ΔΌ«Α―‘
…œΗω‘¬Ω¥ΝΥ“ΜΤΣ±»ΫœΜπΒΡ¬έΈΡ<Squeeze-and-Excitation Networks>,ΫώΧλΚΆ¥σΦ““ΜΤπΖ÷œμ“Μœ¬ΓΘΈΣ ≤Ο¥…œΗω‘¬Ω¥ΒΡ¬έΈΡ’βΗω‘¬≤≈Ζ÷œμΡΊΘ§“ρΈΣΈ“±»Ϋœœ≤ΜΕ¬≥―ΗΒΡ…ΔΈΡ<≥·Μ®œΠ Α>ΓΘ
ΔΎILSVRCΖ÷άύ»ΈΈώ
’βΤΣΈΡ’¬ΒΡ÷––ΡΥΦœκSEΆχ¬γΒλΕ®ΝΥ2017ΡξΒΡILSVRCΖ÷άύ»ΈΈώΒΡsubmissionΓΘ≤Δ«“ΫΪTop5ΒΡΈσ≤νΦθ–ΓΒΫ2.251%Θ§ΫΪ2016ΡξΒΡΙΎΨϋ≥…Φ®ΧαΗΏΝΥΫΪΫϋ25%ΓΘ
ΔέSE block
SEblockΫαΙΙΆΦ»γœ¬ΆΦΥυ ΨΘΚ
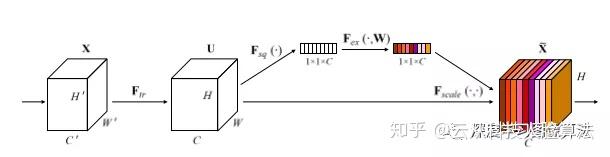
SE block÷ς“Σ”…»ΐ≤ΩΖ÷ΙΙ≥…Θ§Squeeze≤ΌΉς,Excitation≤ΌΉςΘ§Fscale≤ΌΉςΓΘ
Ήœ»Θ§FtrΑ― δ»κΒΡX”≥…δΈΣΧΊ’ςΆΦUΘ§FtrΩ…“‘ «“ΜΗωΉν≥ΘΦϊΒΡΨμΜΐ≤ΌΉςΜρ’ΏΤδΥϊ≤ΌΉςΓΘ
Τδ¥ΈΘ§Squeeze≤ΌΉςΕ‘UΫχ––“ΜΗω»ΪΨ÷ΒΡ≥ΊΜ·≤ΌΉςΘ§±»»γΉν¥σ≥ΊΜ·Μρ’ΏΤΫΨυ≥ΊΜ·(WxHΩ’ΦδΖΕΈßΡΎΫχ––≥ΊΜ·)Θ§≤ζ…ζ“ΜΗωembeddingΘ®1x1xCΘ©ΓΘ
‘Ό¥ΈΘ§Excitation≤ΌΉςΫΪ…œΟφ≤ζ…ζΒΡembeddingΫχ––“ΜœΒΝ–Ζ«œΏ–‘”≥…δ(±»»γFC+RELU+FC)Θ§ΉνΚσΗζ“ΜΗωsigmoidΒΟΒΫΟΩΗωΆ®ΒάΒΡ»®÷ΊΓΘ
ΉνΚσΘ§ΫΪ…œΟφΒΟΒΫΒΡΟΩΗωΆ®ΒάΒΡ»®÷ΊΉς”Ο”ΎUΘ§Ε‘ΟΩΗωΆ®ΒάΒΡUΫχ––Φ”»®«σΚΆΓΘ÷Ν¥ΥΘ§ΨΆΆξ≥…ΝΥ’ϊΗωSE blockΒΡ”≥…δΓΘ
