ДњТыЃКhttps://github.com/MONI-JUAN/TensorFlow 19ЁЊЁЊch14-ДЪЕФЯђСПБэЪОЃКword2vecгыДЪЧЖШы
ФПТМ
-
- ЛљБОИХФю
-
- 1.ДЪЧЖШы
- 2.ЛёШЁгГЩфЙиЯЕ fff
- ЗНЗЈвЛЃКCBOW
-
- 1.вЛИіДЪдЄВтвЛИіДЪ
- 2.ЖрИіДЪдЄВтвЛИіДЪ
- ЗНЗЈЖўЃКSkip-Gram
- бЕСЗ Skip-Gram
-
- ЕквЛВНЃКЯТдигяСЯПт
- ЕкЖўВНЃКжЦзїДЪБэ
- ЕкШ§ВНЃКЩњГЩbatch
- ЕкЫФВНЃКНЈСЂФЃаЭ
- ЕкЮхВНЃКПЊЪМбЕСЗ
- ЕкСљВНЃКПЩЪгЛЏ
ЛљБОИХФю
1.ДЪЧЖШы
ДЪЧЖШыЃКНЋвЛИіДЪгяЃЈwordЃЉзЊЛЛГЩвЛИіЯђСПЃЈvectorЃЉЃЌгУword2vecБэЪОДЪЧЖШы
ЖРШШБрТыЃКУПИізжФИгУвЛИіЯђСПБэЪОЃЌР§ШчБэЪОаЁаДзжФИЃЌдђашвЊвЛИіГЄЖШЮЊ26ЕФЯђСПБэЪОУПИізжФИЃЌЖРШШБэЪОЭъШЋЦНЕШЕиПДДєСЫЕЅДЪБэжаЕиЫљгаЕЅДЪЃЌКіТдСЫДЪгыДЪжЎЧАЕФСЊЯЕЁЃЕЋЪЧгааЉЕЅДЪжЎМфЯрЫЦадИќДѓЃЌЗДЖјЛсБЛКіЪг
word2vec ЃКбЇЯАвЛИігГЩф fff ЃЌАбЕЅДЪБфГЩЯђСПЃЌ vec=f(word)vec=f(word)vec=f(word) ЁЃШч256ЮЌЛђ512ЮЌЃЌПЩвдИќМгИпаЇЕФЗНЪНБэЪОЕЅДЪЃЌЛсгаИќЗсИЛЕФгаЙиДЪгяЕФаХЯЂЃЌадФмЛсДѓДѓЬсИпЁЃ
2.ЛёШЁгГЩфЙиЯЕ fff
ЗНЗЈЃК
- ЛљгкЁАМЦЪ§ЁБЃКНЋОГЃЭЌЪБГіЯжЕФДЪгГЩфЕНЯђСППеМфЕФЯрНќЮЛжУЃЌР§ШчCBOW
- ЛљгкЁАдЄВтЁБЃКДгвЛИіДЪЛђМИИіДЪГіЗЂЃЌдЄВтЫќУЧПЩФмЕТЯрСкДЪЃЌЭЈГЃгУетжжЃЌР§ШчSkip-Gram
ЗНЗЈвЛЃКCBOW
CBOW ЕФШЋГЦЮЊ Continuous Bag of WordsЃЌМДСЌајДЪДќФЃаЭЃЌЩЋЕФКЫаФ ЫМЯыЪЧРћгУФГИіДЪгяЕФЩЯЯТЮФдЄВтетИіДЪгяЁЃ
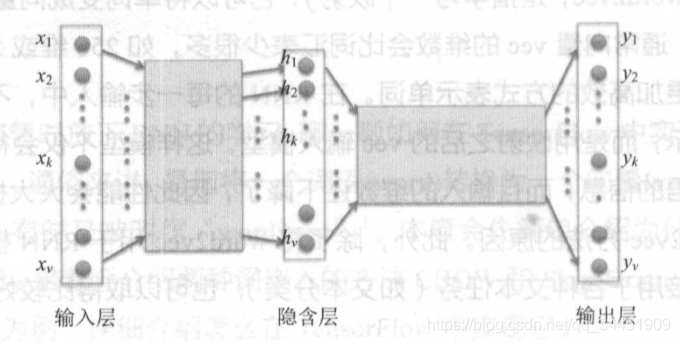
1.вЛИіДЪдЄВтвЛИіДЪ
ЪфШыxЃЌОЙ§ШЋСЌНгвўВиВуЕНhЃЌhОЙ§ШЋСЌНгВуЪфГіyЁЃ
ЃЈV ЪЧДЪЛуБэжаДЪЕФЪ§СПЃЌЖРШШБэЪОЕФ x ЕФаЮзДЮЊ(V,) ЃЉ
ЪфГі y ЯрЕБгкзі Softmax ВйзїЧАЕФ logitsЃЌаЮзДвВЪЧ (V,) ЃЌЪЧгУвЛИіДЪдЄВтСэвЛИіДЪЁЃ
вўВуЕФжЕБЛЕБзїЪЧДЪЕФЧЖШыБэЪОЃЌМД word2vec жаЕФ ЁАvecЁБ
2.ЖрИіДЪдЄВтвЛИіДЪ
ЕНвўКЌВуЕФЪБКђЃЌАбШЋСЌНгЕФжЕЖММгЦ№РД
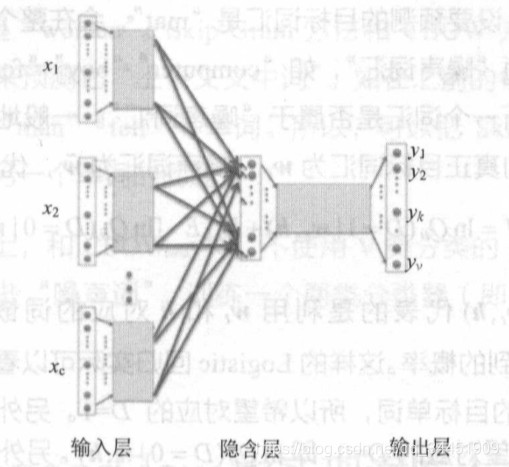
ЖдгІЕФЭјТчНсЙЙЃК
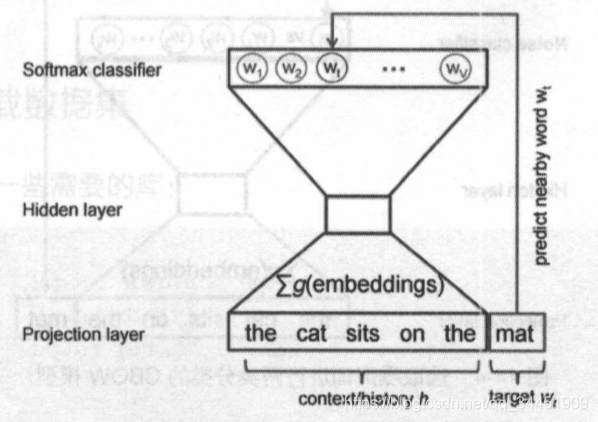
ШчЭМжаЕФ ЁАthe cat sits on theЁБЃЌдЄВт ЁАmatЁБ
ећИіЭјТчЯрЕБгкЪЧ V РрЗжРрЦїЃЌV ЭЈГЃЗЧГЃДѓЃЌвђДЫМђЕЅЕиаоИФЭјТчНЋ V ЗжЮЊСНРрЁЃ
