文章目录
-
- 为啥要肝 Java 原生 BitSet
- BitSet 介绍
-
- BitSet 使用
- Set 偷窥真相的入口
- Set 源码
- 计算 word 数组下标
- 数组 words[wordIndex] 元素位操作
- Go 重写 Java 原生包 BitSet
- Q&A
- 附录
为啥要肝 Java 原生 BitSet
??今天,来聊下关于 java.util 包中的 BitSet 。为什么突然聊这个呢?是有下面一个情景:
??原 AbTest 平台进行 Go 版本的重构「重构的原因有很多,比如资源利用率低、Java 多线程切 Go 协程、等等,这里不做重点」,原实验组流量配比的随机性分桶是用 Java 原生包 BitSet 存储,重构需要完全契合 BitSet 的映射策略。
??所以这里唠一下 Java 原生 BitSet 的内部实现,结尾也会附上 Go 版的实现!
BitSet 介绍
??BitSet ,又叫做 BitMap 。包含于 java.util 原生包,一种数据结构,通过 bit 的两种状态「 true / false 」标识数据性质,通常在大数据排序、优化大数据存储、等等。
??像上文提到的,就是 利用 BitSet 存储了实验流量分配的大量命中信息。
??将 AbTest 实验随机分配的流量位存储在 BitSet 中,当流量进入的时候,依据 BitSet 中的信息进行命中判断,进而完成实验的相关配置。
BitSet 使用
??BitSet 的使用很简单,像 Java 普通类一样,New 之后,进行初始化操作。
??这里提供了多种初始化方法,比如:
static BitSet
valueOf(byte[] bytes)
Returns a new bit set containing all the bits in the given byte array.
static BitSet
valueOf(ByteBuffer bb)
Returns a new bit set containing all the bits in the given byte buffer between its position and limit.
static BitSet
valueOf(long[] longs)
Returns a new bit set containing all the bits in the given long array.
static BitSet
valueOf(LongBuffer lb)
Returns a new bit set containing all the bits in the given long buffer between its position and limit.
??可以观察出来,这些只是参数不一致,就是多态中的重载。
??我们将不以这些方法作为 BitSet 内部机制的分析载体,而是以其中的数据存储方法 Set 作为入口,更具有代表性,一致性。
Set 偷窥真相的入口
??Set 方法是 BitSet 进行数据写入的入口方法,可完成指定位置的数据写入。
??方法介绍如下:
public void set(int bitIndex)
Sets the bit at the specified index to true.
Parameters:
bitIndex - a bit index
Throws:
IndexOutOfBoundsException - if the specified index is negative
Since:
JDK1.0
Set 源码
??了解内部机制,主要两种方法,一种是源码追溯,一种文档查阅。
??下面我们从 Set 源码入手:
public void set(int bitIndex) {
if (bitIndex < 0)throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);int wordIndex = wordIndex(bitIndex);expandTo(wordIndex);words[wordIndex] |= (1L << bitIndex); // Restores invariantscheckInvariants();}private void expandTo(int wordIndex) {
int wordsRequired = wordIndex+1;if (wordsInUse < wordsRequired) {
ensureCapacity(wordsRequired);wordsInUse = wordsRequired;}}// 扩容操作,2倍扩容private void ensureCapacity(int wordsRequired) {
if (words.length < wordsRequired) {
// Allocate larger of doubled size or required sizeint request = Math.max(2 * words.length, wordsRequired);words = Arrays.copyOf(words, request);sizeIsSticky = false;}}/*** Every public method must preserve these invariants.*/private void checkInvariants() {
assert(wordsInUse == 0 || words[wordsInUse - 1] != 0);assert(wordsInUse >= 0 && wordsInUse <= words.length);assert(wordsInUse == words.length || words[wordsInUse] == 0);}
??我们看 set (int bitIndex) 方法,很简单,不到十行的代码!