ΚΥ–ΡΥΦœκ «≤ΜΆ§Ά®ΒάΒΡ»®÷Ί”ΠΗΟΉ‘ ”ΠΖ÷≈δΘ§”…Άχ¬γΉ‘ΦΚ―ßœΑ≥ωά¥ΒΡΘ§Εχ≤Μ «œώInception net“Μ―υΝτœ¬ΙΐΕύ»ΥΙΛΗ…‘ΛΒΡΚέΦΘΓΘ
ΔήSqueeze Operator
»γœ¬ΆΦΥυ ΨΘ§‘ΎResnet-50…œ≤β ‘ΝΥ≤ΜΆ§ΒΡ»ΪΨ÷≥ΊΜ·ΖΫΖ®Ε‘Ήν÷’–ßΙϊΒΡ”ΑœλΓΘ

¥”…œΆΦΩ…“‘Ω¥≥ωΘ§Ήν¥σ≥ΊΜ·ΚΆΤΫΨυ≥ΊΜ·Ά§―υ”––ßΘ§ΒΪ «ΤΫΨυ≥ΊΜ·±»Ήν¥σ≥ΊΜ·ΒΡ–ßΙϊ…‘ΈΔΚΟ“ΜΒψΒψΓΘΥδ»ΜΉς’ΏΤδ Β «≤…”ΟΉν¥σ≥ΊΜ·ΒΡΘ§±Ψ»Υ»œΈΣΉν¥σ≥ΊΜ·”– ±ΚρΜα ήΒΫ“Μ–©≤ΜΝΦ ΐΨίΒΡΗ…»≈Θ§ΕχΤΫΨυ≥ΊΜ·ΗϋΡήΙΜΖ¥”≥≥ωΆ≥ΦΤ…œΒΡΙφ¬…ΓΘΒΪ «Έό¬έ‘θΟ¥―υΘ§¥”…œΆΦΩ…“‘ΦδΫ”Ω¥≥ωSEblock «Ζ«≥Θ¬≥ΑτΒΡΘ§Έό¬έ―Γ‘ώΡΡ÷÷≥ΊΜ·ΖΫΖ®Θ§Ήν÷’–ßΙϊ”ΠΗΟΕΦ≤ΜΜα≤νΨύΧΪ¥σΓΘ
ΔίExcitation Operator
»γœ¬ΆΦΥυ ΨΘ§‘ΎResnet-50…œ≤β ‘ΝΥ≤ΜΆ§ΒΡΖ«œΏ–‘Ε‘Ήν÷’–ßΙϊΒΡ”ΑœλΓΘ
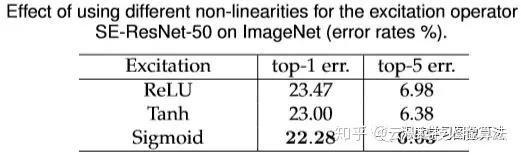
¥”…œΆΦΩ…“‘Ω¥≥ωΘ§ΫΪΖ«œΏ–‘”≥…δsigmoidΧφΜΜ≥…tanh‘Ύ–ßΙϊ…œ±δΒΟ…‘ΈΔ≤νΝΥ“ΜΒψΒψΘ§ΒΪ «ΜΙ≤ΜΟςœ‘ΓΘΒΪ «»γΙϊΧφΜΜ≥…ReluΒΡΜΑΘ§–ßΙϊΨΆ¥σ¥ρ’έΩέΘ§…θ÷ΝΕΦΒΆ”ΎResnet-50ΒΡbaselineΝΥΓΘΥυ“‘ΥΒ‘ΎExcitation≤ΩΖ÷ΗυΨίΆχ¬γΒΡΫαΙΙΚΆΕ‘œνΡΩΒΡάμΫβΘ§…ς÷Ί―Γ‘ώ“Μ÷÷ΦΛάχΚ· ΐΖ«≥Θ÷Ί“ΣΓΘ
ΔόDifferent stages
»γœ¬ΆΦΥυ ΨΘ§‘ΎResnet-50…œ≤β ‘ΝΥ≤ΜΆ§ΒΡstagesΦ”»κSE blockΕ‘Ήν÷’–ßΙϊΒΡ”ΑœλΓΘ