вВОЭЪЧХаЖЯЪЧЗёЮЊЁАдыЩљДЪЛуЁБЁЃ
гХЛЏКЏЪ§ЃК
J=ln?QІШ(D=1ЈOwt,h)+kEw~?Pnoise [ln?QІШ(D=0ЈOw~,h)]J=\ln Q_{\theta}\left(D=1 \mid \boldsymbol{w}_{t}, \boldsymbol{h}\right)+k \underset{\widetilde{w} \sim P_{\text {noise }}}{E} \left[\ln Q_{\theta}(D=0 \mid \tilde{\boldsymbol{w}}, \boldsymbol{h})\right] J=lnQІШ?(D=1ЈOwt?,h)+kw ?Pnoise ?E?[lnQІШ?(D=0ЈOw~,h)]
ЦфжаЃК
- hhhЃКЩЯЯТЮФ
- wtw_twt?ЃКеце§ЕФФПБъДЪЛу
- w~\widetilde{w}w ЃКдыЩљДЪЛу
- QІШQ_{\theta}QІШ?ЃКLogistic ЛиЙщЕУЕНЕФИХТЪ
бЁШЁдыЩљДЪНјааСНРрЗжРрЕФ CBOW ФЃаЭЃК
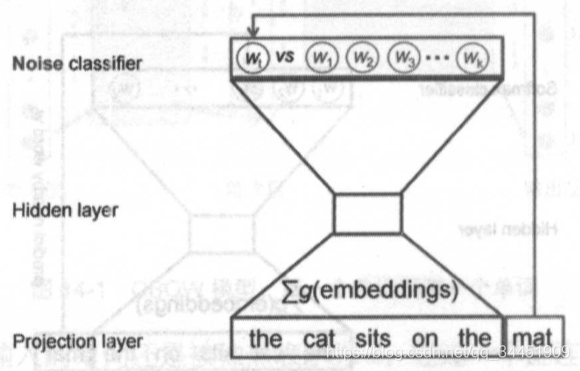
вўКЌВуПЩвдПДзїЪЧ word2vec жаЕФ ЁАvecЁБ ЯђСПЁЃ
ЖдгквЛИіЕЅДЪЃЌЯШНЋЖРШШБэЪОЪфШыФЃаЭЃЌвўКЌВуЕФжЕЖдгІЕФДЪЕФЧЖШыБэЪОЁЃ
дк Tensorflow жаЃЌЫ№ЪЇБЛГЦЮЊ NCE Ы№ЪЇЃЌЖдгІЕФКЏЪ§ЮЊ tf.nn.nec_lossЁЃ
ЗНЗЈЖўЃКSkip-Gram
Skip-Gram ЗНЗЈКЭ CBOW ЗНЗЈе§КУЯрЗДЃК ЪЙгУЁАГіЯжЕФДЪЁБРДдЄВтЫќЁАЩЯЯТЮФЮФжаДЪЁБЁЃ
ШчдкжЎЧАЕФОфзгжаЃЌЪЧЪЙгУ ЁАwomanЁБ ЃЌРДдЄВтЁАmanЁБЃЌЁАfellЁБЕШЕЅДЪ ЁЃ
ЫљвдЃЌПЩвдАб Skip-Gram ЗНЗЈПДзїДгвЛИіЕЅДЪдЄВтСэвЛИіЕЅДЪЕФЮЪЬтЁЃ
КѓУцЪЧгУ Tensorflow бЕСЗвЛИі Skip-Gram ЗНЗЈЕФДЪЧЖШыЁЃ
бЕСЗ Skip-Gram
жБНгдЫаа word2vec_basic.py МДПЩ
python word2vec_basic.py
ЯъЯИПДвЛЯТЦфжаСљИіВНжшЕФДњТы
ЕквЛВНЃКЯТдигяСЯПт
####################################################################
# ЕквЛВН: ЯТдигяСЯПт
print("----------------------------------")
print("ЕквЛВН: ЯТдигяСЯПт")
url = 'http://mattmahoney.net/dc/'def maybe_download(filename, expected_bytes):"""етИіКЏЪ§ЕФЙІФмЪЧЃКШчЙћfilenameВЛДцдкЃЌОЭдкЩЯУцЕФЕижЗЯТдиЫќЁЃШчЙћfilenameДцдкЃЌОЭЬјЙ§ЯТдиЁЃзюжеЛсМьВщЮФзжЕФзжНкЪ§ЪЧЗёКЭexpected_bytesЯрЭЌЁЃ"""if not os.path.exists(filename):print('start downloading...')filename, _ = urllib.request.urlretrieve(url + filename, filename)statinfo = os.stat(filename)if statinfo.st_size == expected_bytes:print('Found and verified', filename)else:print(statinfo.st_size)raise Exception('Failed to verify ' + filename + '. Can you get to it with a browser?')return filenamedef read_data(filename):"""етИіКЏЪ§ЕФЙІФмЪЧЃКНЋЯТдиКУЕФzipЮФМўНтбЙВЂЖСШЁЮЊwordЕФlist"""with zipfile.ZipFile(filename) as f:data = tf.compat.as_str(f.read(f.namelist()[0])).split()return datafilename = maybe_download('text8.zip', 31344016) # ЯТдигяСЯПтtext8.zip
vocabulary = read_data(filename) # НЋгяСЯПтНтбЙЃЌВЂзЊЛЛГЩвЛИіwordЕФlist
print('Data size', len(vocabulary)) # змГЄЖШЮЊ1700Эђзѓгв
print(vocabulary[0:100]) # ЪфГіЧА100ИіДЪЁЃ
text8.zipвЛЙВ29.8mbЃЌШчЙћЯТВЛЯТРДЃЌПЩвдЪжЖЏЯТдиЗХЕНЕБЧАФПТМЃКhttp://mattmahoney.net/dc/text8.zip
ЕкЖўВНЃКжЦзїДЪБэ
####################################################################
# ЕкЖўВН: жЦзївЛИіДЪБэЃЌНЋВЛГЃМћЕФДЪБфГЩвЛИіUNKБъЪЖЗћ
print("----------------------------------")
print("ЕкЖўВН: жЦзїДЪБэ")def build_dataset(words, n_words):"""КЏЪ§ЙІФмЃКНЋдЪМЕФЕЅДЪБэЪОБфГЩindex"""count = [['UNK', -1]]count.extend(collections.Counter(words).most_common(n_words - 1))dictionary = dict()for word, _ in count:dictionary[word] = len(dictionary)data = list()unk_count = 0for word in words:if word in dictionary:index = dictionary[word]else:index = 0 # UNKЕФindexЮЊ0unk_count += 1data.append(index)count[0][1] = unk_countreversed_dictionary = dict(zip(dictionary.values(), dictionary.keys()))return data, count, dictionary, reversed_dictionaryvocabulary_size = 50000 # ДЪБэЕФДѓаЁЮЊ5ЭђЃЈМДЮвУЧжЛПМТЧзюГЃГіЯжЕФ5ЭђИіДЪЃЉ
data, count, dictionary, reverse_dictionary = build_dataset(vocabulary, vocabulary_size)
del vocabulary # ЩОГ§вдНкЪЁФкДц
