1、为什么需要haroxy
haroxy官方定义如下:
HAProxy是一种免费的、非常快速和可靠的解决方案,它提供了高可用性、负载平衡和对TCP和基于http的应用程序的代理。它特别适用于非常高的流量网站,并且拥有相当多的世界上最受欢迎的网站。多年来,它已经成为事实上的标准的opensource负载平衡器,现在已经与大多数主流的Linux发行版一起发布,并且经常在云平台上默认部署
实际上mycat本身也可以直接搭配keepalived来做高可用,如果不搭配haproxy,那么永远只有一台mycat是可用状态,其他的只是做灾备用。haproxy主要作用是mycat的负载均衡以及高可用。
PS:haproxy官网默认的下载地址http://www.haproxy.org/download打不开,网上各种搜到的也不行;于是自己试了加了认证https://www.haproxy.org/download成功打开。
2、为什么需要xinetd这个东西
2.1、首先haproxy默认给出的后端健康检查方式为httpchk,分如下几种:
option httpchk
option httpchk< url >
option httpchk< method > < url >
option httpchk< method > < url > < version >
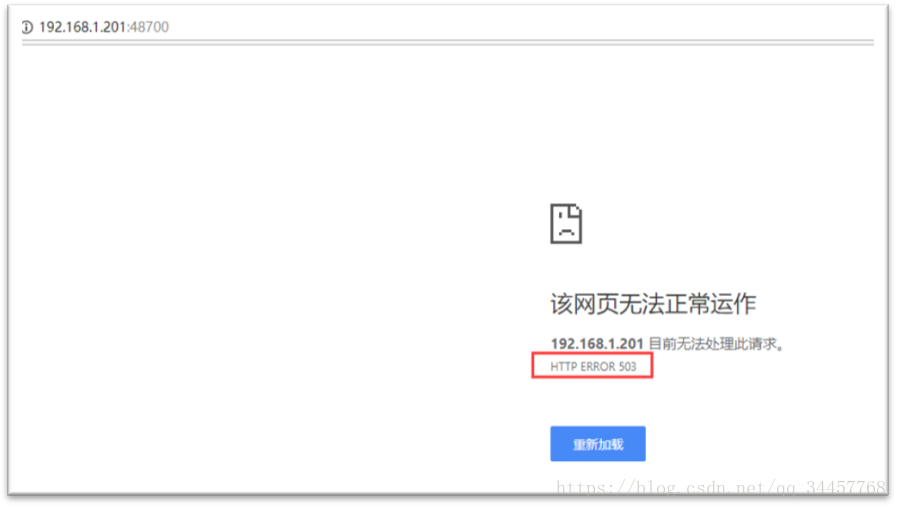
2.2、采用xinetd的原理是,给mycat的服务器上运行一个端口为48700的服务,这个服务监控着mycat进程的状态,一旦mycat进程不可用,那么就会给前端返回503参数,如图:
2.3、附上48700端口服务的配置文件/etc/xinetd.d/mycat_status内容:
service mycat_status{flags = REUSEsocket_type = streamport = 48700wait = nouser = rootserver =/usr/local/bin/mycat_statuslog_on_failure += USERIDdisable = no
}2.4、可以看出这个进程服务对象就是/usr/local/bin/mycat_status这个脚本,内容如下:
#!/bin/bashmycat=`/usr/local/mycat/bin/mycat status | grep'not running' | wc -l`
if [ "$mycat" = "0" ];then/bin/echo-e "HTTP/1.1 200 OK\r\n"else/bin/echo-e "HTTP/1.1 503 Service Unavailable\r\n"
fi2.5、我们无法采用httpchk方式直接去检测mycat的8066端口是否存活,因为mycat代理的是mysql的服务,而mysql客户端连接服务器用的是mysql本身制订的通信协议(个人理解为类似API方式);那么haproxy健康检查方式难道只有httpchk了吗?当然不是,haproxy自带了一个专门针对mysql健康检查的一个配置选项,如下:
option mysql-check user username这里的username对应的是mysql真实存在的一个用户,必须是无密码的。
2.6、官方文档给出的信息如下:

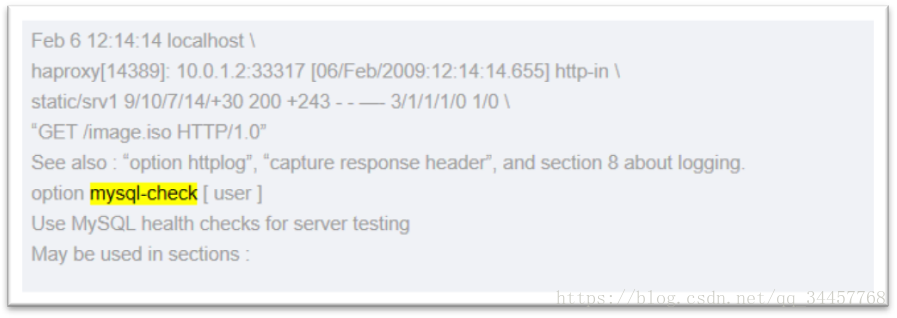
可以看出还有针对其他类型的健康检查,比如pgsql。
2.7、但是我们也不能使用mysql-check的方式直接对mycat进行检测;首先,用这种方式在mycat跟haproxy两部分都配置好了后haproxy是无法正常访问后端的,其次即使能成功,此时健康检查的目标也不是mycat而是最后端的mysql了。
3、关于keepalived
keepalived是以VRRP协议为实现基础的,VRRP全称Virtual Router Redundancy Protocol,即虚拟路由冗余协议。
虚拟路由冗余协议,可以认为是实现路由器高可用的协议,即将N台提供相同功能的路由器组成一个路由器组,这个组里面有一个master和多个backup,master上面有一个对外提供服务的vip(该路由器所在局域网内其他机器的默认路由为该vip),master会发组播,当backup收不到vrrp包时就认为master宕掉了,这时就需要根据VRRP的优先级来选举一个backup当master。这样的话就可以保证路由器的高可用了。
3.1、先附上keepalived.conf常规配置及说明
! Configuration File for keepalived############################ 全局配置 ############################global_defs {notification_email {XX@qq.com # 发生诸如切换操作时邮件告警地址,可以定义多个,每行一个。这个功能有点鸡肋,keepalived死掉也没法发了,可以用在vrrp_script定义的脚本里面触发发邮件的功能。}notification_email_from keepalived@showjoy.com # 邮件发送源地址smtp_server 127.0.0.1 # SMTP Server地址smtp_connect_timeout 30 # SMTP Server的超时时间router_id keepalived_1 # 标识机器名
}############################ VRRP配置 ############################# 定义检测 haproxy 状态的脚本
vrrp_script chk_haproxy {script "/etc/keepalived/haproxy_check.sh" # 检测 haproxy 状态的脚本路径interval 10 # 检测时间间隔weight 2 # 权重
}
# 定义虚拟路由, K_1为虚拟路由的标示符,自己定义名称
vrrp_instance K_1 {state MASTER # 指定当前主机的的角色,MASTER表示是主,BACKUP表示备用;个人测试此参数没有实际功能,只作标识用interface eth0 # 实际监控的网卡virtual_router_id 1 # 相同的 VRID 为一个组,他将决定多播的 MAC 地址priority 100 # 设置本节点优先级,范围[0-254],高的为MASTER,如果优先级一样,则IP地址大的是MASTERnopreempt # 主要作用于master服务死掉又恢复时不抢占VIPadvert_int 1 # 组播信息发送间隔,默认1s,两个节点设置必须一样