¥”…œΆΦΩ…“‘Ω¥≥ωΘ§‘Ύ≤ΜΆ§ΒΡstages…œΦ”»κSE blockΕΦΡήΙΜ¥χά¥–ßΙϊ…œ ’“φΓΘ≤Δ«“‘Ύ≤ΜΆ§ΒΡstages…œΒΡ ’“φΜΙΩ…“‘–Έ≥…ΜΞ≤ΙΘ§≤Μ≥εΆΜΚΆ≤ΜœύΜΞ“÷÷ΤΓΘΥυ“‘Έ“Ο«Ω…“‘‘Ύ≤ΜΆ§ΒΡstages…œΦ”»κSE block»ΜΚσάέΜΐΒΟΒΫ–ßΙϊ ’“φΓΘ
ΔΏInregration strategy
»γœ¬ΆΦΥυ ΨΘ§‘ΎResnet-50…œΈ“Ο«Ω…“‘‘Ύ≤ΜΆ§ΒΡΈΜ÷Ο≤ε»κSE blockΓΘ
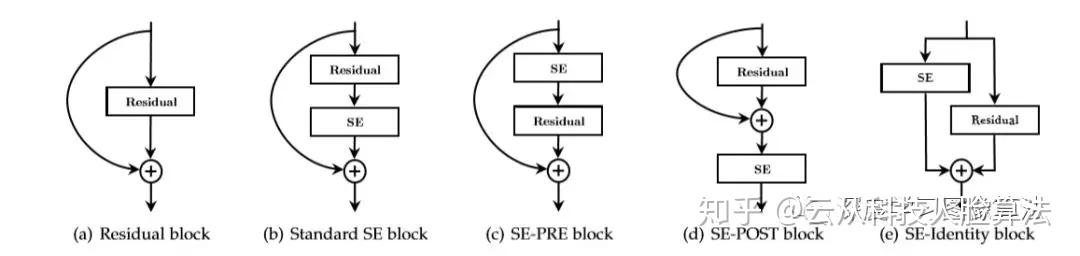
ΡΩ«Α÷ςΝςΒΡΦΗ÷÷ΖΫΖ®»γ…œΆΦΥυ ΨΓΘSE-PRE «‘Ύresidual unit÷°«Α≤ε»κΘ§»γ…œΆΦcΥυ ΨΓΘSE-POST «‘Ύresidual summation÷°Κσ≤ε»κΘ§»γ…œΆΦdΥυ ΨΓΘSE-Identity «‘Ύidentity connection’βΗωΖ÷÷ß…œ≤ε»κΘ§»γ…œΆΦeΥυ ΨΓΘ
≤ΜΆ§ΒΡ≤ε»κΈΜ÷Ο‘λ≥…ΒΡ–ßΙϊ ’“φ“≤≤ΜΨΓœύΆ§ΓΘ»γœ¬±μΥυ ΨΘΚ
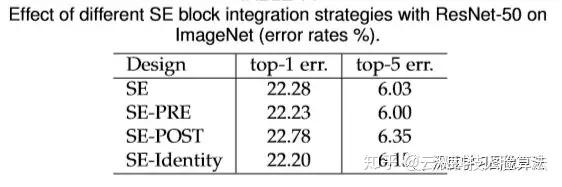
¥”±μ÷–Ω…“‘Ω¥≥ωΘ§SE-PRE, SE-Identity , SE-StandardΕΦ±μœ÷ΒΟ≤Μ¥μΘ§ΕχSE-POST‘Ύ–ßΙϊ…œ±μœ÷ΒΟ”–Βψ≤ΜΨΓ»γ»Υ“βΝΥΓΘ
ΉήΫαΘΚSE_BLOCK‘Ύ≤ΜΆ§ΈΜ÷Ο≤ε»κresnetΆχ¬γ÷–ΨΏ”–±»Ϋœ«ΩΒΟ¬≥Ατ–‘ΓΘΒΪ «“≤≤Μ «Υφ–ΡΥυ”ϊœκ‘ΎΡΡάο≤ε»κΕΦΩ…“‘ΒΡΓΘ±»»γSE-POST‘λ≥…–ßΙϊœ¬ΫΒΒΡ«ιΩωΥΒΟς±Ί–κ¥ρ»κΒ–ΨϋΡΎ≤ΩΘ§»ΥΦ“ΕΦsummationΆξΝΥΘ§residual unitΕΦΫα χΝΥΡψ≤≈≤ε»κΨΆΟΜ ≤Ο¥“β“εΝΥΓΘ