print('Most common words (+UNK)', count[:5]) # ЪфГізюГЃГіЯжЕФ5ИіЕЅДЪ
print('Sample dataЃЈbefore):', [reverse_dictionary[i] for i in data[:10]]) # дРДЧА10ИіЕЅДЪ
print('Sample dataЃЈlater) :', data[:10]) # зЊЛЛКѓЕФdata
data_index = 0 # ЯТУцЪЙгУdataРДжЦзїбЕСЗМЏ

ЕкШ§ВНЃКЩњГЩbatch
вЛИі batch ПЩвдПДзїЪЧвЛаЉЁАЕЅДЪЖдЁБЕФМЏКЯЃЌШч woman -> man ЃЌ woman -> fell
М§ЭЗзѓБпБэЪОЁАГіЯжЕФЕЅДЪЁБЃЌгвБпБэЪОИУЕЅДЪЫљдкЁАЩЯЯТЮФЁБжаЕФЕЅДЪЁЃ
ЕкШ§ВНжївЊЪЧЖЈвхвЛИіКЏЪ§ЃЌгУгкЩњГЩskip-gramФЃаЭгУЕФbatch
generate_batch(batch_size, num_skips, skip_window)
ЪфШыЃК
-
batch_sizeЃКвЛИіbatchжаЕЅДЪЖдЕФИіЪ§
-
num_skips ЃКЁБЩЯЯТЮФЁАЪ§
skip_windowЃКЁБЩЯЯТЮФЁАКђбЁЪ§
ЩњГЩЕЅДЪЖдЕФЪБКђЃЌЯШдкгяСЯПтжабЁШЁГЄЖШЮЊЃЈskip_window * 2+1ЃЉСЌајЕЅДЪСаБэЃЌзюжаМфЕФвВОЭЪЧSkip-Gram ЗНЗЈжаЁБГіЯжЕФЕЅДЪЁАЃЌЦфгрЕФЃЈskip_window * 2ЃЉЪЧЁБЩЯЯТЮФЁАЃЌдкетЕБжабЁШЁ num_skips ИіДЪзїЮЊЁБЩЯЯТЮФЁАЗХШы labelsЁЃ
ЪфГіЃК
- batchЃКSkip-Gram ЗНЗЈжаЁБГіЯжЕФЕЅДЪЁАЃЌаЮзДЮЊ (batch_size, )
- labelsЃКЁБЩЯЯТЮФЁАжаЕФЕЅДЪ (batch_size, 1)
####################################################################
# ЕкШ§ВНЃКЖЈвхвЛИіКЏЪ§ЃЌгУгкЩњГЩskip-gramФЃаЭгУЕФbatch
print("----------------------------------")
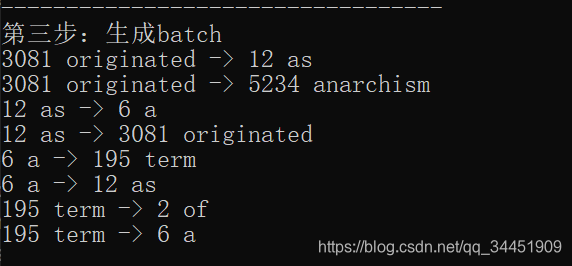
print("ЕкШ§ВНЃКЩњГЩbatch")def generate_batch(batch_size, num_skips, skip_window):# data_indexЯрЕБгквЛИіжИеыЃЌГѕЪМЮЊ0# УПДЮЩњГЩвЛИіbatchЃЌdata_indexОЭЛсЯргІЕиЭљКѓЭЦglobal data_indexassert batch_size % num_skips == 0assert num_skips <= 2 * skip_windowbatch = np.ndarray(shape=(batch_size), dtype=np.int32)labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)span = 2 * skip_window + 1 # [ skip_window target skip_window ]buffer = collections.deque(maxlen=span)# data_indexЪЧЕБЧАЪ§ОнПЊЪМЕФЮЛжУ# ВњЩњbatchКѓОЭЭљКѓЭЦ1ЮЛЃЈВњЩњbatchЃЉfor _ in range(span):buffer.append(data[data_index])data_index = (data_index + 1) % len(data)for i in range(batch_size // num_skips):# РћгУbufferЩњГЩbatch# bufferЪЧвЛИіГЄЖШЮЊ 2 * skip_window + 1ГЄЖШЕФword list# вЛИіbufferЩњГЩnum_skipsИіЪ§ЕФбљБО# print([reverse_dictionary[i] for i in buffer])target = skip_window # target label at the center of the buffertargets_to_avoid = [skip_window] # БЃжЄбљБОВЛжиИДfor j in range(num_skips):while target in targets_to_avoid:target = random.randint(0, span - 1)targets_to_avoid.append(target)batch[i * num_skips + j] = buffer[skip_window]labels[i * num_skips + j, 0] = buffer[target]buffer.append(data[data_index])# УПРћгУbufferЩњГЩnum_skipsИібљБОЃЌdata_indexОЭЯђКѓЭЦНјвЛЮЛdata_index = (data_index + 1) % len(data)data_index = (data_index + len(data) - span) % len(data)return batch, labels# ФЌШЯЧщПіЯТskip_window=1, num_skips=2
# ДЫЪБОЭЪЧДгСЌајЕФ3(3 = skip_window*2 + 1)ИіДЪжаЩњГЩ2(num_skips)ИібљБОЁЃ
# ШчСЌајЕФШ§ИіДЪ['used', 'against', 'early']
# ЩњГЩСНИібљБОЃКagainst -> used, against -> early
batch, labels = generate_batch(batch_size=8, num_skips=2, skip_window=1)
for i in range(8):print(batch[i], reverse_dictionary[batch[i]],'->', labels[i, 0], reverse_dictionary[labels[i, 0]])
ЕкЫФВНЃКНЈСЂФЃаЭ
БфСП embeddings ЃЌаЮзДЪЧЃЈvocabulay_size, embedding_sizeЃЉ,ЖдгкidЕЅДЪЕФЧЖШыЪЧ embeddings[id,:]
ЪфШыЪ§Он train_inputsЃЌгУ tf.nn.embedding_lookup зЊГЩЖдгІЕФЯђСП embed
дйЖдБШ embedКЭЪфШыЕФБъЧЉ train_lavelsЃЌгУ tf.nn.nec_loss ЖЈвхNCEЕФЫ№ЪЇ
бЕСЗФЃаЭЕФЪБКђЛЙЯЃЭћЖдФЃаЭНјаабщжЄЃЌЫљвдШЁГіЁБбщжЄЕЅДЪЁАЕФЪБКђгЩгк embeddings ИїИіЮЌЖШЕФДѓаЁПЩФмВЛвЛбљЃЌЫљвдашвЊзівЛДЮЙщвЛЛЏЃЌЙщвЛЛЏКѓЕФ normalized_embeddings МЦЫубщжЄДЪКЭЦфЫћЕЅДЪЕФЯрЫЦЖШЁЃ
