在 base/(oid)/(relfilenode) 这个文件里面:
select relname, relowner, relfilenode from pg_class where relowner = 10 ;
--或者可以加入表名称的过滤
select relname, relowner, relfilenode from pg_class where relowner = 10 and relname like '%viid%';
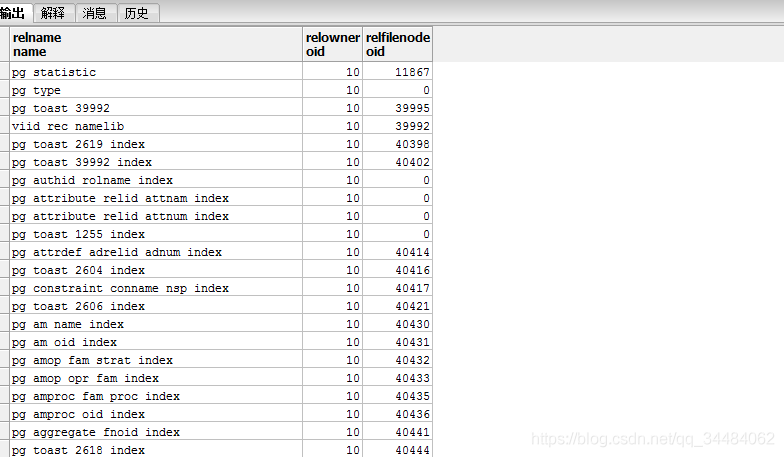
可以知道 pg_statistic 存在 11867 文件中
当然也可以利用一下语句:这样就可以拿到对应的表的相关数据;
select pg_relation_filepath('pg_statistic');

当然实际的存储不会这么简单。每一张表的文件都会有一些附加的存储文件,如文件名后加上 _fsm 的是空闲空间映射表 (Free Space Map)。另外 base/(dboid)/(relfilenode) 这个文件超过 1GB 以后,Postgres 会把这个文件拆分成不超过 1G 的多个文件,文件末尾加上 .1 .2 .3 … 做编号。 如 24589 24589.1 24589.2 。据说这是因为某些文件系统支持的最大文件大小有限制(如 fat32 只支持最大 4G )的文件。