œ¬±μ «SE_BLOCKΒΡΝμΆβ“Μ÷÷±δ÷÷ΒΡ«ιΩωΘΚ
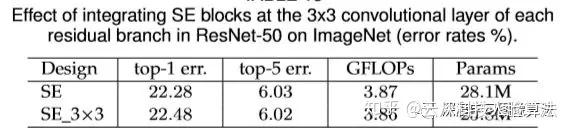
’β÷÷±δ÷÷ τ”Ύ÷±ΒΖΜΤΝζΘ§÷±Ϋ”Α―SE_BLOCKΚΆresidual unit »ΎΚœ≥…ΈΣ“Μ≤ΩΖ÷Θ§÷±Ϋ”Ζ≈‘ΎΝΥresidual unit ΡΎ≤ΩΘ§ΨΏΧε «Ζ≈‘ΎΝΥ3x3 conv layerΒΡΚσΟφΓΘ
–ΓΫαΘΚ¥”…œ±μΩ…“‘Ω¥≥ωΘ§’β―υΖ≈ΒΡΜΑ”…”Ύ3x3 conv layer ”–Ηϋ…ΌΒΡΆ®Βά ΐΘ§Υυ“‘‘λ≥…ΝΥSE_BLOCK≤Έ ΐΒΡΦθ…ΌΓΘΈ“Ο«”ΟΗϋ…ΌΒΡ≤Έ ΐΒΟΒΫΝΥœύΕ‘ΩΩΤΉΒΡΖ÷άύΉΦ»Ζ¬ Θ§’β‘Ύ ΒΦ ΙΛ≥Χ÷– «Ε‘ΉΦ»Ζ¬ ΚΆΥΌΕ»ΒΡ“Μ÷÷ΚήΚΟΒΡtrade offΓΘ
ΔύEffect of Squeeze
»γœ¬±μΥυ ΨΘ§‘ΎResnet-50…œ≤β ‘ΝΥSqueezeΚΆNoSqueezeΕ‘Ήν÷’–ßΙϊΒΡ”ΑœλΓΘ
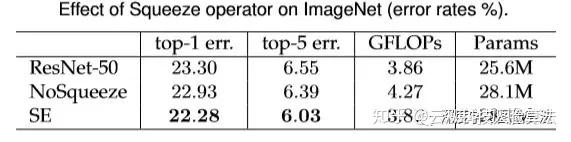
Έ“Ο« Ήœ»Α―pooling≤ψ“Τ≥ΐΓΘΤδ¥Έ”Ο“ΜΗω1x1ΒΡΨμΜΐ≤ψΧφΜΜ‘≠ά¥ΒΡFC≤ψΓΘΈ“Ο«Α―ΧφΜΜ÷°ΚσΒΡΫαΙΙΫ–ΉωNoSqueezeΓΘNoSqueeze±ΘΝτΝΥ‘≠±ΨΧΊ’ςΆΦΒΡΩ’ΦδΫαΙΙΓΘ¥”±μ÷–Έ“Ο«Ω…“‘Ω¥≥ω»ΪΨ÷–≈œΔΕ‘”Ύ–ßΙϊΧα…ΐ”–Ή≈÷Ί“Σ”ΑœλΓΘœύ±»”ΎResnet-50Θ§Φ”ΝΥSE blockΒΡΆχ¬γ÷Μ”–…ΌΝΩΒΡΦΤΥψΝΩ‘ωΦ”ΒΪ «¥χά¥ΝΥ”––ßΒΡ–ßΙϊΧα…ΐΘ§Υυ“‘’β «÷ΒΒΟΒΡΓΘ
ΔαRole of Excitation