??画了主要流程图,如下:
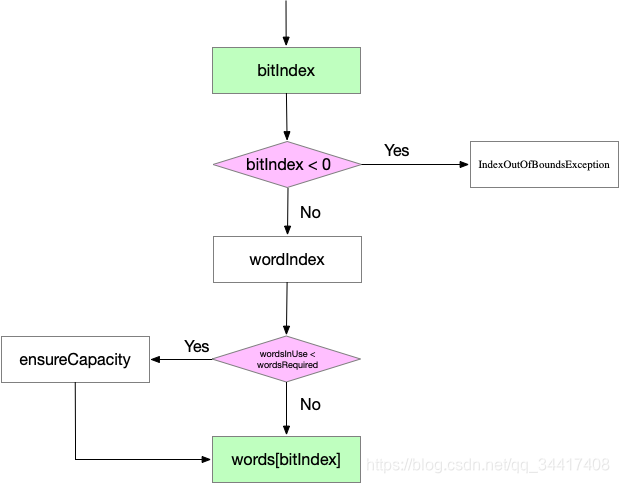
??大体可分为下面四部分,核心为二、四步骤:
1、参数有效性的校验,无效参数直接抛出异常「IndexOutOfBoundsException」;
2、计算数组下标;
3、数组扩容操作;
4、数组元素位操作;
计算 word 数组下标
??下标 wordIndex 计算源码如下,其将参数 bitIndex 进行了右移 6 位操作,相当于 bitIndex / 2^6 (64) 。
/* * BitSets are packed into arrays of "words." Currently a word is * a long, which consists of 64 bits, requiring 6 address bits. * The choice of word size is determined purely by performance concerns. */
private final static int ADDRESS_BITS_PER_WORD = 6;/*** Given a bit index, return word index containing it.*/
private static int wordIndex(int bitIndex) {
return bitIndex >> ADDRESS_BITS_PER_WORD;
}
??为什么这样做呢?和 bitSet 数据结构有关系!
??这里引入 bitset 的初始化源码:
public BitSet(int nbits) {
// nbits can‘t be negative; size 0 is OKif (nbits < 0)throw new NegativeArraySizeException("nbits < 0: " + nbits);initWords(nbits);sizeIsSticky = true; //标识words大小由用户指定}// private void initWords(int nbits) {
words = new long[wordIndex(nbits-1) + 1];}
??可以看到,BitSet 其实质数据结构为 Long[] ,也就是 64 位的元素集合,每个元素也都是 64 位,如下图:
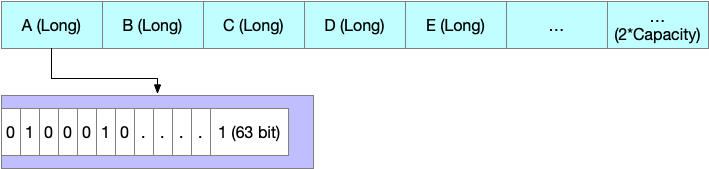
??bitIndex 需要进行 64 位的偏移找到所在的数组下标。
数组 words[wordIndex] 元素位操作
??在找到数组下标之后,要进行元素的 bit 操作。「bit 默认为 0 」 这里引入了 “ 或 ” 运算,运算规则如下:
|=:两个二进制对应位都为0时,结果等于0,否则结果等于1;
??由于 Long 类型是 8 字节,64 位,所以这里要进行移位运算,找到属于 bitIndex 的 bit ,将其置 1 。源码为:
words[wordIndex] |= (1L << bitIndex);
??即翻译成可读性较强的是下面的样子:
words[wordIndex] = [wordIndex] |1 << (bitIndex % 64)
??完成之后,数据标识已写入。
??总体来讲,BitSet 实现及写入逻辑并不困难。 下面将给出 Go 版的 Java 原生 BitSet 写法。
Go 重写 Java 原生包 BitSet
??了解了 Java 原生 BitSet 包的具体实现,换种语言解释也是十分简单,Go 版本如下:
//将 string 转为 bit 桶
sDec, err := base64.StdEncoding.DecodeString(group.Buckets)
if err != nil {
logger.Info("ab process base64.StdEncoding.DecodeString(bucket) fail:%s", err.Error())break
}
dst := make([]bool, experiment.Partitions)
for i, _ := range dst {
//防止解析之后不够partitions大小bitIndex := i / 8if bitIndex < len(sDec) {
dst[i] = (sDec[bitIndex] & (1 << (i % 8))) != 0}
}
Q&A
1、在计算数组元素位操作时,为什么 " 1L << bitIndex " 等价于 " 1 << (bitIndex % 64)" 呢?
是因为 Long 类型数据一共有 64 位,进行移位运算的话,有可能有效位全移出去了,所以需要模上长度。
也可以理解为,每个元素长度是 64,要算当前 bitIndex 所属的位置,取模是一种很好的映射关系。
2、Go 里面没有实现的 BitSet 吗?
Go 没有原生实现 BitSet ,有许多开源包,但开源包各有各的策略,不能保证和 Java 原生 BitSet 集合的存储关系一致!
附录
开发语言,不过是原理的诠释手段之一…