####################################################################
# ЕкЫФВНЃКНЈСЂФЃаЭ
print("----------------------------------")
print("ЕкЫФВНЃКНЈСЂФЃаЭ")
batch_size = 128
embedding_size = 128 # ДЪЧЖШыПеМфЪЧ128ЮЌЕФЁЃМДword2vecжаЕФvecЪЧвЛИі128ЮЌЕФЯђСП
skip_window = 1 # skip_windowВЮЪ§КЭжЎЧАБЃГжвЛжТ
num_skips = 2 # num_skipsВЮЪ§КЭжЎЧАБЃГжвЛжТ# дкбЕСЗЙ§ГЬжаЃЌЛсЖдФЃаЭНјаабщжЄ
# бщжЄЕФЗНЗЈОЭЪЧевГіКЭФГИіДЪзюНќЕФДЪЁЃ
# жЛЖдЧАvalid_windowЕФДЪНјаабщжЄЃЌвђЮЊетаЉДЪзюГЃГіЯж
valid_size = 16 # УПДЮбщжЄ16ИіДЪ
valid_window = 100 # ет16ИіДЪЪЧдкЧА100ИізюГЃМћЕФДЪжабЁГіРДЕФ
valid_examples = np.random.choice(valid_window, valid_size, replace=False)
num_sampled = 64 # ЙЙдьЫ№ЪЇЪБбЁШЁЕФдыЩљДЪЕФЪ§СП# НЈСЂФЃаЭ
graph = tf.Graph()
with graph.as_default():# ЪфШыЕФbatchtrain_inputs = tf.placeholder(tf.int32, shape=[batch_size])train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])# гУгкбщжЄЕФДЪvalid_dataset = tf.constant(valid_examples, dtype=tf.int32)# дкcpuЩЯЖЈвхФЃаЭwith tf.device('/cpu:0'):# ЖЈвх1ИіembeddingsБфСПЃЌЯрЕБгквЛааДцДЂвЛИіДЪЕФembeddingembeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))# РћгУembedding_lookupПЩвдЧсЫЩЕУЕНвЛИіbatchФкЕФЫљгаЕФДЪЧЖШыembed = tf.nn.embedding_lookup(embeddings, train_inputs)# ДДНЈСНИіБфСПгУгкNCE LossЃЈМДбЁШЁдыЩљДЪЕФЖўЗжРрЫ№ЪЇЃЉnce_weights = tf.Variable(tf.truncated_normal([vocabulary_size, embedding_size],stddev=1.0 / math.sqrt(embedding_size)))nce_biases = tf.Variable(tf.zeros([vocabulary_size]))# tf.nn.nce_lossЛсздЖЏбЁШЁдыЩљДЪЃЌВЂЧваЮГЩЫ№ЪЇЁЃ# ЫцЛњбЁШЁnum_sampledИідыЩљДЪloss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_weights,biases=nce_biases,labels=train_labels,inputs=embed,num_sampled=num_sampled,num_classes=vocabulary_size))# ЕУЕНlossКѓЃЌОЭПЩвдЙЙдьгХЛЏЦїСЫoptimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss)# МЦЫуДЪКЭДЪЕФЯрЫЦЖШЃЌгУгкбщжЄnorm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))normalized_embeddings = embeddings / norm# евГіКЭбщжЄДЪЕФembeddingВЂМЦЫуЫќУЧКЭЫљгаЕЅДЪЕФЯрЫЦЖШvalid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset)similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True)# БфСПГѕЪМЛЏВНжшinit = tf.global_variables_initializer()
ЕкЮхВНЃКПЊЪМбЕСЗ
####################################################################
# ЕкЮхВНЃКПЊЪМбЕСЗ
print("----------------------------------")
print("ЕкЮхВНЃКПЊЪМбЕСЗ")
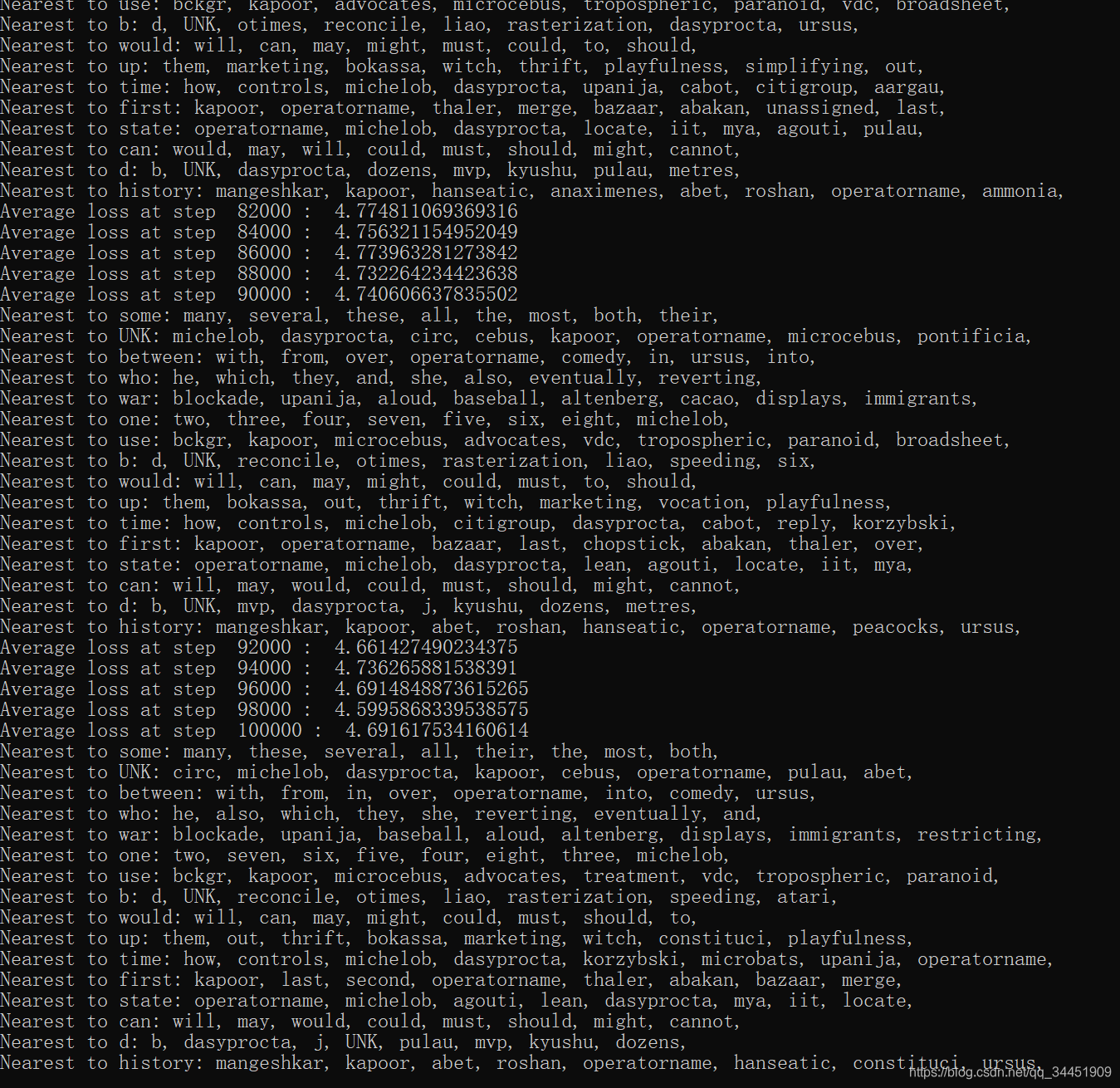
num_steps = 100001with tf.Session(graph=graph) as session: init.run() # ГѕЪМЛЏБфСПprint('Initialized')average_loss = 0for step in xrange(num_steps):batch_inputs, batch_labels = generate_batch(batch_size, num_skips, skip_window)feed_dict = {
train_inputs: batch_inputs, train_labels: batch_labels}_, loss_val = session.run([optimizer, loss], feed_dict=feed_dict) # гХЛЏвЛВНaverage_loss += loss_valif step % 2000 == 0:if step > 0:average_loss /= 2000 print('Average loss at step ', step, ': ', average_loss) # 2000ИіbatchЕФЦНОљЫ№ЪЇaverage_loss = 0# УП1ЭђВНЃЌЮвУЧНјаавЛДЮбщжЄif step % 10000 == 0: sim = similarity.eval() # бщжЄДЪгыЫљгаДЪжЎМфЕФЯрЫЦЖШ# вЛЙВгаvalid_sizeИібщжЄДЪfor i in xrange(valid_size):valid_word = reverse_dictionary[valid_examples[i]]top_k = 8 # ЪфГізюЯрСкЕФ8ИіДЪгяnearest = (-sim[i, :]).argsort()[1:top_k + 1]log_str = 'Nearest to %s:' % valid_wordfor k in xrange(top_k):close_word = reverse_dictionary[nearest[k]]log_str = '%s %s,' % (log_str, close_word)print(log_str)# final_embeddings ЪЧзюКѓЕУЕНЕФ embedding ЯђСП# ЫќЕФаЮзДЪЧ[vocabulary_size, embedding_size]# УПвЛааОЭДњБэзХЖдгІindexДЪЕФДЪЧЖШыБэЪОfinal_embeddings = normalized_embeddings.eval()