ΈΣΝΥΧαΙ©excitationΙΠΡήΒΡ“ΜΗω«εΈζ»œ÷ΣΆΦœώΘ§Ής’Ώ―–ΨΩΝΥSE_Resnet50ΒΡ ΐΨίΖ÷≤ΦΓΘ’βΗω ΐΨίΖ÷≤Φ÷ς“Σ¥”3ΗωΫ«Ε»ά¥ΩΦ≤λΘ§“Μ «≤ΜΆ§ΒΡάύΨ≠ΙΐExcitation÷°ΚσΒΡ ΐΨίΖ÷≤ΦΘ§Εΰ «‘Ύ≤ΜΆ§ΒΡΆχ¬γ…νΕ»œ¬ ΐΨίΖ÷≤ΦΒΡ≤ν“λΘ§»ΐ «Ά§“ΜΗωάύ÷–≤ΜΆ§ΆΦΤ§ΒΡ ΐΨίΖ÷≤Φ±δΜ·ΓΘ
Ήœ»Έ“Ο«ά¥Ω¥Ω¥≤ΜΆ§ΒΡάύΒΡ ΐΨίΖ÷≤Φ«ιΩωΓΘ
»γœ¬ΆΦΥυ ΨΘ§‘ΎResnet-50…œ≤β ‘ΝΥ≤ΜΆ§ΒΡclass‘Ύ≤ΜΆ§ΒΡΆχ¬γ…νΕ»œ¬”…”ΎSE blockΒΡ”Αœλ≤ζ…ζΒΡ≤ΜΆ§ ΐΨίΖ÷≤Φ«ιΩωΓΘ
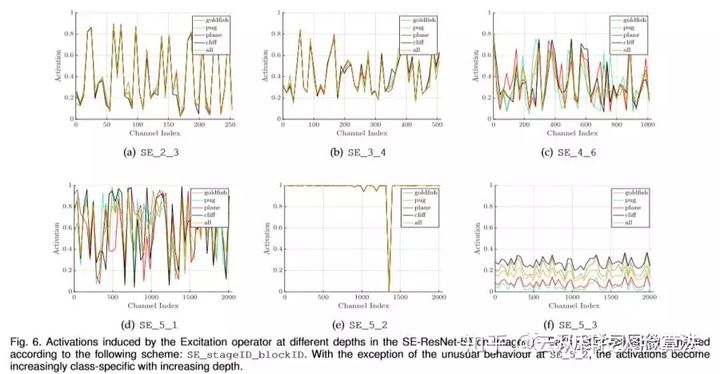
¥”…œΆΦΩ…“‘Ω¥≥ωΘ§≤ΜΆ§ΒΡclassΒΡ ΐΨίΖ÷≤Φ‘Ύ«≥≤ψΆχ¬γ÷–ΒΡ ΐΨίΖ÷≤ΦΖ«≥ΘœύΥΤΘ§±»»γSE_2_3.’βΥΒΟςΝΥ‘ΎΆχ¬γΒΡ«≥≤ψ≤ΩΖ÷ΗςΗωάύ÷°ΦδΙ≤œμΝΥΡ≥÷÷ΧΊ’ςΆ®ΒάΒΡ÷Ί“Σ–‘Θ§ΜΙΟΜ”–≤ζ…ζΖ÷Μ·ΓΘΒΪ «‘ΎΆχ¬γΗϋ…ν¥ΠΘ§≤ΜΆ§ΒΡclass÷°ΦδΒΡ ΐΨίΖ÷≤Φ±μœ÷≥ωΝΥclass_specificΘ®άύ±πΧΊ“λ–‘Θ©Θ§±»»γSE_4_6ΚΆSE_5-1ΓΘ
Τδ¥ΈΘ§Έ“Ο«‘ΌΩ¥Ω¥‘ΎΆχ¬γΉνΚσΒΡstage÷–SE blockΒΡ“Μ–©Ζ¥≥Θ±μœ÷ΓΘ
»γœ¬ΆΦΥυ ΨΘ§SE_5-2÷–ΗςΗωάύ±πΉνΚσΒΡΦΛΜν÷ΒΕΦΦΗΚθΫ”Ϋϋ”ΎΆ§“ΜΗωvalueΘ§«ζœΏΕΦΦΗΚθ÷ΊΚœΝΥΓΘSE_5-3ΚσΟφΫτΫ”Ή≈“ΜΗωpooling≤ψΚΆ“ΜΗωΖ÷άύ≤ψΓΘ
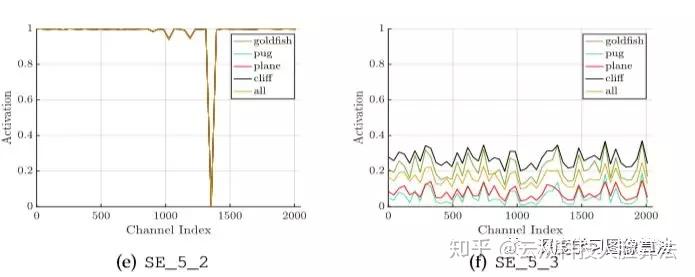