# 验证方式与验证密码,两个节点必须一致authentication {auth_type PASSauth_pass 1111
}
# 上面定义的vrrp_script脚本加入到vrrp_instance选项中来track_script {chk_haproxy
}
# 虚拟 IP 池,即外部访问的地址,两个节点设置必须一样,可以定义多个,每行一个
virtual_ipaddress {192.168.1.208
}
}3.2、对于vrrp_script,官方说明文档如下:
vrrp_script <STRING> { # VRRP script declarationscript <QUOTED_STRING> # script to run periodicallyinterval <INTEGER> # run the script this every secondsweight <INTEGER:-254..254> # adjust priority by this weightfall <INTEGER> # required number of failures for OK switchrise <INTEGER> # required number of successes for OK switch
} The script will be executed periodically, every <interval> seconds. Its exit code will be recorded for all VRRP instances which will want to monitor it. Note that the script will only be executed if at least one VRRP instance monitors it with a non-zero weight. Thus, any number of scripts may be declared without taking the system down. If unspecified, the weight equals 2, which means that a success will add +2 to the priority of all VRRP instances which monitor it. On the opposite, a negative weight will be subtracted from the initial priority in case of failure.3.3、个人整理出两种VIP漂移模式,根据服务器环境去选择,主要区别于haproxy_check.sh脚本的不同
3.4、第一种情况是主机上只运行着单个keepalived服务,当haproxy不可用时,直接kill掉本机的keepalived服务,使得VIP漂移
3.5、附上脚本
#!/bin/bash
log_file="/usr/local/keepalived/haproxy_check.log"
date=`date '+%F_%H_%M'`
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];thenkillall keepalived#记录切换日志echo "date" >> $ log_fileecho "haproxy is stopped, killall keepalived!" >> $ log_fileecho " " >> $ log_file
fi
3.6、需注意的地方:
(一)必须先启动MASTER再启动BACKUP,因为MASTER设置了nopreempt。
(二)MASTER死掉重启时,先启动haproxy在启动keepalived
3.7、第二种配置主要针对一台机器运行着几个keepalived服务(virtual_router_id不同)的情况,根据设定的priority及weight对组传播的优先级值产生变化,使得VIP漂移。
3.8、附上脚本:
#!/bin/bash
log_file="/usr/local/keepalived/haproxy_check.log"
date=`date '+%F_%H_%M'`
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];thenecho "date" >> $ log_fileecho "haproxy is stopped, vip shift!" >> $ log_fileecho " " >> $ log_fileexit 1
elseexit 0
fi3.9、以下为组传播的优先级值变化的实际逻辑:
(一)当weight>0(可用weight =20、priorit=90搭配weight =40、priorit=80去测)
执行结果为0(即haproxy可用),组传播的优先级值=priority+ weight
执行结果为1(即haproxy不可用),组传播的优先级值= priority
(二)当weight<0(可用weight =-20、priorit=70搭配weight= -40、priorit=80去测)
执行结果为0(即haproxy可用),组传播的优先级值= priority
执行结果为1(即haproxy不可用),组传播的优先级值= priority+weight
3.10、需注意的地方:
(一)不能设置nopreempt;打个比方,主机M的haproxy不可用,使得VIP飘到B,此后M恢复了,接着B不可用,但由于M设置了nopreempt,VIP无法漂移到M,然后……就没有然后了……
(二)组传播的优先级值以配置好的priority及weight去计算,不会不断的提高或者降低
(三)组传播的优先级值保持的范围在[1,254],不会有优先级小于等于0或者优先级大于等于255的情况出现
(四)官方文档有句If unspecified, the weight equals 2说的是默认权重是2,但本人用了各种方式去测试结果表明:在没设置weight或者weight=0的情况下,无论主备机的priorit设置值相差多少,只要其中一台机器的执行结果为1(即haproxy不可用),就会发生VIP漂移。