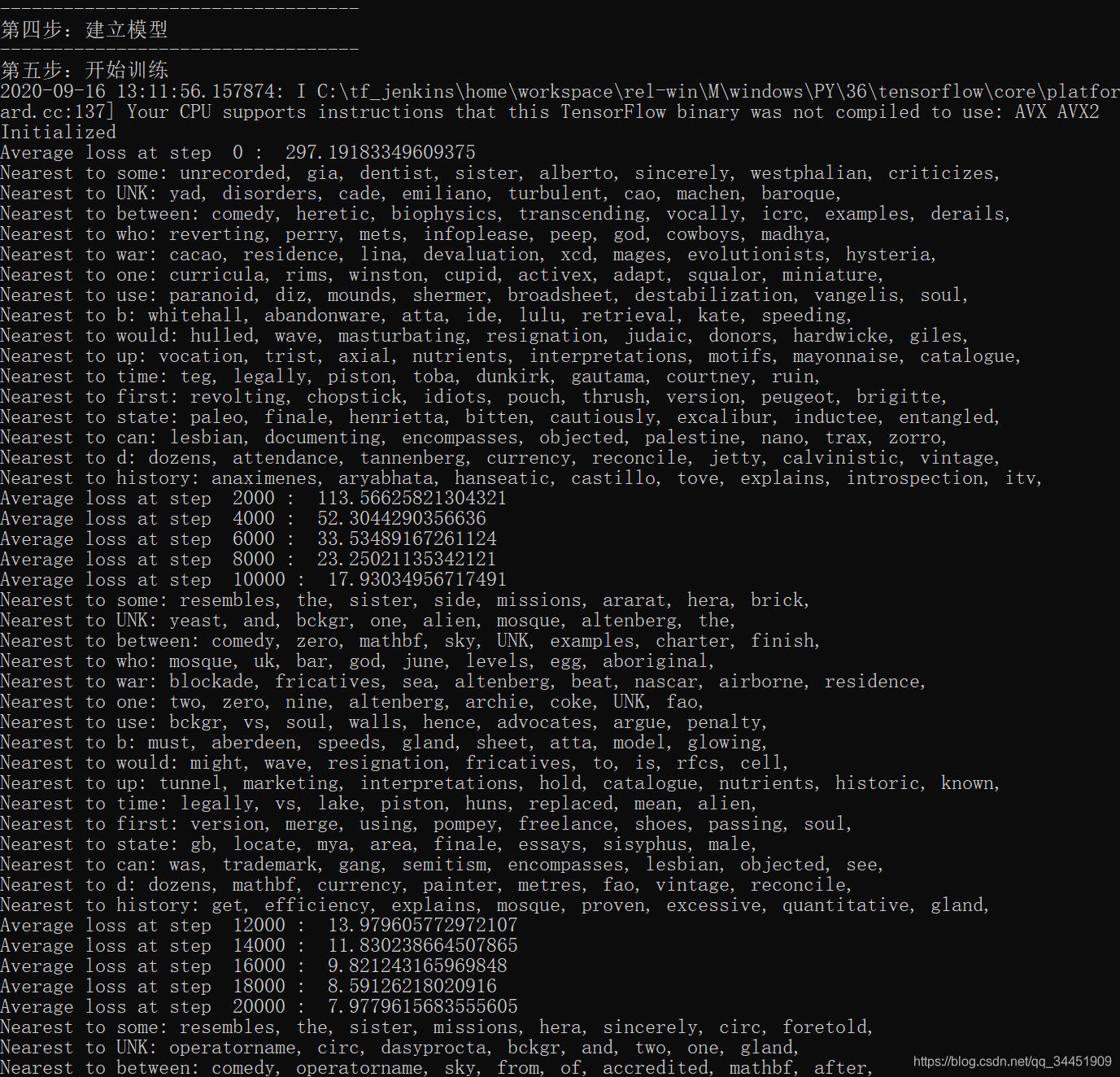
ДгНсЙћПЩвдЗЂЯжЃЌвЛПЊЪМЪфГіЕФЕЅДЪЪЧЫцЛњЕФЃЌУЛгаЪВУДвтвхЁЃ
ЕЋЪЧбЕСЗЕНзюКѓЕФЪБКђЃЌЪфГіЕФДЪЛуЛЙЪЧБШНЯНгНќЕФЃЌЫЕУїembeddingПеМфЕФЯђСПБэЪООпБИСЫвЛЖЈКЌвхЃК
ЕкСљВНЃКПЩЪгЛЏ
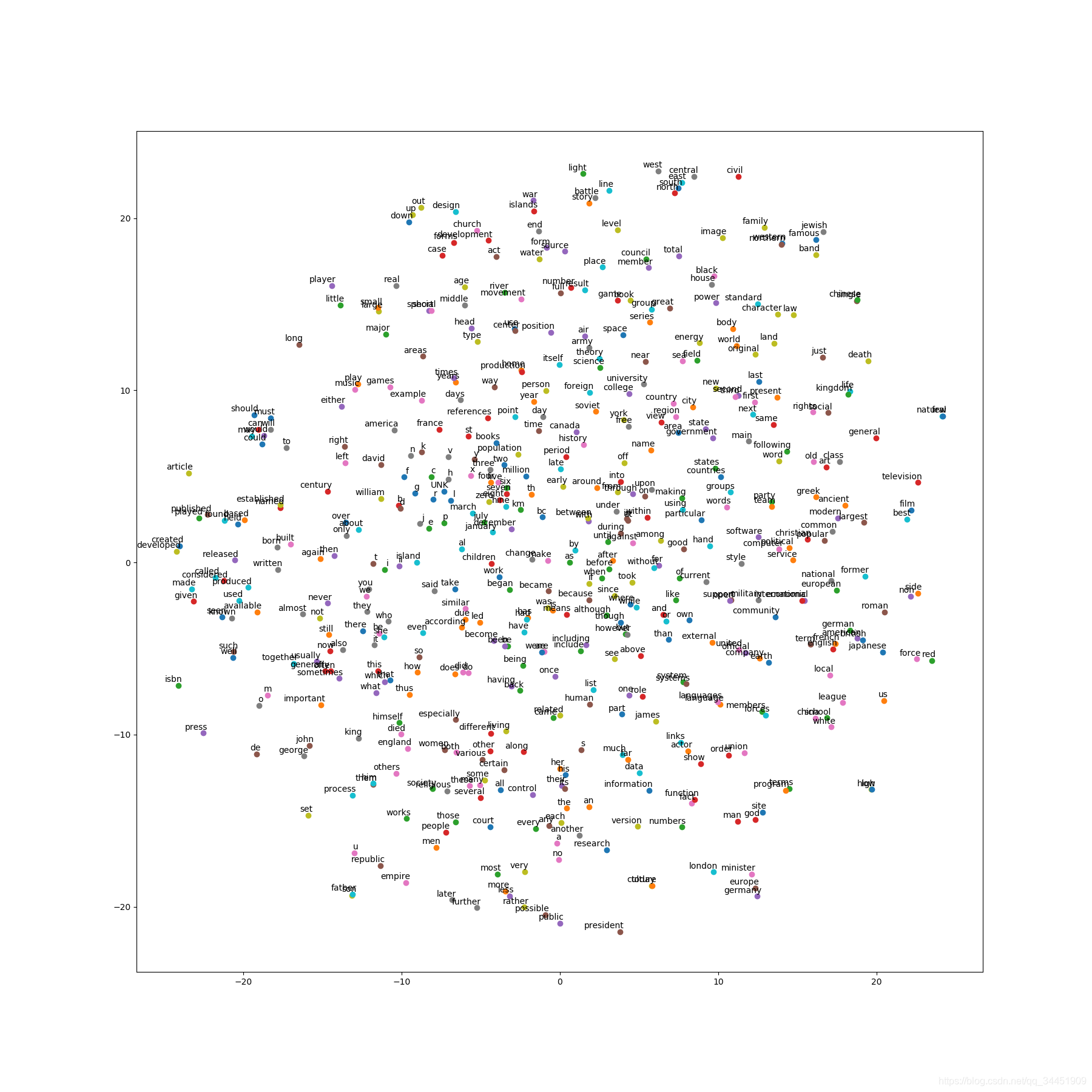
ЕУЕН final_embeddings КѓЖдЧЖШыПеМфНјааПЩЪгЛЏБэЪОЃЌЪЙгУ t-SNE ЗНЗЈАб128ЮЌБфГЩ2ЮЌЃЌЛЈСЫ500ИіДЪЕФЮЛжУЃЌБЃДцЮЊ tsne.png
####################################################################
# ЕкСљВНЃКПЩЪгЛЏ
print("----------------------------------")
print("ЕкСљВНЃКПЩЪгЛЏ")
# ПЩЪгЛЏЕФЭМЦЌЛсБЃДцЮЊЁАtsne.pngЁБdef plot_with_labels(low_dim_embs, labels, filename='tsne.png'):assert low_dim_embs.shape[0] >= len(labels), 'More labels than embeddings'plt.figure(figsize=(18, 18)) # in inchesfor i, label in enumerate(labels):x, y = low_dim_embs[i, :]plt.scatter(x, y)plt.annotate(label,xy=(x, y),xytext=(5, 2),textcoords='offset points',ha='right',va='bottom')plt.savefig(filename)try:# pylint: disable=g-import-not-at-topfrom sklearn.manifold import TSNEimport matplotlibmatplotlib.use('agg')import matplotlib.pyplot as plt# вђЮЊЮвУЧЕФembeddingЕФДѓаЁЮЊ128ЮЌЃЌУЛгаАьЗЈжБНгПЩЪгЛЏ# ЫљвдЮвУЧгУt-SNEЗНЗЈНјааНЕЮЌtsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)# жЛЛГі500ИіДЪЕФЮЛжУplot_only = 500low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only, :])labels = [reverse_dictionary[i] for i in xrange(plot_only)]plot_with_labels(low_dim_embs, labels)except ImportError:print('Please install sklearn, matplotlib, and scipy to show embeddings.')