‘ΎSE_5-2÷–«ζœΏΦΗΚθ÷ΊΚœΘ§‘ΎSE_5-3÷–ΗςΗωάύΥδ»Μ≤Μ÷ΊΚœΘ§ΒΪ «±δΜ·«ς ΤΦΗΚθ“ΜΡΘ“Μ―υΘ§Έ®“ΜΒΡ«χ±πΈόΖ«ΨΆ «scale≥ΏΕ»ΥθΖ≈…œΒΡ“Μ–©«χ±πΑ’ΝΥΓΘ¥”’βΗωœ÷œσΈ“Ο«≤¬œκΘ§‘ΎΆχ¬γΒΡΉνΚσstage÷–SE blockΕ‘”ΎΆχ¬γΒΡ÷Ί–¬–ΘΉΦ“―Ψ≠ΟΜ”–‘γΤΎstageΒΡSE blockΡ«Ο¥÷Ί“ΣΝΥΓΘ‘Ύ ΒΦ ΙΛ≥Χ÷–Θ§Έ“Ο«Ω…“‘“Τ≥ΐlast stageΒΡSEΆχ¬γά¥Φθ…ΌΦΤΥψΝΩΆ§ ±”÷ΦΗΚθ≤ΜΜα¥χά¥–ßΙϊΨΪΕ»…œΒΡœ¬ΫΒΓΘ
ΉνΚσΈ“Ο«‘ΌΩ¥Ω¥Ά§“ΜΗωάύ÷–≤ΜΆ§ΆΦΤ§ΒΡ ΐΨίΖ÷≤Φ±δΜ·ΓΘ»γœ¬ΆΦΥυ ΨΘ§Ής’Ώ“‘2ΗωclassΈΣάΐΉ”Θ§’Ι ΨΝΥ‘Ύ“ΜΗωάύ÷–ΒΡΤΫΨυ÷ΒΚΆ±ξΉΦ≤νΥφΉ≈≤ΜΆ§ΒΡchannelΚΆ≤ΜΆ§ΒΡΆχ¬γdepthΒΡ±δΜ·ΓΘ
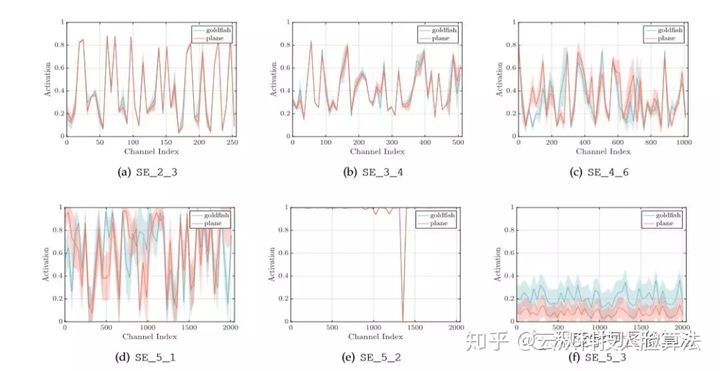
¥”…œΆΦ÷–Έ“Ο«Ω…“‘Ω¥≥ωάύΦδΚΆάύΡΎ÷– ΐΨίΖ÷≤ΦΕΦ «ΥφΉ≈Άχ¬γdepth≤ΜΕœ±δΜ·ΒΡΓΘΥφΉ≈Άχ¬γ±δ…νΘ§ΖΫ≤ν“Μ÷±±δ¥σΘ§“≤ΨΆ «άύΡΎΚΆάύΦδΕΦ≤ζ…ζΝΥΖ÷Μ·–‘Θ§’β «Άχ¬γΦχ±πΡήΝΠΧαΗΏΒΡ“Μ÷÷±μœ÷ΓΘΧΊ±π‘ΎSE-5-1÷–ΖΫ≤ν“―Ψ≠±δΒΟΩ…ΙέΓΘ”…¥ΥΈ“Ο«Ω…“‘¥σΒ®≤¬œκΘ§άύΡΎ Βάΐ≤ν“λ–‘ΒΡ≤ΜΕœΧαΗΏ¬ζΉψΝΥ≤ΜΕœ‘ω≥ΛΒΡάύΦδ≤ν“λ–‘ΒΡ–η«σΓΘΜΜΨδΜΑΥΒΘ§άύΡΎΒΡΖ÷Μ·ΡήΝΠΒΡΧαΗΏΉν÷’“≤¥ΌΫχΝΥάύΦδΖ÷Μ·ΡήΝΠΒΡΧαΗΏΓΘ
’βΤΣ¬έΈΡΜΙΫ≤ΝΥΚήΕύœΗΫΎΘ§ΒΪ «±ΨΈΡΒΫ¥ΥΈΣ÷ΙΘ§Ζώ‘ρΉς’ΏΒΡΆχ¬γ « ’Ν≤ΝΥΘ§Έ“≈¬Έ“’βΤΣΈΡ’¬ΈόΖ® ’Ν≤ΝΥΓΘ≤ΜΥΒΝΥΘ§Έ“»ΞΦ”ΑύΝΥΘΓ ß≈ψΝΥœ»ΘΓ
ΙΪ÷ΎΚ≈:facefinetune
ΖΔœ÷ΗϋΕύΨΪ≤
ΙΊΉΔΙΪ÷ΎΚ≈
